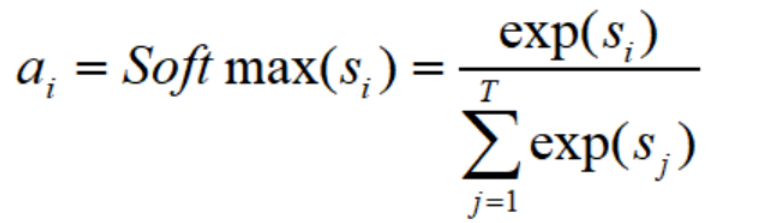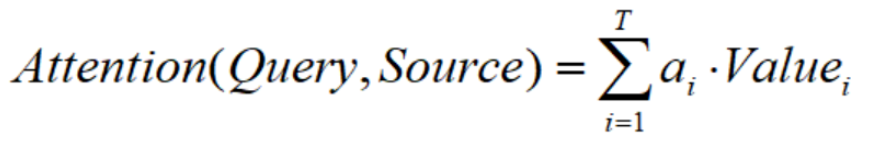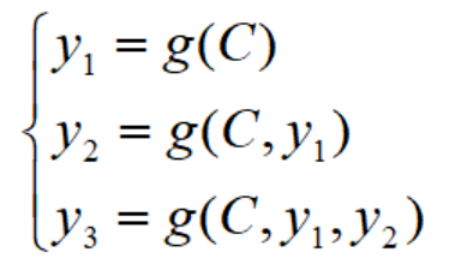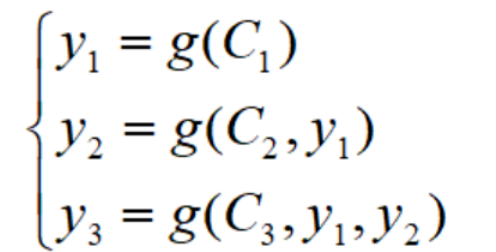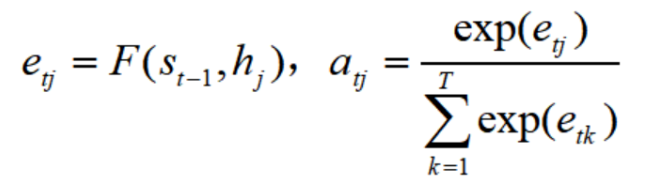title: intern-ms-prepare
password: xcl12345
微软实习生准备 DeFiHackLabs 区块链交易调试工具:Phalcon、Tx.viewer、Cruise、Ethtx、Tenderly。其中,Tx.viewer可以对交易流程进行可视化,而Tenderly支持最多的链。
区块链漏洞 Insufficient Gas Griefing Insufficient Gas Griefing 可以在接受数据并在另一个合约的子调用中使用。这种方法通常用于多重签名钱包和交易中继器 。如果子调用失败,则要么恢复整个事务,要么继续执行 。
以一个简单的中继合约为例。如下所示,中继者合约允许某人签署交易,而无需执行交易 。当用户无法支付与交易相关的 Gas 费用时,通常会使用此方法。
1 2 3 4 5 6 7 8 9 10 contract Relayer { mapping (bytes => bool) executed; function relay(bytes _data) public { // 重播保护;不要两次调用同一事务 require(executed[_data] == 0, "Duplicate call"); executed[_data] = true; innerContract.call(bytes4(keccak256("execute(bytes)")), _data); } }
执行交易的用户(即转发者)可以通过使用足够的 Gas 来有效地审查交易,以便交易执行,但没有足够的 Gas 来使子调用成功。有两种方法可以防止这种情况:(1)允许受信任的用户转发交易;(2)要求转发者提供足够的gas,如下所示:
1 2 3 4 5 6 7 // 由转发者调用的合约 contract Executor { function execute(bytes _data, uint _gasLimit) { require(gasleft() >= _gasLimit); ... } }
中继智能合约可以作为不同区块链之间的桥梁,实现跨链操作和数据交换。中继智能合约可以提供更高的隐私保护,通过将敏感的交易和数据处理逻辑放在中继智能合约中进行,而不是直接在区块链上执行。
Insufficient Gas Griefing 影响:攻击者可以创建恶意交易,将合约陷入无限循环或长时间执行的状态,消耗大量的计算资源和燃料(Gas),从而导致网络拥塞或其他用户无法执行交易。
Reentrancy 当合约中的错误可能允许恶意合约在原始函数执行期间意外地重新进入合约时,可能会发生这种攻击。如果被恶意使用,这可以用来从智能合约中抽走资金。
外部调用 可以通过对攻击者控制的合约进行外部调用来执行重入,外部调用允许被调用者执行任意代码。外部调用的触发方式有:
(1)以太坊转账。当以太币转移到合约地址时,会触发合约中实现的receive或函数。fallback攻击者可以在该方法中写入任意逻辑fallback,这样只要合约收到转账,该逻辑就会被执行。
(2)safeMint。难以发现的外部调用的一个例子是 OpenZeppelin(开源的智能合约开发框架)的ERC721._safeMint与ERC721._safeTransfer函数。
1 2 3 4 5 6 7 function _safeMint(address to, uint256 tokenId, bytes memory _data) internal virtual { _mint(to, tokenId); require( _checkOnERC721Received(address(0), to, tokenId, _data), "ERC721: transfer to non ERC721Receiver implementer" ); }
该函数之所以命名为_safeMint,是因为它首先检查合约是否已实现 ERC721Receiver,即将其标记为 NFT 的自愿接收者,从而防止代币无意中被铸造到合约中。但_checkOnERC721Received是对接收合约的外部调用,允许任意执行。
单函数 Reentrancy 当攻击者尝试递归调用的函数有漏洞时,就会发生单函数Reentrancy攻击。
1 2 3 4 5 6 function withdraw() external { uint256 amount = balances[msg.sender]; (bool success,) = msg.sender.call{value: balances[msg.sender]}(""); require(success); balances[msg.sender] = 0; }
在这里我们可以看到,余额只有在资金转移后才被修改 。这可以让黑客在余额设置为 0 之前多次调用该函数,从而有效地耗尽智能合约的资源。
如何防止 Reentrancy 最简单的重入预防机制是使用 ReentrancyGuard,它允许您添加修饰符,例如nonReentrant。 另一种方法,使用 checks-effects-interactions,即先检查后转账。
腾讯安全平台部 0x00 简历与项目 0x00-1 自我介绍: 1 谢传龙,本科西安电子科技大学,2018 届网络空间安全排名第一,连续三年一等奖学金。硕士中国科学技术大学网络空间安全专业。有两段实习经历,获得过信息安全作品赛一等奖。研究生研究方向为系统安全。平时喜欢打 CTF,逆向手。擅长的语言是 C/C++,python。自己平时也了解过Unity UE 相关的知识。学过 C++ 逆向等。熟悉 hook,反调试,fastbin/uaf/double-free/thunk-extend 等。
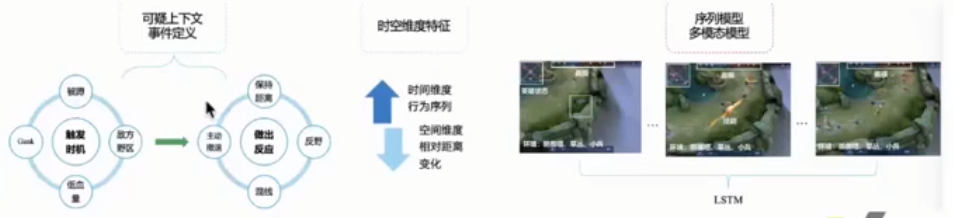
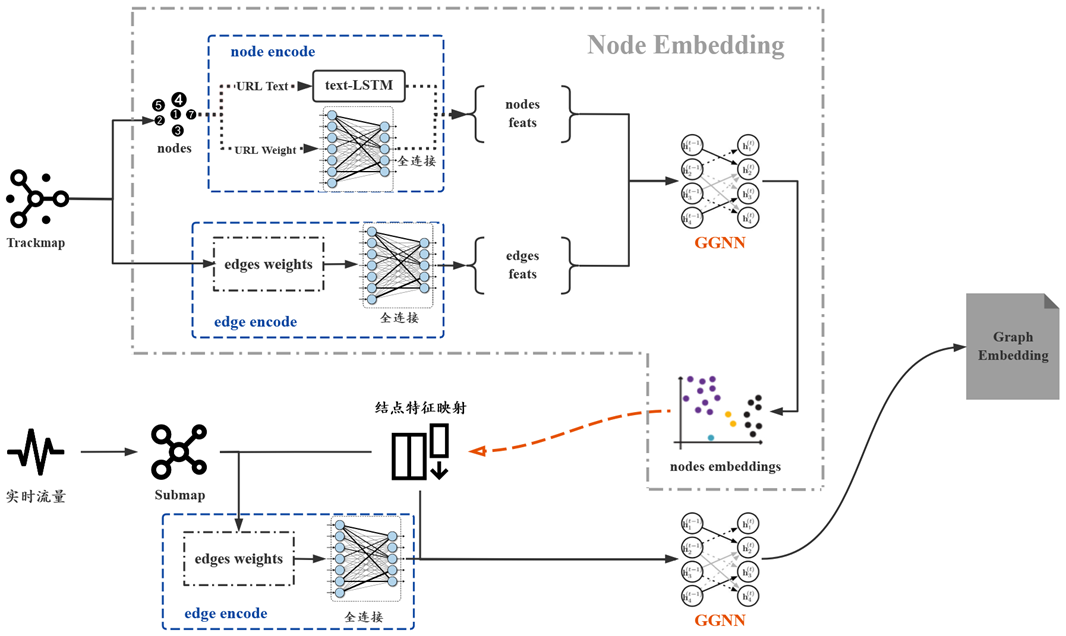
0x00-2 实习经历介绍: 0x00-2-1 科恩实验室 腾讯科恩实验室,2021.10 -> 2022.4。基于子图行为异常的分布式 Bot 识别。基于 GGNN 图神经网络,提升腾讯云防火墙在爬虫检测方面的能力,主要负责算法实现。(使用 dgl 图神经网络库)
什么是分布式 Bot?
分布式 Bot 是由多个不同 IP 的节点共同完成一次对网站的爬取任务,常见的模式多由一个任务调度中心将所需爬取的目标站点 URL 分发给各个节点,各节点完成各自的爬取任务。
分布式 Bot 的特点?
1 2 3 4 5 6 7 8 难以检测: 1. 单个节点对目标站点的访问频率相对较低 2. 单个节点对目标站点的URL访问顺序相对无序、随机 便于检测: 1. 同源于一个分布式爬取任务的节点,爬取行为多有一致性 2. 多存在代理池,一个分布式Bot集群中各节点IP网段相对集中(B\C段) 3. 分布式 Bot 由于调度下发任务的随机性和零散性,常常造成单节点分配到的url具有一定的随机性和零散性,这导致单个 Bot 节点的 url 访问序列,不会符合正常业务逻辑对应的访问模式、也不符合站点页面间的层次组织关系。 4. 相对于人类行为,Bot 任务的 URL 访问序列存在明显差异,例如对资源类 URL (js/css/ico 等) 请求的缺失
传统策略的不足
1 2 3 单个节点访问频率低:常用的频率异常规则难以感知 难以完整打击:一个节点被拦截,其余节点仍能完成大部分爬取任务 对抗性:UA/Referer 字段异常规则易遭对抗
动机
1 将访问序列建模成一个一个的节点,我们可以用 AI 图神经网络解决这个问题。
Step1:特征工程
1 2 3 4 5 图特征建模: 1. trackmap:此网站所有网页所构成的节点 url 可以构成一个 trackmap。节点间存在有向带权重边,权重为站点历史流量统计到的该访问序列出现的次数。(站点流量中,人类流量与传统单机 bot 流量的量级要远高于分布式 bot,且分布式 bot 的 url 访问序列有一定随机性和零散性,故 Trackmap 的边权重可以反映某一访问序列的异常程度,即如果出现权重很小的边,那么我们就要着重关注) 2. submap:一定时间内某 ip 的访问序列。 3. submap 的访问权重序列,时间间隔序列。 4. 其余特征:访问时间,UA 字段,Referer 字段,IP 地点/运营商/类型(IDC/DYN)等。
Step2:打标签
1 2 3 1. UA 带有 spider 字样 2. IP 网段是某个知名 spider 3. submap 中访问序列权重均值很低,且访问节点数 > 某个阈值
Step3:网络结构
1 2 3 4 5 训练方法: 1. trackmap 中将节点特征(主要就是 URL 文本)过 bert 形成 node characters,将边特征(边的权重)过全连接形成 edge characters。 2. 将打好标签的 submaps 映射到 trackmap 中,可以获得 submap 的表示。 3. submap 过 GGNN(与 GNN 不同,加入了类似于 LSTM 的门控机制,有助于长序列) 生成 graph embedding。 4. 结合 submap 的其他特征,例如访问时间间隔序列,UA 字段,Referer 字段,IP 地点/运营商/类型(IDC/DYN)等,最后做全连接 + Relu,进行二分类。
Step4:效果
1 测试集上针对某小说网站 70W 条数据,分布式 Bot 召回率为 97%,误报率为 6%。
0x00-2-2 北京微软 北京微软,2023.11 -> 至今。PPL 进程针对内核攻击者的改进方案研究。
Step1:背景
1 2 3 4 5 6 7 8 edge 要开发一个区块链钱包,此钱包安装好后,用户的钱包密码会保存在 TPM 中,而用户所进行的交易由用户主机中 vbs enclave 进程中的私钥进行签名。但是,会有两个安全风险: 1. 在用户初始化钱包的阶段,用户将钱包密码由浏览器发送到 TPM 的过程中,会在用户主机上运行的钱包进程中进行中转,如果攻击者劫持这个钱包进程,就会获得密码。 2. 用户在签名交易的过程中,用户将交易信息由浏览器发送到 VBS enclave,也会在用户主机上运行的钱包进程中进行中转,如果攻击者劫持这个钱包进程,就会任意修改交易信息(例如交易量,目标地址)。 为了解决这个问题,我们在用户主机上运行的钱包进程中使用了 PPL 机制。PPL 简单理解,当用户想要使用 OpenProcess 等 API 来获得这个进程并进行接下来的攻击时,会在 VTL-1 中做一个 check(执行由 hypervisor 保护),只有更高级别的 PPL 进程才能够获得我们所创建的这个 PPL 进程的句柄。但是它也会产生一个问题: 1. 由于做 check 实际上就是对 PPL 的等级做 check,且这个等级保存在 windows 内核中(进程的 EPROCESS),如果内核态攻击者修改这个等级,那么就可以绕过这个 check。
Step2:方案设计
1 2 3 4 5 6 7 8 9 1. 调研攻击者采取攻击的多种方式,路径有:(1)现有已签名的驱动程序漏洞;(2)其他系统 PPL 的漏洞。其最终目的都是获得钱包 PPL 进程的有效句柄。 2. 在避免攻击者有权限访问 PPL 进程这一点: (1)借助 windows defender,让其 hook 关键 windows API(openProcess,ReadProcessMemory 等),由于 defender 的引擎是由 hypervisor 保护的,因此可以有效防止攻击者使用这些手段来获得有效句柄,并可以防止攻击者 attack defender。另外,还可以注册回调函数,可以理解为是在内核态下进行的 hook,有效防止攻击者通过直接系统调用(hell gate)来绕过 hook。同时,defender 也会定期检查自己的 hook 代码是否被 unhook 掉。 (2)定期检查 PPL 进程的 EPROCESS,防止被攻击者修改。 3. 即使攻击者有权限访问 PPL,我们也要保证密码与交易信息不被泄露或篡改。 (1)密码使用 windows passkey team 的现有方案,直接使用他们的安全模块与 TPM 交互,从而不走 PPL 进程。 (2)交易信息经过调研,此部分不容易防御,因此,当签名后的交易发送到 bridge service(上链之前)的时候,使用邮箱通知用户所交易的金额/收款地址等,以供用户确认。
Step3:目前工作
1 2 1. Windows 的 PatchGuard 会定时检查 windows 原生的 PPL 进程的 EPROCESS 结构体,正在调研能否代替 defender,并能够做实时保护。 2. 正在做使用 windows passkey team 的密码保护方案的 prototype。
0x00-3 项目介绍: 0x00-3-1 针对 UAF 的 fuzz 工具 https://github.com/strongcourage/uafuzz/blob/master/raid20-final286.pdf
正在开发…
现在有很多 fuzz 框架例如,AFL 或 LibFuzzer。针对 PWN 中很容易出现的 UAF,结合 blackhat 2020 About Directed Fuzzing and Use-After-Free: How to Find Complex & Silent Bugs? 的演讲,对其进行了复现。
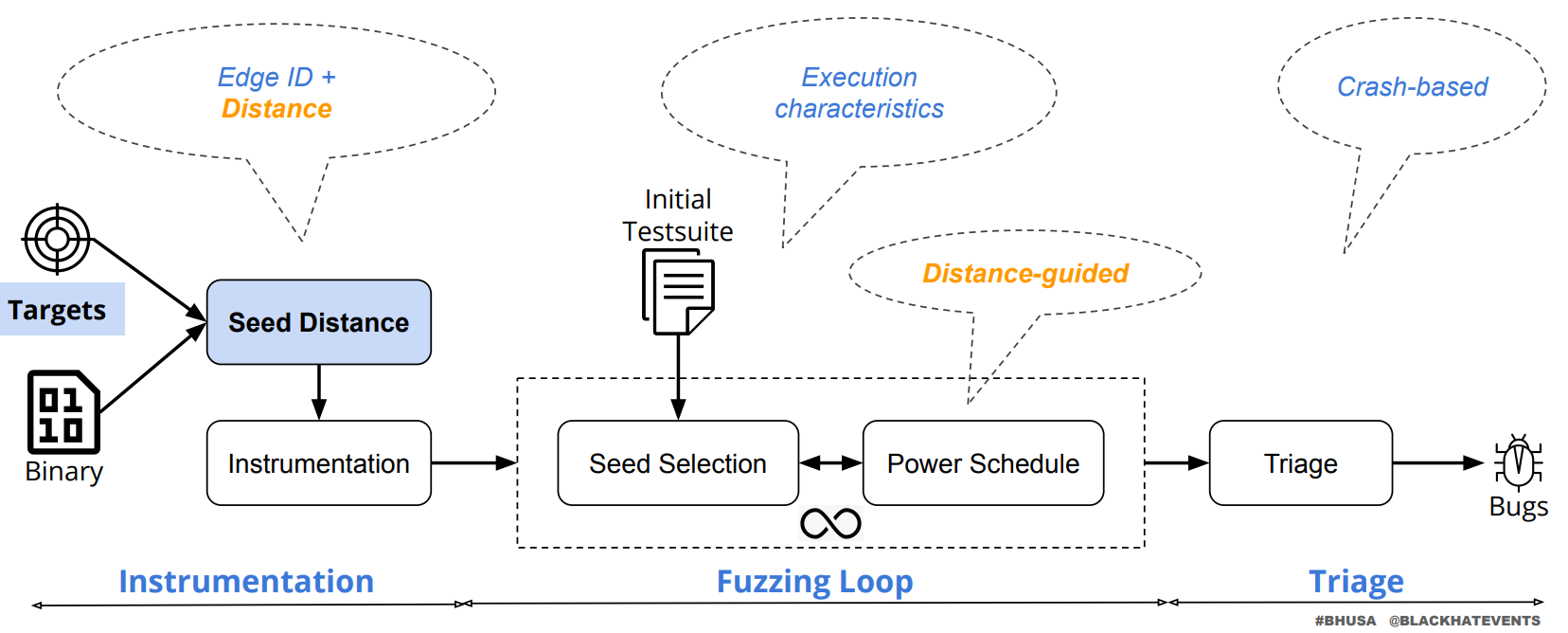
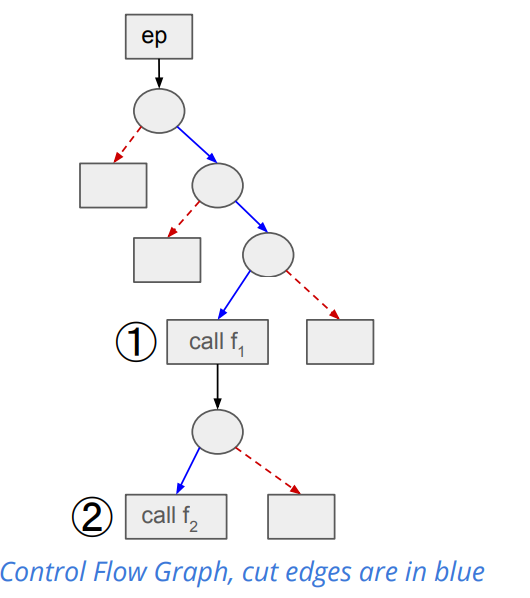
