image-caption
image-caption: 图像中文描述
数据集下载:https://tianchi.aliyun.com/dataset/145781?t=1699533627520
Show, Attend, and Tell
这是一篇2021年的文章,用于生成图像的描述。利用卷积神经网络CNN提取图像特征,使用RNN将特征向量解码成语言序列。本论文在RNN(LSTM)上加入了attention机制,对图像特征的像素点进行概率估计,并加权求和,其思想为:人们在观察图像中倾向于关注有用信息,它创新性的将Attention作用到输入图像的像素点之上。
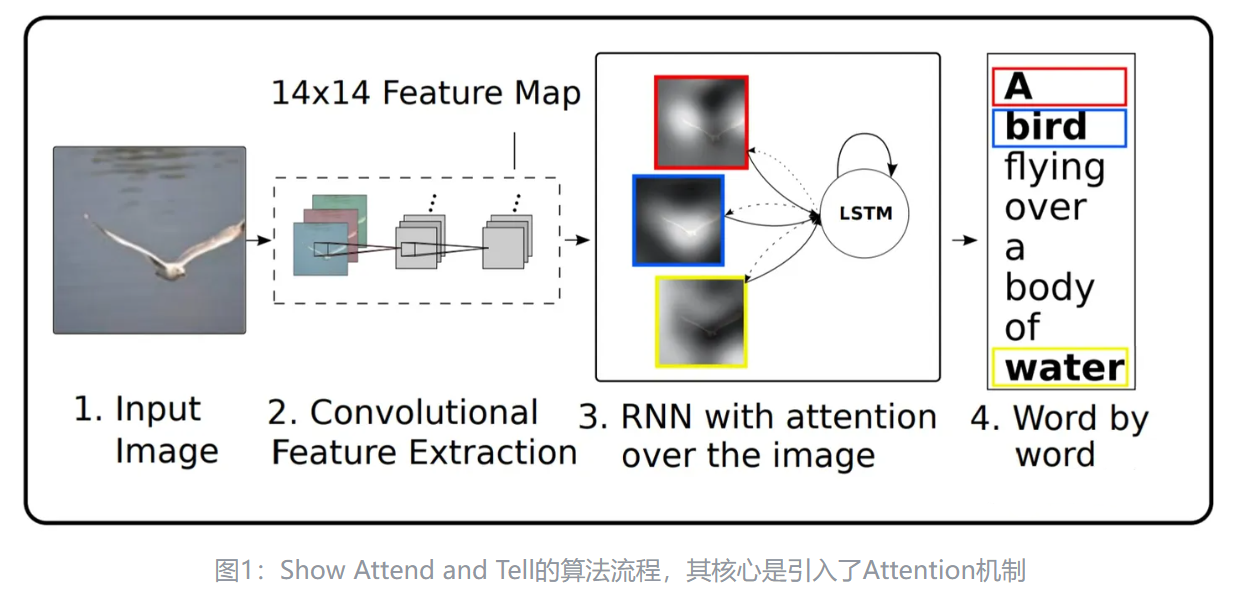
此文的贡献是:(1)提出了基于attention的image caption;(2)可视化了attention在每个时间上关注的点;(3)量化了加入attention机制后性能的提高。
Encoder
VGGNet、Inception等是在大规模图像数据集(如ImageNet)上进行了预训练的模型,可以很好的提取到图像的特征。通过将最后的flatten与FC去掉,可以得到特征图。
