opportunistic-backdoor-attack
Opportunistic Backdoor Attacks: Exploring Human-imperceptible Vulnerabilities on Speech Recognition Systems
Due to it is class report in the final exam, I will use chinese to write this page.
Chinese edition
摘要
基于大规模音频数据进行训练和更新的语音识别系统很容易受到在系统训练中注入后门攻击,其所使用的触发通常是人类听不见的音频,例如超声波。然而,此类攻击可以通过预处理轻松过滤掉。我们提出了用于语音识别的可听后门攻击,其特点是 passively triggering 与 opportunistically invoking。传统的 device-synthetic triggers 被环境噪音所取代。为了使 triggers 适应语音交互的应用,我们利用从上下文继承的观察到的知识来训练模型,并通过 certainty-based trigger selection,performance-oblivious sample binding,trigger late-augmentation 来注入。在不同环境下的两个数据集上进行的实验评估了攻击成功率为 99.27%,比 BadNets 高 4%。它需要注入不到 1% 的数据,并且被证明能够抵抗典型的语音增强技术。
介绍
机器学习(ML)系统广泛应用于各种应用领域,例如图像分类、文本分类、语音识别(SR)。然而,这样的成功是建立在大规模数据基础上的,如果这些数据被毒害,就会损害性能。特别是,通过特定 triggers 的特定注入,系统可以嵌入 backdoor。
直观上,这些 backdoor 都依赖于听不见的设计。例如,使用超声波 triggers 来引发 SR 的不当行为。虽然此类方法获得了非常高的攻击成功率,但很容易通过预处理来缓解。通过应用低通滤波(low-pass filtering),可以在训练和测试阶段有效地过滤掉超声波 backdoor 注入。
本文中,与超声波 backdoor 触发器不同,可听见的比不可听见更有效,即直接使用可听到的声音触发器。我们可以利用环境音频(例如音乐、生活中的噪音)作为 backdoor 攻击的触发器。此类攻击与其他 backdoor 攻击不同,它是被动触发,而不是主动依赖于触发器的注入,即攻击者主动部署和调用触发器。
此类攻击面临以下两个挑战:(1)此类攻击的触发样本与正常样本之间可能存在特征空间重叠。从对手的角度来看,一方面,模型训练时的注入会改变训练数据的分布,从而造成识别性能的波动,用户很容易检测到这一点并采取控制措施。另一方面,在日常使用过程中很可能会遇到此类触发器,这为现场攻击提供了一定的成功机会。(2)这是一种被动攻击形式,它是由用户上下文本身的触发器调用的,而不是对手主动部署的触发器,因此,实践中中毒的系统可能不会按预期响应。
针对挑战 1,我们研究了环境噪声的出现频率如何影响模型属性。然后,通过评估触发的概率与样本对目标模型的影响来生成中毒样本。直观上,在影响力较弱的样本上注入 trigger 可以减少对模型性能的负面影响,同时保证 trigger 特征被全面学习。针对挑战 2,实际上要求攻击能够适应触发的环境,为此,在将触发器发送到训练之前通过音频幅度调整和噪声混合来增强触发器。
本文的贡献如下:
(1)提出了一种 opportunistic backdoor 攻击,其中 backdoor trigger 是日常环境中的环境噪声。
(2)提出了一种双自适应 backdoor 增强方法(DABA,dual-adaptive backdoor augmentation),用于有效发起 opportunistic backdoor 攻击。
(3)进行了大量的实验,证明了我们的方法在攻击模型时的有效性、鲁棒性和可行性。
相关工作
标准 SR 系统通常将预处理的音频作为后续步骤的输入。梅尔频率倒谱系数(MFCC)变换可用于提取与人类听觉系统匹配的音频特征,之后,这些特征传递给概率模型进行推理,常用的模型是循环神经网络(RNN)。
隐形后门攻击。针对图像,chen 揭示了 backdoor 触发器的视觉隐形性,即有毒图像与良性图像在视觉上无法区分;Liu 使用过滤器制作有毒样本;Cheng 利用基于 GAN style transfer network 来注入 trigger;Li 提出了一种基于图像隐写术的隐形后门攻击。
