tracr-paper
Tracr: Compiled Transformers as a Laboratory for Interpretability
编译器 Tracr 将以 RASP 编写的人类可读程序转换为标准的 decoder-only transformers。
Transformer 架构与 RASP 编程语言
Transformer 大体结构
link。
之前自己学过 transformer,现在复习一下。Transformer 总体结构如下:
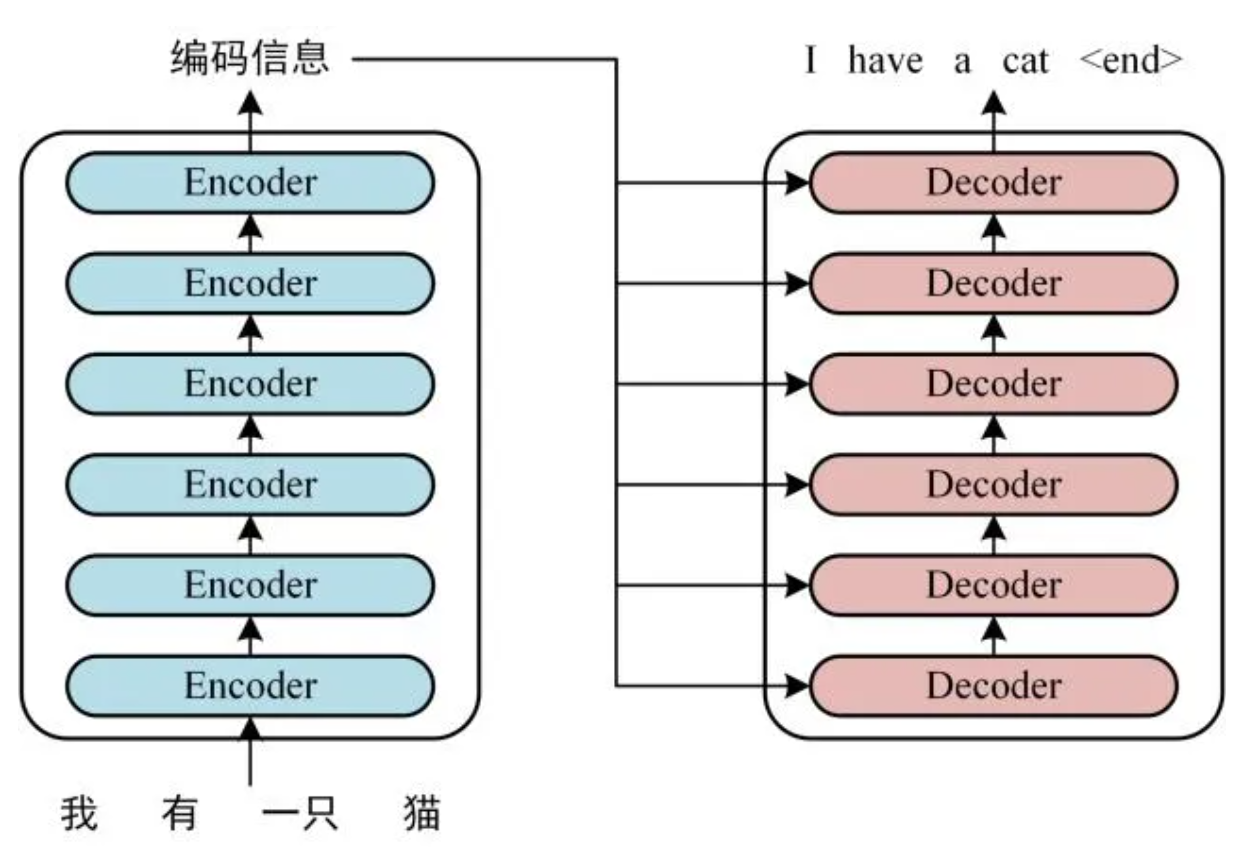
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
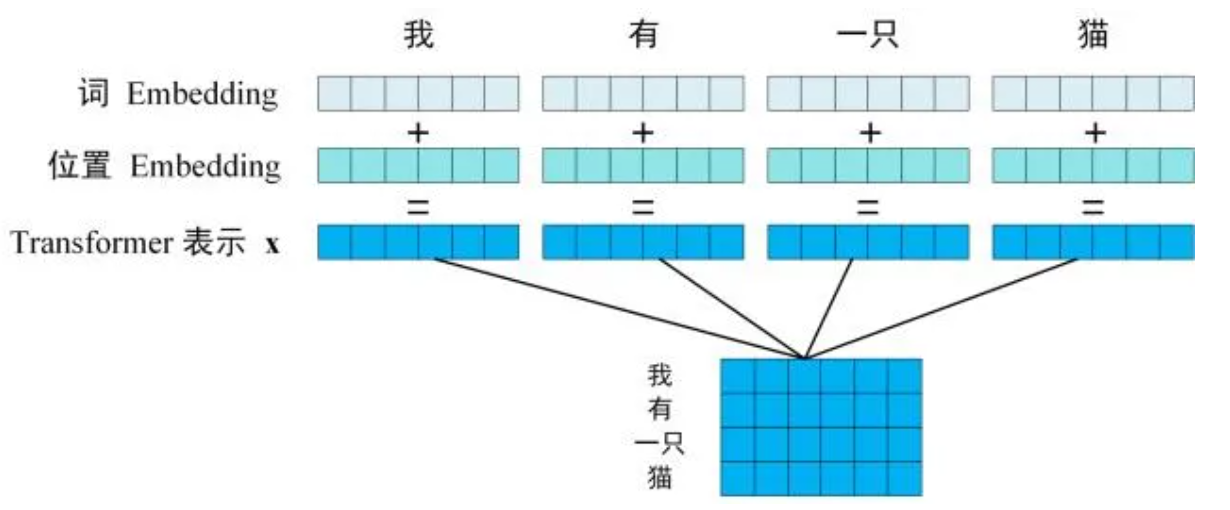
Step1:获取输入句子的每一个单词的表示向量 X,X 由单词的 Embedding 和单词位置的 Embedding 相加得到,Embedding 就是从原始数据提取出来的 Feature。
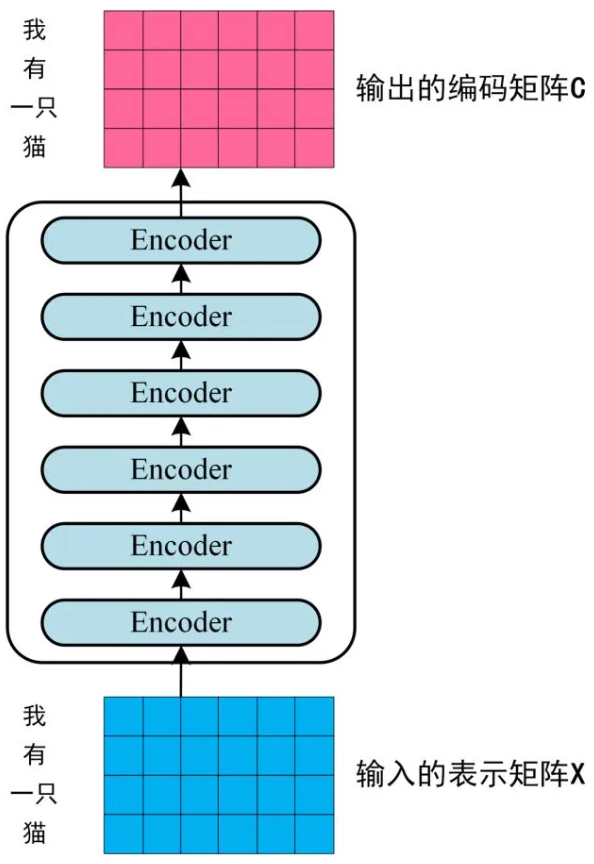
Step2:将得到的向量矩阵传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C。Encoder block 输出的矩阵维度与输入完全一致。