Decoder
使用LSTM,在每个时间step上生成词语。
复习一下LSTM的知识:
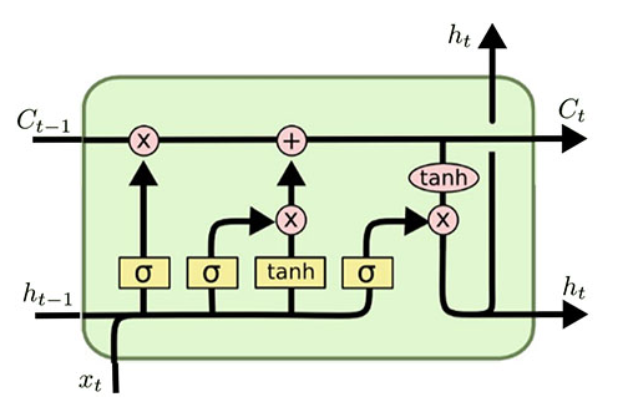
LSTM的输入为:$C{t-1},h{t-1},x_{t}$,输出为$C_t,h_t$。
遗忘门:
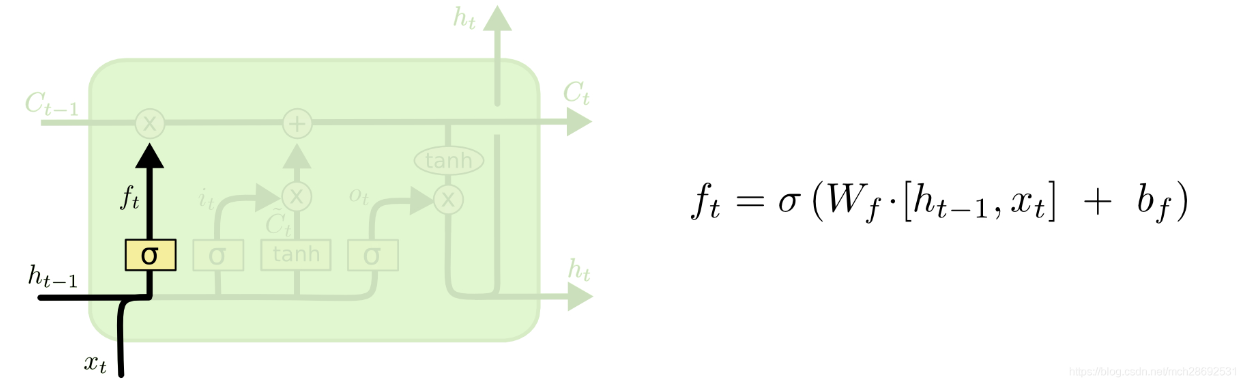
输出门(存储并更新细胞状态):
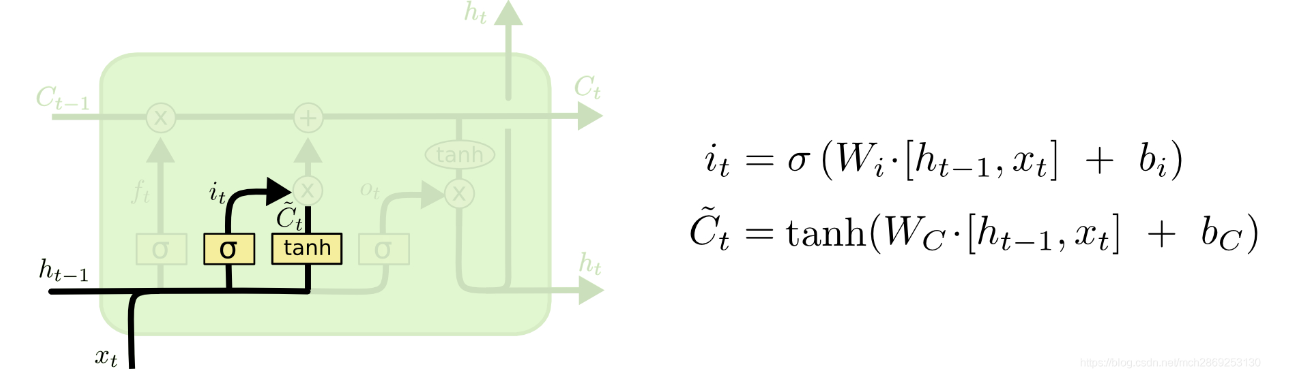
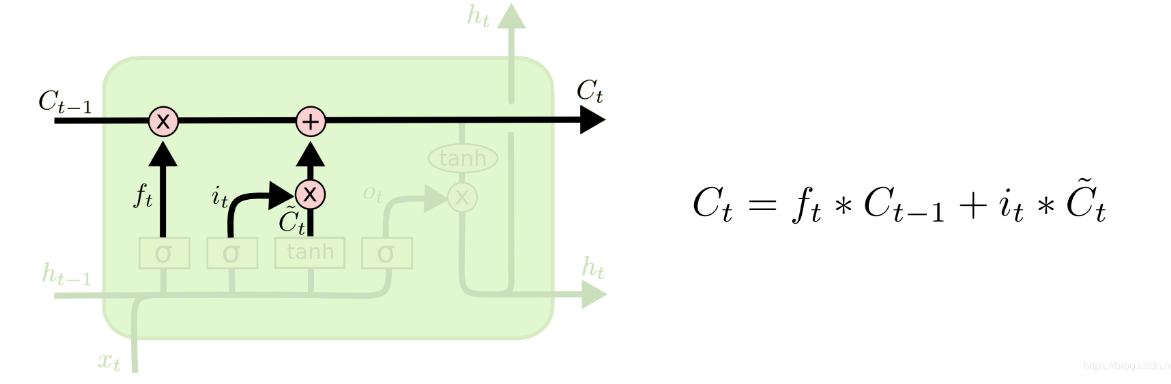
输出门:
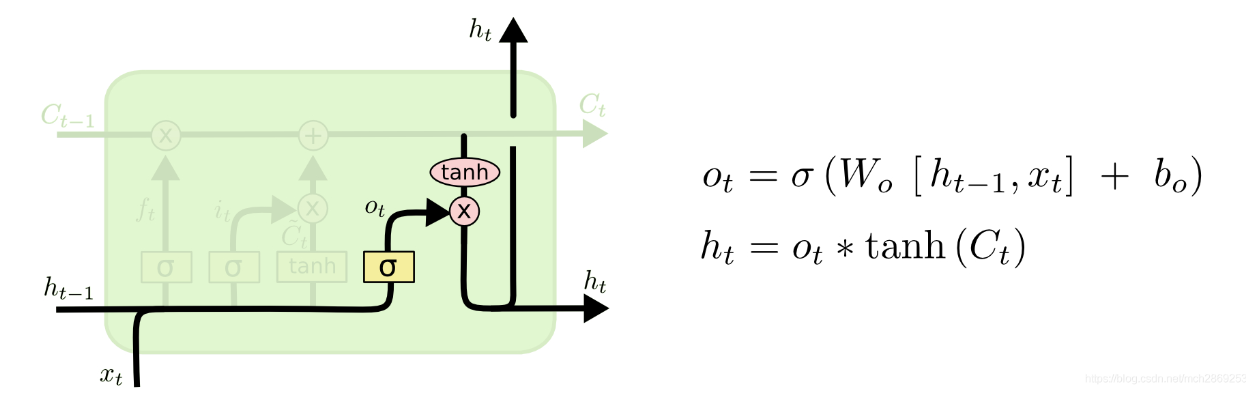
.png)
Attention
作用是帮助生成LSTM中的$Ct$。利用CNN提取出的特征向量$a$与LSTM输出的$h{t-1}$,通过FC+softmax计算每个像素点的概率值,之后对每个像素点加权求和。模型结构具体看下图。
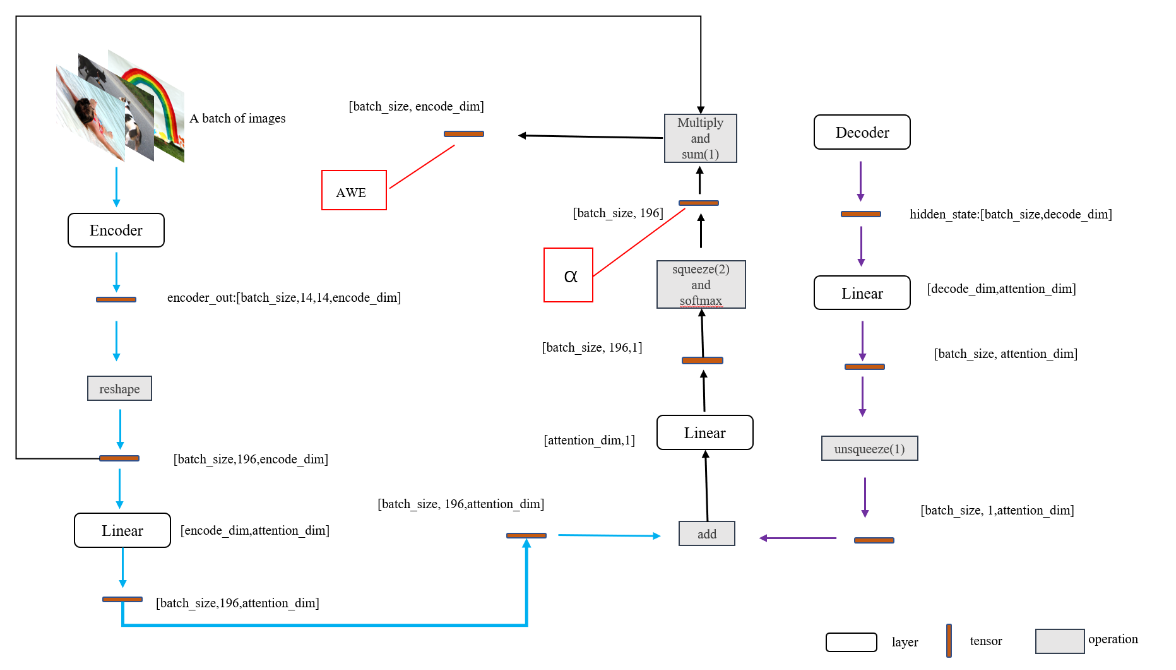
Backend
我首先将训练好的模型封装成 demo.py,之后打算用 c++ 写的后端封装这个 demo.py。后端主要是借鉴了 link,吐槽一下,将其转为 Windows 下的服务器真不容易。
参考链接:
[1] https://github.com/foamliu/Image-Captioning-PyTorch
[2] https://blog.csdn.net/qq_43152622/article/details/118755946
[3] https://github.com/dabasajay/Image-Caption-Generator
[4] https://blog.csdn.net/sophicchen/article/details/103306545
[5] https://omarshishani.com/how-to-upload-images-to-server-with-react-and-express/
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!