1 2 3 4 5 6 7 8 9 10 1. 以 fuzz 的代码点与二进制文件为基础,生成 edge ID 与 distance 信息,并以此指导 seed 生成。 2. 从最初的 seed 中生成 testcase,并从中选择 distance 最小的 case 作为输入。 3. 根据反馈信息,生成新的 seed,并重新生成 testcase。 4. Power Schedule,(1)确定哪些测试用例值得更多地探索,根据测试用例触达的代码路径或是接近目标区域的程度,决定为其分配更多的资源来生成更多变种。(2)分配测试用例的能量,可以以理解为对每个选中的测试用例生成变种(即通过修改测试用例来探索新路径)的次数。(3)根据测试过程中收集到的数据(如代码覆盖率变化、新发现的路径等),动态调整资源分配策略。 4. Triage:其中一些可能会引起程序的异常行为或崩溃。Triage 阶段首先需要对这些测试用例进行初步的分类和筛选,以区分哪些是真正有价值的(可能触发了漏洞的测试用例),哪些是误报或不相关的。 主要是在能量分配方面做的策略: 1. 一个触发 UAF 漏洞的有效测试用例很可能是那些能按正确顺序(即分配、释放后使用)并覆盖多个 UAF 事件的路径。那么,通过静态分析技术预先识别程序调用图中可能导致 UAF 事件序列的 (caller, callee) 对,并在计算距离时降低这些调用对的权重,这意味着,如果测试用例的执行路径包含了这样的调用对,它们被认为是距离目标更近的路径。(到 use 函数的路径) 2. 割边(Cut-edge)特指那些其目的地更有可能达到 bug trace 中下一个目标的边。通过静态内部程序分析识别割边,帮助 UAFuzz 理解程序内部的逻辑结构。偏好那些触发更多割边的输入。这种评分不仅考虑了覆盖到的割边数量,还考虑了这些割边被触发的次数(即命中计数)。直觉在于,通过更频繁地执行那些关键路径(即通过割边的路径),测试用例更有可能以正确的顺序触发漏洞相关的事件(如UAF中的分配、释放后使用)。 3. 相似度计算。会优先考虑那些不仅覆盖了与漏洞痕迹相似的目标位置序列,而且在整个漏洞痕迹中覆盖了更多目标位置的测试用例。
UAF 基础
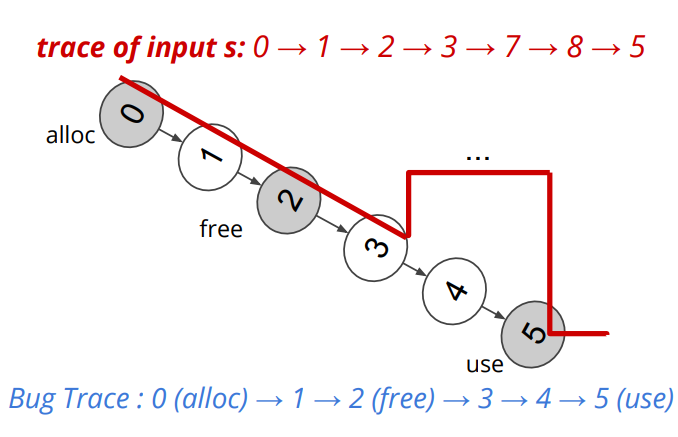
UAF 就是 free 后再使用,它会导致信息泄露、DOS 攻击等。
一个 UAF 的例子:
Fuzz 基础
1 2 3 黑盒 fuzz:不需要关于软件内部结构或实现的先验知识。测试人员主要关注软件的外部表现和输出,而不是其内部逻辑。测试用例通常是随机生成的,不依赖于程序的内部逻辑。 灰盒 fuzz:结合了黑盒测试和白盒测试(了解内部结构的测试)的特点。尽管不需要完全了解软件的内部实现细节,但测试过程会利用一定程度的内部信息(如代码覆盖率)来指导测试用例的生成和执行。 白盒 fuzz。
灰盒测试的步骤:
1 2 3 4 5 1. 选择好的输入。 2. 输入突变。 3. 根据输出来评估输入的好坏。 4. 对配置进行更新,从而指导输入进行突变。 5. 跳转到 2。
没有尽善尽美的做法,由于漏洞有的很复杂,且代码中有的数据结构很复杂,所以我们很难对所有类型的漏洞进行 fuzz,只能进行定向灰盒模糊测试 DGF(只能定向 fuzz 出某些漏洞)。它与基于覆盖率为导向的灰盒测试的区别为:
1 2 1. DGF 针对软件的特定部分进行测试。使用程序分析技术来识别和定位目标区域,并生成或调整测试用例以增加触及这些特定区域的概率。这可能涉及到对特定路径的追踪、对特定函数调用的监控等。 2. 基于覆盖率为导向的模糊测试旨在最大化软件执行路径的覆盖率,发现软件中尽可能多的漏洞。通过监控软件的代码覆盖率来引导测试用例的生成和选择。新生成的测试用例如果能够执行到之前未覆盖的代码路径,则会被优先选择用于后续测试。
主流 DGF 的设计
1 2 3 4 5 1. 以 fuzz 的代码点与二进制文件为基础,生成 edge ID 与 distance 信息,并以此指导 seed 生成。 2. 从最初的 seed 中生成 testcase,并从中选择 distance 最小的 case 作为输入。 3. 根据反馈信息,生成新的 seed,并重新生成 testcase。 4. Power Schedule,(1)确定哪些测试用例值得更多地探索,根据测试用例触达的代码路径或是接近目标区域的程度,决定为其分配更多的资源来生成更多变种。(2)分配测试用例的能量,可以以理解为对每个选中的测试用例生成变种(即通过修改测试用例来探索新路径)的次数。(3)根据测试过程中收集到的数据(如代码覆盖率变化、新发现的路径等),动态调整资源分配策略。 4. Triage:其中一些可能会引起程序的异常行为或崩溃。Triage 阶段首先需要对这些测试用例进行初步的分类和筛选,以区分哪些是真正有价值的(可能触发了漏洞的测试用例),哪些是误报或不相关的。
检测 UAF 的难点
1 2 3 fuzz 很难发现的原因: 1. 复杂性:多个事件按顺序跨越多个函数 2. 不会报分段错误
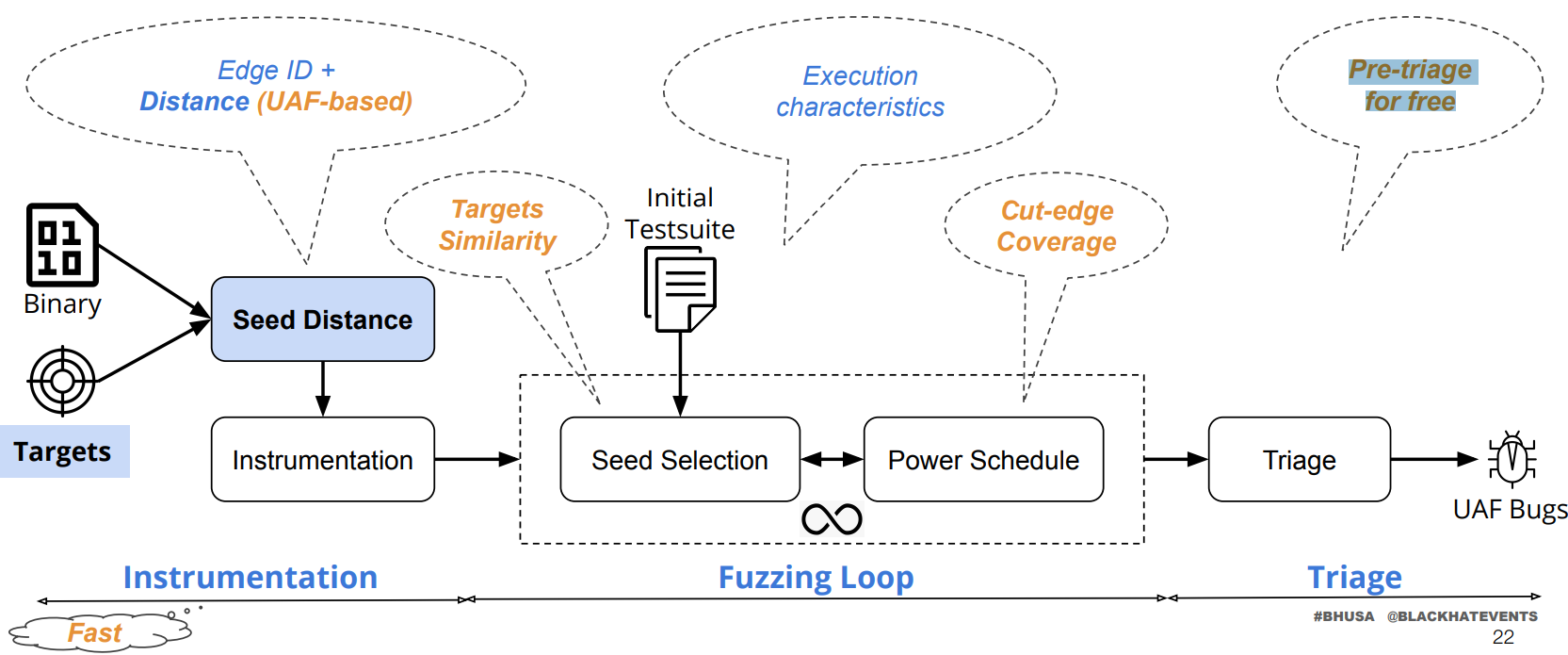
UAFuzz 的设计
1 2 3 种子选择:基于与 target 输入轨迹的相似度对种子优先级进行排序 能量分配:(1)基于 UAF 的距离,优先考虑覆盖 UAF 事件的种子;(2)Cut-edge Coverage:哪些种子可以覆盖更多的到达目标的边;(3)与目标的相似度。 Triage:仅对覆盖所有边的输入进行分类并进行预过滤。
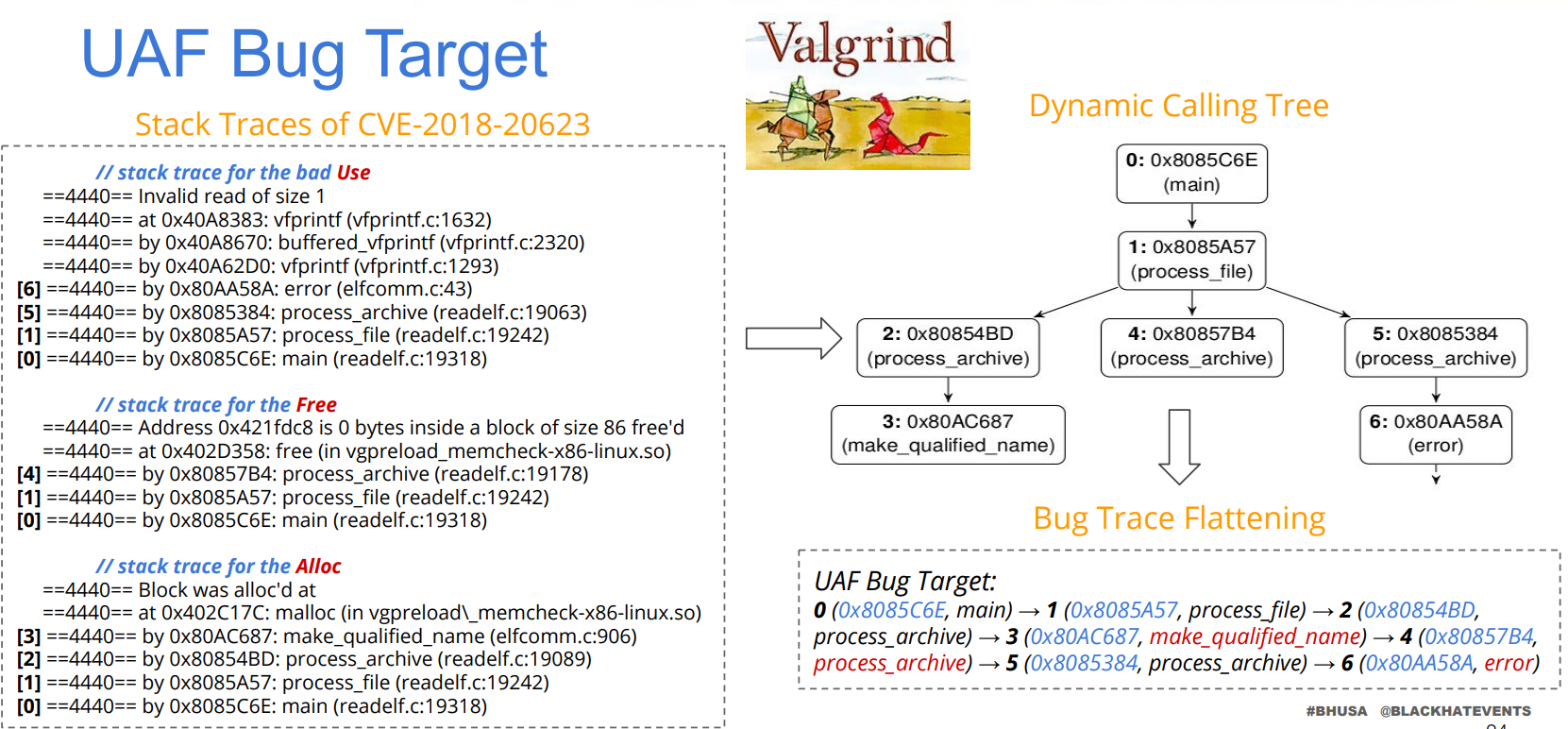
一个 UAF 的例子:
能量分配中的 distance 可以这样计算:
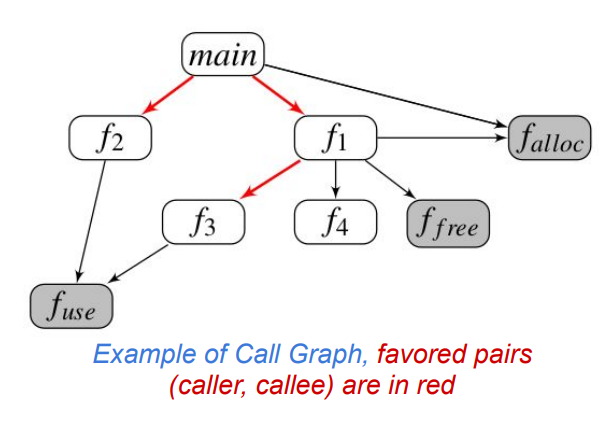
1 2 (1)在计算种子距离上,需要考虑目标顺序,调用轨迹依次包含 alloc、free 和 use 函数。 (2)直觉:一个触发 UAF 漏洞的有效测试用例很可能是那些能按正确顺序(即分配、释放后使用)并覆盖多个 UAF 事件的路径。那么,通过静态分析技术预先识别程序调用图中可能导致 UAF 事件序列的 (caller, callee) 对,并在计算距离时降低这些调用对的权重,这意味着,如果测试用例的执行路径包含了这样的调用对,它们被认为是距离目标更近的路径。例如:首选调用跟踪 <main, f_2, f_use>, <main, f_1, f_3, f_use>。
在能量分配时采用 Cut-edge Coverage Metric(割边覆盖度量)技术:
1 2 3 4 5 在现有的模糊测试工作中,当考虑测试用例是否能按序到达目标时,所有边(程序执行过程中可能遍历的路径)通常被等同对待。这意味着,在评估测试用例的有效性时,并没有对不同边根据它们达到后续目标的概率进行区分。 割边(Cut-edge)特指那些其目的地更有可能达到 bug trace 中下一个目标的边。通过静态内部程序分析识别割边,帮助 UAFuzz 理解程序内部的逻辑结构。 UAFuzz 偏好那些触发更多割边的输入。这种评分不仅考虑了覆盖到的割边数量,还考虑了这些割边被触发的次数(即命中计数)。直觉在于,通过更频繁地执行那些关键路径(即通过割边的路径),测试用例更有可能以正确的顺序触发漏洞相关的事件(如UAF中的分配、释放后使用)。
在能量分配时采用的相似度计算:
1 2 3 4 5 6 7 8 传统的方法在选择待变异的种子测试用例时,并不考虑测试用例覆盖的目标位置数量。意味着,尽管某些测试用例可能覆盖了更多与潜在漏洞相关的代码区域,但它们并没有因此而获得更高的优先级。 (1)前缀(Prefix):它考虑了测试用例覆盖目标位置的顺序。如果一个测试用例按照与漏洞痕迹(bug trace)相似的顺序覆盖了一系列目标位置,那么这个测试用例被认为是更有价值的。 (2)包(Bag):虽然不如前缀精确,因为它不考虑目标位置的覆盖顺序,但它考虑了整个漏洞痕迹中所有被覆盖的目标位置。这使得能够从一个更宽泛的视角评估测试用例与目标之间的相似度。 基于前缀和包度量:UAFuzz 采用了一种基于前缀和包度量结合的种子选择。这意味着它在选择种子测试用例时,会优先考虑那些不仅覆盖了与漏洞痕迹相似的目标位置序列,而且在整个漏洞痕迹中覆盖了更多目标位置的测试用例。 选择最大覆盖输入:具体来说,UAFuzz更频繁地选择那些到目前为止在这个度量上取得最高值的“最大覆盖输入”(max-reaching inputs),即那些与漏洞痕迹最相似的测试用例。
找出可疑漏洞并作筛选(pre-filter):
1 利用目标相似度度量(Target Similarity Metric):UAFuzz 通过目标相似度度量来自动识别出哪些测试用例是潜在输入。
0x00-3-2 基于双向 GRU + attention 的聊天机器人 1 使用双向GRU+attention进行训练,tkinter 进行 GUI 展示。通过注册和登录机制与聊天机器人对话。聊天机器人使用 50,000 个小黄鸭样本进行训练,使用的是第 75 轮训练的结果。我们的聊天机器人仅适用于中文。并且部署了 mysql。
0x00-3-3 VPN 状态下的内网扫描工具 1 如果想扫描一个企业(一般是学校)的内部网络,但是它的vpn(easyconnect)不可用,只对外提供 webvpn 的接口,那么你可以使用这个工具来扫描内部网络。该工具针对的webvpn是wrd tech开发的,使用AES-CBC-128加密,默认的key和iv都是wrdvpnisthebest!。 因此,对于没有修改key和iv的企业,我们可以将内网url转换为公网url。
Step1:拿到账号:xx;密码:xx。 进入https://webvpn.bit.edu.cn/并登录。需要注意的是,由于北京理工大学已经禁止vpn登录,因此只能使用webvpn。
Step2: 北京理工大学webvpn界面如下:
经查找,其提供的服务并没有校园网用户认证:10.0.0.55/srun_portal_pc?
ac_id=8&srun_wait=1&theme=bit。
Step3: 经查阅,此webvpn为信瑞达公司,在webvpn中的内网url加密时,使用AES-128加密,默认key=wrdvpnisthebest!,iv=wrdvpnisthebest!。经过检验,北京理工大学并未修改key与iv的值,保留了默认值。 借助脚本webvpn.py,可以将10.0.0.55/srun_portal_pc?ac_id=8&srun_wait=1&theme=bit转为:
1 https://webvpn.bit.edu.cn/http/77726476706e69737468656265737421a1a70fcc696026052b/srun_portal_pc?ac_id=8&srun_wait=1&theme=bit
Step4: 因此,由
1 https://webvpn.bit.edu.cn/http/77726476706e69737468656265737421a1a70fcc696026052b/srun_portal_pc?ac_id=8&srun_wait=1&theme=bit
,可以访问校园网用户认证界面,审计发现,其js代码存在缺陷。
Step5: 由于此网页为HTTP,并未使用HTTPS。分析网页js源码,发现密码直接使用base64表替换加密,而未使用其它保护用户口令的方法(如随机数)。js源码如下所示:
Step6: 因此,开启wireshark混杂模式,抓取北京理工大学内网流量包,成功抓到用户认证流量包。如下所示:
0x00-3-4 图像中文描述 1 Show, Attend, and Tell。本论文在RNN(LSTM)上加入了attention机制,对图像特征的像素点进行概率估计,并加权求和,其思想为:人们在观察图像中倾向于关注有用信息,它将Attention作用到输入图像的像素点之上。之后,写了一个 c++ http_server 用于接收图片,用 react 写了一个前端用于回传。
0x00-3-5 基于 rust 的 FPS 游戏透视 正在开发 AssaultCube 的外挂。
1 2 3 4 1. 已知玩家头部坐标为 x1,y1,z1,敌人头部坐标为 x2,y2,z2,敌人脚部坐标为 x3,y3,z3,根据上述代码,如何进行计算,将敌人的方框展示在玩家的屏幕上? (1)需要将敌人的头部和脚部坐标从世界坐标系转换到屏幕坐标系,需要用到视图矩阵和投影矩阵,这可以从游戏的内存中读取(0x17DFD0)。 (2)根据视图矩阵,对于敌人的头部 (x2, y2, z2) 和脚部 (x3, y3, z3) 坐标,将坐标转换到屏幕坐标系中,从而获得:(head_screen_x, head_screen_y) 和 (feet_screen_x, feet_screen_y)。 (3)使用 windows_ez_overlay 绘制方框。
AssaultCube 是一个局域网的 FPS 游戏,分析后发现没有任何检测技术。因此,其客户端进程 ac_client.exe 可以被任意读取,且发现玩家信息固定保存在 0x18AC04,使用 rust 多线程读取后进行坐标转换计算玩家矩形位置与大小。打包成 dll 直接进行注入即可。原始的 Cube 游戏是用 C++ 和 OpenGL 开发的。
1 2 3 4 5 6 7 8 9 10 11 12 13 rust 的安全性体现在哪里?内存安全。内存安全是指在程序运行过程中,对内存访问的控制,保证程序可以正确、安全地处理内存中的数据。不正确的内存访问可能导致各种严重问题,比如数据泄露、程序崩溃和安全漏洞等。常见的内存安全问题包括但不限于: 1. 缓冲区溢出:当程序写入的数据超过了分配的内存大小时,会覆盖相邻内存区域的数据,可能导致程序行为异常或被恶意利用。 2. 悬垂指针:当内存被释放后,仍有指针指向该内存区域,再次访问该指针会导致不可预知的行为。 3. 重复释放内存:对同一块内存进行多次释放操作可能会引发程序崩溃或其他安全问题。 4. 野指针:指向未知内存区域的指针,其访问可能导致程序崩溃或数据损坏。 rust 是如何保证内存安全的?Rust 通过一系列语言设计和编译器检查,提供了强大的内存安全保障,主要体现在以下几点: 1. 所有权系统:Rust通过所有权(Ownership)、借用(Borrowing)和生命周期(Lifetimes)的概念来管理内存。每块数据在Rust中都有一个明确的所有者;数据可以被借用,但在任何时刻,要么只能有一个可变引用(写权限),要么有多个不可变引用(读权限),这避免了数据竞争和修改冲突。 2. 借用检查器:Rust编译器内置的借用检查器能在编译时检查引用是否遵守所有权和生命周期的规则,确保安全地访问内存。 3. 模式匹配:Rust的模式匹配强制开发者处理所有可能的情况,减少因遗漏处理分支而导致的潜在内存安全问题。 4. 无空指针:Rust通过Option<T>枚举类型处理可能为空的情况,使得开发者必须显式处理None情况,避免了空指针引用。
游戏坐标加密了怎么办?
32位的hook与64位的hook有什么区别?