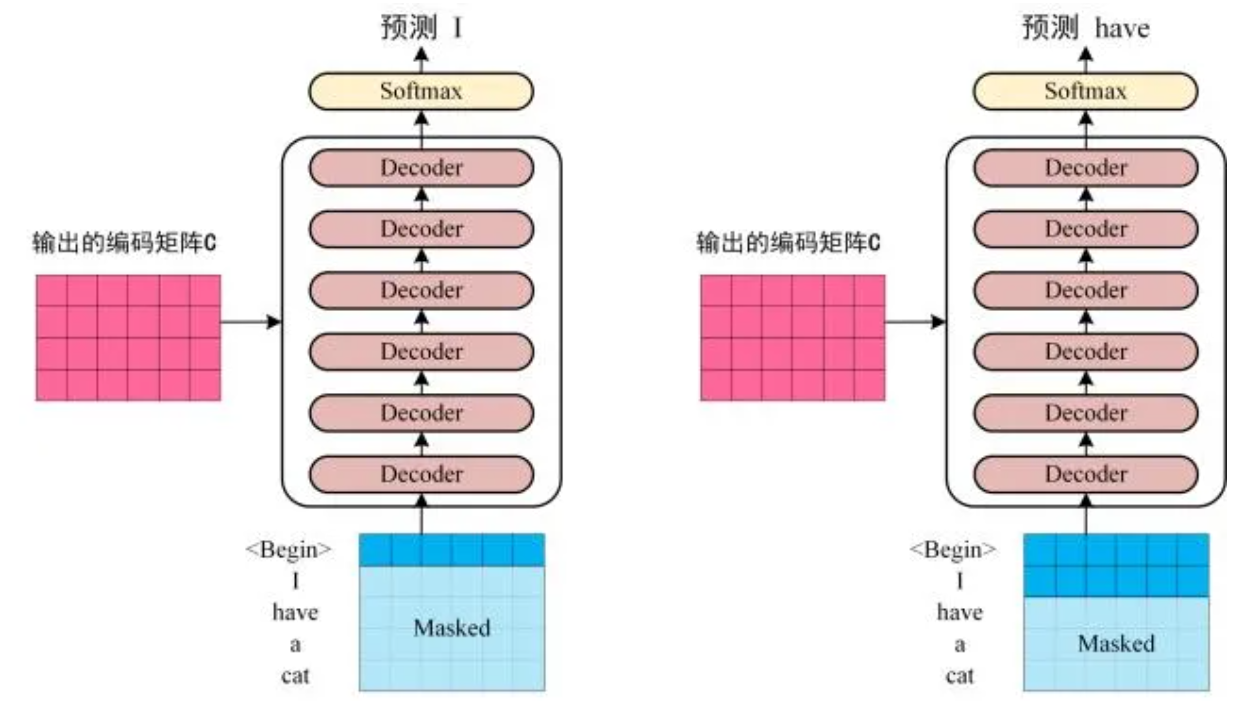
Step3:将 Encoder 输出的编码信息矩阵 C 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1->i 翻译下一个单词 i+1。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
下面重点说一下 Transformer 的自注意力机制。
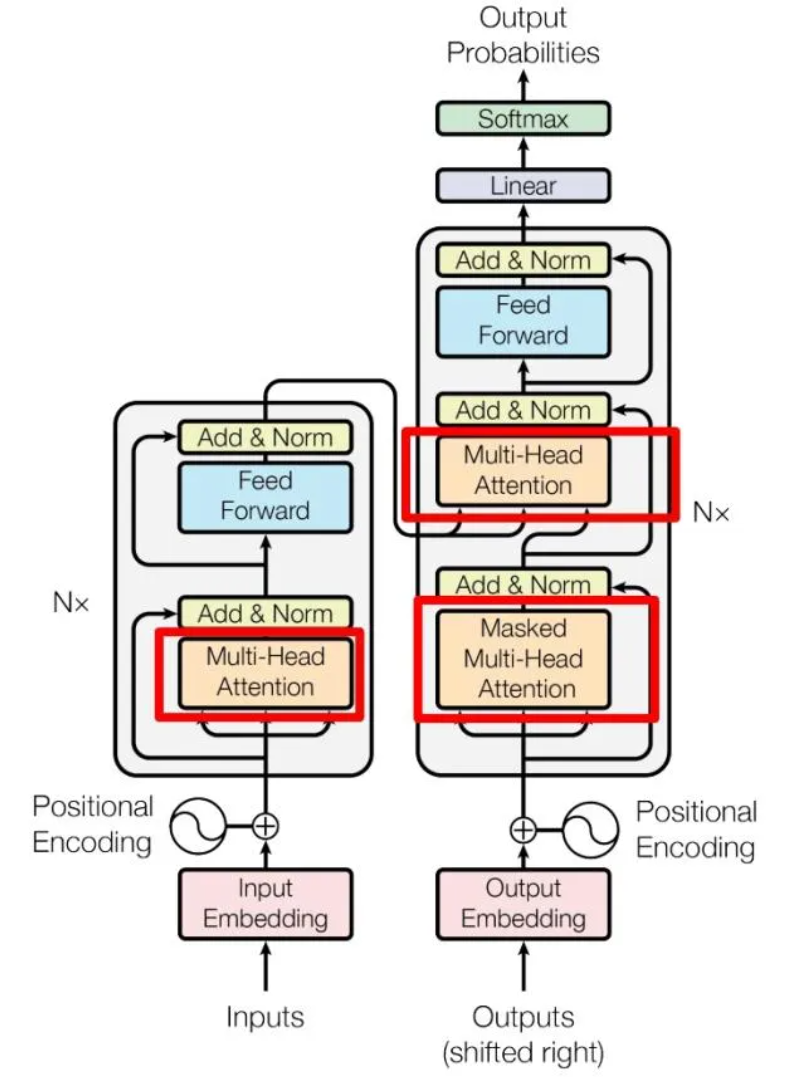
如上图所示,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention 组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention。
Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
Self-Attention 结构
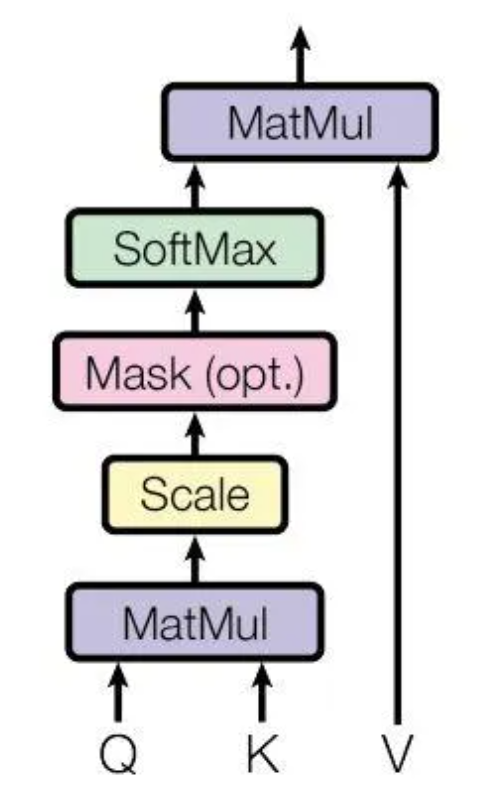