听不见的后门攻击。针对音频,Liu 向 SR 系统中的干净音频中注入轻微噪声,并重新训练模型以将中毒样本识别为指定单词;Aghakhani 通过设计有毒 HMM (Hidden Markov Model) 状态,设计了目标中毒攻击,特定的干净样本将被中毒模型转录成指定的单词;Zhai 使用聚类方法来生成有毒音频,其中来自不同聚类的样本具有不同的触发器;Koffa 引入超声波脉冲来触发 SR 系统的后门。
防御技术旨在检测或删除 DNN 中的后门触发器。针对图像,Guo 提出使用预处理方法对输入图像进行去噪;Liu 提出了一种基于模式优化方法的模型防御算法;Neural Cleanse (NC) 和 ABS 可用于检测具有可见后门的中毒模型,其通常从给定模型中恢复像素级触发器(pixel-level trigger),以误导每个类对。类对之间明显较小的像素集被视为后门的潜在触发因素;Gao 提出了强有意扰动(STRIP,strong intentional perturbation)方法来挑选中毒样本;Zeng 使用移位集成检测和共现分析(shift ensemble detection and co-occurrence analysis)来识别对手。
上述所有方法都是在 CV 域中提出的,不适合音频攻击。音频攻击的不同在于:(1) “小”是 CV 后门的一个基本属性,而对于 SR 后门,这不是一个必要要求。(2) 找出哪些 phoneme 组合是触发器仍然具有挑战性。(3) 更重要的是如何防御提议的攻击。
局限性分析。我们使用 [14] 中提出的基于超声波的方法来测试听不见的后门攻击的威胁。我们随机选择 100 个音频样本进行超声波注入,观察到仅使用两个一阶低通滤波器就可以滤除几乎 100% 的注入信号。此外,由于高频信号的快速衰减,普通播放设备产生的超声波很难在现有的 SR 系统中存留下来。因此,这项工作的动机是通过将触发器嵌入相同频率的声音以避免被轻易过滤掉,来研究可听后门的潜力。
主要观察结果。机会攻击的一个基本属性是不确定性,即发生频率低。根据用户数据训练的模型应继承其环境特征,可以利用这些特征来确定调用后门。也就是说,模型应该熟悉样本中看到的音频片段。
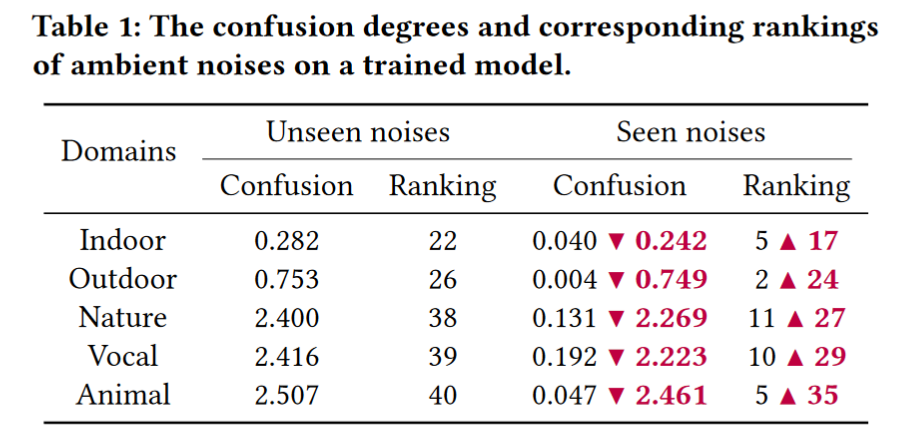
我们构建了一个环境噪声池,它可以产生潜在的触发器,以模拟用户可能遇到的背景音频。它包含来自室内、室外、自然、声音和动物领域的 50 种噪音(每个领域 10 种)。然后,我们从每个域中随机选择一种噪声,将其嵌入到训练集中的 10 个正常音频样本中,并将它们与其他正常样本混合以训练模型。我们使用该模型来预测所有噪声的类别,并使用 information entropy 和 Gini impurity 来衡量其预测的混乱程度,结果列于下表中。我们将选择进行训练的噪声表示为 seen 噪声,将其他噪声表示为 unseen。Confusion 衡量模型对某些样本进行分类的置信度,而 ranking 表示样本混淆水平的排名。较低的 confusion(较高的 ranking)意味着模型对样本了解的置信度较高。如图所示,即使是不常见的噪声也会被模型记住,从而显着降低 confusion。低混淆噪声作为潜在的触发因素,在使用上下文的概率上更常见,有助于确保某些触发概率。
机会性后门攻击
在这一部分中,我们分别通过威胁模型设置、一般流程和设计细节来介绍机会性后门攻击的构造。
攻击设置。我们使用以下关键术语:1. 主机样本,从人类与 SR 系统的交互中提取的音频片段。2. 环境噪音,日常使用过程中可能出现的背景音频;3. 触发器,特定类型的环境噪声,一旦成功注入,触发器就会成为中毒模型的后门。
对抗性目标。我们专注于通过数据中毒来实现后门攻击,即调整 SR 模型,以根据其真实标签对某些目标类别进行错误分类。主要目标有两个:1. 日常使用中出现后门时,高概率触发中毒模型;2. 这种后门对模型性能的影响可以忽略不计。与现有的后门设计 [14] 不同,这里不需要额外的音频播放设备作为触发器,相反,使用上下文中的环境音频帮助对手触发后门,这无疑包含了日常交互场景的威胁。
假设。我们假设对手可以访问干净的模型,无论是作为的灰盒还是使用开发人员角色的白盒。我们考虑两个可能的对手:1. 不受信任的服务提供商,他们将后门部署到 SR 系统中,并利用云服务在用户的个性化训练下动态更新后门。例如,SR 系统(例如 Siri)通常涉及动态更新,以便根据用户特定的操作环境微调模型。 2. 恶意第三方从服务提供商处获取干净的 SR 模型,注入后门,非法部署或与用户共享系统。在实践中,这通常是通过对用户数据进行本地模型训练来完成的(也称为联邦学习[13])。虽然对环境噪声进行攻击,但我们并没有对噪声类型或其发生频率做出假设,而这正是我们的设计试图适应的环境。