1 2 3 4 5 6 7 8 9 10 11 12 13 1. 对于系统API的hook,windows 系统为了达成hotpatch的目的,每个API函数的最前5个字节均为: move edi,edi push ebp mov ebp,esp 其中move edi,edi这条指令是为了专门用于hotpatch而插入的,微软通过将这条指令跳转到一个short jmp,然后一个long jmp可以跳转到任意4G范围内的代,达到运行中替换dll的目的。假设我们要求把0x12345678这个地址的函数hook,使其跳转到0x12345690,我们可以将这5个字节替换为:0xe9 (0x12345690-0x12345678-5) ,以达到跳转到0x12345690这个地址的目的(此处,注意大小端系统的区别),这条指令是相对跳转。 2. 64位系统没有了上面这样的方便之处,因此必须有一种新的策略。64位的跳转,可用两种方法,下面两个方法都是绝对跳转指令。 (1) mov rax, 0x0123456789abcdef jmp rax (2)也可以间接跳转。将一个old_func_address的前x个字节修改为跳转到我们的new_func_address,然后再运行原来的函数地址
0x01 基础知识 0x01-1 逆向相关 0x01-1-1 反调试技术 1.有一些标志,在正常的运行状态的值跟调试状态的值不一样,或者就是一些 API (IsDebuggerPresent,查询进程环境块 PEB 中的 BeingDebugged 标志),在正常的运行下跟调试状态运行下的结果或返回值不一样。
2.根据运行时间(RDTSC),在正常情况下,我们的一个函数到下一个函数的运行时间也就是0.0000001秒,但是在调试状态下由于单步运行就会让这个运行时间增加,我们可以在第一个函数中获取当前时间,在第二个函数中也获取当前时间。
3.调试器在做软件断点的时候 会有 CC 指令写入,我们就可以对 CC 进行检测,调试器在做硬件断点的时候会对调试寄存器进行操作,我们可以检测调试寄存器中的值,调试器在做内存访问断点的时候,会修改内存属性,我可以对内存属性进行检测。
4.基于异常的机制,我们可以在程序里面制造一些异常,编写异常处理函数,在异常处理函数里面进行检测。
1 2 3 4 5 6 7 8 (1)筛选器异常。(如果有SetUnhandledExceptionFilter这种函数,就说明有筛选器的存在) 异常默认是由操作系统处理的,现在用 API 设置由用户自己定义处理异常(内存访问无效,修改到常量区等错误),当发生异常的时候,系统将调用这个回调函数,并根据回调函数的返回值决定如何进行下一步操作。在进程范围内,筛选器异常处理回调函数是唯一的,设置了一个新的回调函数后,原来的就失效了。 语法:invoke SetUnhandledExceptionFilter, offset MyFilter 使用场景:代码加密(加密是因为可以防止他人改 eip 跳过你的异常,加了密之后就算跳过看到的也是加密后的代码,执行加密的代码段也是会错的)。代码段进行加密,代码开始产生异常报错,异常筛选器的回调内解密代码,重设eip信息。非调试状态能正常执行程序,调试状态不能正常执行程序(注册异常后用调试工具的话,异常会被调试工具接收,断点不了异常处理函数,也就调试不了程序,除非找到你的异常处理函数) (2)SEH 异常处理。在程序当中如果发现有 Fs[0] 这种代码 就说明有 SEH 的存在。
5.符号检测&窗口检测&特征码检测。主要针对一些使用了驱动的调试器或监视器,这类调试器在启动后会创建相应的驱动链接符号,以用于应用层与其驱动的通信。但由于这些符号一般都比较固定。
6.TLS 线程局部存储。
7.PEB 结构体。
1 2 3 4 1. BeingDebugged。IsDebuggerPresent API。 2. Ldr,一个指向_PEB_LDR_DATA结构的指针,存储当前进程加载的所有模块的信息,包括模块的基地址、入口点、导入表、导出表等。调试进程时,堆内存会出现很多0xFEEEFEEE,表示未使用过的堆内存。而_PEB_LDR_DATA是在堆内存中创建的,所以查看PEB.Ldr,看里面是否有0xFEEEFEEE。若有,则代表进程正在被调试。 3. ProcessHeap,指向HEAP结构体,Flags(+0xC)与ForceFlags(+0x10)两个成员,当被调试时,这两个成员被设置为特定的值(正常情况下Flags为0x2,ForceFlags为0x0,仅在XP中有效)。 4. NtGlobalFlag,PEB.NtGlobalFlag会设置为0x70,正常应该是0。
8.NtQuerylnformationProcess 获得与调试相关的信息。
1 2 3 4 5 (1)ProcessDebugPort,进程处于调试状态时,系统就会为它分配1个调试端口(Debug Port),若进程处于非调试状态,则变量dwDebugPort的值设置为0;若进程处于调试状态,则变量dwDebugPort的值设置为0xFFFFFFFF。 (2)ProcessDebugObjectHandle,会获得调试对象的句柄,如果进程处理与调试状态,句柄就存在,反之就不存在。 (3)ProcessDebugFlags。
9.NtQuerySysteminformation,NtQueryObject 等 API,ZwSetlnformationThread(强制分离 detach 被调试者与调试器,从而达到反调试的目的)。
0x01-1-2 外挂检测 1 2 3 FPS游戏简单,刷新速度快,检测物体多,数据量大。导致它的大部分运算只能放在本地,也就是你的电脑上进行。 MOBA 游戏难,每一次玩家的点击数据都需要上传给服务器进行判断,简而言之就是服务器做的运算的工作,本地只是一个执行的动画。需要去拆游戏过程中上传服务器的数据包,拆完还需绕过服务器的验证规则。最后你还需要成功修改,不能被发现。
FPS 外挂
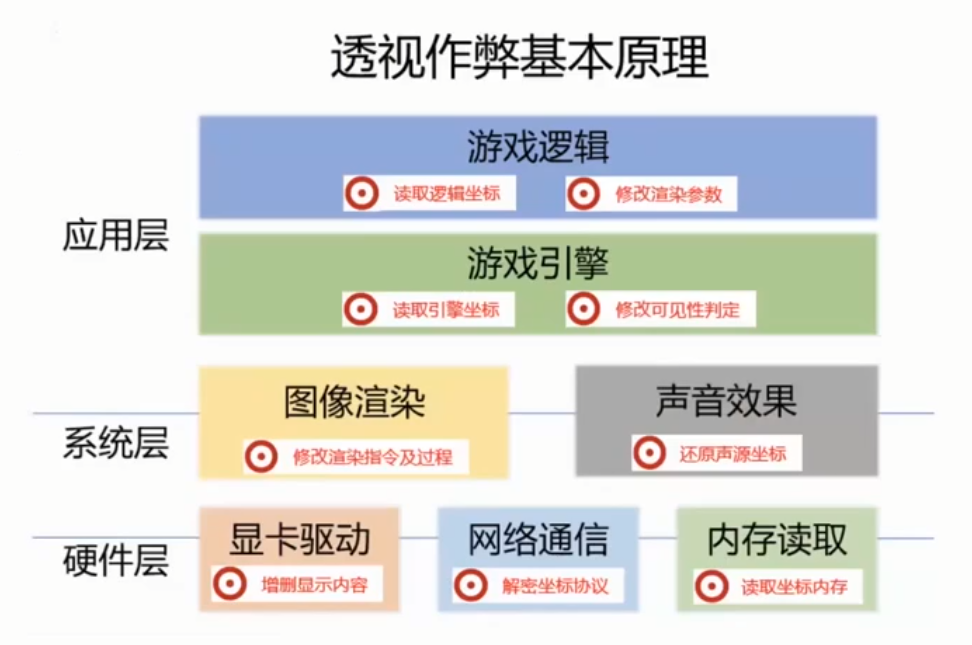
1 2 3 4 5 6 7 8 9 10 11 12 13 1. 自瞄,锁头。 (a)通过截图当前窗口,分析图片中的人物,再结合骨骼参数进行判断,操作鼠标事件去进行调整。 (b)通过hook游戏函数的方式修改朝向、或者通过坐标读取并模拟按键的方式操作玩家锁定敌人的模型头部。 2. 透视。 (a)读取游戏客户端数据来获取敌人的准确坐标,并且通过修改系统DLL、显卡驱动、游戏的渲染参数等方式,将敌人的准确位置展示给作弊玩家。 (b)对抗:模拟假人数据投放入战场,以此来混淆透视外挂的效率。 (c)游戏利用Direct3D (D3D)渲染一个物体,而D3D提供多种渲染状态,它影响几何物体怎样被渲染。渲染类的透视外挂就是利用D3D的原理,通过修改相应的游戏文件参数实现的。 3. AI 外挂。异常行为检测(鼠标输入波动),使用 AI 对抗 AI。 3. DMA 外挂。 (a)DMA是Direct Memory Access(直接内存访问)是一种读写数据的计算机技术,允许硬件设备(如网卡、显卡等)直接访问系统内存,而不需要通过CPU。 (b)传统外挂有外挂程序运行于作弊机器上读写游戏客户端关键数据或代码;而DMA外挂则是以硬件替代了外挂软件读写游戏数据,物理隐藏了外挂程序。
0x01-1-3 SEH&VEH&UEH 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 向量异常处理(VEH): (1)允许开发者为线程注册多个异常处理器函数。 (3)不是基于堆栈的,而是基于先进先出(FIFO)的队列。 (3)SetWindowsHookEx(spy++)。 (4)当异常发生时,首先调用 VEH 处理器(按照它们注册的顺序),早于 SEH。 结构化异常处理(SEH): (1)Windows 提供的标准异常处理机制,支持在程序中直接处理硬件异常(如访问违规、除零错误等)和软件异常。 (2)SEH 使用 try 和 except 语句来定义异常处理代码块。指 C++ 中的异常处理机制,使用 try、catch 语句处理异常。 (3)当异常发生时,系统会查找最近的SEH异常处理器(即最近的 try/except 代码块)。如果找到,就执行相应的处理代码。如果没有找到,异常会向调用堆栈上抛。 非结构化异常处理(UEH): (1) 执行顺序:VEH -> SEH -> UEH。
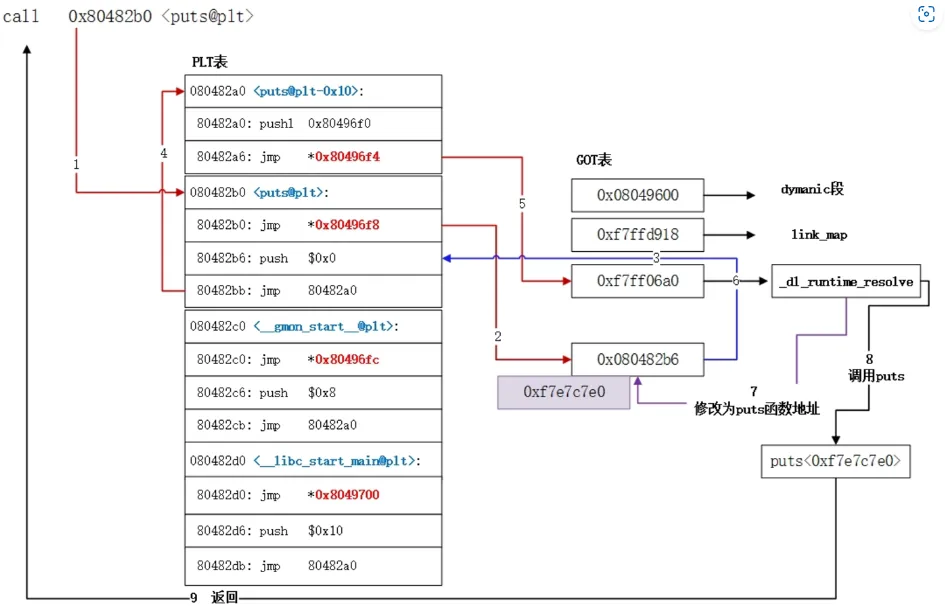
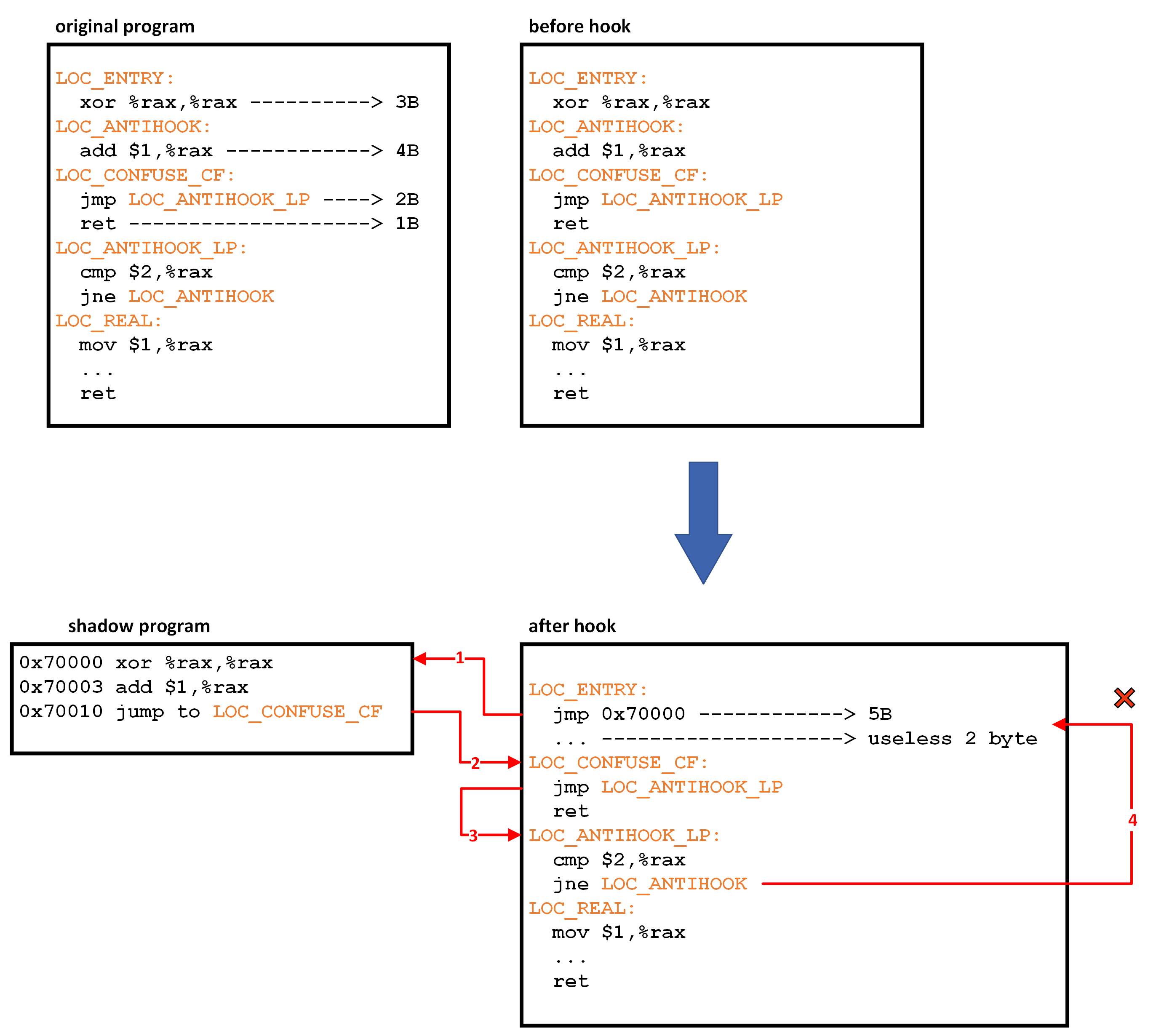
0x01-1-4 hook (1)PLT/GOT hook。GOT/PLT 挂钩是通过修改 GOT/PLT 段的地址来实现的。
1 2 3 4 5 6 7 GOT(全局偏移表)位于数据段中,它将记录外部符号的地址映射,外部符号包含变量和函数。然而,库在加载到内存时并没有固定的地址,所以GOT不能直接保存符号的地址。 PLT(过程链接表)位于代码段中,库中的每个外部函数都将记录在PLT中。每个PLT的记录都是一个小的可执行代码。PLT的记录将跳转到 .GOT 中的函数调用。 在编译阶段,-fPIC参数将生成与位置无关的代码。如果库不使用-fPIC参数,则当加载到进程的内存时,库文件需要重新定位并更改其代码段(意味着我们需要重复的库)。如果库使用-fPIC,则库将使用相对地址,因此我们不需要更改库代码段。当调用函数时,它将首先跳转到PLT,然后根据GOT的记录跳转到实际的函数地址。在首次调用外部函数之前,GOT表不记录其地址,这是因为linux使用了延迟绑定技术。 GOT表的记录最初都保存dl_runtime_resolve函数。当首次调用外部函数时,将跳转到PLT,然后根据GOT的记录跳转到dl_runtime_resolve函数地址。此函数将把实际的外部函数地址写入GOT的记录。
(2)inline hook。
1 2 3 4 反 hook: (1)RIP 地址。 (2)short jump。跳转到一个地址,但是是 256 字节内。 (3)jump back,如下图:
(3)普通 hook,先 unhook,执行正常逻辑,然后再 hook。 0x01-1-5 Go 逆向的点 0x01-1-6 C++ 虚表判定 1 2 3 (1)构造函数中使用 lea 0xxxxx(%rip),%rdx 的方式拿到虚表。 (2)一个单独的类(无父类)虚表指针是成员变量的第一个成员。 (3)C++ 对象在构造函数中初始化虚表指针,虚表指针指向类的虚表。
0x01-1-7 rust 逆向的点 0x01-1-8 flutter 逆向的点 0x01-1-9 安卓逆向 Frida 与 Xposed 原理 1 2 Frida 主要是通过将一个代理库注入到目标进程中,然后利用这个库提供的接口执行 JavaScript 脚本,实现对目标进程的控制。 Xposed 则是在 Android 系统级别工作,通过修改 Zygote 进程(Android 中所有应用进程的父进程)来影响后续启动的所有应用。
Exception hook 原理 1 2 3 4 5 Windows: Structured Exception Handling (SEH): 是一种基于栈的异常处理机制,函数内部设置异常处理代码,当发生异常时,Windows 会从当前函数开始向上遍历调用栈 Vectored Exception Handling (VEH) 先于 SEH 处理程序执行。 Linux: 异常处理通常通过信号(Signals)机制实现。当程序遇到错误时,操作系统会发送一个信号给进程。
Ptrace & ebpf原理 1 2 Ptrace:GDB的基础 ebpf 原理:允许在内核中运行沙箱化的程序,而无需修改内核代码或加载模块。eBPF 程序可以附加到各种内核事件(如系统调用、网络包、文件访问等),并收集数据。
ARM汇编:寄存器,调用约定(包括其他CPU架构),跳转指令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 1. 寄存器: R0-R12:通用寄存器,用于存储数据和地址。 R13 (SP):堆栈指针,指向当前堆栈的顶部。 R14 (LR):链接寄存器,用于保存子程序返回地址。 R15 (PC):程序计数器,指向当前执行的指令地址。 CPSR (Current Program Status Register):当前程序状态寄存器,包含条件标志位和其他控制位。 SPSR (Saved Program Status Register):保存的程序状态寄存器,用于模式切换时保存 CPSR 的值。 2. 调用约定:AAPCS (ARM Architecture Procedure Call Standard) 2-1. 参数传递:前四个参数使用 R0-R3 寄存器传递。剩余的参数通过堆栈传递。如果参数是浮点数,可以使用 VFP/SIMD 寄存器 S0-S15 或 D0-D7 传递。 2-2. 返回值:返回值通常通过 R0 寄存器传递。如果返回值是浮点数,可以使用 S0 或 D0 传递。 2.3. 寄存器使用: R0-R3:用于传递参数和返回值,调用者保存。 R4-R11:用于保存局部变量,被调用者保存。 R12:临时寄存器,调用者保存。 R13 (SP):堆栈指针,被调用者保存。 R14 (LR):链接寄存器,调用者保存。 R15 (PC):程序计数器,自动管理。 3. 常见的 ARM 跳转指令: B (Branch):无条件跳转到指定地址 BL (Branch with Link):跳转到指定地址,并将返回地址保存到 LR 寄存器。 BX (Branch and Exchange):跳转到指定地址,并切换到目标地址的指令集(Thumb 或 ARM)。
Thumb 或 ARM指令集的区别 1 2 3 4 ARM 指令集:指令长度固定为 32 位(4 字节)。支持更丰富的指令集和更复杂的操作。 Thumb 指令集:指令长度固定为 16 位(2 字节)。指令集相对简单,但足以覆盖大多数常见的操作。 ARM 指令集:占用更多的内存空间。适用于对性能要求较高的场景,如高性能计算和复杂算法。 Thumb 指令集:用于对代码大小敏感的嵌入式系统,如微控制器和移动设备
DEX结构、ELF结构、反编译过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 DEX(Dalvik Executable)文件是 Android 应用程序的字节码格式,用于在 Dalvik 虚拟机(现在是 ART 虚拟机)上运行。ELF(Executable and Linkable Format)是一种常见的二进制文件格式,用于可执行文件、共享库和对象文件。 DEX 文件反编译 (1)提取 DEX 文件:从 APK 文件中提取 DEX 文件。 (2)解析 DEX 文件:使用工具(如 dexdump)解析 DEX 文件的结构。 (3)反编译字节码:使用工具(如 dex2jar 和 JD-GUI)将 DEX 文件转换为 Java 字节码(.class 文件)。 (4)查看源代码:使用反编译工具(如 JD-GUI)查看和分析 Java 源代码。 ELF 文件反编译 (1)提取 ELF 文件:从目标文件中提取 ELF 文件。 (2)解析 ELF 文件:使用工具(如 readelf)解析 ELF 文件的结构。 (3)反汇编:使用工具(如 objdump)将 ELF 文件反汇编为汇编代码。 (4)高级反编译:使用工具(如 IDA Pro 或 Ghidra)将汇编代码转换为更高层次的伪代码或 C 代码。 (5)分析源代码:查看和分析反编译后的代码。
Java反射、静态代理和动态代理 1 2 3 Java 反射(Reflection)允许程序动态地调用对象的方法和访问字段。动态创建对象:可以在运行时创建任意类的对象。动态调用方法:可以在运行时调用任意类的方法。动态访问字段:可以在运行时访问任意类的字段。 静态代理指的是编译时就已经确定的代理类。代理类和目标类实现了相同的接口,通过代理类来间接调用目标类的方法。动态代理是指在运行时动态生成代理类,Java 提供了 java.lang.reflect.Proxy 类和 java.lang.reflect.InvocationHandler 接口来实现动态代理。