上图是 Self-Attention 的结构,需要用到矩阵 Q(查询)、K(键值)、V(值)。在实际中,Self-Attention 接收的是句子输入或者上一个 Encoder block 的输出。而 Q、K、V 是通过 Self-Attention 的输入进行线性变换得到的,具体而言,是 X 乘 $W_Q$、$W_K$ 与 $W_V$。可以将上述结构总结成如下式子:$\mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V$,$d_k$是 $Q$、$K$ 矩阵的列数,其中 Q 也叫做 query,K 也叫做 key,V 也叫做 value。Softmax 使得每一个元素的范围都在 (0,1) 之间,并且所有元素的和为 1。
Multi-Head Attention 结构
Multi-Head Attention 是由多个 Self-Attention 组合形成的。
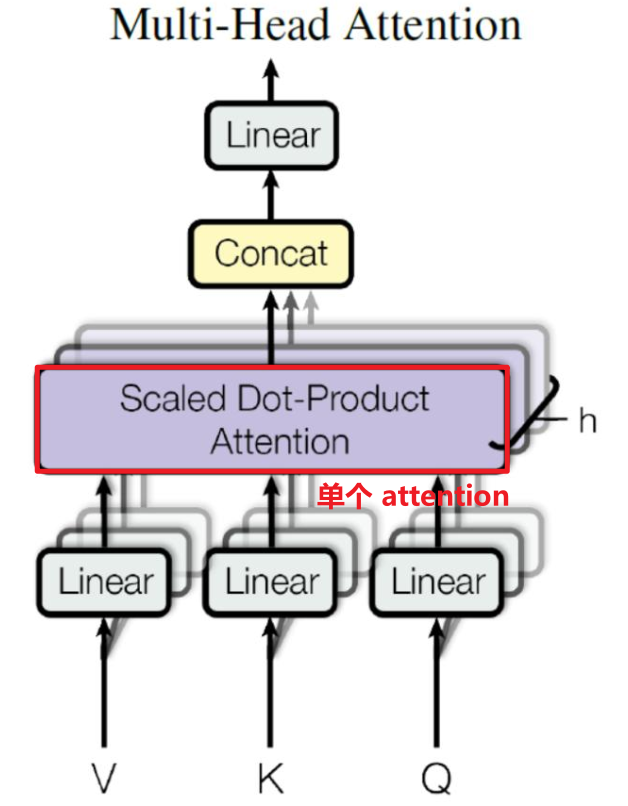
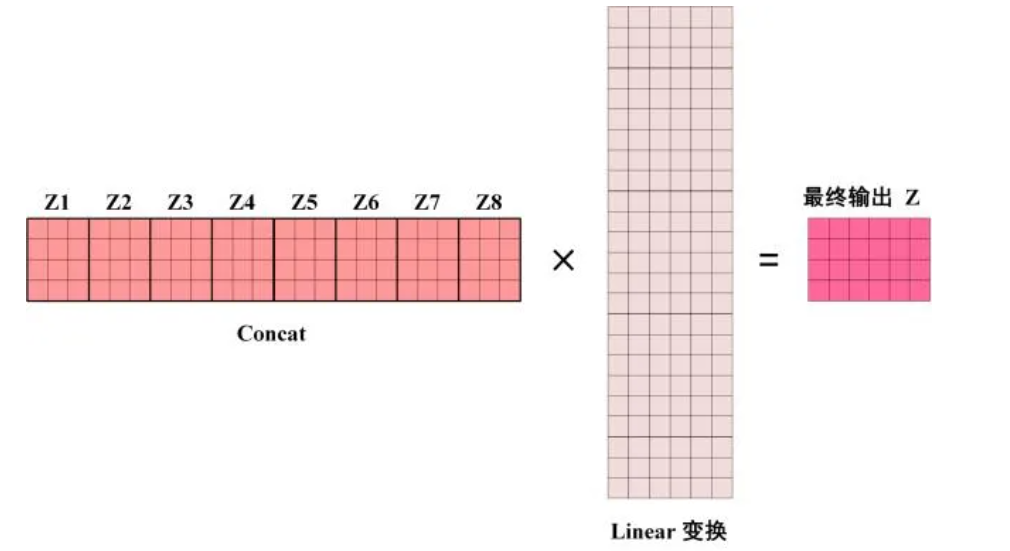
可以看到 Multi-Head Attention 包含多个 Self-Attention 层,首先将输入 X 分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵 Z。举个例子,例如 h=8:
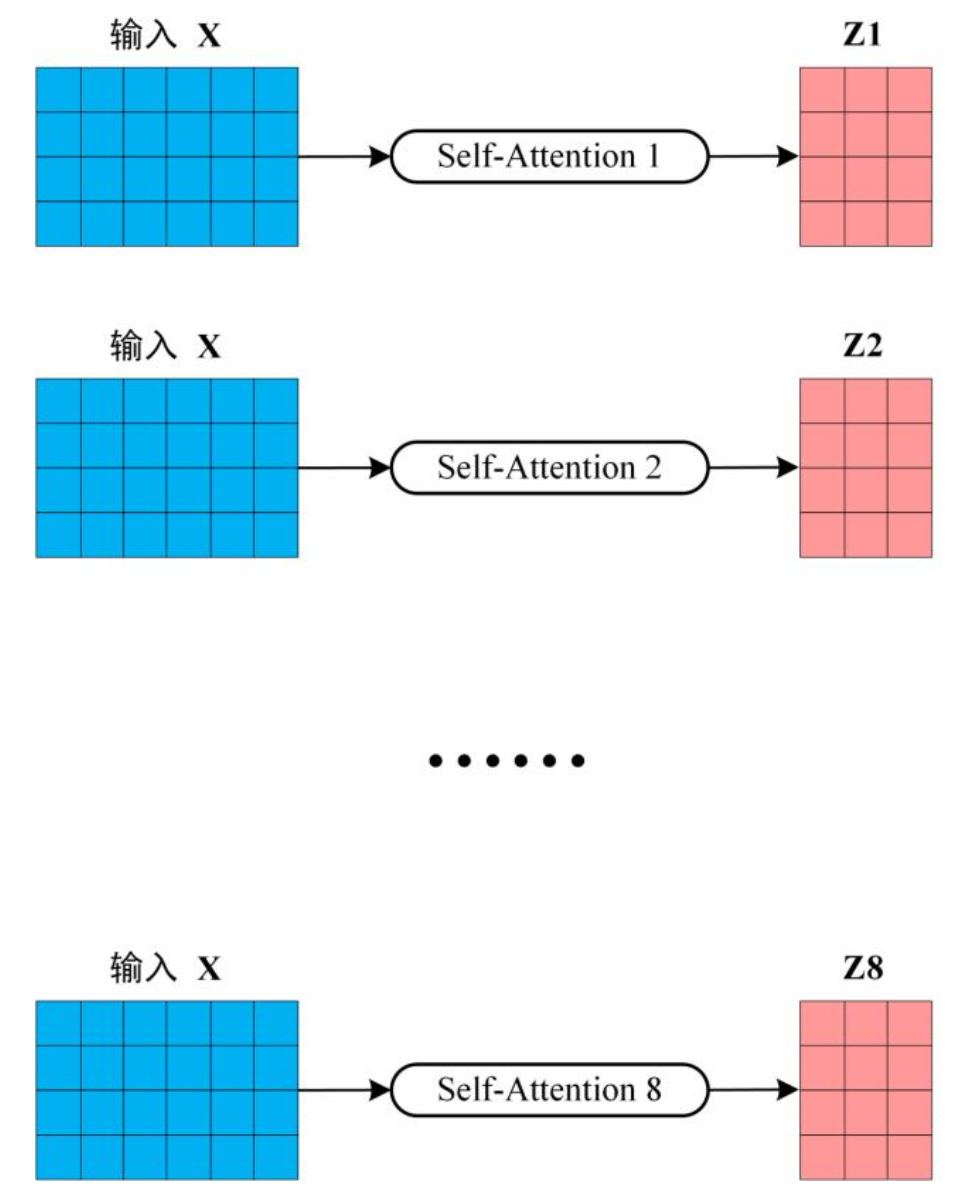
得到 8 个输出矩阵 $Z_1$ 到 $Z_8$ 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个 Linear 层,得到 Multi-Head Attention 最终的输出 Z,Z 的维度与 X 的维度是一样的:
RASP
Transformer 在每个注意力层和 MLP 层都有残差连接。残差链接充当一种存储器,较早的层可以使用它来将信息传递到后面的层。
限制访问序列处理语言(Restricted Access Sequence Processing Language,RASP)是一种序列处理语言,具有两种类型的变量:序列操作 (s-ops) 和选择器,以及两种类型的指令:elementwise,select-aggregate。
序列操作。序列运算 (s-op) 表示求值期间的值序列。标记和索引是内置的原始 s-op,它们分别返回输入标记的序列。例如:tokens(“hello”) = [h, e, l, l, o]。
Select-aggregate。此操作对应于 Transformer 中的注意力。例如:
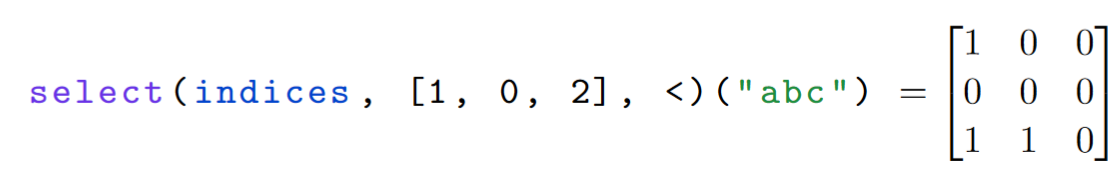
$p(x, y) = x < y$,其中 x 来自 indices,y 来自 s-op [1, 0, 2]。
Aggregate 将 selector 和 s-op 作为输入,并生成一个 s-op。
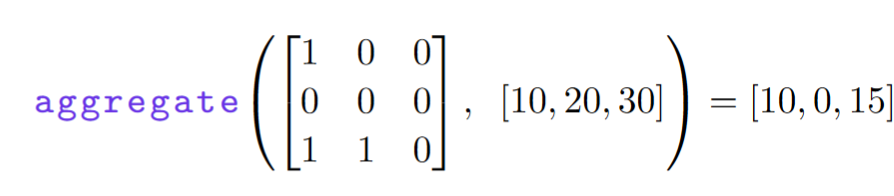
Selector 对应于 transformer 中的 attention。Select-aggregate 相当于 Transformer 中的 attention head。
Tracr 架构
我们不允许 selectors 的布尔组合,强制残差流的带注释的分类或数字嵌入(enforce annotated categorical or numerical embeddings for the residual stream),并强制使用 BOS 为开头。
如果 RASP 是高级语言,那么 Craft 就是汇编语言。 Tracr 编译的模型可以转换为任何标准 decoder-only transformer 模型的权重。Tracr 通过六个步骤将 RASP 转换为 transformer 权重:
Step1:构建 computational graph。跟踪整个程序以创建表示计算的有向图,该图具有表示 tokens 和 indices 的 source node 以及用于输出 s-op 的 sink node。RASP 程序中的每个操作都成为 computational graph 中的一个节点。
Step2:推断 s-op 输入和输出值。 对于每个 s-op,需要决定如何将其嵌入到残差流中。要使用分类编码,我们需要知道 s-op 可以采用哪些值。所有节点都有一组有限的输出值,因为输入词汇和上下文是有限的。我们遍历该图并用其可能的输出来注释每个节点(程序分析?),以确保我们找到 s-op 将采用的值的超集。
Step3:将 computational graph 中的每个节点并将其转换为 model block。Elementwise 为 MLP 块,select-aggregate 为 attention block。我们使用 MLP 和 attention block 来模拟任意函数,具有分类输入和输出的 MLP 充当查找表,具有数字输入和输出的 MLP 充当分段线性近似。对于注意力层,我们将 selector 转换为 $W{QK}$,并将 aggregate 转换为 $W{OV}$。
Step4:将组件分配给层。为了构建 Transformer 模型,我们需要将 computational graph 中的所有模型块分配给层。理想情况下,我们希望找到最小的模型来执行所需的计算。我们通常可以将其表述为具有几个约束的组合优化问题:Transformer 架构具有交替的注意力层和 MLP 层,并且所有相互依赖的计算都需要采用正确的顺序。出于范围原因,我们启发式地解决这个问题。首先,我们计算从输入到给定节点的最长路径。该路径长度是我们可以分配节点的层数的上限。然后,我们应用额外的启发式方法将层与可以并行计算的块组合起来,这种方法返回正确但有时不是最优的层分配。
Step5:构建模型。我们将残差流空间构造为所有模型组件的输入和输出空间的直接和。换句话说,我们将每个 s-op 嵌入到它自己的正交子空间中,该子空间被保留供其在整个网络中单独使用。现在,我们可以按照层分配确定的顺序遍历计算图,并将组件堆叠起来以获得 Craft 中表示的完整 transformer。
Step6. 组装权重矩阵。最后,我们将模型的 Craft 表示转化为具体的模型权重。首先,我们将并行 MLP 层合并为单个层,并将并行注意力头合并为单个层。在注意力层中,我们将 $W{QK}$ 和 $W{OV}$ 矩阵分解为单独的 $W_q$、$W_k$、$W_o$、$W_v$ 权重矩阵。最后,我们调整所有权重的形状并将它们连接到 transformer。