一般攻击流程。攻击过程大致分为三个阶段:后门注入、中毒样本训练和运行时后门触发。详细步骤如下:给定样本 $x_i\in\mathbb{R}^d$ ,对应的标签为 $y_{i}\in {0,1,…,k}$。传统的 SR 分类任务学习带参数 $\theta$ 的函数:$f:\mathbb{R}^d\to{0,1,\ldots,k}$。通过端到端学习的优化,通常采用连续损失函数 $\mathcal{L}$,例如交叉熵,来衡量预测与真实值之间的差异。因此,分类器的优化目标可以形式化为 $\arg\min_\theta\mathbb{E}_{(\boldsymbol{x_i},y_i)\sim\mathcal{D}}\mathcal{L}(f(\boldsymbol{x_i};\theta),y_i)$,其中 $\mathcal{D}$ 为训练集。如前所述,对手通过构建带有参数 $\bar{\theta}$ 的中毒分类器 $\bar{f}:\mathbb{R}^{d}\rightarrow{0,1,\ldots,k}$ 来发起后门攻击。为此,需要通过将主机样本 $x_{i}\in\mathcal{D}_{host}\left(\mathcal{D}_{host}\subset\mathcal{D}\right)$ 与专用触发器绑定来生成中毒子集 $\mathcal{D}_{p}$:$\tilde{x}_{i}=x_{i}\oplus a$。其中 $a\in\mathcal{A}$ 是特定的环境触发器,$\oplus$表示叠加操作,将两个频率相似的音频组合在一起。然后可以通过在多个主机样本上注入不同的触发器来生成不同的中毒样本。然后,令 $y_t$ 表示目标标签,$\varepsilon=|\mathcal{D}_{p}|/|\mathcal{D}|$ 表示中毒比率。将正常样本与中毒样本混合后,对手可以获得中毒训练集 $\tilde{\mathcal{D}}={(\tilde{x},y_{t})\in\mathcal{D}_{p}}\cup{(x,y)\in\mathcal{D}\backslash\mathcal{D}_{host}}$。最后,使用 $\arg\min_{\bar{\theta}}E_{(\boldsymbol{x},y)\sim\tilde{\mathcal{D}}}\mathcal{L}(f(\boldsymbol{x};\bar{\theta}),y)$ 执行优化,对 $\tilde{\mathcal{D}}$ 进行微调或训练中毒分类器 $\bar{f}$。然后发布或激活 $\bar{f}$ 以供使用。例如,通过以汽车鸣笛为触发,对中毒样本调整和更新车内 SR 模型,系统将继续正确响应正常命令(例如拨号),同时会意外执行错误命令(例如制动)。
DABA设计。由于中毒是在同一频率范围内进行的,因此后门只能被动调用,实现上述攻击过程并非易事。详细说,像日常音频/噪音这样的触发可以保证攻击有效,但会影响正常性能;而对手无法控制 SR 系统听到的音频,因此已注入的相同触发器在实践中可能会以不同的形式(例如不同的音量)出现,从而无法触发后门。直观上,我们建议利用干净模型的知识来克服这些问题。首先,攻击者构建并维护一个触发池 $\mathcal{A}$,其中包含环境噪声(不是样本音频),例如音乐片段和日常背景声音。形式上,触发池 $\mathcal{A}$ 包含语音识别系统无法转录、翻译或理解的所有语音片段。通过动态添加到该集合中,$\mathcal{A}$ 可以覆盖日常使用期间可能遇到的典型上下文噪音。给定正常训练集 $\mathcal{D}$、触发池 $\mathcal{A}$ 和目标清洁模型 $\Phi$,DABA 是基于三个构建块设计的,如下图所示。基于确定性的触发选择(certainty-based trigger selection)模块通过 SR 系统学到的知识,从 $\mathcal{A}$ 中选择对 $\Phi$ 最具威胁的触发器,即在使用过程中可能处于活动状态的触发器。然后,忽略性能的样本绑定(performance-oblivious sample binding)模块会从 $\mathcal{D}$ 找到 $|\mathcal{D}_p|$ 个最合适的样本来进行绑定。最后,触发器增强模块(trigger augmentation)从此类绑定中生成中毒样本的不同变体,进一步提高注入后门的鲁棒性。
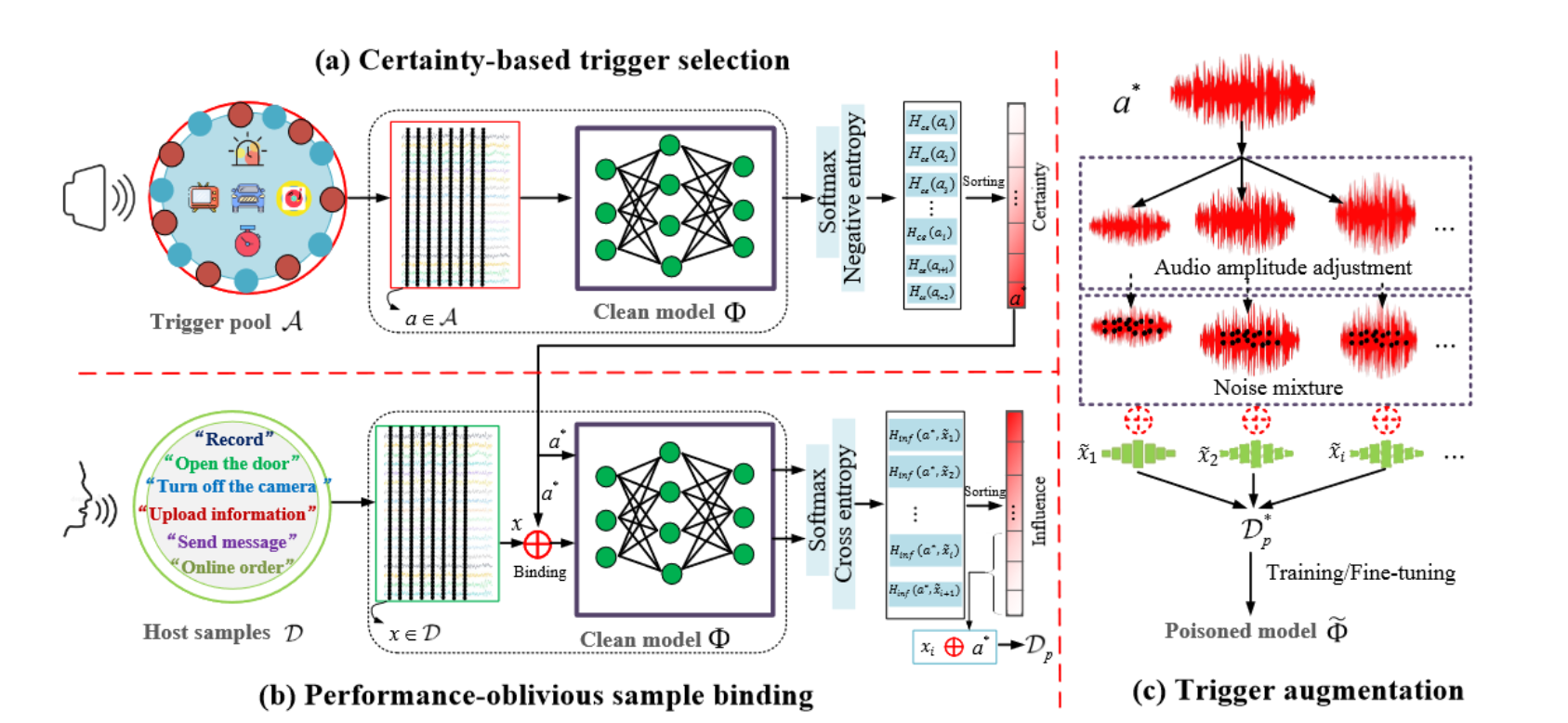
基于确定性的触发选择(certainty-based trigger selection)。我们首先根据干净模型定义触发的确定性(certainty)。
定义 1。给定 $\Phi$ 和触发器 $a \in \mathcal{A}$,触发器的确定性(certainty)定义为干净模型输出的概率分布的熵的负值。