反调试和反反调试、ollvm(反混淆) 1 2 3 4 5 6 7 安卓反调试: (1)isDebuggerConnected() - hook (2)检查 /proc 文件系统中的 status 文件,可以判断当前进程是否被调试(tracerPid)- 手动修改 /proc/<pid>/status 文件中的 TracerPid 值为 0 (3)ptrace 的返回值(是否是-1)来判断是否被调试 - hook (4)adb Process process = Runtime.getRuntime().exec("getprop ro.debuggable"); - adb shell setprop ro.debuggable 0 (5)系统中是否存在 frida、Xposed 相关的文件和进程,检查 zygote 进程的状态 (6)检查设备是否是模拟器
加固与脱壳(整体加固、指令抽取、指令转换/vmp、java2c) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 整体加固: 1.1 代码混淆 字符串加密:将字符串常量加密,运行时解密。 类名、方法名、变量名混淆:使用无意义的名称替换原有的类名、方法名和变量名。 控制流扁平化:将代码的控制流结构打乱,增加逆向工程的难度。 1.2 资源加密 资源文件加密:对 APK 中的资源文件(如图片、XML 文件等)进行加密,运行时解密。 Dex 文件加密:对 DEX 文件进行加密,运行时解密并加载。 1.3 反调试 检测调试器:使用 Debug.isDebuggerConnected() 等方法检测调试器。 检测模拟器:检测设备是否为模拟器。 检测 root 权限:检测设备是否被 root。 1.4 反逆向 完整性校验:对 APK 文件进行完整性校验,防止被篡改。 动态代码加载:使用动态加载技术,延迟加载关键代码。 指令抽取:指令抽取是指将程序的关键指令提取出来,存储在不同的位置,然后在运行时动态加载和执行。 2.1 指令分段 分割指令:将指令分成多个部分,存储在不同的位置。 动态加载:在运行时动态加载和拼接指令。 2.2 指令加密 指令加密:对提取的指令进行加密,运行时解密。 动态解密:在运行时动态解密指令并执行。 指令转换:Java2C 是一种将 Java 代码转换为 C 代码的技术,通常用于保护 Android 应用程序。通过将关键的 Java 代码转换为 C 代码,可以利用 C 语言的编译优化和保护机制来增加逆向工程的难度。 4.1 代码转换 Java 到 C 转换:将关键的 Java 代码转换为 C 代码。 编译成 Native 代码:将 C 代码编译成 Native 代码(.so 文件)。 4.2 代码混淆 C 代码混淆:对生成的 C 代码进行混淆,增加逆向工程的难度。 数据加密:对数据进行加密,运行时解密。 4.3 动态加载 动态加载 Native 代码:在运行时动态加载和执行 Native 代码。
Unicorn框架原理、VirtualApp框架原理 1 2 3 Unicorn 通过模拟 CPU 的指令执行过程。 VirtualApp 是一个 Android 应用虚拟化框架,允许在一个应用中运行多个独立的虚拟应用环境。VirtualApp 通过动态代理、类加载器和系统 API 拦截等技术,实现应用的隔离和虚拟化。
安卓虚拟机(Davilk和ART)、JIT和AOT 1 2 3 Dalvik 虚拟机是 Android 早期使用的虚拟机,它基于寄存器架构,主要运行 DEX(Dalvik Executable)格式的字节码。与 JVM 的栈架构不同,Dalvik 使用寄存器架构,Dalvik 使用 JIT 编译技术,在运行时将字节码编译为本地机器码。 ART 是 Android 5.0(Lollipop)它取代了 Dalvik 虚拟机,提供了更好的性能和内存管理。ART 使用 AOT 编译技术,在安装时将 DEX 字节码编译为本地机器码,生成 OAT(Optimized ART)文件。
HTTPS证书校验(单向、双向校验)、中间人攻击 1 单向:客户端验证服务器的证书,但服务器不验证客户端的证书。
安卓系统安全机制(权限控制、签名校验)、so加载流程(linker) 1 应用程序在 AndroidManifest.xml 文件中声明权限。
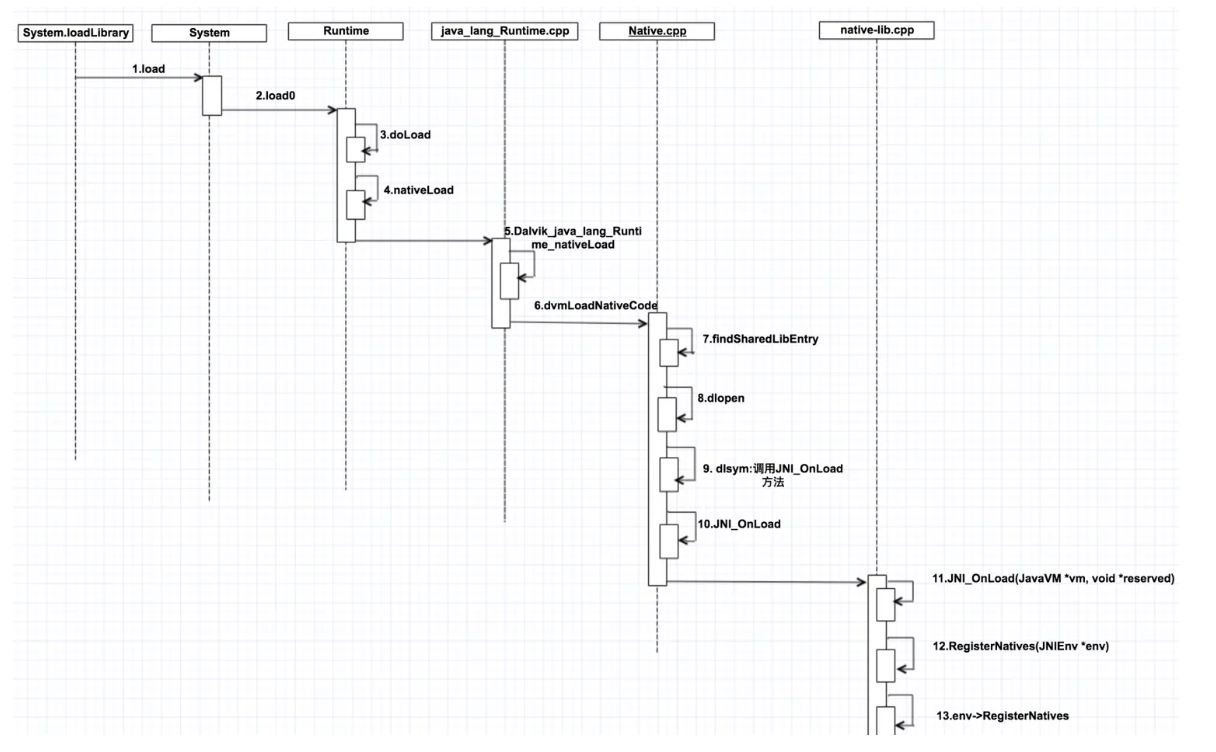
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 so加载流程 2.1 加载请求 (1)dlopen:显式调用 dlopen 函数加载共享库。 (2)系统调用:在程序启动时,动态链接器自动加载程序依赖的共享库。 (3)JNI:在 Java 代码中使用 System.loadLibrary 方法加载共享库。 2.2 动态链接器解析 (1)查找共享库:动态链接器根据库名查找共享库文件的位置。或者在 /system/lib、/vendor/lib、/data/app-lib、LD_LIBRARY_PATH 等中搜索。 (2)打开文件:open 系统调用打开共享库文件。 (3)读取 ELF 头:读取共享库文件的 ELF 头,获取文件的基本信息,如入口点、程序头表、节头表等。 (4)映射文件:mmap 系统调用将共享库文件映射到内存中。这包括代码段、数据段、BSS 段等。 2.3 重定位 (1)解析符号:解析共享库中的符号表,找到需要链接的函数和变量。 (2)重定位:根据重定位表更新共享库中的地址引用。重定位表包含需要更新的地址和对应的符号信息。 2.4 初始化 执行构造函数:动态链接器调用共享库中的构造函数(如 __attribute__((constructor)) 标记的函数)。 如果共享库中有 init_array 段,动态链接器会按顺序调用 init_array 段中的函数。 调用 JNI_OnLoad:如果共享库是 JNI 库,动态链接器会调用 JNI_OnLoad 函数。JNI_OnLoad 用于注册 Java 类中的本地方法。 2.5 返回句柄:返回一个句柄(void* 类型),该句柄可以在后续的 dlsym 和 dlclose 调用中使用。 dlsym:根据句柄和符号名获取函数地址。
安卓系统启动流程、Zygote启动流程、APP启动流程 1 2 3 4 5 安卓系统启动流程: (1)Bootloader 初始化硬件设备。 (2)初始化 Linux 内核。 (3)启动 Init 进程,/init.rc。 (4)启动 Zygote 进程。绑定到一个特定的 Socket(通常是 local:zygote),等待来自 ActivityManagerService 的启动请求,fork 系统调用创建一个新的子进程。
Activity和Service的生命周期、Binder通信机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Activity 是 Android 中的一个重要组件,用于表示一个单一的屏幕: onCreate(Bundle savedInstanceState):活动创建时调用。通常在这里进行初始化操作,如设置布局、初始化变量等。 onStart():活动变得可见时调用。 onResume():活动开始与用户交互时调用。此时活动位于前台,可以接收用户的输入。 onPause():通常在这里保存活动的临时状态,释放可能消耗大量资源的对象。 onStop():活动不再可见时调用。通常在这里释放更多资源。 onRestart() onDestroy() onSaveInstanceState(Bundle outState):系统即将开始暂停活动并可能被销毁时调用,用于保存活动的临时状态 Service 用于在后台执行长时间运行的操作或执行需要在后台运行的任务: onCreate():服务第一次创建时调用。通常在这里进行初始化操作。 onStartCommand(Intent intent, int flags, int startId):返回值决定服务被杀死后的行为。 onBind(Intent intent):如果服务被绑定到客户端,此方法被调用。返回一个 IBinder 对象,用于客户端和服务之间的通信。 onUnbind(Intent intent):当所有客户端都解除绑定时调用。 onDestroy() Binder 是 Android 中的一种进程间通信(IPC)机制,用于实现不同进程之间的通信。Binder 机制基于客户端-服务端模型,客户端通过 Binder 与服务端进行通信。 Windows 的 IPC 机制有哪些?共享内存,命名管道
如何从海量的APP找出一个二次打包的应用 有几种思路(流量特征,代码相似度检测,UI节点遍历等)
Android 的 init_array 和 JNI_OnLoad 的时机问题,如何绕过 init_array 段中的反调试 1 2 3 4 5 6 7 8 9 10 init_array 段(ELF),用于存储一组函数指针。这些函数在程序启动时按顺序调用,通常用于执行全局对象的构造函数或其他初始化任务。 1.1 执行时机 加载时:当动态链接器加载共享库时,会解析 init_array 段并按顺序调用其中的函数。 优先级:init_array 段中的函数在 JNI_OnLoad 之前调用。 1.2 作用 全局对象构造:用于构造全局对象。 JNI_OnLoad 用于在 Java 代码和本地代码之间建立连接,在 JVM 加载本地库时被调用。 2.1 执行时机:当 JVM 加载本地库时,会调用 JNI_OnLoad 函数。 2.2 作用:用于注册 Java 类中的本地方法。
so 函数定位 可以自己执行 so 文件中的函数,在自己 App 项目中建立签名类(具体的 native 方法定义通过反编译技术获取),要注意的是包名和类名要和原 App 一致。或者可以这样运行:
1 2 3 (1) 在JDK环境下建立签名类,最后打包成 jar 包; (2) 将 so 文件放在系统的 lib 或 lib64 文件下; (3) 调用 jar 包中的类即可;
对于函数名加密(没有符号表)的时候,可以用 objection hook 一下,其中有 JNI 静态注册(默认)与动态注册。
1 2 3 JNI_OnLoad 是在加载 so 的时候调用的。 (1)静态注册:通过 JNIEXPORT 和 JNICALL 两个宏定义声明,在虚拟机加载 so 时发现上面两个宏定义的函数时就会链接到对应的 native 方法。JNI 层名称为:Java_包名_类名_方法名。 (2)动态注册:通过 RegisterNatives 方法手动完成 native 方法和 so 中的方法的绑定,这样虚拟机就可以通过这个函数映射表直接找到相应的方法了。
如果 Native 采用的静态注册,那可以通过grep命令在libs文件夹下进行筛选,如果 Native 方法采用的是动态注册,有 objection 脚本,能够一步到位的定位到 Native 方法注册地址和所在的 so 文件。最终可以找到方法在 so 文件的偏移。
对于动态注册:
Frida 与 Xposed 1 2 3 4 5 6 7 8 9 10 11 12 1. frida 相关,默认以attach模式。 两种操作模式: (1)CLI模式:通过命令行将js脚本注入到进程中。 frida -U com.android.settings -l hello.js (2)RPC模式:通过py脚本间接完成js脚本的注入。 两种操作App的方式: (1)spawn(调用)模式:将启动App的权利交给Frida来控制,即使目标App已启动,在使用Frida对程序进行注入时,还是会重新启动App并注入。frida -f就会调用spawn模式。 (2)attach(附加)模式:在目标App已启动的前提下,利用ptrace原理注入程序进而完成Hook操作,默认以attach模式注入。 2. 两者比较: Xposed 可以在一个函数中完成针对所有进程的 hook,在 zygote 重新启动后生效,对系统影响较大,需要 root。而 frida 是单进程级别的hook,还可以 hook windows/ios,不需要 root。
objection 1 2 objection -g com.cz.babySister explore android hooking watch class <class_name> // 钩取某个类中所有非构造函数
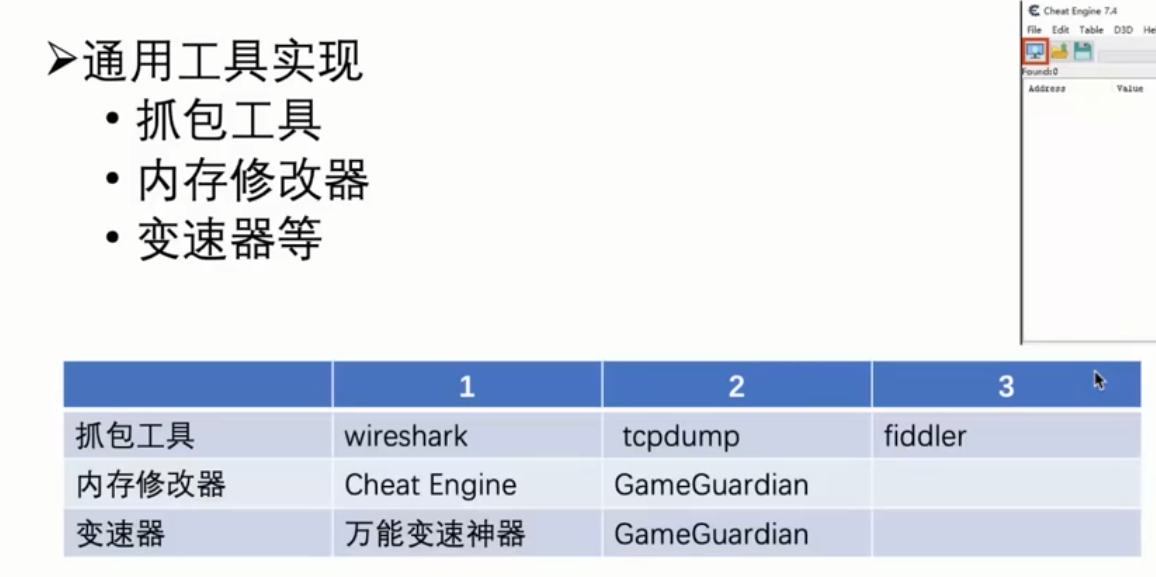
抓包 1 2 3 4 5 1. 沙箱,修改安卓源码。 2. 中间人(wifi 代理/vpn 代理)。 a. wifi 代理弊端:无法处理非http通信,例如websocket;容易被app检测到。 b. vpn 代理。相当于虚拟新网卡并修改手机路由表,工具为postern(注意要匹配所有地址)。 c. 反抓包:反 wifi 代理、反 VPN 代理、服务器校验客户端/客户端校验服务器(CA 证书层面),例如,(1)app 使用特定 API(Proxy.NO_PROXY`、System.getProperty("http.proxyHost")`等)检测来防止 wifi 代理;(2)使用 `getNetWorkCapbilities()` 来检测网络接口,从而检测 VPN app。(3)客户端校验服务器,即在客户端和服务器进行握手时,验证 CA 的 hash 值,来达到只与持有相同 CA 的服务器进行通信,而服务器只与持有特定 CA 的客户端进行交互。
修改设备信息 1 2 3 4 设备的相关信息(设备指纹/设备名称/设备型号)都是通过 android.os.Build 类中的成员值得到的。 (1)IMEI 设备的唯一标识,由 15 位数字组成。 (2)IMSI 是移动网络中区分不同用户的识别码,其存储在 SIM 卡中,由 15 位数字组成。 (3)Android_id 是设备第一次启动时产生与存储的 64 bit 数,也叫做 SSAID(Settings.Secure.ANDROID_ID)。此值只有在设备被刷机或者恢复出厂设置时才会被修改。
如何定位关键类 1 2 3 1. jeb jadx 反汇编看。 2. hook 相关类。 3. 抓包。
为什么有时候 classloader 找不到? 1 时机不对,即类加载器ClassLoader在加固应用启动时切换,从而导致上述情况。具体而言,app中的类都是对应的ClassLoader加载到ART虚拟机中的,如果ClassLoader不正确,那么就无法找到对应的类。`当加固应用启动时,app的当前ClassLoader会发生切换,故而出现上述情况`。
app加固方法 0x01-1-10 python 逆向的点 0x01-1-11 寄存器 1 2 3 4 5 6 7 8 9 10 EBP:(SS段中栈内数据指针)扩展基址指针寄存器 ESI:(字符串操作源指针)源变址寄存器 EDI:(字符串操作日标指针)目的变址寄存器 ESP:(SS段中栈指针)栈指针寄存器 CS:Code Segment,代码段寄存器 SS:Stack Segment,栈段寄存器 DS:Data Segment,数据段寄存器 ES:Extra (Data)Segment,附加(数据)段寄存器 FS:Data Segment,数据段寄存器,它用于计算SEH(Structured Exception Handler,结构化异常处理机制)、TEB(Thread Environment Block,线程环境块)、PEB(Process Environment Block,进程环境块)等 GS:Data Segment,数据段寄存器
0x01-1-11 栈
栈帧:栈帧就是利用EBP(不是ESP)寄存器访问内局部变量、参数函数返回地址等的手段。最新的编译器中都带有一个优化(Optimization)选项,使用该选项编译简单的函数将不会生成栈帧。
0x01-1-12 调用约定 1 2 3 cdecl 方式,主要在 C 语言中使用,函数调用者负责处理栈,就是把函数调用时 push 进去的参数给消除。就像 printf 函数一样,可以向函数传递长度可变的参数,这种功能在其他调用方式中很难实现。 stdcall 方式,常用于win32 API,栈的清理工作由被调用者完成, fastcall 方式,使用寄存器传递前两个参数,而不是使用栈。其调用速度快。
0x01-1-12 PE 文件格式与加载流程