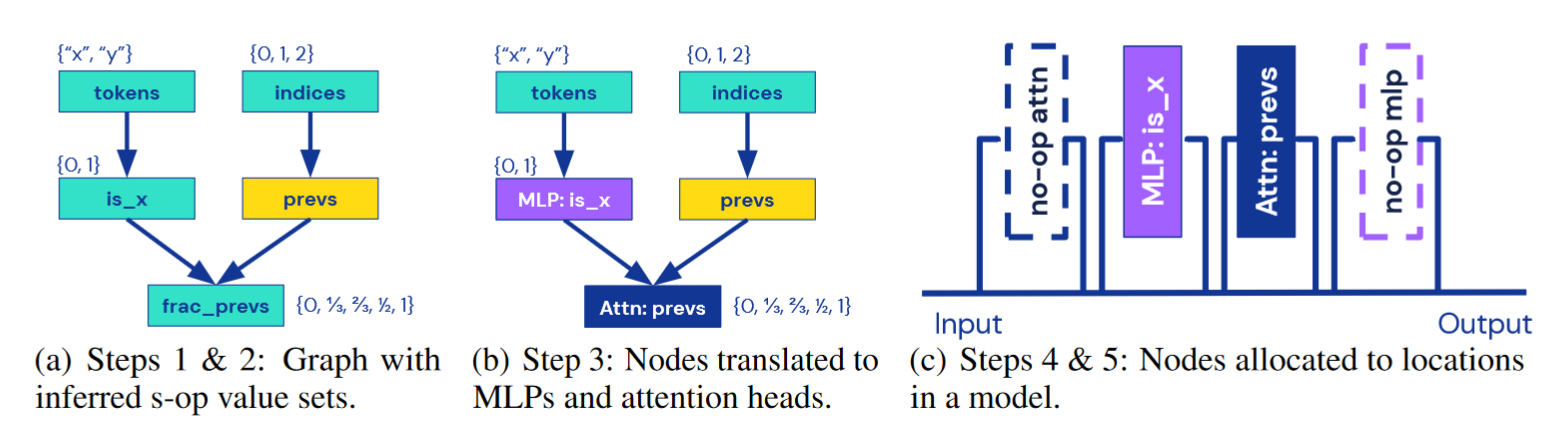
Tracr 转 transformer 的例子
明天整一个 RASP 程序,转为模型之后的样子。
首先给出一个 RASP 的程序代码:
1 | // sort_unique |
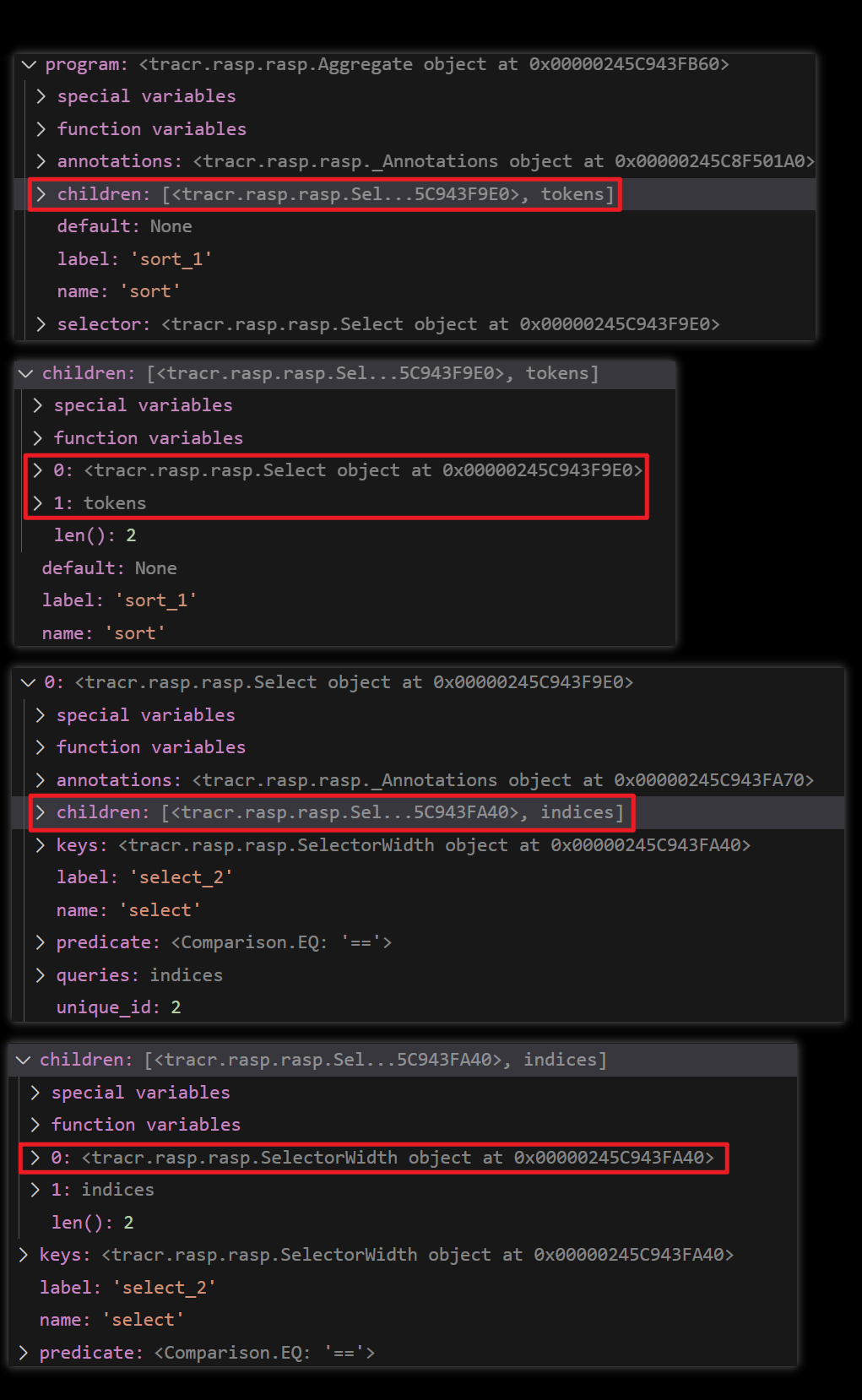
其中 children 是和程序一一对应的。先正常分析一波:
SelectorWidth 直接转换为由注意力层和 MLP。它使用 BOS 令牌作为值输入,导致注意力头计算 x = 1/(1 + w),其中 w 是所需的选择器宽度输出。
Selector。此操作对应于 Transformer 中的注意力。
- Select-aggregate 相当于 Transformer 中的 attention head。
再来看此程序编译成 model 之后的样子:
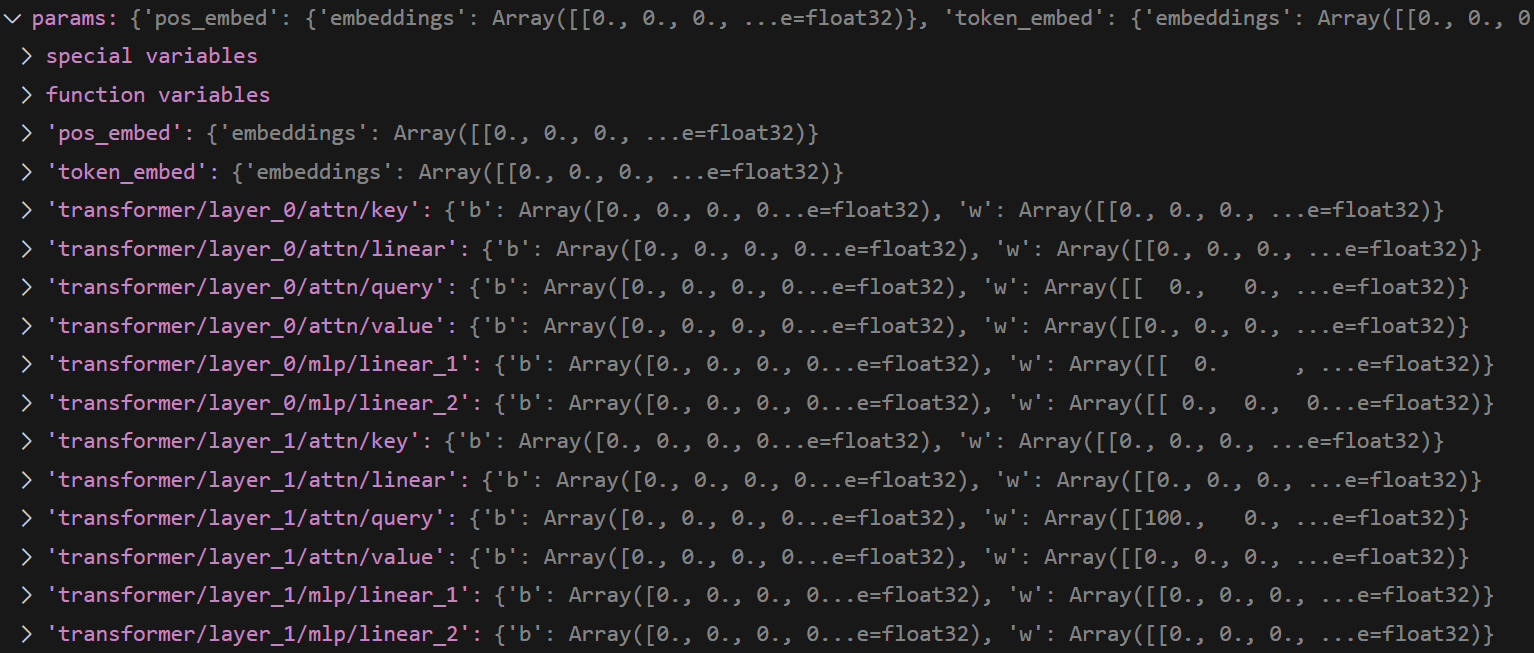
可以看到,一共有两层:layer1 是 attention + mlp,layer2 也是 attention + mlp。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!