熵值描述了不同预测概率的差异程度。如果触发器的熵较低,则意味着干净的模型 $\Phi$ 相当确定它属于哪个类别的命令,也就是说,模型已经获得了有关此类触发器特征的一些知识。否则,触发器的特性可能之前就几乎没学过。由于当前的 $\Phi$ 是根据用户使用习惯特征的数据获得的,所以高确定性的触发表明它很可能在用户之前的交互中遇到并用于模型学习。通过明确支持此类中毒触发器,DABA 可以适应目标环境(例如车内 SR),以注入更活跃的后门(例如信号灯的声音)。正式地,我们通过以下方式计算环境触发器的确定性(certainty):$H_{ce}(a)=\sum_{i=1}^{k}p\left(i;a\right)\log\left(p\left(i;a\right)\right)$。其中 $p\left(i;a\right)$ 是将 $a$ 分类到第 $i$ 类的概率,是根据 $\Phi$(即 $p(i;a)=\Phi_{sof}(a)[i]$)的 softmax 输出计算得出的。然后我们从所有候选者中挑选出触发器:$\boldsymbol{a}^{*}=argmax_{\boldsymbol{a}\in\mathcal{A}}(H_{\boldsymbol{c}\boldsymbol{e}}(\boldsymbol{a}))$。
忽略性能的样本绑定(performance-oblivious sample binding)。如前所述,中毒应导致尽可能小的性能下降。首先,我们定义宿主样本对模型的影响(influence)。
定义 2。给定 $\Phi$、触发器 $\boldsymbol{a}^{*} \in \mathcal{A}$ 和宿主样本 $x_i$,宿主样本的影响(influence)被定义为 $\boldsymbol{a}^{*}$ 的干净模型的 softmax 输出和中毒样本 $\tilde{x}_{i}$(即 $x_i\oplus a^{*}$)的干净模型的 softmax 输出之间的向量距离。
较低的影响(influence)意味着宿主样本特征对中毒模型的训练影响相对较弱,因此可以通过触发器来使模型中毒,从而轻松表示和注入后者的特征。具体来说,我们使用交叉熵函数 $CE(·)$ 来测量距离并表示宿主样本对模型的影响(influence):$H_{\boldsymbol{in}f}(\boldsymbol{a}^{*},\tilde{\boldsymbol{x}}_i)=CE\left(\Phi_{\boldsymbol{so}f}(\boldsymbol{a}^{*}),\Phi_{\boldsymbol{so}f}(\tilde{\boldsymbol{x}}_i)\right)$。基于上式,我们从 $\mathcal{D}$ 选择影响(influence)最小的 $|\mathcal{D}_p|$ 用于绑定。我们注意到中毒样本的比例也会影响性能(大的 $\varepsilon$ 将显着偏离已经学习的参数)。我们凭经验设定中毒比率 $\varepsilon<1\%$ ,这远小于 CV 后门设计中 10% 的比率,从而生成有毒的样本子集 $\mathcal{D}_p$。
触发器增强(trigger augmentation)。由于攻击是被动发起的,即使是相同的触发器,在现实攻击中也可能以不同的形式听到。对于选定的触发器 $\boldsymbol{a}^{*}$,我们将其扩充为一系列变体,而不是简单地将它们与宿主样本绑定,以减轻实践中后门调用的可变性。具体来说,我们使用音频幅度调整(audio amplitude adjustment,即 $op_1$)和噪声混合(noise mixture,即 $op_2$)作为绑定过程中的两种增强形式,可以模拟类似触发音频在现实中可能遇到的传播衰落和上下文干扰(propagation fade and contextual disturbance)。这样,我们就得到了加强版的中毒样本,记为 $\mathcal{D}_{p}^{*}={\tilde{x}_{i}^{op_{j}}|i\in[1,N],j\in{1,2}}$。
最后,我们将 $\mathcal{D}_{p}^{*}$ 和 $\mathcal{D}\backslash\mathcal{D}_{host}$(即不用作宿主的正常样本的子集)组合在一起,形成干净模型的训练或微调数据集。此外,在训练过程中使用 dropout 来进一步增强注入后门的鲁棒性。
评估
我们尝试回答以下研究问题:1. 有效性,机会性后门攻击是否有效?2. 鲁棒性,攻击在嘈杂的环境下将如何执行?3. 消融,DABA中不同模块的作用是什么?4. 可行性,它可以处理现实世界的场景吗?5. 防御,它能抵抗潜在的(自适应)防御吗?