1 2 3 4 5 6 7 8 9 10 11 (1)DOS 头: e_magic //DOS签名(signature,4D5A=>ASCII值"MZ",MZ是一个开发人员的名字首字母,好帅) elfanew //指示NT头(IMAGE_NT_HEADERS)的偏移,下图的elfanew=000000E0(小端序) (2)DOS 存根:由代码与数据混合而成,灵活使用该特性可以在一个可执行文件(EXE)中创建出另一个文件,它在DOS环境中运行16位DOS代码,在Windows环境中运行32位Windows代码,这种特性叫做MS-DOS兼容。 (3)NT 头: Machine // 每种CPU都有自己唯一的mechine码 NumberOfSections // 文件中的节区数量 TimeDateStamp // 记录编译器创建此文件的时间 SizeOfOptionalHeader // 指明IMAGE_OPTIONAL_HEADER32(PE)或IMAGE_OPTIONAL_HEADER64(PE+)长度 Characteristics // 指明文件是否可运行(0002H),是否为DLL(2000H) (4)EXE生成的PE文件的重定位表对应的节区名为 .reloc(一般是最后一个节区)
1 2 3 4 5 6 7 PE 文件加载流程 1、将PE文件从磁盘中读出 2、根据PE结构获取镜像大小,再申请一段可读可写可执行的内存,并填充为0 3、将读取的数据映射到内存中 4、修复导出导入导出表 5、修复重定位 6、跳转到PE入口点进行执行
1 2 3 4 5 6 PE loader 把导入函数输入到 IAT 的顺序 1. 读取IMAGE_IMPORT_DESCRIPTOR的Name,获得库名称字符串"kernel32.dll" 2. LoadLibrary("kernel32.dll") 3. 读取OriginalFirstThunk中的函数名,并在kernal32.dll找到对应地址(GetProcAddress("GetCurrentThreadld")) 4. 将地址填入FirstThunk对应地址 5. 重复3-4,直到OriginalFirstThunk结束
0x01-1-13 各种表 1 2 3 IAT 导入地址表 属于NT可选头的,记录程序正在使用哪些库中的哪些函数。 EAT(导出地址表)。 SDT(段描述符表)。
0x01-1-14 DLL 相关 1 2 3 加载DLL的方式有两种: (1)显式链接(Explicit Linking)程序使用DLL时加载,使用完毕后释放内存。 (2)隐式链接(Implicit Linking)程序开始时加载DLL,程序终止时再释放占用的内存。即隐式链接的DLL生命周期更长。
0x01-1-15 mmap/malloc/brk 申请内存空间一般就两种方法,一种是 malloc,另一种是 mmap 映射空间。 在使用 malloc() 分配内存的时候,可能系统调用 brk(),也可能调用 mmap()。
1 2 3 4 5 6 7 malloc 调用: 1. 当分配一块小内存(小于或等于128kb),malloc()会调用brk()调高堆顶(brk是将数据段(.data)的最高地址指针_edata往高地址推),分配的内存在堆区域。 a. 通过 brk() 方式申请的内存,free 释放内存的时候,并不一定会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用,这样就可以重复使用。 b. 优点:可以减少缺页异常,提高内存访问效率。 c. 缺点:由于申请的内存没有归还系统,频繁的内存分配和释放会造成内存碎片。brk()方式之所以会产生内存碎片,是由于brk通过移动堆顶的位置来分配内存,并且使用完不会立即归还系统,重复使用,如果高地址的内存不释放,低地址的内存是得不到释放的。 2. 当分配一块大内存(大于128kb),malloc()会调用mmap()分配一块内存(mmap是在进程的虚拟地址空间中(一般是堆和栈中间)找一块空闲的空间。 a. mmap()是以页为单位进行内存分配和管理的,释放后就直接归还系统了,所以不会出现小碎片的情况。
brk()的实现的方式很简单,就是通过 brk() 函数将堆顶指针向高地址移动,获得新的内存空间。
mmap 是一种内存映射文件的方法,即将一个文件或者其他对象映射到进程的地址空间。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必调用 read/write 等系统调用函数。
mmap 的实现原理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1. linux 内核使用 vm_area_struct 结构来表示一个虚拟内存区域(例如 BSS 段),同一个进程使用多个 vm_area_struct 结构来分别表示不同类型的虚拟内存区域。各个 vm_area_struct 结构使用链表链接,方便进程快速访问。 Step1:进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域。 a. 进程在用户空间调用函数 mmap b. 在当前进程虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址 c. 为此虚拟区分配一个 vm_area_struct 结构,接着对这个结构各个区域进行初始化 d. 将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表中 Step2:调用内核空间的系统调用函数 mmap (不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射。 a. 为映射分配新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核中相应的文件结构体,每个文件结构体维护者和这个已经打开文件相关各项信息。 b. 通过该文件的文件结构体,链接到 file_operations 模块,调用内核函数mmap,不同于用户空间库函数。 c. 内核 mmap 函数通过虚拟文件系统 inode 模块定位到文件磁盘物理地址。 d. 通过 remap_pfn_range 函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。 Step3:进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝。 a. 前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据拷贝至主存。真正的文件读取是当进程发起读或者写操作时。 b. 进程的读写操作访问虚拟地址空间这一段映射地址后,通过查询页表,先这一段地址并不在物理页面。因为目前只建立了映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。 c. 缺页异常进行一系列判断,确定无法操作后,内核发起请求掉页过程。 d. 调页过程先在交换缓存空间中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。 e. 之后进程即可对这片主存进行读或者写的操作了,如果写操作改变了内容,一定时间后系统自动回写脏页面到对应的磁盘地址,也即完成了写入到文件的过程。注:修改过的脏页面并不会立即更新回文件,而是有一段时间延迟,可以调用msync() 来强制同步,这样所写的内容就能立即保存到文件里了。
0x01-1-16 加壳 1 2 3 windows: 普通的压缩器有:UPX、ASPack、ASProtect、VMP 壳。 针对病毒等恶意文件的压缩器:UPack、PESpin、NSAnti,其会对源文件进行较大变形,严重破坏PE头。
0x01-1-17 windows 消息勾取& DLL 注入 & 代码注入 1 2 3 4 5 6 7 8 (1)Windows操作系统向用户提供GUI(Graphic User Interface,图形用户界面),它以事件驱动(Event Driven)方式工作。发生此类事件时,OS会把事先定义好的消息发送给相应的应用程序,应用程序分析收到的信息后执行相应动作。也就是说,敲击键盘时,消息会从OS移动到应用程序。 (2)Windows消息处理流如下所示: 1. 发生键盘输入事件时,WM_KEYDOWN消息被添加到[OS message queue] 2. OS判断哪个应用程序中发生了事件,然后从[OS message queue]取出消息,添加到相应应用程序[applicationmessage queue]中 3. 应用程序监视自身的[application message queue],发现新添加的WM_KEYDOWN消息后,调用相应的事件处理程序处理 (3)相关 API:SetWindowsHookEx() / UnhookWindowsHookEx()
进程注入DLL时(CreateRemoteThread)主体代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 DWORD WINAPI ThreadProc (LPVOID lParam) URLDownloadToFile (NULL , "http://www.naver.com/index.html" , szPath, 0 , NULL ); return 0 ; } BOOL WINAPI DllMain (HINSTANCE hinstDLL, DWORD fdwReason, LPVOID lpvReserved) case DLL_PROCESS_ATTACH : hThread = CreateThread (NULL , 0 , ThreadProc, NULL , 0 , NULL ); CloseHandle (hThread); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 BOOL SetPrivilege (LPCTSTR lpszPrivilege, BOOL bEnablePrivilege) if ( !LookupPrivilegeValue (NULL , lpszPrivilege, &luid) ) if ( !AdjustTokenPrivileges (hToken, FALSE, &tp, sizeof (TOKEN_PRIVILEGES), (PTOKEN_PRIVILEGES) NULL , (PDWORD) NULL ) ) } BOOL InjectDll (DWORD dwPID, LPCTSTR szDllPath) if ( !(hProcess = OpenProcess (PROCESS_ALL_ACCESS, FALSE, dwPID)) ) pRemoteBuf = VirtualAllocEx (hProcess, NULL , dwBufSize, MEM_COMMIT, PAGE_READWRITE); WriteProcessMemory (hProcess, pRemoteBuf, (LPVOID)szDllPath, dwBufSize, NULL ); hMod = GetModuleHandle (L"kernel32.dll" ); pThreadProc = GetProcAddress (hMod, "LoadLibraryW" ); hThread = CreateRemoteThread (hProcess, NULL , 0 , pThreadProc, pRemoteBuf, 0 , NULL ); WaitForSingleObject (hThread, INFINITE); }
1 2 3 4 5 (2)还可以用注册表进行 dll 注入: 在注册表编辑器中,将要注入的DLL的路径字符串写入AppInit_DLLs,然后重启。User32.dll被加载到进程时,会读取AppInit_DLLs注册表项。所以,相应DLL并不会被加载到所有进程,而只是加载至加载user32.dll的进程。 (3)DLL 卸载:FreeLibrary。
DLL 加载流程:
1 2 3 4 1. 定位。当应用程序请求加载一个 DLL 时,系统首先检查该 DLL 是否已经加载到进程的地址空间中。如果已加载,系统就会重用现有的加载实例,不会重复加载相同的 DLL。如果 DLL 尚未加载,系统将搜索DLL文件。搜索顺序可能包括应用程序的目录、系统目录(如System32)、环境变量指定的路径等。 2. 加载。通过文件映射和内存映射的技术完成的,意味着DLL文件的内容被映射到进程的虚拟内存中。(LoadLibrary/dlopen) 3. 解析导入表。 4. 执行 DLLmain。
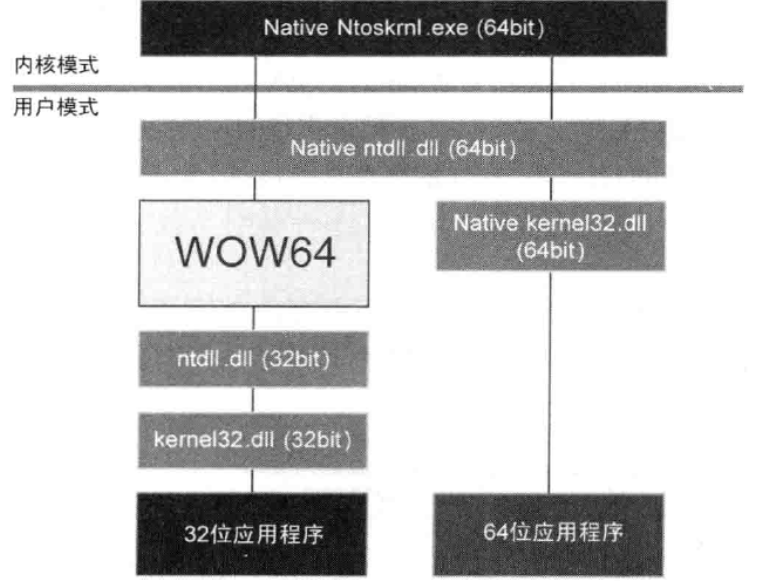
0x01-1-18 x64 逆向注意的点 (1)WOW64(windows on windows 64)的机制,使得32位程序在64位程序中正常运行。64位应用程序会加载kernel32.dll(64位)与ntdll.dll (64位)。而32位应用程序则会加x64载kernel32.dll(32位)与ntdll.dll(32位),WOW64会在中间将ntdll.dll(32位)的请求(API调用)重定向到ntdll.dll(64位)。
(2) windows下有SysWOW64与System32两个文件夹,SysWOW64中存放32位dll,当运行32位程序时,就用这个,映射到System32文件夹下的dll中。System32存放64位dll。
(3)处理器增加了 16 个 XMM 寄存器。 64位系统中不使用段寄存器。
(4)x64进程虚拟内存大小为16TB,32位进程虚存仅为4GB。
0x01-1-19 OLLVM 与 LLVM
1 2 3 4 OLLVM 混淆方式: (1)Instructions Substitution(加减法、逻辑运算) (2)Bogus Control Flow(虚假控制流:BCF) (3)Control Flow Flattening(控制流平坦化:CFF)
去 OLLVM,unicorn/angr 模拟执行,unicorn 相当于一个虚拟 cpu,所以处理的细微程度高于 angr 的代码块级,修复出来的代码精度更高。
1 通过代码的CFG图,分析出代码块之间的关系,然后模拟执行每个代码块。
代码优化 LLVM IR pass
1 2 3 4 5 6 7 8 9 10 11 12 13 14 代码优化的实质是分析+转换。 LLVM Pass 是 LLVM 代码优化中的一个重要组成部分。我们可以将 Pass 看作一个又一个的模块,各个 Pass 可以通过 IR 获取信息,直接对中间代码进行优化,或者为下一个 Pass 做好准备。 常见的代码优化方法有: 1. 删除公共子表达式。例如,x+y 以前被计算过,且一段时间内 x 与 y 中的变量值没有改变,则 x+y 就可以在这段时间内替换成一个常量。 2. 删除无用代码。即删除永远不会被使用的语句。 3. 常量合并。类似于 1,如果一个表达式的值为常量,那么就可以用常量替换这个表达式。 4. 代码移动。例如,对于不管循环多少次都得到相同结果的表达式,在进入循环之前对它们进行求值。 5. 强度削弱。例如,2*x 替换为 x+x。 6. 删除归纳变量。例如,x 每次被赋值时都会增加常数 c,则可以将 x 称为归纳变量。如果有一组归纳变量的变化步调一致,就可以将这组变量删除为只剩 1 个。 LLVM 中 Pass 框架有很高的可重用性与可控制性,这使得用户可以自己开发 Pass 模块,或关闭默认开启的 Pass。Pass 分为两类: 1. 分析,提供信息。 2. 转换,优化 IR。
0x01-1-20 TLS 1 2 3 4 (1)TLS(Thread Local Storage,线程局部存储)回调函数(Callback Function)常用于反调试。TLS回调函数的调用运行要先于EP代码的执行,该特征使它可以作为一种反调试技术使用。 (2)TLS是各线程的独立的数据存储空间,使用TLS技术可在线程内部使用或修改进程的全局数据,就像对待自身的局部变量一样。 (3)PE头文件就会设置TLS表。 (4)在进程初始与结束,会运行TLS。
