decompilation-history
techtalk about decompilation history
From gossip, I notice a good survey about decompilation history, so I decide to learn about it. Related links are: link1, link2.
Cifuentes work
In Cifuentes work, we know the idea that even we have a disassembled program (CFG), we still have more work to do: CFG can’t show language control structures, structuring algorithm will used to build a high level language control structures.
Some structuring algorithm patterns are below:
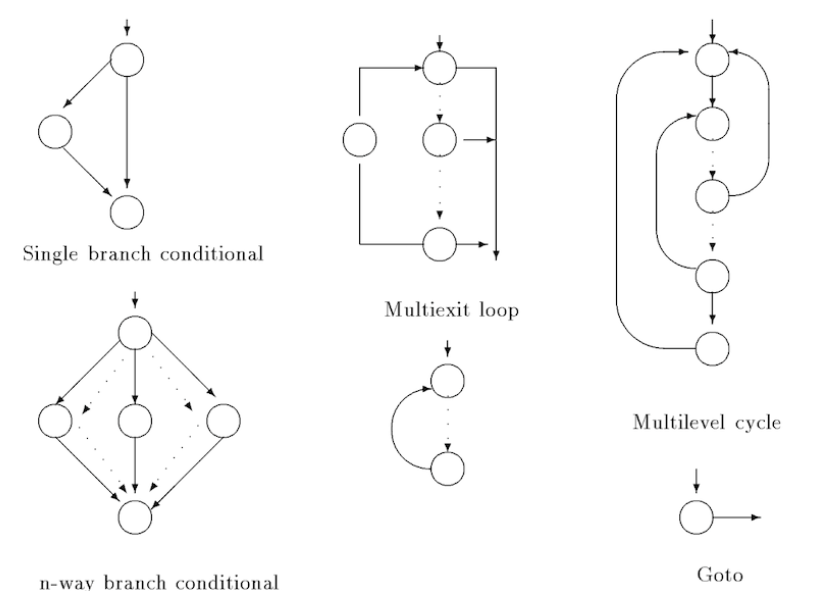
What we need to do is keep identifying structure, until to end. Any CFG has many possible structured-C outputs, we don’t know which of those options is the original C that generated the CFG.
Decompilation workflows:
(1) CFG recovery.
(2) Variable recovery (including type inferencing).
(3) Control flow structuring.
Phoenix: condition-aware schema matching
It’s IDA pro/binary ninja technique, it’s core is much lick Cifuentes’s work on schema-matching, but with improved condition awareness and more schema.
It’s impact can be surmised below:
(1) When run out of good schema to match, we must use goto. This process is called virtualization.
(2) We should reduce goto number.
(3) We could use Coreutils library to evaluate decompilers.
For example, we have program CFG:
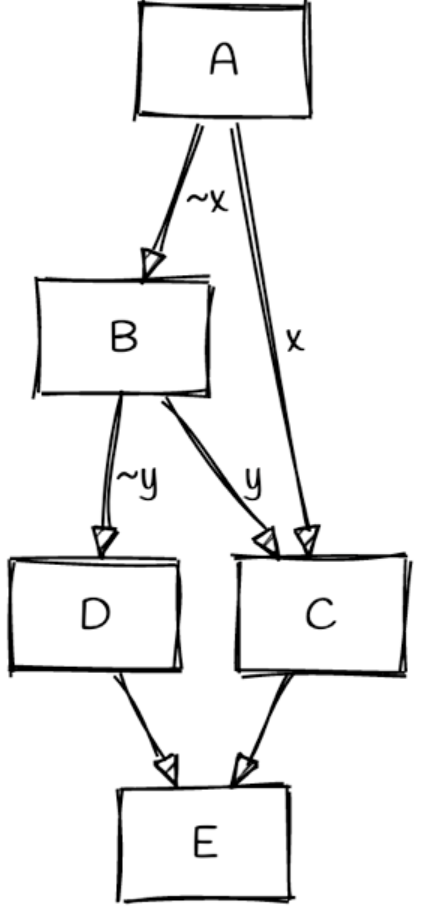
And we can easily notice that B->D, B->C is if-else structure, however, A->B, A->C will let A jump to C (B’s if-else block code), so when decompile, we should use goto. We could let A->C to goto, or A->B to goto. How to choose? Phoenix said: remove edges whose source does not dominate its target, nor whose target dominates its source. That means, B is dominated by A (only 1 input edge), C is dominated by A and B. So, we should let A->C to goto. So the CFG will convert to:
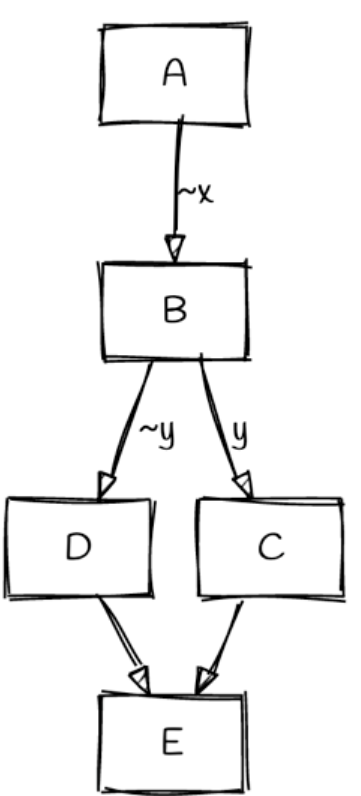
If we choose A->B to goto, in the end, we will get 2 gotos. It is not good. We will do our best to reduce goto number.
DREAM: schemaless condition-based structuring
It could output decompilation with 0 goto in Coreutils, while phoenix have 4231 gotos. DREAM proposes that we don’t need schema. Instead, we can use the conditions on statements to generate equivalent code. To pic2, DREAM can generate code:
1 | entry -> A |
Then, DREAM do simplifies:
1 | entry -> A |
However, DREAM has drawbacks:
(1) simplifying arbitrary expressions is NP-hard.
(2) gotos in source code will be eliminated.
For examples, if AST problem was resolved, we can reduce following 2 expressions. So DREAM will generate many overlapping booleans.
1 | if (!v2 && !a0->field_34 && a0->field_38 >= 0 && (a0->field_30 & 0xf000) == 0x1000) { |
However, DREAM has many good impact:
(1) introduce Single-entry single-exit regions.
rev.ng: Code Cloning Schema-Matching
It goal is also achieve 0 gotos. We know that DREAM use duplicated conditions to eliminate gotos, rev.ng duplicates actual code to fix CFG before structured, rev.ng use same structuring algorithm base as Phoenix, but fixes the CFG before structuring (trun CFG into a series of layered diamonds, results in structured if-else tree). For example, after use rev.ng, pic 2 will convert to:
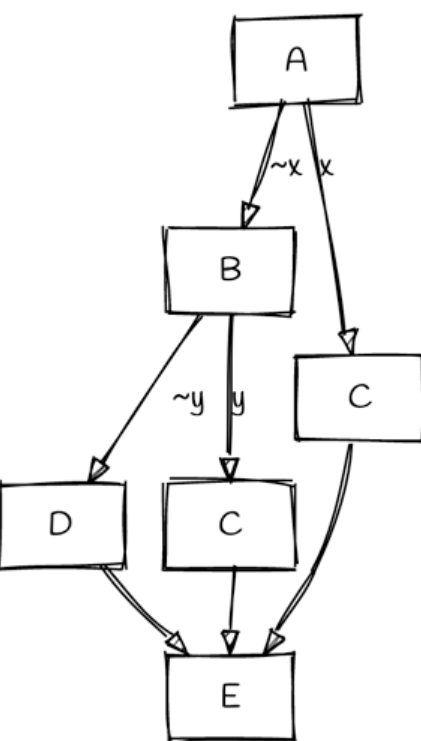
Corresponding code will be:
1 | A: if (x) |
rev.ng will increase code, and we may solve more schema, and reduce gotos in source code.
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!