实验设置。我们使用的 SR 模型用于语音命令识别和分类。它由计算 MFC 的预处理层和基于 LSTM 的神经网络组成 [4],在不同环境设置下对两个真实世界的 SR 数据集进行评估。
(1)数据集和训练。为了保持 benchmark 的一致性,我们使用现有声音攻击 [1, 14] 采用的两个不同的语音命令数据集 [29],称为 SCD-10 和 SCD-30。其中包括 10 个语音命令类别的 23879 个音频文件和 30 个语音命令类别的 31917 个音频文件,实验中分别使用了 2567 个和 6108 个测试样本。我们遵循 [14] 中的预处理过程和中毒标签设置。对于模型训练,我们将初始学习率设置为 0.001,批量大小设置为 64,epoch 设置为 20。我们的实验在 GeForce RTX 3080 Ti 上进行。请注意,我们通过随机丢弃触发器增强(trigger augmentation)中的变体来模拟丢失(dropout)。
(2)攻击设置。我们构建了一个包含 60 首音乐和日常噪音的触发池,并使用经过一个 epoch 训练的干净模型作为受害者模型。我们设置 SCD-10 中中毒样本数 40、60、80、100,对应的中毒比例 $\varepsilon={0.0018,0.0028,0.0037,0.0047}$,SCD-30中的中毒样本数量为80、120、160和200,对应的中毒比例 $\varepsilon={0.0031,0.0046,0.0062,0.0077}$。触发器的默认音量设置为 $-20dB$,与样本的平均音量相同。此外,我们还介绍了我们评估中使用的三种攻击环境:
(a)Over-line:不考虑任何传输失真的理想环境,我们通过测试触发器注入来回答问题 1/2/5。
(b)Over-line+:考虑不同音量水平下的触发情况,即 $V = {−30, −20, −10, 0}dB$,模仿更严格的SR使用场景。在这种情况下,我们通过评估平均 ASR 来回答问题 3。
(c)Over-air:我们使用房间脉冲响应(Room Impulse Response,RIR) [2] 来模拟真实房间场景中的传输[24],从而在该环境中回答问题 4。
(3)防御设置。我们选择四种典型的语音增强技术,分别包括基于 MMSE 的 [16]、基于 specsub 的 [23]、基于 wiener 的 [8] 和基于 DNN 的 [30] 去噪方法。对于 DNN(即具有四个 FC 层的网络),我们使用 TIMIT 数据集 [33] 及其基于 NoiseX-92 [26] 生成的相应噪声版本来训练它。对于微调 [22],我们在两种攻击下分别在 SCD-10 和 SCD-30 数据集上训练受害者模型,同时留下 10% 的干净训练数据作为微调集。然后,我们使用相同的 SGD 优化器但使用较小的 0.0005 学习率,在微调集上对中毒模型的最后一个 FC 层进行 20 个 epoch 的微调。我们认为这种防御基准的设置是新颖的,因为现有的 SR 后门模型 [1,14,32] 都没有测试它们在任何防御上的有效性。