0x01-1-21 调试器实现原理 1 2 3 4 5 6 1. 创建调试进程,使用的API是CreateProcess,创建标志是 DEBUG_ONLY_THIS_PROCESS。或者就是在程序运行起来,再使用调试器去附加使用的 API 是 DebugActiveProcess。 2. 等待调试器事件。被调试程序所发生的所有异常都会通过调试会话发送到我们的调试器进程中,然后我们就可以接收到异常事件,进行处理异常事件,WaitForDebugEvent。 3. 硬件断点,基于调试器寄存器来进行实现的,有8个调试寄存器,分别是Dr0 - Dr7。 4. 软件断点,把代码修改为0xCC,有一些指令会触发80000003异常,也就是断点异常。 5. 单步异常,在浮点寄存器中有一个标志叫单步标志,设置为 1 的时候,执行指令就会触发80000004异常。 6. 内存访问,异常内存访问异常就是通过修改内存属性,让其不可访问,这时候就会触发 C05 异常。
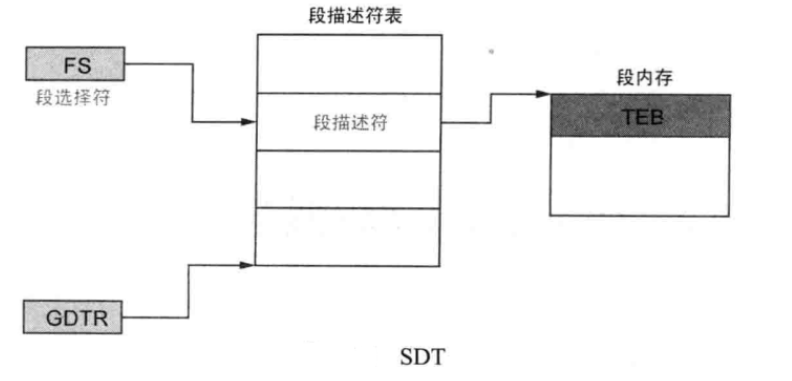
0x01-1-22 TEB & PEB 1 2 3 4 TEB(Thread Environment Block)指线程环境块 (1)该结构体包含进程中运行线程的各种信息,进程中的每个线程都对应1个TEB结构体。 (2)NtTib与ProcessEnvironmentBlock(PEB) (3)FS寄存器除了可以访问TLS,还指向当前线程的TEB。32位系统中进程的虚拟内存大小为4GB,因而需要32位的指针才能访问整个内存空间。但是FS寄存器的大小只有16位,那么它如何表示进程内存空间中的TEB结构体的地址呢?FS寄存器并非直接指向TEB结构体的地址,它持有SDT的索引,而该索引持有实际TEB地址。
0x01-1-23 寄存器传参 1 2 x64:RDI/RDI/RDX x86:fastcall 使用 ECX/EDX
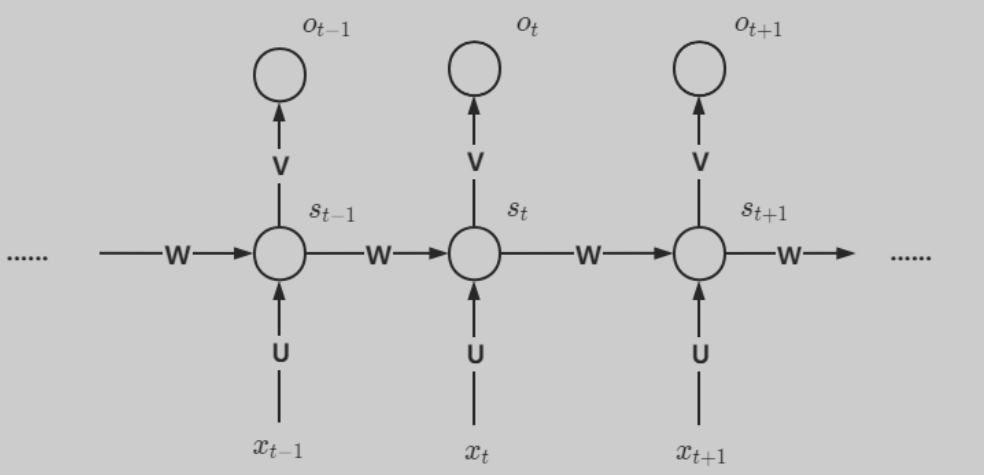
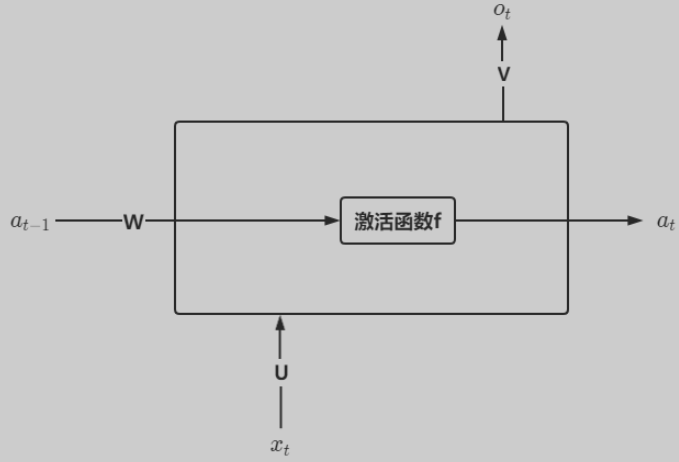
0x01-2 人工智能相关 0x01-2-1 RNN & LSTM & GRU 标准RNN结构输入为x,隐藏层为s,输出层为o,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,还有一个自循环矩阵W。
隐藏层s可以细化为:
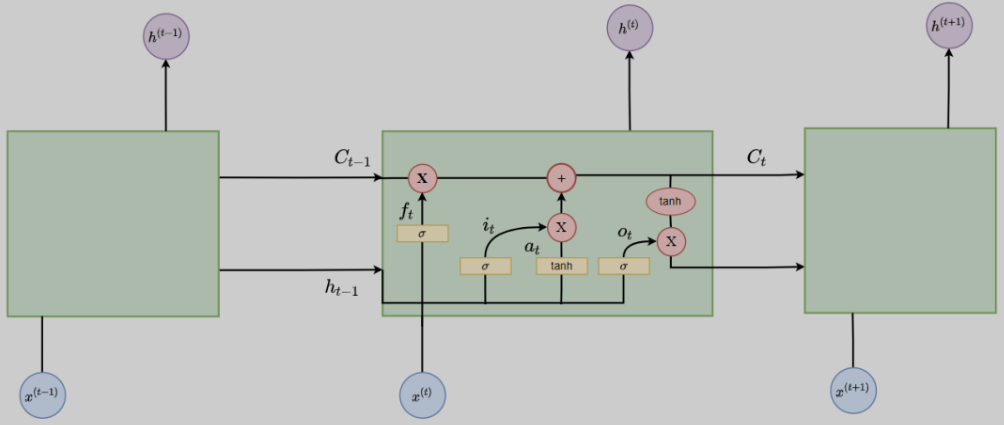
但是RNN有一个问题,即容易造成梯度消失或梯度爆炸问题,这就说明RNN不具备长期记忆,仅仅有短期记忆功能。 因此LSTM应运而生。网络结构如下:
LSTM每一个时刻t都增加一个隐藏状态C(细胞状态),并用两个门来控制它的内容:
遗忘门(Forget Gate),决定上一时刻的细胞状态C_{t-1}有多少保留到当前时刻细胞状态C_t。
输入门(Input Gate),决定当前时刻网络的输入x有多少保存到细胞状态C_t。然后再用输出门(Output Gate)来控制当前细胞状态C_t有多少输出到当前输出值h。
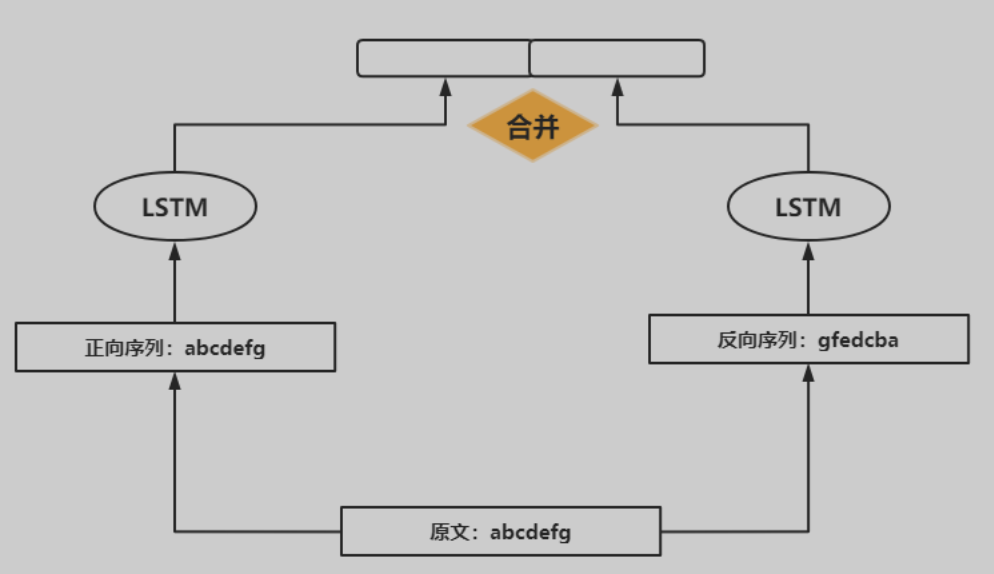
但是,LSTM复杂度较高 ,由此又有了GRU,其是LSTM的v2版本。上述所说的RNN、LSTM与GRU都是处理序列数据,但是利用的一般是前文信息,但是实际上很多场景都需要结合上下文才能综合判断,因此提出了双向循环神经网络。
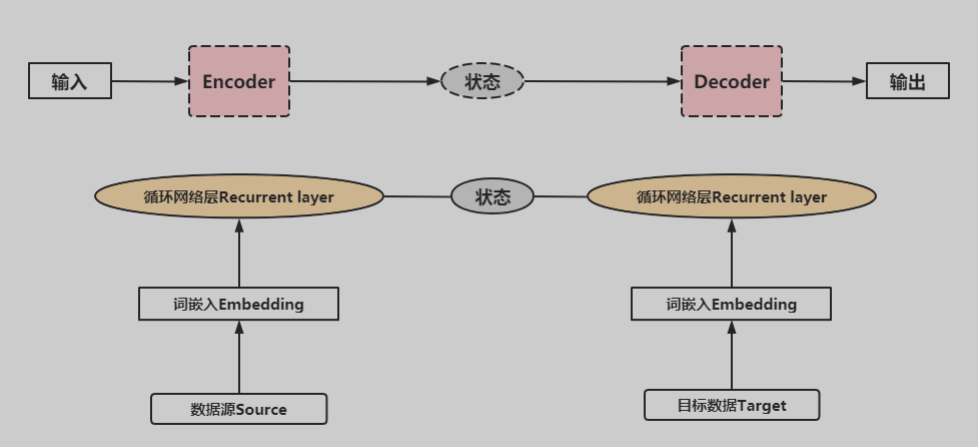
基于此网络构建的典型模型是Encoder-Decoder模型。
对于自编码模型可以理解为:从左到右,看作由一个句子(文章,段落等)生成另外一个句子(文章或段落)的通用处理模型。对于输入与输出都是序列的自编码模型,称之为Seq2Seq模型 。
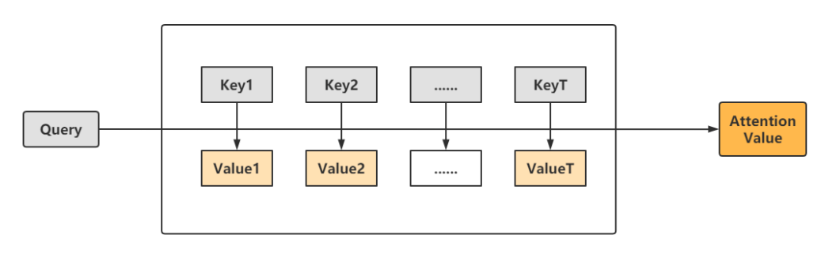
0x01-2-2 注意力机制(AM) Seq2Seq模型,无法应对句子很长的情况 ,于是注意力机制模型应运而生。注意力机制本质就是:输出句子中某个单词和输入句子中每个单词的相关性。 如下图所示:
上图中,key就是输入的每一个单词,value是这些单词对应的取值,称之为数据对,query是输出的某一个单词。给定一个query,计算其与各个key的相似度,得到权重系数,最后得到attention value值。对上述过程进行细分,可以分为:计算相似度、归一化处理、计算注意力3个部分。
Step1:计算相似度:余弦相似度和核函数。
Step2:归一化处理,得到了相似度s_i,之后进行归一化处理(一般使用softmax函数):
Step3:计算注意力
对比一下,不带注意力机制的Encoder-Decoder是这样的:
其中,C代表输入X放入Encoder之后编码成的中间向量,y代表输出的值,g代表Decoder。带注意力机制的Encoder-Decoder是这样的:
但是每句话输入长度不一样啊,这个矩阵的T不是固定的,那么模型是如何确定权重系数矩阵的呢?它是通过对齐函数F来获得目标单词和每个输入单词对应得对齐可能性,然后经过softmax函数进行归一化得到注意力分配概率分布数值。
0x01-3 软件分析相关 1 2 3 May Analysis 与 Must Analysis (1)May Analysis的初始fact为0,最终找出有哪些不是0的fact。例如Reaching Definitions Analysis,其意思是:假设有程序点p与q,在p点定义了变量x,且从p到q之间没有再定义x,那么说x的定值到达了p在此环境下,fact=0代表不可到达,fact=1代表可到达,我们想找不可达的,这样的话就可以把对应的语句删掉。May Analysis,程序满足一条路径即可。 (2)Must Analysis的初始fact为1,最终找出不是1的fact。例如Constant Propagation,其意思是:有程序点p与q,在q点定义了变量x,在q点使用了变量x,q点之前,再没有分支重新定义变量x,那么fact=1代表可常量传播,fact=0代表不可常量传播,我们想找可常量传播的,这样的话就可以传播常量。Must Analysis,程序必须满足所有路径。
0x01-3-1 指针分析 0x01-3-2 常量传播 & worklist 程序的P点有一个变量x,判断在P点是否可以保证x是一个常量。要考虑所有的路径上是否定义的值都一样,如果有两条路径是x=2,有一条是x=3,那显然不行,所以是must analysis。
1 为什么活跃变量分析是backward的,而常量分析是forward的呢?在某个点的变量是否活跃,是由后面的程序决定的。而在某个点的定义是否是常量,是由前面的程序决定的。
此算法不好的点是:如果有任意OUT变化了,所有的block都要重新计算。而对应的Worklist Algorithm为:
0x01-4 算法题 1 2 3 1. 给定一棵二叉树,要求求出其最大平均值:每一个节点下可能挂有若干个子节点,需要计算以这个节点为根节点的子树的所有节点之和除以节点数的道德的平均值,然后在所有子树中找到平均值最大的一个 解法为:后根序遍历,同时记录遍历到当前节点时一共遍历了几个节点,以及和是多少,遍历完左右根后再比较这个平均值和最终结果,取较大的一个
0x01-5 PWN 相关 ROP
代码混淆相关的汇编 1 代码混淆引起所使用的指令都是不常见的指令,我们可以一眼就识别出来比如 rcr,bt,btc,sbb,lahf等。
shellcode 判断与混淆 1 2 1. 使用msf生成的shellcode也是具有特征的,对shellcode进行处理可以消除特征。最基本的处理方式是异或加密,实现代码很简单。 2. 加壳
VMP 提供的保护 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 文件: (1)内存保护 - 此选项允许从任何更改中保护文件在内存中的映像(检查所有没有WRITABLE属性的部分的数据完整性)。在将控件传递给程序的原始入口点之前执行映像完整性检查。如果违反完整性,则会显示相应的消息,程序将停止执行。 (2)导入保护 - 此选项允许隐藏受保护程序使用的API列表。建议使用此选项以及输出文件的打包。 (3)资源保护 - 此选项加密程序的资源(图标,清单和其他服务资源除外)。 (4)打包输出文件 - 此选项允许打包受保护的文件以减小其大小。执行受保护文件时,将自动解压缩应用程序。整个解包没有任何磁盘写入,完全在RAM中。 重要提示:程序启动时,解压缩代码后,控件将传递给EntryPoint。如果EntryPoint的代码是虚拟化的,则此代码将在与解包器本身的代码相同的VM解释器上执行。EntryPoint的虚拟化与受保护文件的打包相结合,可防止手动解压缩受保护文件,因为在这种情况下,入侵者必须恢复EntryPoint代码才能获得工作文件映像。 额外的保护级别: (1)水印 - 允许为项目添加水印。 (2)VM段 - 编译文件时,会将新段添加到存储各种系统数据的位置(虚拟化和变异代码,VM解释器,水印等)。此选项允许指定这些新段的名称。建议将段的标准“.vmp”名称更改为其他名称(例如“.UPX”)。 (3)剥离调试信息 - 删除调试信息阻碍了破解者对代码的分析。 (4)剥离重定位 - 某些编译器(即Delphi)为EXE文件创建重定位表,操作系统不使用该重定位表来加载EXE文件。如果启用该选项,则重定位表占用的空间将用于VM需求。 检测: (1)调试器 - 此选项可防止调试受保护的文件。有两种类型的调试器:用户模式调试器(OllyDBG,WinDBG等)和内核模式调试器(SoftICE,Syser等)。在将控制传递给程序的入口点之前执行调试器检测。如果检测到调试器,则会显示相应的消息,程序将停止执行。 (2)虚拟化工具 - 此选项禁止在各种虚拟环境中执行受保护的文件:VMware,Virtual PC,VirtualBox,Sandboxie。在将控制传递到程序的入口点之前执行虚拟化的检测。如果检测到虚拟环境,则会显示相应的消息,程序将停止执行。
VMProtect虚拟机保护分析 1 2 3 VMP是一个基于堆栈机的intel指令模拟器,对过编译把原来的intel指令编译成精心设计的一组虚拟指令,然后用自己的一套引擎来解释执行。VMP加壳后,他会将原来的代码进行删除,导致基本完全无法进行还原。 使用VMProtect保护后的程序添加了两个新节区,并且 IAT 表也需要修复(可以使用 unicorn 搞),因为VMP保护后的程序导入地址是运行时动态计算的。进入虚拟机的标志是push uint32 加上 call function 跳转到.vmp1的节区进行操作。call进去后就开始依次执行每一个handle了,在每个handle里面都存在的大量的代码混淆阻碍逆向分析。
如何找 vmprotect OEP?
1 2 3 4 1. 通过对ZwProtectVirtualMemory下断,观察栈顶。 2. 对代码节下硬件执行断点,得知道原始函数在大致哪个范围。 3. 对mainCRTstartup内使用的一些API下断点(IsProcessorFeaturePresent, GetSystemTimeAsFileTime),然后回溯找到OEP。 4. 一般对相应的遇见的第一个api下断点,一般的api也就是GetVersion,GetSystemTimeAsFileTime,如果下段后的栈回溯在text段内,那么我们继续回溯即可。可以看到相应的可以对上了,我们直接溯到call jmp的位置进行dump即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 VMP采取的方案: 虚拟机的寄存器:在内存开辟一段连续的区域当成虚拟机的寄存器,业界称之为VM_CONTEXT,某些版本的VMP用EDI指向这个区域 虚拟机的堆栈: 这个和物理机是一样的,直接在内存开辟就好。VMP还是用EBP指向栈顶 虚拟机的指令:不同版本VMP的指令是不一样的,这样可以在一定程度上防止VMP本身被破解,业界俗称VM_DATA 虚拟机的EIP:业界俗称vEIP,某些版本的VMP用ESI替代,指向VM_DATA,用以读取虚拟CPU需要执行的指令; VMP虚拟机的执行流程 (1)想想启动VT时,是不是要先开辟一段内存空间,把当前guestOS部分寄存器的值保存好?VMP也一样,先保存物理寄存器的值,后续退出VM后才能还原 (2)让vEIP从VM_DATA读取虚拟机的指令 (3)由于虚拟机的指令和物理CPU完全不同,那么在指令读取后,该怎么去执行了?举个栗子:比如0x1表示入栈,0x2表示出栈,0x3表示寄存器之间互相传数据(当然实际的指令可能不会这么简单,VMP每个版本的指令集都不同),这些指令该怎么执行了?在VMP中,有个概念叫handler,专门根据不同的指令执行不同的操作(当然这些操作VMP事先都定义好了)。这个和VT中VMX的handler作用类似:根据不同的异常有不同的处理方法(我个人猜测VMP的作者肯定借鉴了VT的原理和思路);为了达到这种不同指令执行不同handler分支的效果,编码实现层面通常用switch+case实现,用于将不同的指令跳转到不同的分支执行,业界俗称dispatcher。具体到汇编代码,switch+case一般的汇编形式为:mov ecx,dword ptr ds:[eax*4+base] (注意寄存器可能会变成其他的,但这 xxx*4+基址的形式不会变), 这是比较明显的特征,用以用来定位VMP的dispatcher。 (4)执行完一个handler,vEIP接着指向下VM_DATA的下一个指令,然后重复(2)-(4)这几个步骤; (5)综上所述,要想全面了解、分析和掌控VMP,必须要找准这么几个点: VM_DATA:虚拟机的指令都集中在这了 VM_CONTEXT:虚拟寄存器都保存在这里 diapatcher:所有指令都从这里路由到对应的handler执行(可以简单理解为管理层派发活的,不过3.x版本的VMP貌似去掉了统一的dispatcher,由上个handler直接跳转到下个handler,有点P2P、区块链去中心化的感觉) handler:具体模拟执行虚拟指令的分支(可以简单理解为具体干活的工具人)。handler之间跳转通过jmp esi 或 push esi ,ret等指令实现(不同版本使用的寄存器可能不同,但跳转实现的方式就这些); vEIP:当前执行的指令,需要明确是由那个物理寄存器保存的 vStack:存放了临时数据用于各种交换
源代码到可执行文件的过程 预处理,编译,汇编,链接。
blind ROP
SROP
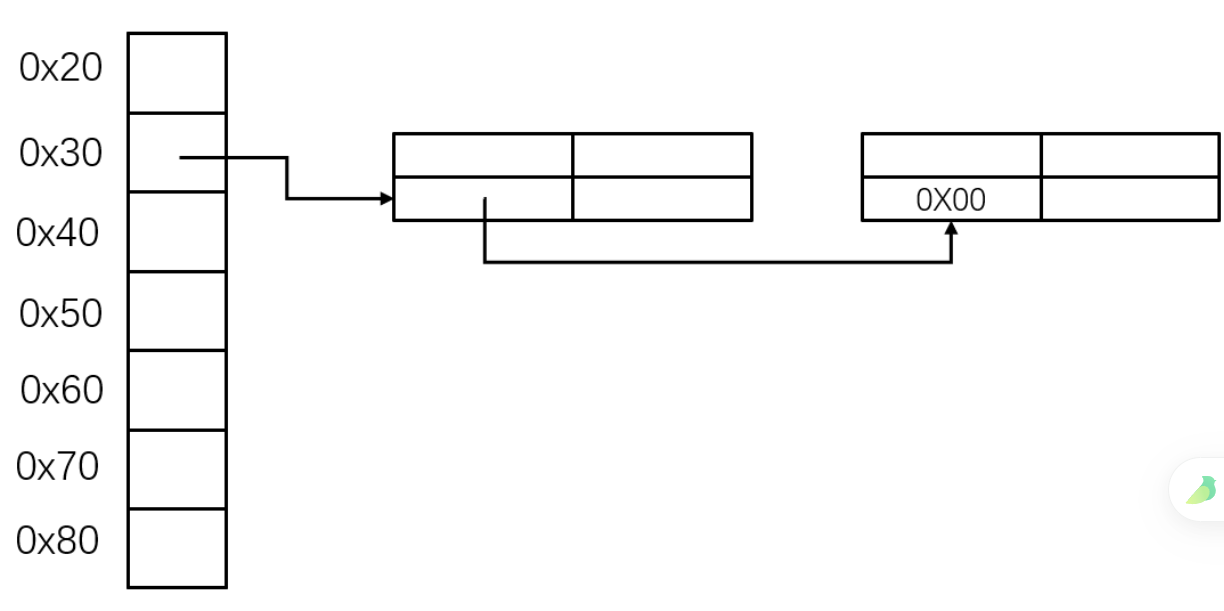
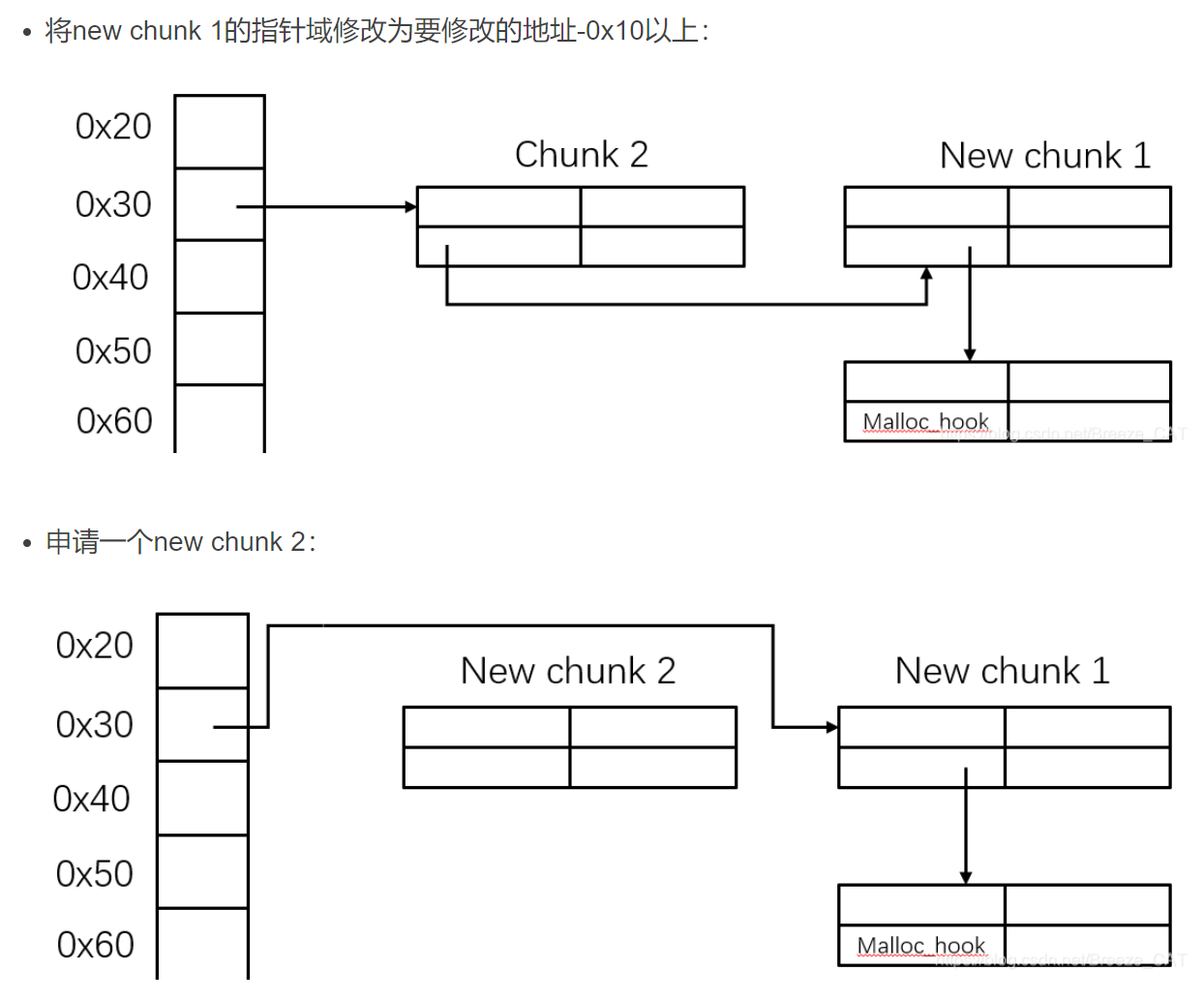
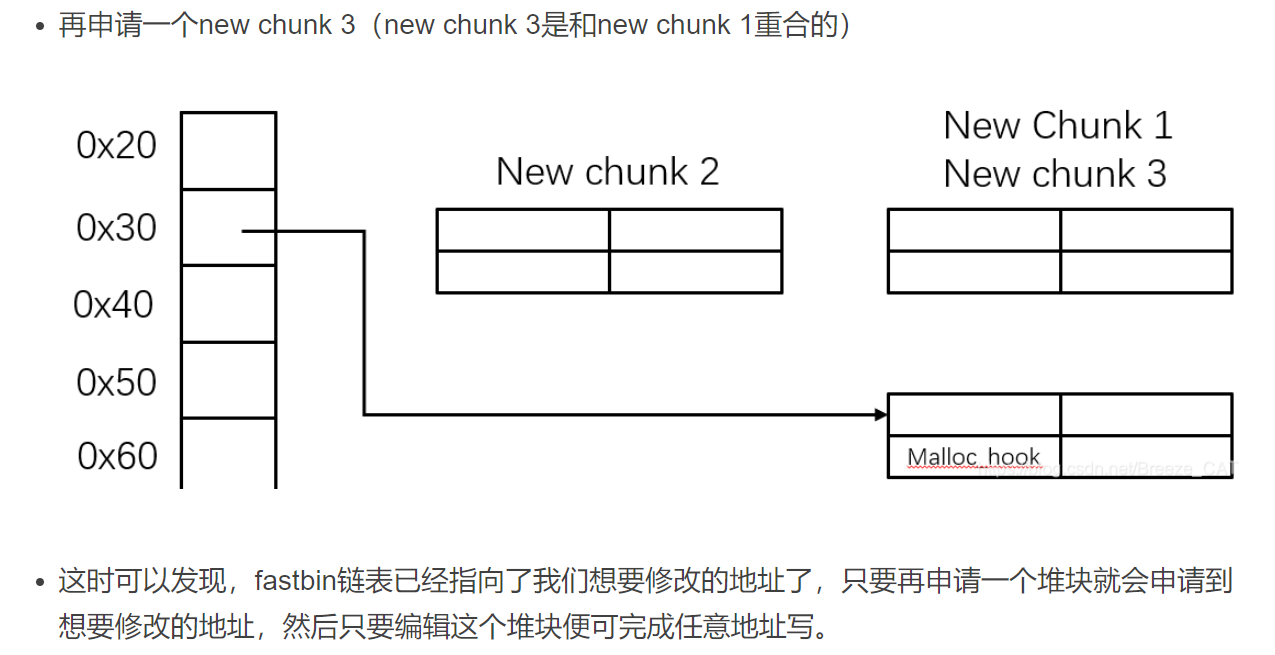
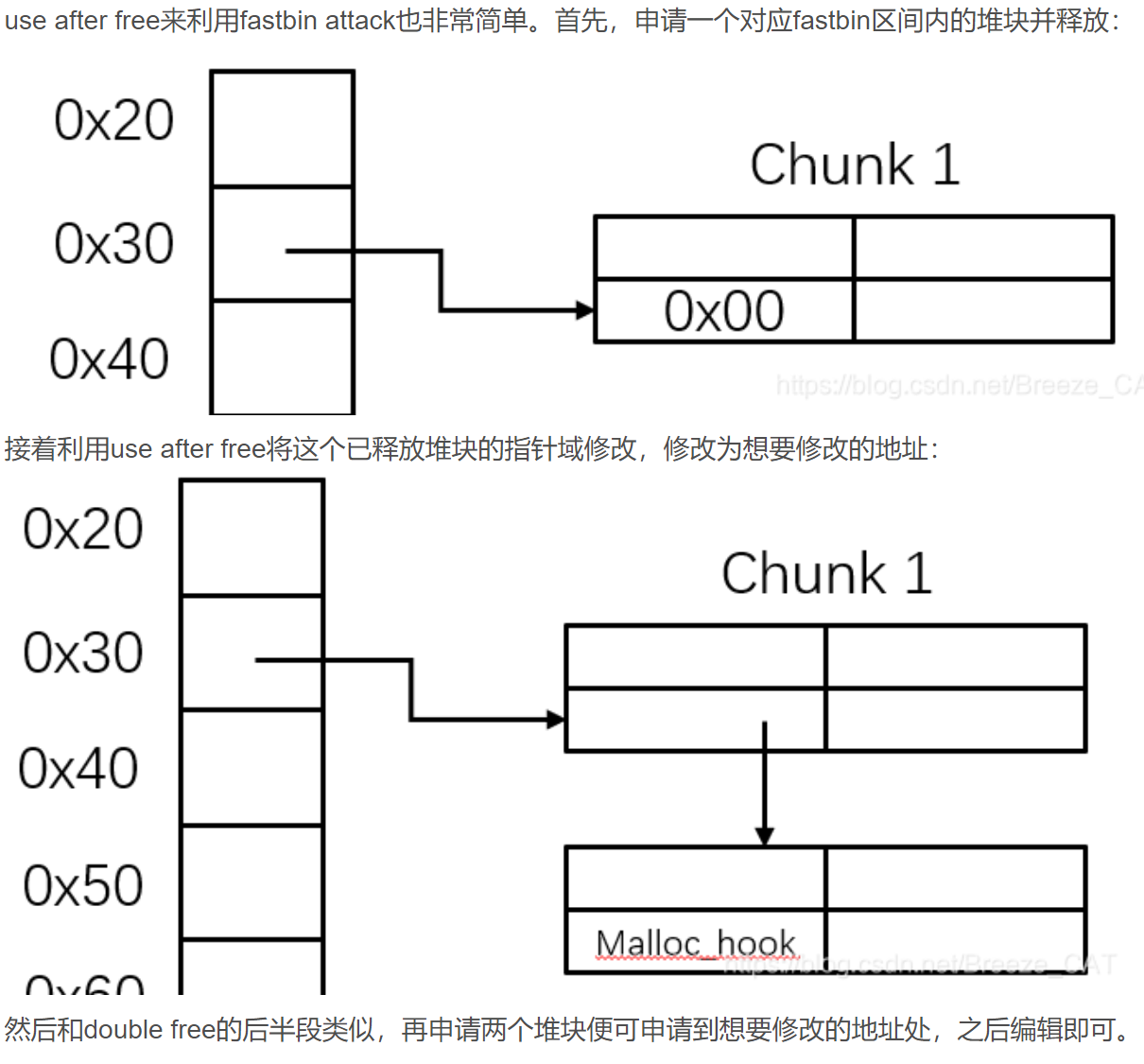
fastBin 相关漏洞 1 2 3 fastbins 是管理在 malloc_state 结构体的一串单向链表,分为0x20-0x807个链表。每个表头对应一个长度不超过4个的单向链表。 1. 每次释放对应大小的堆块都会被连入对应大小的链表中(链表长度<4)。 2. 每次分配会优先从fastbins中分配对应大小的区块。
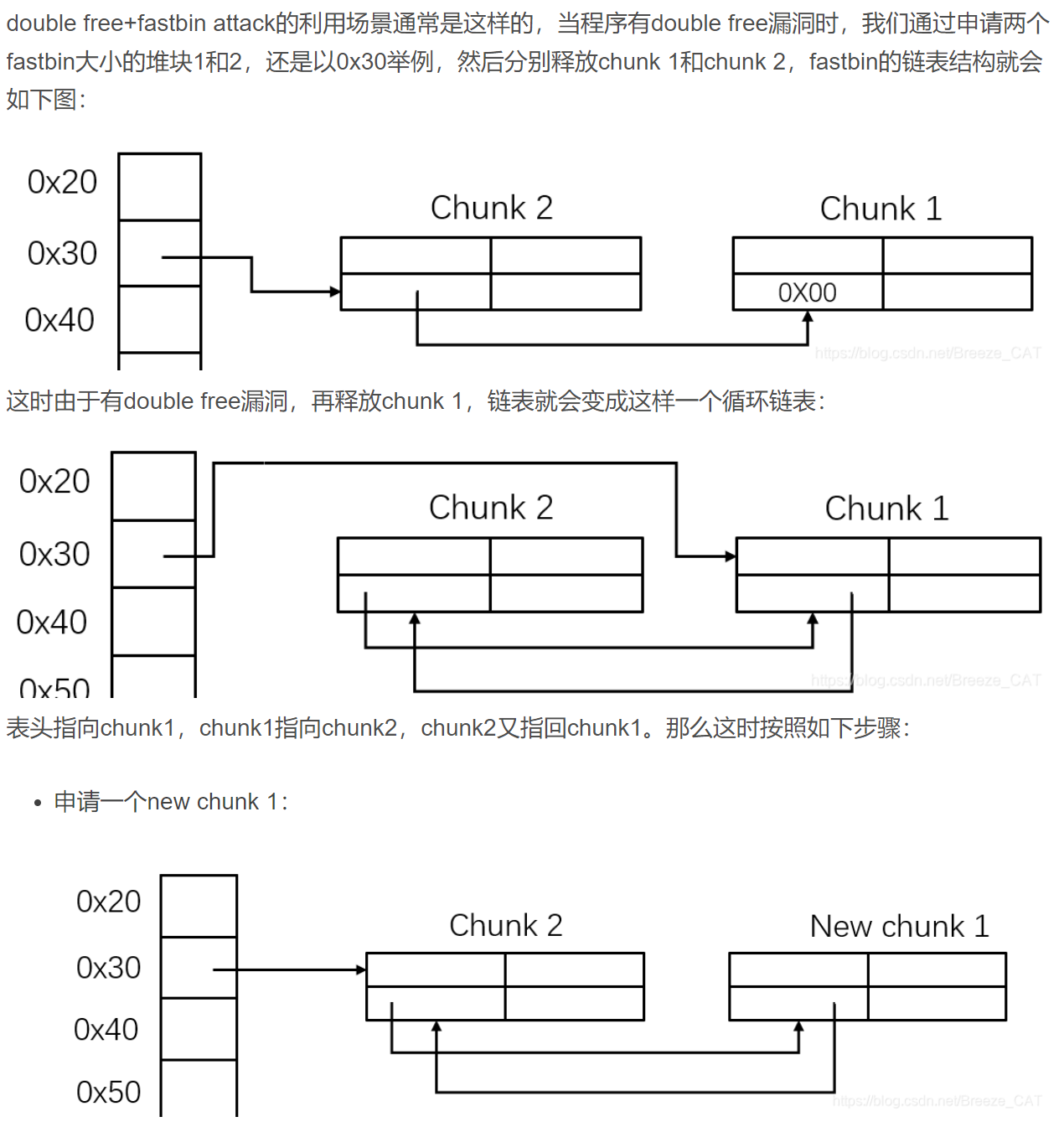
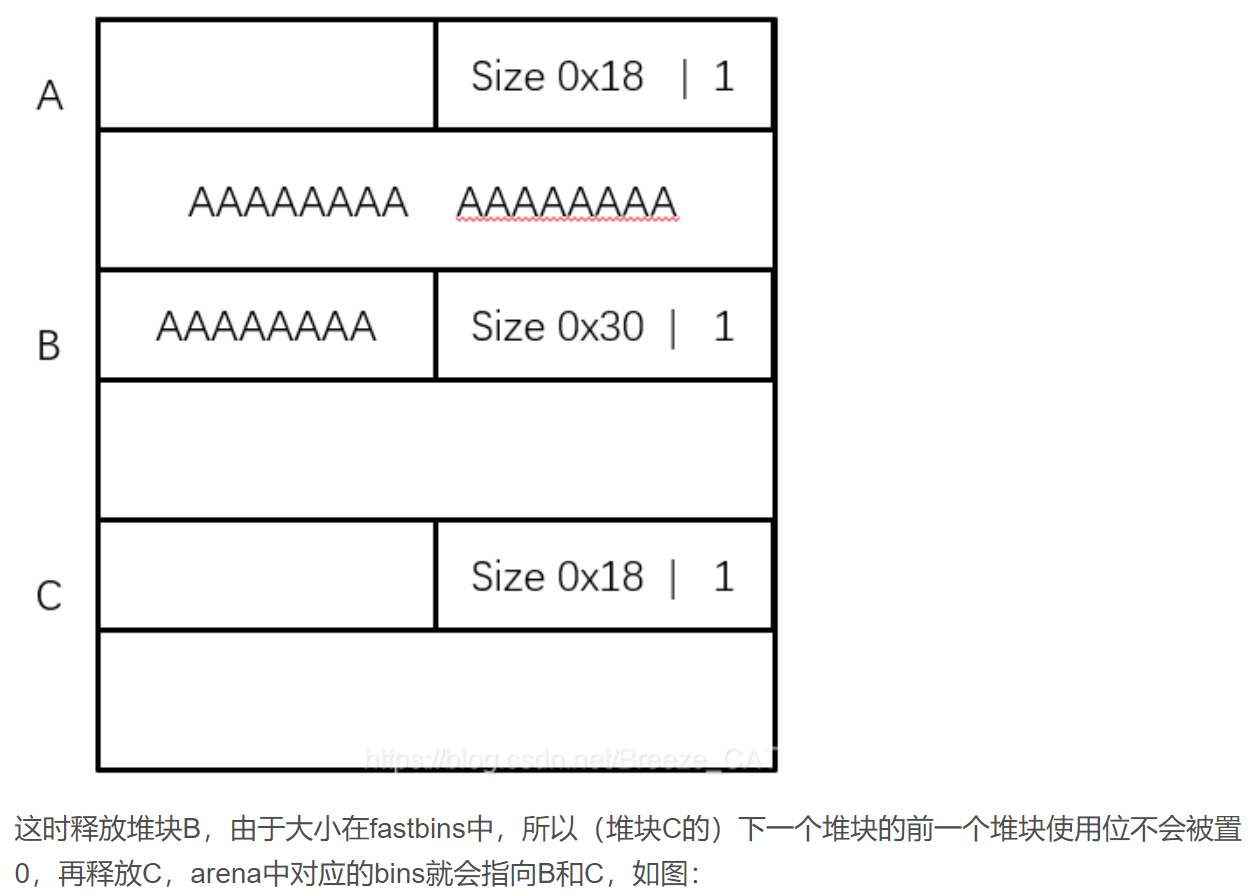
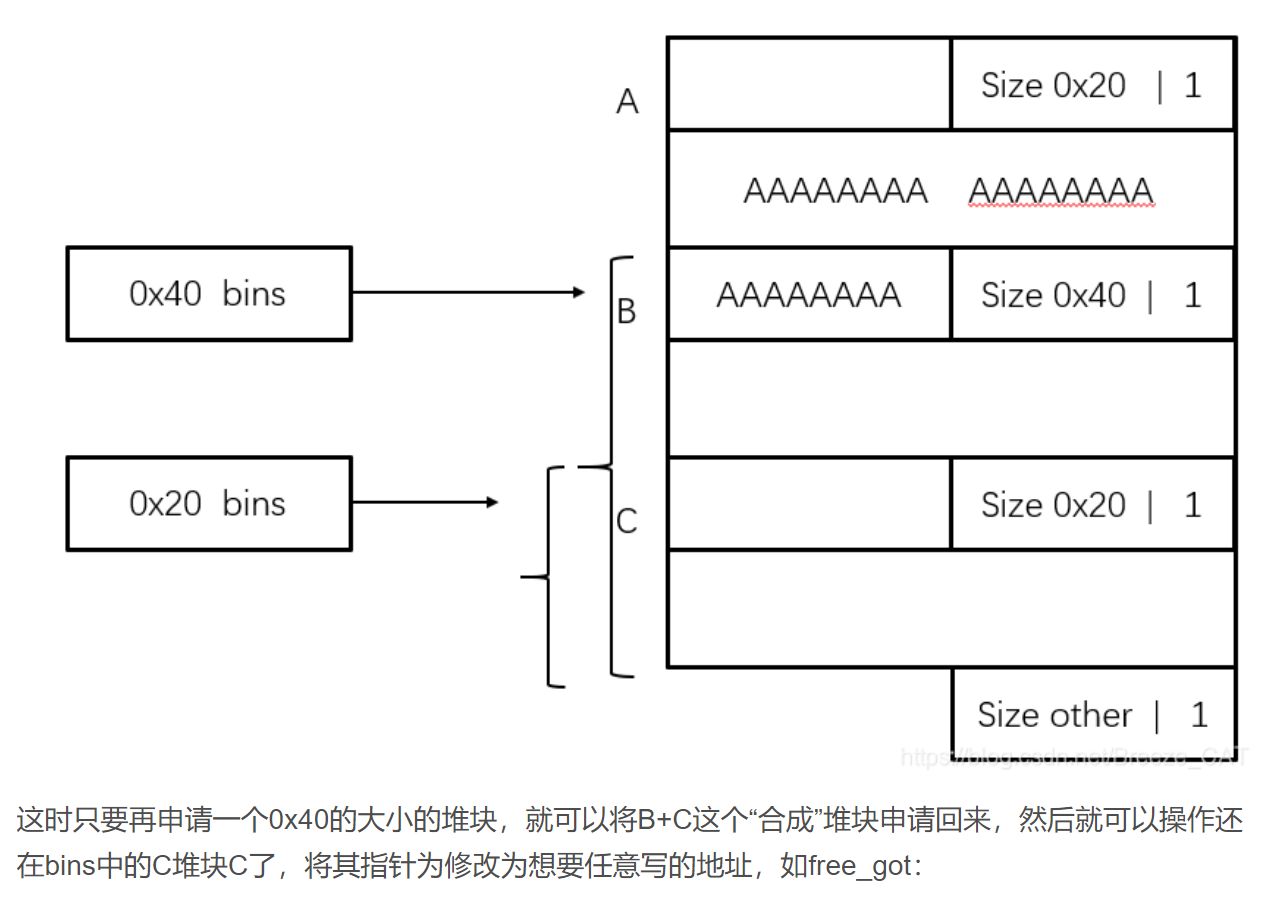
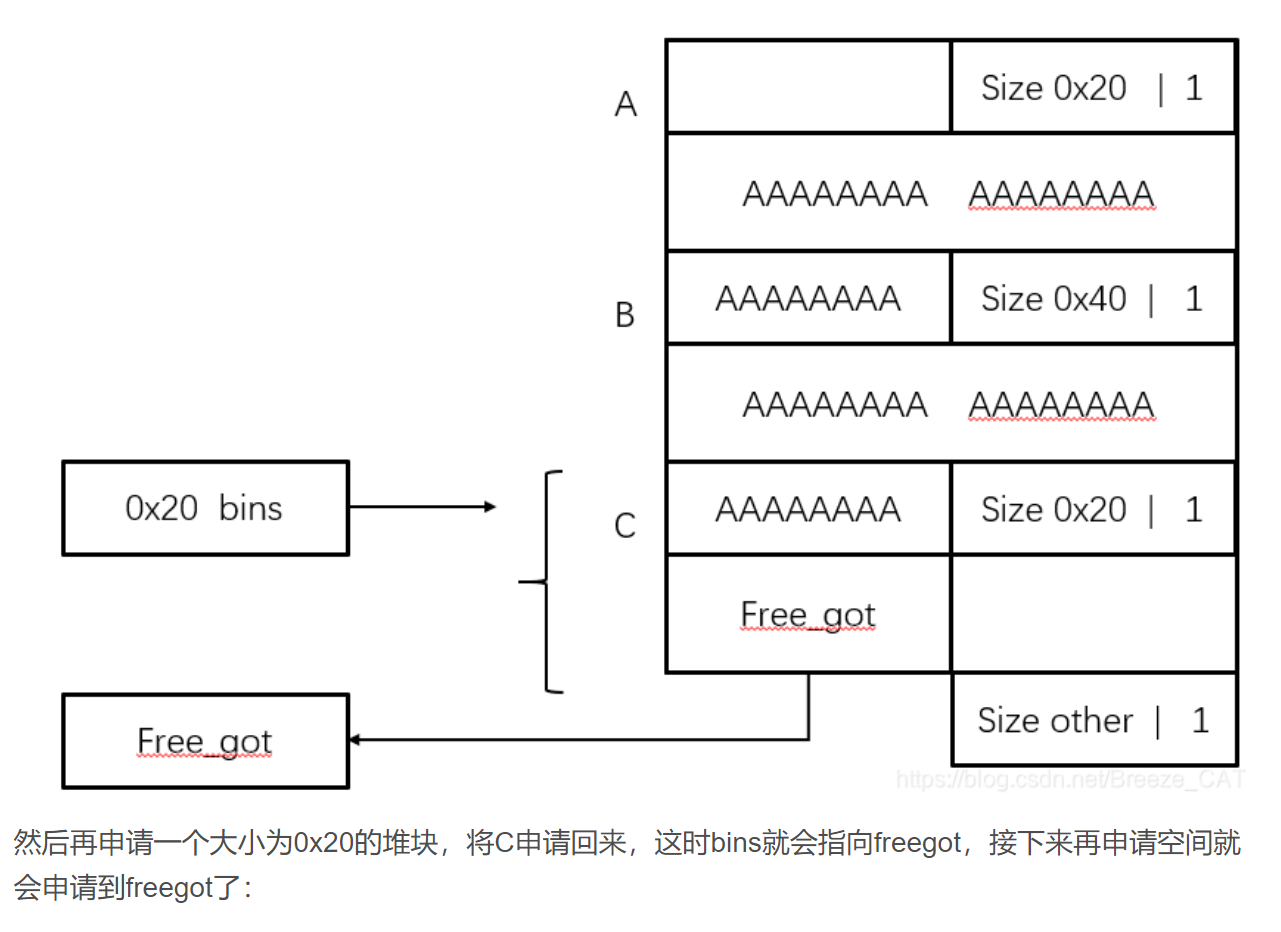
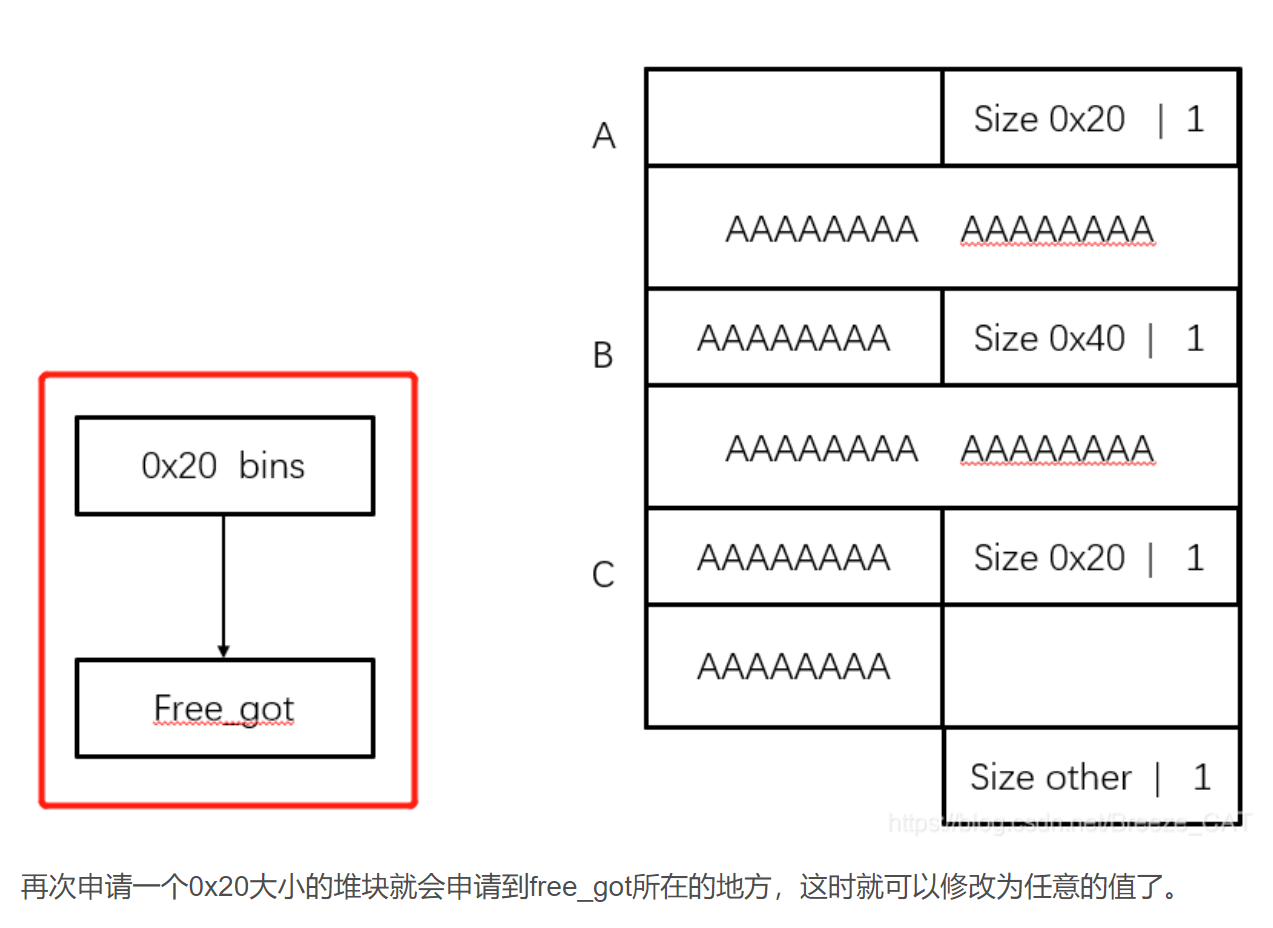
double free + fast bin
UAF + fastbin
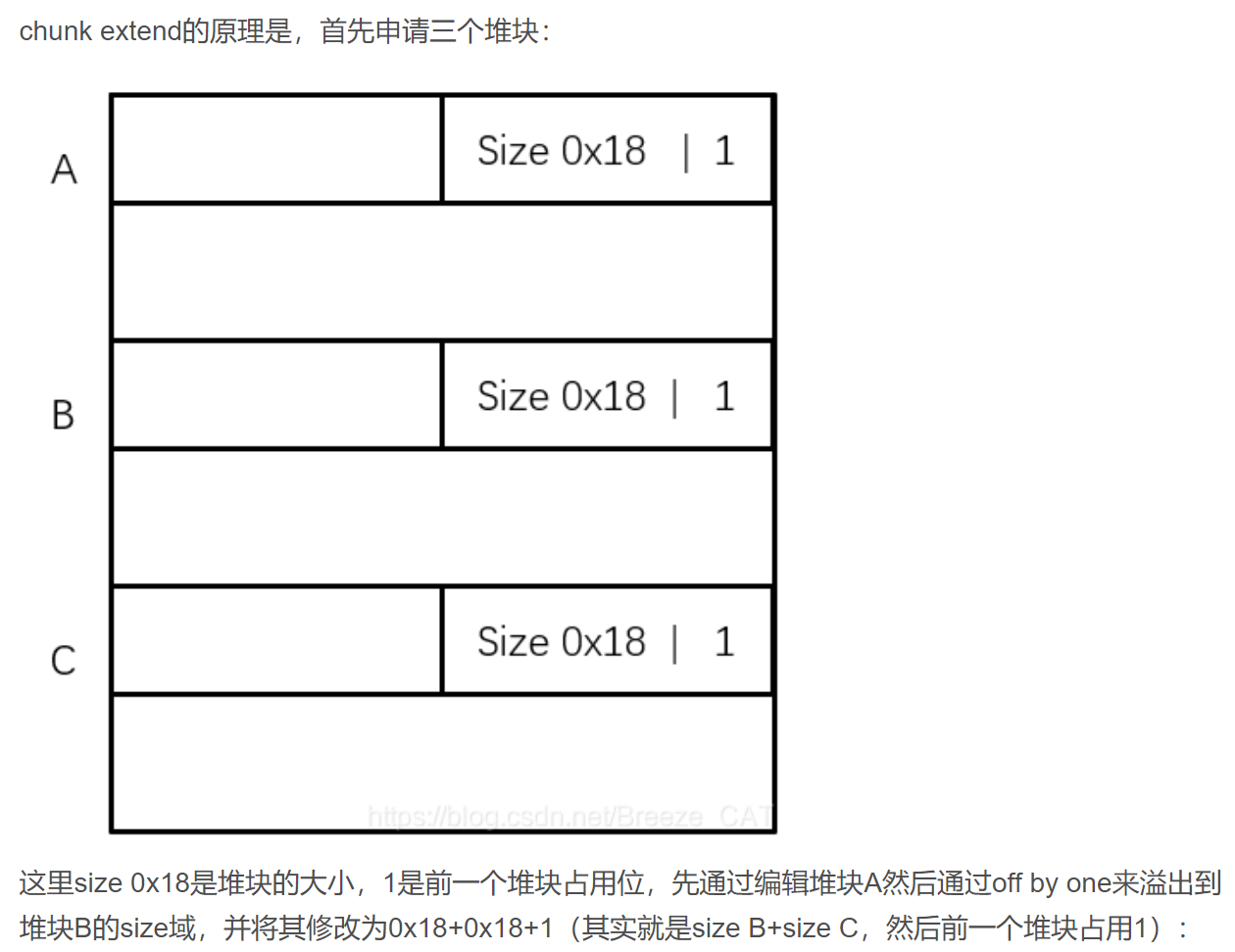
check extend 1 2 3 chuank extend 利用需要的条件是: 1. 可以进行堆布局 2. 可以溢出至少一个字节
0x01-6 windows 安全相关 0x01-7 编程语言基础 STL 迭代器 STL(Standard Template Library,标准模板库)迭代器是一种用于遍历和访问STL容器中元素的对象。它提供了一种统一的方式来访问不同类型的容器,如向量(vector)、链表(list)、集合(set)、映射(map)等。
STL迭代器可以被视为一个指针,它指向容器中的某个元素。通过对迭代器进行操作,可以遍历容器中的元素、访问元素的值、进行插入和删除操作等。迭代器相当于一个泛化的指针,通过派生统一的接口以及通过多态重写这些接口,使得迭代器可以适应不同类型的容器
C++ 多态是如何实现的?
静态多态包含:函数重载,C++编译器会将函数的参数类型以及其它修饰添加到函数的标签中,用于区别不同的重载函数。模板函数,由编译器根据调用替换模板参数,自动生成函数。
动态多态:虚函数,有虚表和虚函数指针实现,虚表由编译器实现,每一个有虚函数的类都拥有一张虚表,其中记录的是它的虚函数地址,函数重写时新的函数指针会替代掉基类对应位置的函数地址。
1 虚函数。通过在运行时解析函数调用来实现的,而不是在编译时,从而允许代码在面对新的派生类型时保持开放性和灵活性。代码复用、扩展性与灵活性。
另外编译器在生产实例的时候还会自动生成一段内存来存储虚表的指针,使得调用虚函数的时候可以根据这张虚表+偏移定位到需要调用的虚函数地址。
C++ 多态 (1)在基类的函数前加上 virtual 关键字,在派生类中重写该函数,运行时将会根据对象的实际类型来调用相应的函数。如果对象类型是派生类,就调用派生类的函数;如果对象类型是基类,就调用基类的函数。
(2)存在虚函数的类都有一个一维的虚函数表叫做虚表,类的对象有一个指向虚表开始的虚指针。虚表是和类对应的,虚表指针是和对象对应的。
(3) 父类子类调用(不是虚函数)。
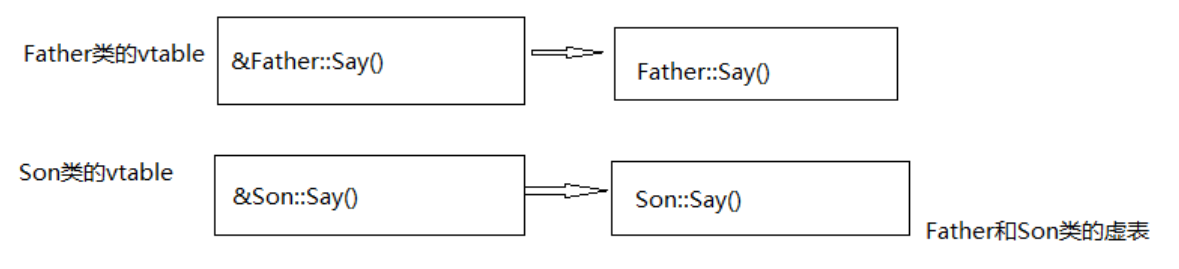
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 6 class Father 7 { 14 void Say () 15 {16 cout << "Father say hello" << endl;17 }18 };19 20 21 class Son :public Father22 { 24 void Say () 25 {26 cout << "Son say hello" << endl;27 }28 };29 30 void main () 31 {32 Son son;33 Father *pFather=&son; 34 pFather->Say ();35 }
从编译角度,c++ 编译器在编译的时候,要确定每个对象的非虚函数的地址,这称为早期绑定,当我们将 Son 类的对象 son 的地址赋给 pFather 时,c++编译器进行了类型转换,此时 c++ 编译器认为变量 pFather 保存的就是 Father 对象的地址,调用的当然就是 Father 对象的 Say 函数。从内存角度,如下所示:
(4)父类子类调用(有虚函数):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 6 class Father 7 { 14 virtual void Say () 15 {16 cout << "Father say hello" << endl;17 }18 };19 21 class Son :public Father22 { 24 void Say () 25 {26 cout << "Son say hello" << endl;27 }28 };29 30 void main () 31 {32 Son son;33 Father *pFather=&son; 34 pFather->Say ();35 }
编译器在编译的时候,发现 Father 类中有虚函数,此时编译器会为每个包含虚函数的类创建一个虚表(即 vtable),该表是一个一维数组,在这个数组中存放每个虚函数的地址,如下所示:
编译器另外还为每个对象提供了一个虚表指针 (vptr),用于定位虚表,在程序运行时,根据对象的类型去初始化vptr,从而让 vptr 正确的指向了所属类的虚表,从而在调用虚函数的时候,由于 pFather 实际指向的对象类型是Son,因此 vptr 指向的 Son 类的 vtable。
对象会初始化虚表指针,这是在对象的构造函数中运行的。在构造子类对象时,要先调用父类的构造函数,它初始化父类对象的虚表指针,当执行子类的构造函数时,子类对象的虚表指针被初始化,指向自身的虚表。
C++ 智能指针 管理动态分配的内存的,它会帮助我们自动释放 new 出来的内存,从而避免内存泄漏。
1 2 3 4 auto_ptr。两个指针不能指向同一个资源,复制或赋值都会改变资源的所有权。 unique_ptr。两个指针不能指向同一个资源,禁止复制,只允许移动,是 auto_ptr 的替代。 shared_ptr。采用引用计数的智能指针。 weak_ptr。对一个或多个 shared_ptr 实例拥有的对象的访问,但不参与引用计数。
0x01-8 计算机网络相关 linux epoll 1 2 3 4 5 6 7 处理大量并发连接。 工作模式: (1)LT (Level Triggered,水平触发): 默认模式,当 epoll_wait 检测到描述符就绪,将这个事件通知给应用程序,应用程序可以不立即处理该事件。下次调用 epoll_wait 时,如果这些事件仍然满足条件,则会再次通知这些事件。 (2)ET (Edge Triggered,边缘触发): 高性能模式,仅当状态变化时才通知一次。应用程序必须立即处理事件,因为只有下一个状态变化才会触发通知。 epoll_ctl - 管理 epoll 实例的感兴趣的事件列表。
如果服务器上有大量的连接处于 TIME_WAIT 状态应该如何处理? 1 2 3 为什么会有 TIME_WAIT 状态? 1. 正常关闭连接:当服务器和客户端之间的连接正常关闭时,根据 TCP 协议的规定,连接的一端(通常是客户端)会进入 TIME_WAIT 状态。在此状态下,该端会等待一段时间,以确保网络中的所有数据包都被接收和处理完毕。这样可以避免后续的数据包被之前连接的残留数据所干扰。 2. 端口资源耗尽:如果服务器的端口资源被快速消耗完,可能会导致连接的 CLOSE_WAIT 状态无法正常关闭,从而导致服务器出现大量的 TIME_WAIT 状态。
1 设置地址复用,少用短连接,调整 TIME_WAIT 时间。
短链接与长链接 短连接(Short Connection)是一种连接方式,它指的是在通信双方完成一次数据交换后立即断开连接的方式。
长连接(Long Connection),即在通信双方之间建立一次连接后,可以持续较长的时间,用于多次数据交换。
特点和应用场景:
临时性:短连接是一种临时性的连接,即每次通信都需要重新建立连接,数据交换完毕后立即关闭连接。与长连接相比,短连接的生命周期较短暂。
资源消耗少:由于短连接仅在数据交换期间建立,连接时间较短,因此相对于长连接来说,短连接的资源消耗较少。这对于服务器端来说可以释放连接资源,提高系统的可扩展性。
频繁的连接建立和断开:由于每次通信都需要重新建立连接,因此短连接的连接建立和断开操作比较频繁。这可能会对服务器端的性能产生一定的影响,尤其在高并发的情况下。
适用于请求-响应模式:短连接通常用于请求-响应模式的应用场景,例如网页浏览、文件下载等。客户端发送请求,服务器端响应并返回数据,然后立即关闭连接。
短连接适用于那些对实时性要求较高、连接时间较短、资源消耗较少的场景。它可以减轻服务器的负载,并且连接的建立和断开操作相对简单。然而,由于频繁的连接建立和断开操作,短连接在高并发情况下可能会导致连接的建立和断开开销较大,因此在设计和选择网络通信方式时需要综合考虑实际需求和系统性能。
相比之下,长连接更适用于需要保持持久连接、频繁通信、实时性要求不高的场景,如聊天应用、实时数据推送等。
0x01-9 数据库相关 0x01-10 Linux 相关 1 dlopen(打开dll)/dlsym(获取dll中某函数的地址,对应 GetProcAddress)/dlclose
1 2 3 ss -t // 查看 tcp 链接, -n 显示端口号 lsof -i TCP // 查看正在运行系统上的文件的工具,但它也可以用来查看打开的网络连接 tcpdump // 获取 TCP 数据包。
memcpy 和 memmove 是怎么实现的? A.memcpy 函数:
memcpy 函数用于在内存区域之间进行字节级别的拷贝。memcpy 的实现通常使用比较底层的方法,如使用处理器的指令集来进行高效的内存复制操作。memcpy 的使用有一个前提:目标内存区域和源内存区域不得重叠,否则结果是不确定的。
B. memmove 函数:
memmove 的实现考虑了源内存区域和目标内存区域可能重叠的情况。因此,它采用了更保守的策略,使用了临时缓冲区,以确保正确的结果。memmove 的使用没有重叠的限制,可以安全地处理重叠的内存区域。需要注意的是,虽然 memmove 在处理重叠内存区域时比 memcpy 更安全,但也因为这种额外的处理而可能导致性能略低于 memcpy。
close & shutdown
功能:
close 函数用于关闭套接字,关闭连接并释放相关的资源。当调用 close 函数时,套接字会立即关闭,不再接收或发送数据。shutdown 函数用于关闭套接字的一部分功能。通过 shutdown 函数可以选择关闭套接字的读取(输入)功能、写入(输出)功能或同时关闭两者。
关闭连接和资源释放:
close 函数关闭套接字时,会立即关闭连接并释放与该套接字相关的资源,包括文件描述符(file descriptor)和缓冲区等。shutdown 函数不会立即关闭连接,而是根据参数来决定关闭的方式。如果选择关闭读取功能,那么套接字仍然可以发送数据,反之亦然。只有当两端都调用了 shutdown 函数关闭读取和写入功能后,连接才会真正关闭。
影响其他套接字:
close 函数关闭套接字时,只会关闭当前套接字,对其他套接字没有影响。shutdown 函数关闭套接字的一部分功能时,可能会影响与之相关的其他套接字。例如,如果一个套接字调用了 shutdown 函数关闭写入功能,而另一个套接字试图向该套接字发送数据,那么发送操作可能会失败。
死锁 1 2 3 4 5 如果有两个线程去1、2去访问同一个资源 C ,并且二者必须同时获取锁 A 和 B 才可以访问 C。问什么顺序获取锁会导致死锁,正确的获取和释放顺序是如何? 1. 分情况讨论:第一如果两个线程同时去分别先获取不同的锁就会出现死锁,比如线程1先获得锁 A 而线程 2 先获得锁 B 然后二者都会等待。 2. 正确的顺序应该是二者同时竞争同一个锁: a. 先释放 A,由于对方正在等待A,那么对方接下来会等待B,而此时释放 B 是没有阻碍的
C++ 避免死锁 1 2 3 std::lock()。 1. 无死锁的加锁顺序:std::lock() 函数会按照一种事先确定的顺序对传入的互斥量进行加锁。这个顺序是为了避免出现死锁的条件,即遵循 "资源申请的有序性" 原则。通过约定一个全局的加锁顺序,可以避免不同线程在加锁时产生循环依赖的情况,从而避免死锁。 2. 无死锁的原子加锁操作:std::lock() 函数使用原子操作来保证多个互斥量的加锁操作是原子的。原子操作保证了多个线程无法同时对同一个互斥量进行加锁,从而避免了竞争条件。如果无法一次性对所有互斥量进行加锁,std::lock() 函数会自动解锁之前已经加锁的互斥量,然后等待其他线程解锁剩余的互斥量,再重新尝试对所有互斥量进行加锁,直到所有互斥量都成功加锁为止。
0x01-11 区块链相关 0x01-12 算法基础 排序算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1. 冒泡排序。其大体思想就是通过与相邻元素的比较和交换来把小的数交换到最前面。这个过程类似于水泡向上升一样,因此而得名。对5,3,8,6,4这个无序序列进行冒泡排序。首先从后向前冒泡,4和6比较,把4交换到前面,序列变成5,3,8,4,6。同理4和8交换,变成5,3,4,8,6,3和4无需交换。5和3交换,变成3,5,4,8,6,3,这样一次冒泡就完了,把最小的数3排到最前面了。 a. 平均时间复杂度:O(n^2) 2. 选择排序。在长度为N的无序数组中,第一次遍历n-1个数,找到最小的数值与第一个元素交换;第二次遍历n-2个数,找到最小的数值与第二个元素交换; a. 平均时间复杂度:O(n^2) 3. 插入排序,一个个比较,就像插扑克牌。平均时间复杂度:O(n^2)。 4. 快速排序,分治思想。先从数列中取出一个数作为key值;将比这个数小的数全部放在它的左边,大于或等于它的数全部放在它的右边;对左右两个小数列重复第二步,直至各区间只有1个数。平均时间复杂度:O(N*logN)。 5. 归并排序。将数组分成2组A,B,如果这2组组内的数据都是有序的,那么就可以很方便的将这2组数据进行排序。依次类推,当分出来的小组只有1个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的2个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。平均时间复杂度:O(N*logN)。 6. 堆排序。最坏,最好,平均时间复杂度均为O(nlogn)。 a. 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。 b. 将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
哈希冲突解决 1 2 3 1. 开放定址法,从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。然后把发生冲突的元素存入到该单元的一种方法。开放定址法需要的表长度要大于等于所需要存放的元素。开放定址法的缺点在于删除元素的时候不能真的删除,否则会引起查找错误,只能做一个特殊标记。只到有下个元素插入才能真正删除该元素。 2. 链地址法(拉链法)。 3. 再哈希法,就是同时构造多个不同的哈希函数:Hi = RHi(key) i= 1,2,3 … k; 当H1 = RH1(key) 发生冲突时,再用H2 = RH2(key) 进行计算,直到冲突不再产生。
md5 流程 1 2 3 输入:不定长度信息(要加密的信息) 输出:固定长度128-bits。由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。 基本方式为:求余、取余、调整长度、与链接变量进行循环运算。得出结果。
1 2 3 4 5 6 7 8 9 10 11 (1)信息填充,长度恰好是512的整数倍。 (2)结构初始化,在处理过程中需要定义一个结构。该结构包含了每一次需要处理的一个明文块 (512bit)和计算出来的散列值 (128bit)。在散列的整个过程中,它的作用非常重要 ,各个明文块计算出来的散列值都是通过它来传递的。 (3)分组文件,将填充好的文件进行分组,每组 512位 ,共有N组。 (4)处理分组,使用算法处理每组数据。 a. MD5算法在计算时会用到四个32位被称作链接变量 (Chaining Variable)的整数参数 ,在使用之前要对它们赋初值。 b. 进入算法的四轮循环运算。循环的次数是信息中512位信息分组的数目。 c. 将上面四个链接变量复制到另外四个变量中。 d. 主循环有四轮,每轮循环都很相似。第一轮进行16次操作。每次操作对 a、b、c和 d中的其中三个作一次非线性函数运算 ,然后将所得结果加上第四个变量,一个子分组和一个常数。再将所得结果向右环移一个不定的数,并加上 a、b、c或 d中之一,最后用该结果取代 a、b、c或 d中之一。
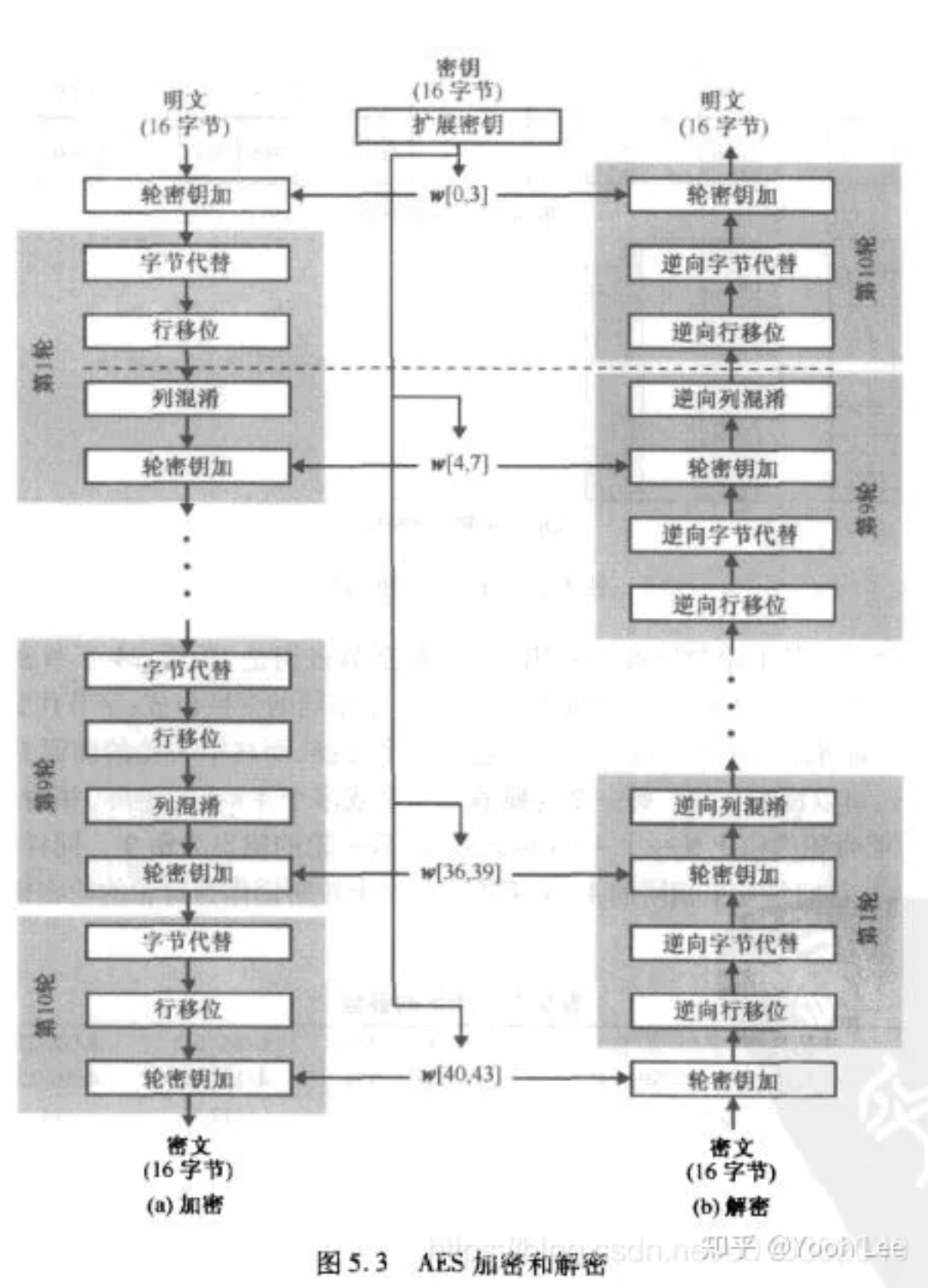
AES
0x01-13 病毒分析 wannaCry病毒分析(勒索病毒) 1 2 3 4 5 6 7 8 9 WannaCry利用Windows系统的SMB漏洞获取系统的最高权限,该工具通过恶意代码扫描开放445端口的Windows系统。WannaCry利用永恒之蓝漏洞进行网络端口扫描攻击,目标机器被成功攻陷后会从攻击机下载WannaCry蠕虫进行感染,并作为攻击机再次扫描互联网和局域网的其他机器,形成蠕虫感染大范围超快速扩散。 其核心流程如下图所示: 1. 木马母体为mssecsvc.exe,运行后会扫描随机IP的互联网机器,尝试感染,也会扫描局域网相同网段的机器进行感染传播,此外会释放敲诈者程序tasksche.exe,对磁盘文件进行加密勒索。 2. 木马加密使用AES加密文件,并使用非对称加密算法RSA 2048加密随机密钥,每个文件使用一个随机密钥,理论上不可攻破。 WannaCry勒索病毒主要行为是传播和勒索。 1. 传播:利用基于445端口的SMB漏洞MS17-010(永恒之蓝)进行传播 2. 勒索:释放文件,包括加密器、解密器、说明文件、语言文件等;加密文件;设置桌面背景、窗体信息及付款账号等。
1 2 3 4 5 过程: 1. 主程序运行后会先连接域名(KillSwitch),如果该域名连接成功,则直接退出且不触发任何恶意行为。否则触发传播勒索行为,执行sub_408090函数。 2. 创建mssecsvc2.0服务,并启动该服务,参数为”-m security”,蠕虫伪装为微软安全中心。 3. 读取并释放资源tasksche.exe至 C:\Windows 路径,创建线程运行。 4. 蠕虫传播。WSAStartup:初始化网络。蠕虫初始化操作后,会生成两个线程,分别进行局域网和公网传播。
1 2 永恒之蓝: SMB服务端口(默认是445端口),并利用该漏洞来执行恶意代码,甚至获得系统的完全控制权。漏洞的核心是在SMBv1协议中的一个称为“Windows内核传输模式”的特性。该特性允许攻击者发送一个特殊设计的数据包,其中包含了恶意的SMB1协议请求,当Windows操作系统试图处理这个请求时,会导致系统内核缓冲区的溢出,从而使攻击者能够执行任意的代码。
0x01-14 其它 性能指标评估 1 2 3 4 QPS(TPS):每秒钟处理request/事务的数量。 并发数:系统同时处理的request/事务的用户数量。 响应时间(Response Time,RT):服务器处理响应的耗时,一般取平均响应时间。 CPU 占用,内存占用磁盘IO等,如果有网络还要考虑丢包。
0x01-15 游戏安全相关 游戏安全基础导论 游戏安全问题:
外挂。
社交类游戏有恶意内容(合规包括涉政、涉恐,业务包括广告、骂人等)。
打金工作室(DNF 刷钱,利用工具刷游戏资源,卖给玩家变现)(人脸认证可以识别)。
盗号。木马、假客户端。
DDOS 攻击(ping 值突增)。
演员与消极行为。
棋牌类黑产(就像赌桌一样)。
游戏数据盗用(xx 盒子知道 LOL 游戏数据)。
网吧客户端营销推广(插件),改广告。
游戏私服(逆向后直接模拟),给玩家更好的游戏体验。
单机盗版(Denuvo加固、3DM破解)。
云游戏。沙盒环境,有传统安全问题,也会有云端逃逸作弊。
如何设计?