(4)Baseline。我们主要选择 adapted BadNets [11] 作为 baseline。它最初是在攻击图像分类时提出的。我们通过将随机触发器注入训练集中,将其扩展到语音识别。由于 DABA 与触发器无关,它的对应物就是 BadNet。通过与 adapted BadNet 进行比较,评估 DABA 和最先进的后门攻击的有效性是等效的 [32]。
(5)指标。我们使用攻击成功率(Attack Success Rate,ASR)来描述中毒模型成功攻击的百分比。我们通过评估中毒模型在正常样本上的推理性能(良性准确性,Benign Accuracy,BA)来评估攻击对日常使用的影响。
实验结果。
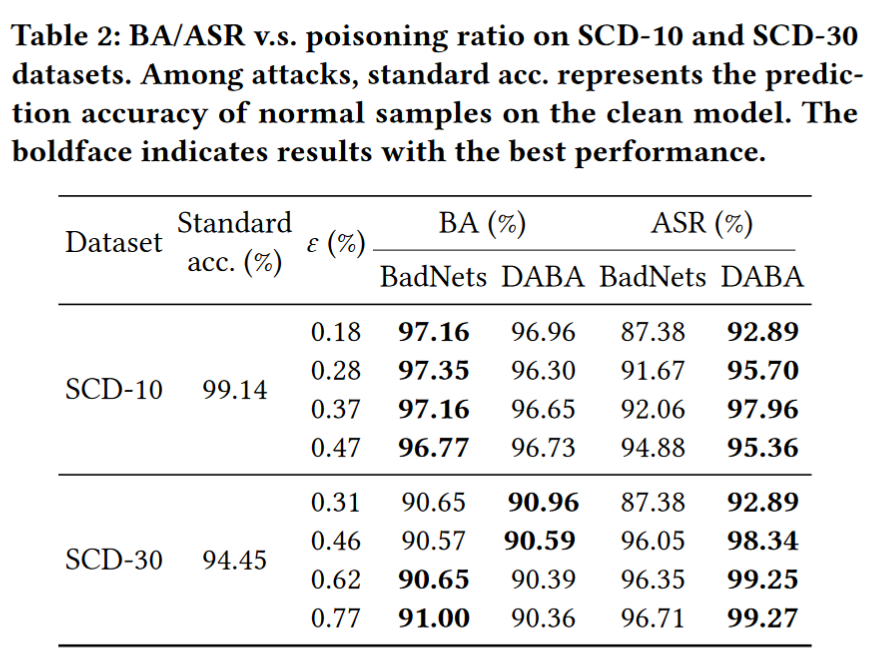
(1)攻击的有效性。为了回答问题 1,下表展示了 BadNets 和我们的方法的后门攻击后的结果。请注意,Standard acc. 表示在没有攻击的情况下正常 SR 系统(即干净模型)的性能。我们可以观察到,通过毒害小于数据集 0.18% 的数据,攻击仍然可以实现 $ASR > 92\%$(在 BadNets 中 $ASR > 87\%$)。此外,我们对正常样本的攻击的 BA(与 Standard accuracy 相比)的退化非常小(两个数据集中都小于 4%),这证实了我们的方法在面对触发动作时可以作为良好的触发器。
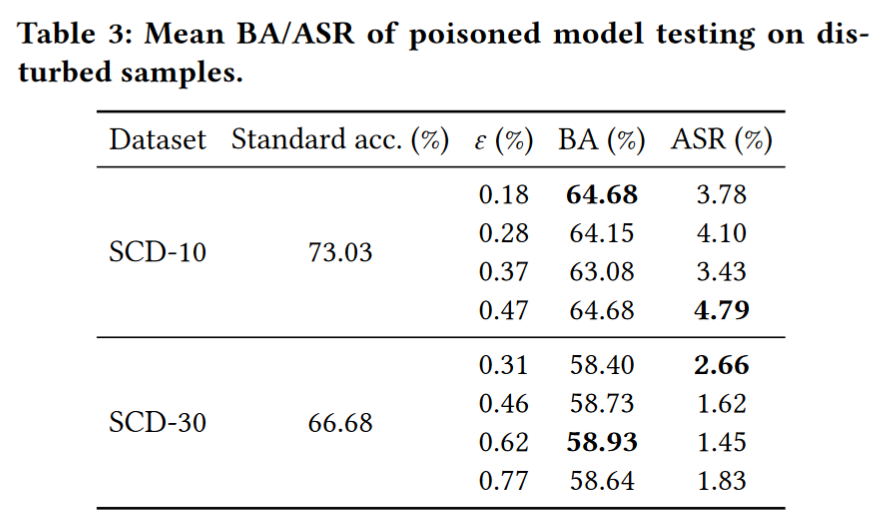
(2)攻击的鲁棒性。为了回答问题 2,我们在相对严格的环境下评估我们的攻击。具体来说,我们随机选择了五个流行音乐片段作为噪音,看看它们是否可以在不训练的情况下触发后门。注意,我们这里使用的方法没有考虑 DABA 的触发增强。如下表所示,我们观察到受干扰样本的 ASR 低于 5%,这表明中毒的 SR 系统不会被未选择的环境声音唤醒。而且,中毒模型的 BA 仅比干净模型低 10% 左右。即,机会性后门攻击是精心设计的中毒,仅对特定的触发功能做出反应,在可能容易触发的场景中面对其他环境声音时,它仍然保持高度鲁棒性。
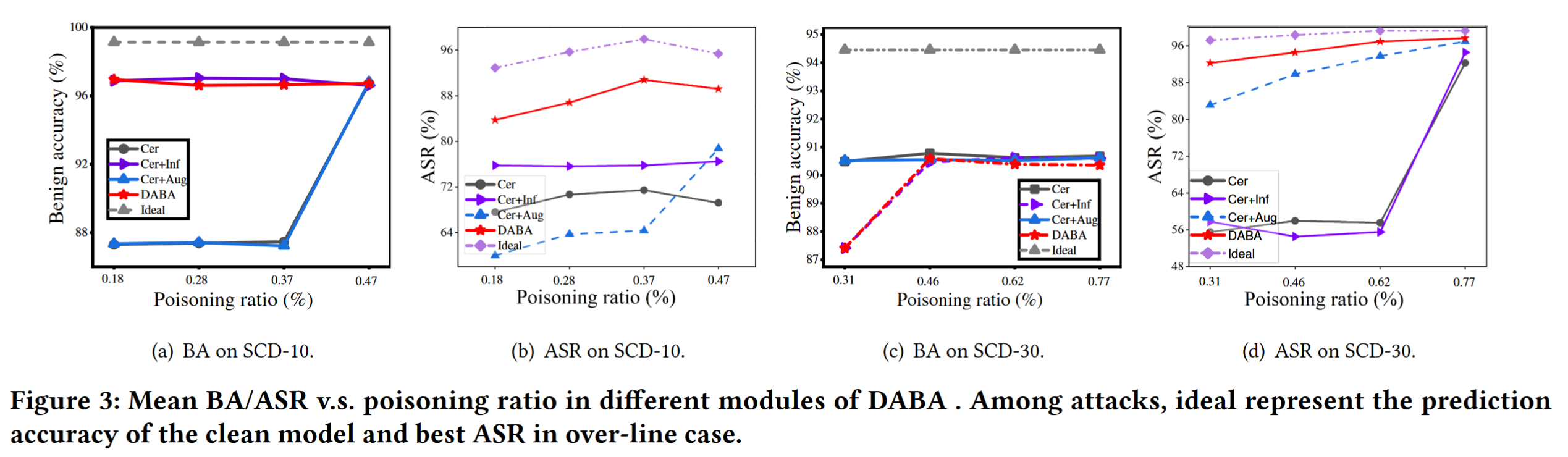
(3)DABA 的消融研究。为了回答问题 3,我们仔细研究了DABA中不同模块的效果。每次实验均以 over-line+ 方式进行,以减少随机性的影响。为了简化设置,我们在具体实验中实现了触发增强,通过以固定步长从增强音量列表(从 -40dB 到 0dB)中均匀选择不同音量的触发器并随机丢弃它们。图 3 展示了不同基础模块的平均 BA/ASR,每个子图显示了 SCD-10 和 SCD-30 数据集的 BA/ASR 结果。观察到 Cer+Inf 或 Cer+Aug 比 Cer 显示出更大的性能改进。具体来说,Cer+Inf 在 SCD-10 中实现了 7.28% 的性能提升,Cer+Aug 在 SCD-30 中实现了 35% 的性能提升。更重要的是,我们可以看到 DABA 在表中实现了最好的 ASR,这意味着 DABA 可以在更严格的触发环境下有效提高机会性后门攻击的 ASR。
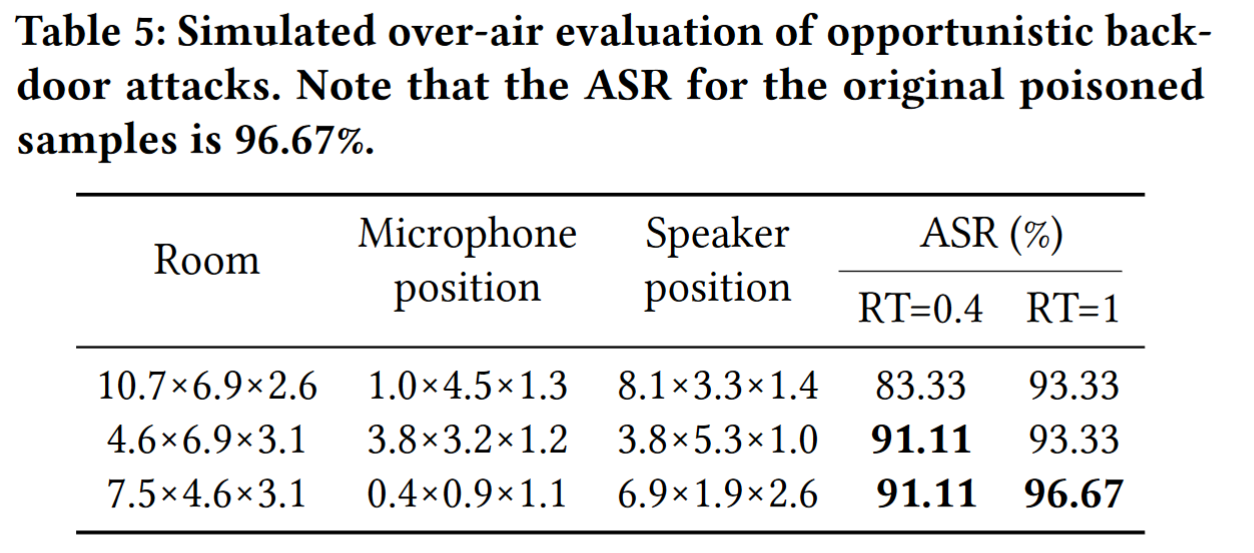
(4)攻击的可行性。为了回答问题 4,我们想研究是否可以在现实世界的无线场景中触发攻击。具体来说,我们从 9 个中毒类别(SCD-10)中随机抽取了总共 90 个样本。然后,我们使用 DABA 来评估不同房间设置的攻击可行性,包括不同的房间尺寸、麦克风位置、扬声器位置和混响时间。表 5 显示了混响时间为 0.4,1 时每个房间的 ASR。观察到我们的方法可以在不同的房间设置中将 ASR 保持在 83.33% 到 96.67% 之间。机会性后门攻击在现实的无线场景中具有更高的ASR来执行触发动作,这证明了我们的攻击具有巨大的可行性。
(5)对语音增强的抵抗。为了回答问题 5,我们首先检查 DABA 是否能够在音频的噪声预处理中生存。我们评估中毒模型中去噪测试集的 BA/ASR。实验结果如图 4(a) 和图 4(b) 所示。从 SCD-10 上的结果可以看出,DABA 在 MMSE 上保持了更好的 BA/ASR,这表明基于 MMSE 的防御对于此类攻击几乎无效。基于 DNN 的防御将 ASR 降低至2.6%,但其 BA 下降了近30%,这在实践中是不可接受的。此外,基于 spesub 和基于 wiener 的防御仅将 BA 降低了约 3%,从而减轻了 40% 的 ASR,这使它们成为更理想的措施。然而,SCD-30 的实验结果反映了另一个有趣的发现。如图 4(b) 所示,四种防御措施并没有减轻 DABA 的 ASR,而是导致 BA 下降,这表明 spesub 或 wiener 等典型技术在可变条件下很容易崩溃。
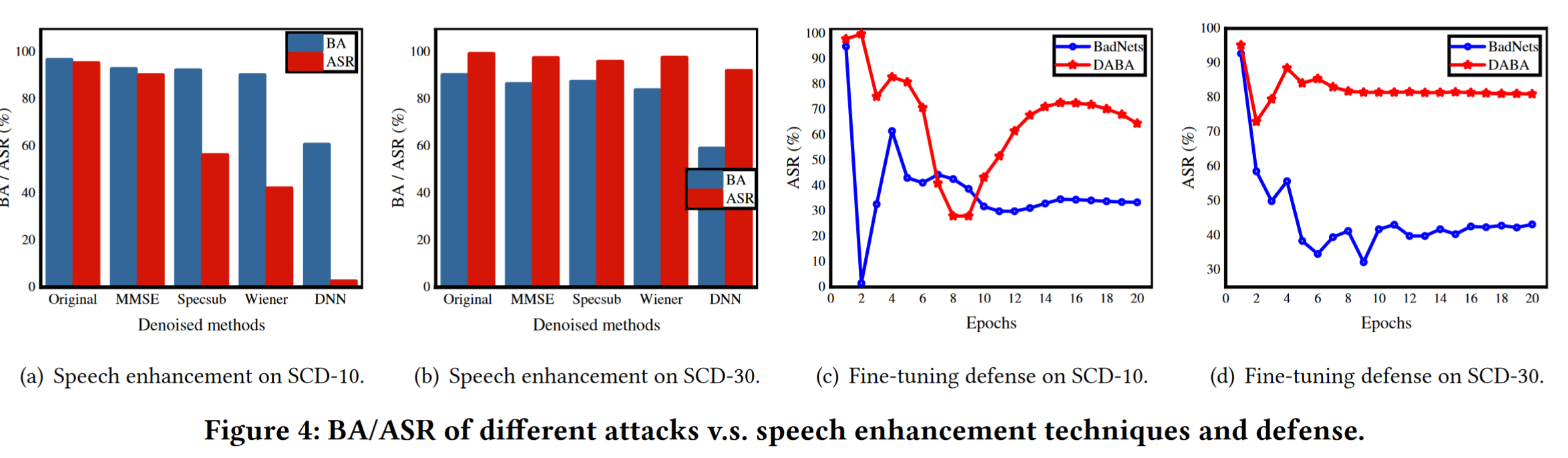
(6)微调的阻力。为了回答问题 5,我们进一步将我们提出的 DABA 与 BadNet 在对基于干净数据的微调的抵抗力方面进行比较 [22],这是一种跨媒体通用后门防御。比较结果如图 4(c) 和图 4(d) 所示。从 SCD-10 的结果可以看出,BadNets 的 ASR 在仅仅 1 个 epoch 后就从 94.88% 下降到 1.48%,并在 20 个 epoch 后保持在 33.41%,而我们的 DABA 攻击在 15 个 epoch 后仍然高于 60%。此外,DABA 的 ASR 达到了 80.99%,而 BadNets 在 SCD-30 上经过 20 个 epoch 后仍然为 43.17%。
讨论
被忽视的后门。当前 CV 和 SR 系统中的后门设计需要对手现场播放一些音频来触发中毒模型中植入的后门。然而,对手不仅很难在现场保持在线状态。相比之下,我们的机会主义攻击是即插即有条件运行的,这避免了不切实际的存在要求,并为攻击场景(例如室内、车内)提供了更多可能性。我们认为后门攻击的标准是不经意的漏洞注入和条件触发,因为它就像蠕虫一样,只要条件成立,最终就会对受害者构成威胁。
攻击的调用不确定。诚然,我们的机会主义后门攻击是一种不确定的攻击,可能会长时间保持沉默,并且不如主动攻击有效。然而,由于缺乏昂贵的人力和设备成本,它适合广泛部署,这可能会给用户带来更严重的威胁。同时,伺机调用很可能会造成不易察觉的损害。
结论。现有的听不见的后门触发器(例如超声波)可以通过预处理轻松减轻或注意到,主要是因为附加设备需要安装在附近。为了打破这一限制,我们探索了第一个用于语音识别的可听后门攻击范例,其特点是被动触发和机会主义调用。此外,我们通过基于确定性的触发器选择、忽略性能的样本绑定和触发器增强来发起机会攻击。我们相信识别此类新漏洞可以促进 SR 系统的安全发展。
参考文献
[1] Stefanos Koffas, Jing Xu, Mauro Conti, and Stjepan Picek. 2021. Can You Hear It? Backdoor Attacks via Ultrasonic Triggers. arXiv preprint arXiv:2107.14569 (2021).
[2] Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. 2019. Advances and open problems in federated learning. arXiv preprint arXiv:1912.04977 (2019).
[3] Nicholas Carlini and David Wagner. 2018. Audio adversarial examples: Targeted attacks on speech-to-text. In Proc. of SPW. IEEE, 1–7.
[4] Andrew Varga and Herman JM Steeneken. 1993. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech communication 12, 3 (1993), 247–251.
[5] Yunfei Liu, Xingjun Ma, James Bailey, and Feng Lu. 2020. Reflection backdoor: A natural backdoor attack on deep neural networks. In Proc. of ECCV. Springer, 182–199.
[6] Tongqing Zhai, Yiming Li, Ziqi Zhang, Baoyuan Wu, Yong Jiang, and Shu-Tao Xia. 2021. Backdoor attack against speaker verification. In Proc. of ICASSP. IEEE, 2560–2564.
[7] Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. 2019. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access 7 (2019), 47230–47244.
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!