尽量让服务端做敏感功能。
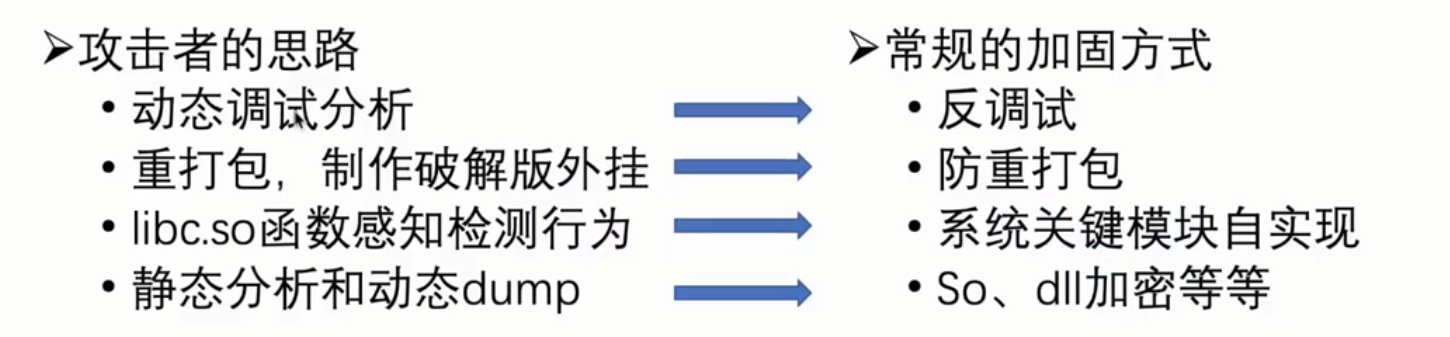
客户端加固:
加壳、混淆、反调试、游戏进程保护(不经过 ring0)。
外挂在线监测。可疑样本上报->外挂识别->特征提取->白名单测试->对抗监控特征发布。
坐飞机、挂车怎么处理?
明确加减分规则(信誉分)、单次挂车没事。
实时扣分反馈,对用户进行引导,做低等级副本。
打金工作室怎么处理?人脸检测、弹验证码、封账号。
客户端安全开发基础-PC篇 常见 C++ 编译器:MSVC(微软)、LLVM(clang)。
常见的加壳:VMProtect(混淆+虚拟化)、UPX、SafeEngine、Themida。
VMP 特征:push + call。
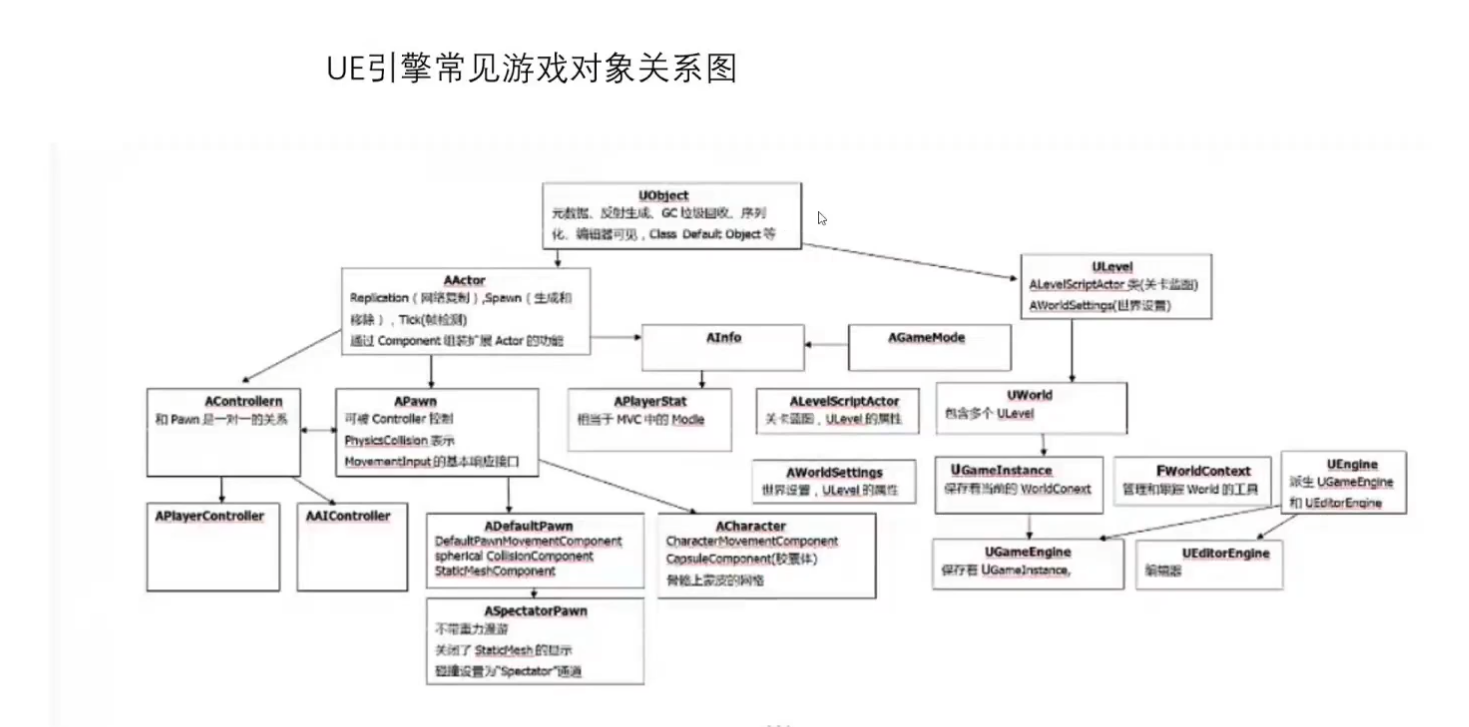
UE4 引擎:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ULevel: UE的场景划分模式是基于子关卡来做的,UE4和其他支持大世界的引擎一样支持游戏场景中的物体动态加载与卸载,UE4中的动态加载卸载的子关卡叫做流关卡(StreamingLevel、ULevelStreaming类),一开始就加载的子关卡叫持久关卡(PersistentLevel) UWorld:游戏主场景,游戏过程中,一般只存在一个UWorld实例 GNames: 包含游戏中所有对象的命名字符串信息 GObjects:包含所有游戏对象的链表 Gamelnstance:顾名思义,游戏实例,保存着当前的World和其他整个游戏的信息,官方解释是一个正在运行的游戏的高级别管理对象,在游戏创建时生成,游戏关闭时销毁,一个游戏中可以有多个Gamelnstance。在游戏中切换关卡,Gamelnstance不会销毁,切换关卡时可用GameInstance携带信息 GameMode: 负责指定游戏的规则,也就是应该如何玩游戏、遵守哪些规则 GameState:游戏状态,记录游戏的数据,比如当前游戏的进度,世界人物的完成状态等,可同步到各个客户端 UObject: 引擎对象的最小单位 Actor: 在UE离不是某种具象化的3D世界对象,而是世界里面的种种元素,用更泛化抽象的概念来看,小到一个个地上的石头,大到整个世界的运行规则,更像是一个容器 RootComponent:对象根组件,包含对象的位置信息(坐标、朝向) Pawn 是作为世界中的一个“代理”的Actor。Pawn可以由控制器处理,它们可以轻松地接受输入,并且可以执行各种各样的类似于玩家的动作。 Character是类人的Pawn。它默认包含一个用于碰撞的CapsuleComponent(胶囊体组件)与CharacterMovementComponent(角色运动组件)它可以进行基本的拟人运动它可以平滑地在网格上复制运动,并且它具有一些动画相关的功能。 Controller是负责管理Pawn的Actor,分为AIController和PlayerController。其中PlayerController(玩家控制器)是Pawn和控制它的人类玩家间的接口。PlayerController本质上代表了人类玩家的意愿。
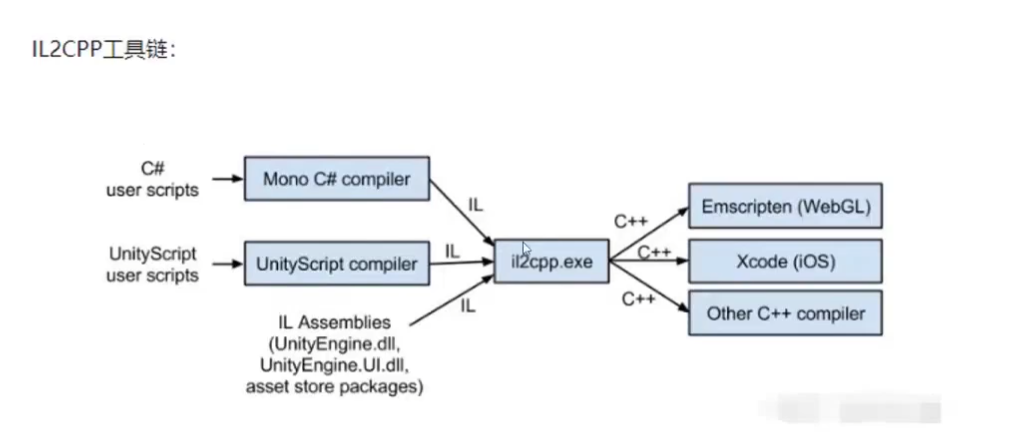
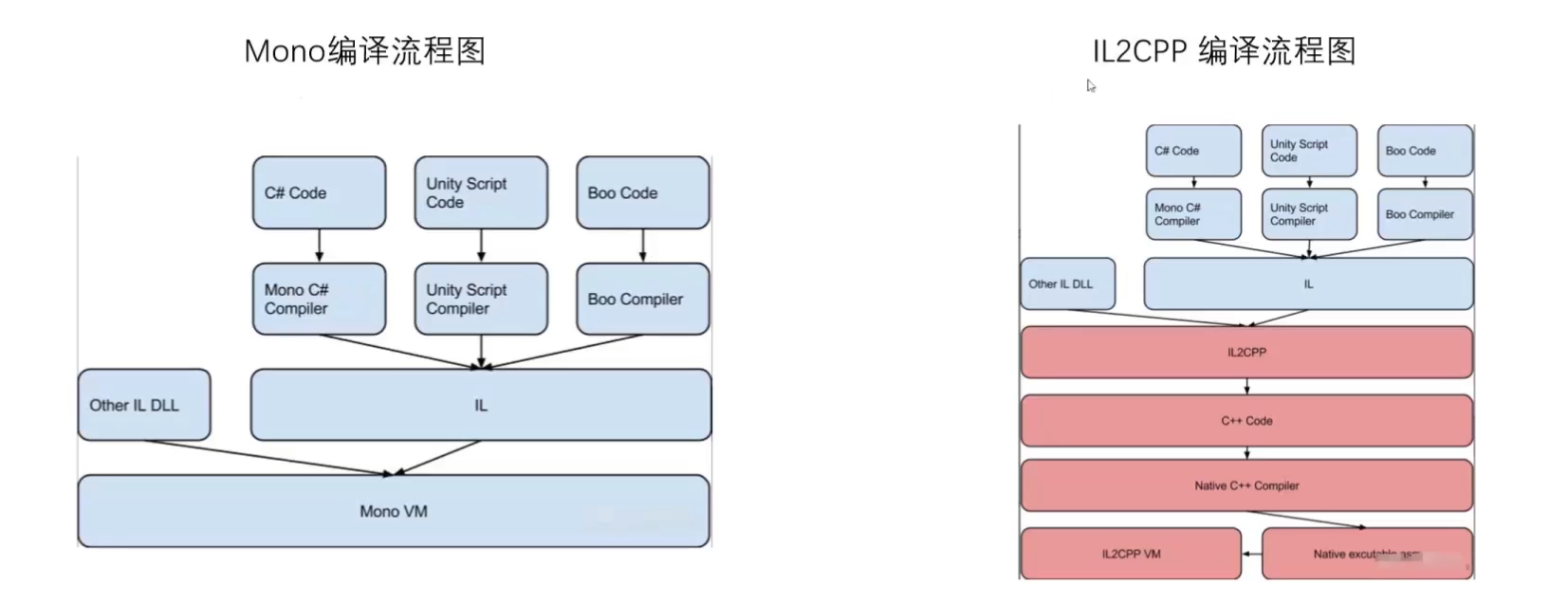
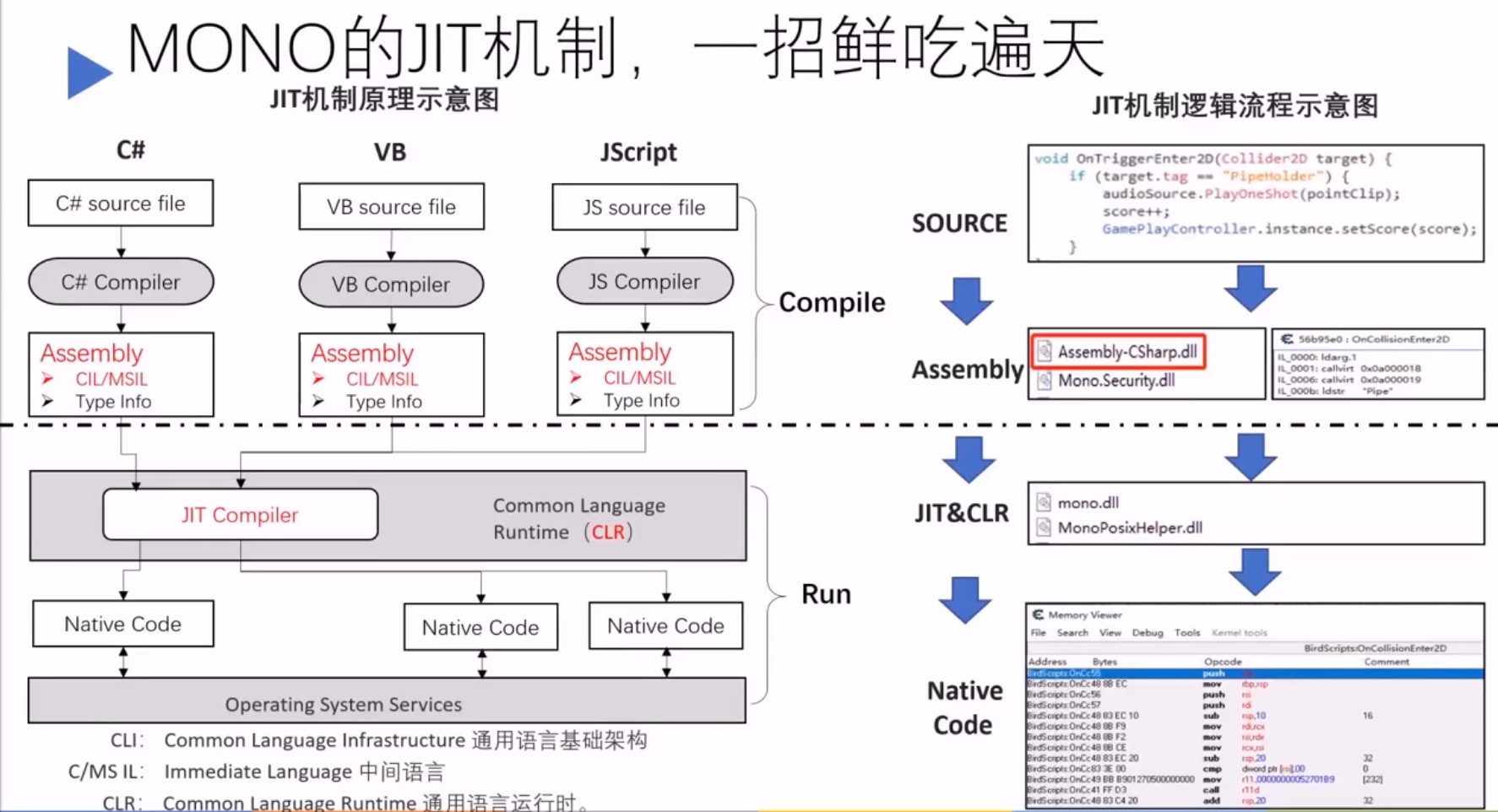
Unity 引擎(跨平台比较好):Unity 脚本后处理的两种方式有 mono 与 IL2CPP。
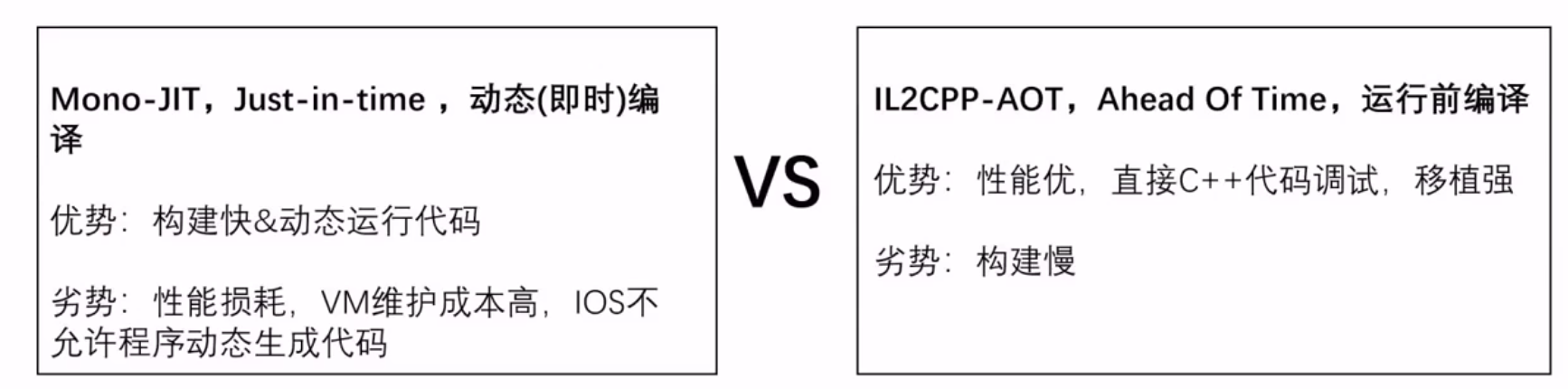
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Mono:在尽可能多的平台上使.net标准的东西能正常运行。 Mono 组成组件:C#编译器,CLI虚拟机。 编译器: C# 编译器 mcs,将 C# 转为 IL。 Mono runtime 编译器:将 IL 转为原生码。 三种转译方式: 即时编译(Just in time,JlT):程序运行过程中转译为目标平台的原生码。 提前编译(Ahead oftime,AOT):程序运行之前,转译为目标平台的原生码并且存储,程序运行中仍有部分CIL的byte code需要JIT编译。 完全静态编译(Fu ahead oftime,Ful-AOT):程序运行前,将所有源码编译成目标平台的原生码。 Unity跨平台的原理:Mono运行时编译器支持将IL代码转为对应平台原生码 JIT编译:将IL代码转为对应平台原生码并且将原生码映射到虚拟内存中执行。JIT编译的时候IL是在依托Mono运行时,转为对应的原生码后在依托本地运行。 Mono 优缺点: 1.构建应用非常快 2.由于Mono的JIT(Just In Time compilation)机制,所以支持更多托管类库 3.支持运行时代码执行 4.Mono VM在各个平台移植异常麻烦,有几个平台就得移植几个VM(WebGL和UWP这两个平台只支持IL2CPP)
1 2 3 4 5 6 7 IL2CPP 优缺点: 1.相比Mono,代码生成有很大的提高 2.可以调试生成的C++代码 3.程序的运行效率比Mono高,运行速度快 4.多平台移植非常方便 5.相比Mono构建应用慢 6.只支持AOT(Ahead of Time)编译
进程注入分类: 1 2 3 4 5 6 7 8 9 10 静态注入--进程创建前完成注入 (1)导入表注入 (2)DLL劫持注入 (3)注册表注入 动态注入--进程运行过程中进行注入 (1)远程线程注入 (2)消息钩子注入 (3)APC注入 (4)IAT(导入表函数)劫持注入
导入表注入:程序运行时会导入 dll,这些信息保存在IMAGE_NT_HEADER的OptionalHeader的第二个项,指向着一个IMAGE_IMPORT_DESCRIPTOR(IID)结构体数组。进程启动时系统会遍历这个数组,加载dll到内存。因此修改导入表结构,增加一个导入表项,就可以实现让程序加载我们的dll。
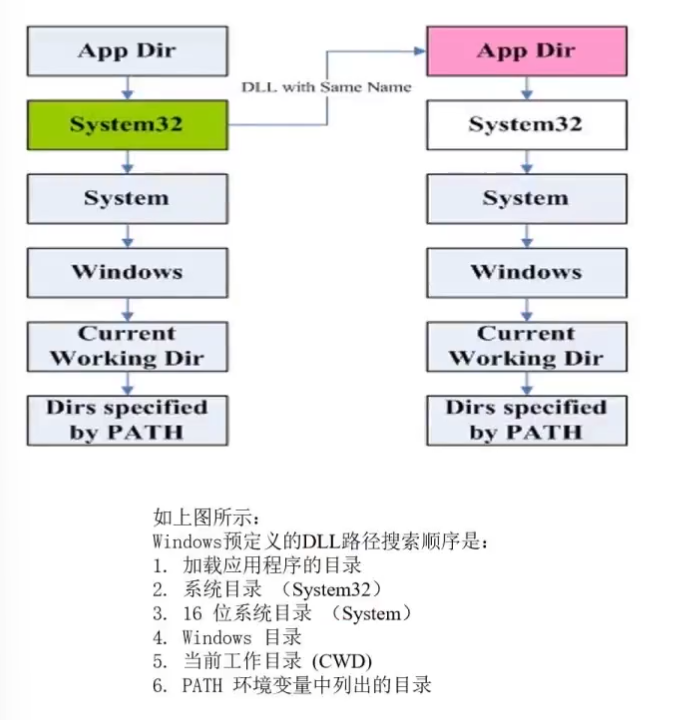
DLL 劫持注入:程序在磁盘上搜索 DLL 文件。
伪造一个系统同名的DLL,提供同样的输出表,每个输出函数转向真正的系统DLL。程序调用系统DLL时会先调用当前目录下伪造的DLL,完成相关功能后再跳到系统DLL同名函数里执行。
注册表注入:AppInit_DLLs与loadAppinit_dll,仅限加载 user32.dll 的程序。
远程线程注入:craeteRemoteThread。
1 2 3 常见的利用CreateRemoteThread来实现远程线程注入的方式有两种: 1.定义远程线程入口地址为LoadLibraryW并将需要加载的模块路径作为参数传入。 2.编写ShellCode并将远程线程入口地址定义为ShellCode的执行地址,在ShellCode中调用Map,到目标进程中的DLL入口函数。
1 FindProcess -> OpenProcess -> VitualAllocEx -> WriteProcessMemory -> CreateRemoteThread
消息钩子注入:微软的不同进程设置消息钩子。
1 FindWindow -> getwindowThreadProcessId -> LoadLibraryEx -> GetProcAddress -> SetWindowsHookEx -> UnhookWindowsHookEx
APC 注入:线程调度的时候操作系统会遍历APC列表,并加载代码。
1 FindProcess -> OpenProcess -> VitualAllocEx -> WriteProcessMemory -> OpenThread -> QueueUserAPC(GetProcAddress(GetModuleHandle))
IAT劫持注入:调用系统 API 的时候,劫持系统导入表函数。
Hook 方式: Inline Hook:minhook 库。
虚表 Hook:call [rax+0x48],把虚表地址进行替换,成为 hook(hook游戏内部函数)。
IAT(导入表) Hook:Hook 游戏所调用的外部 api 的函数。
内核 APIHook(SSDT SSSDT):修改 Shadow SSDT 的表,是全局的。
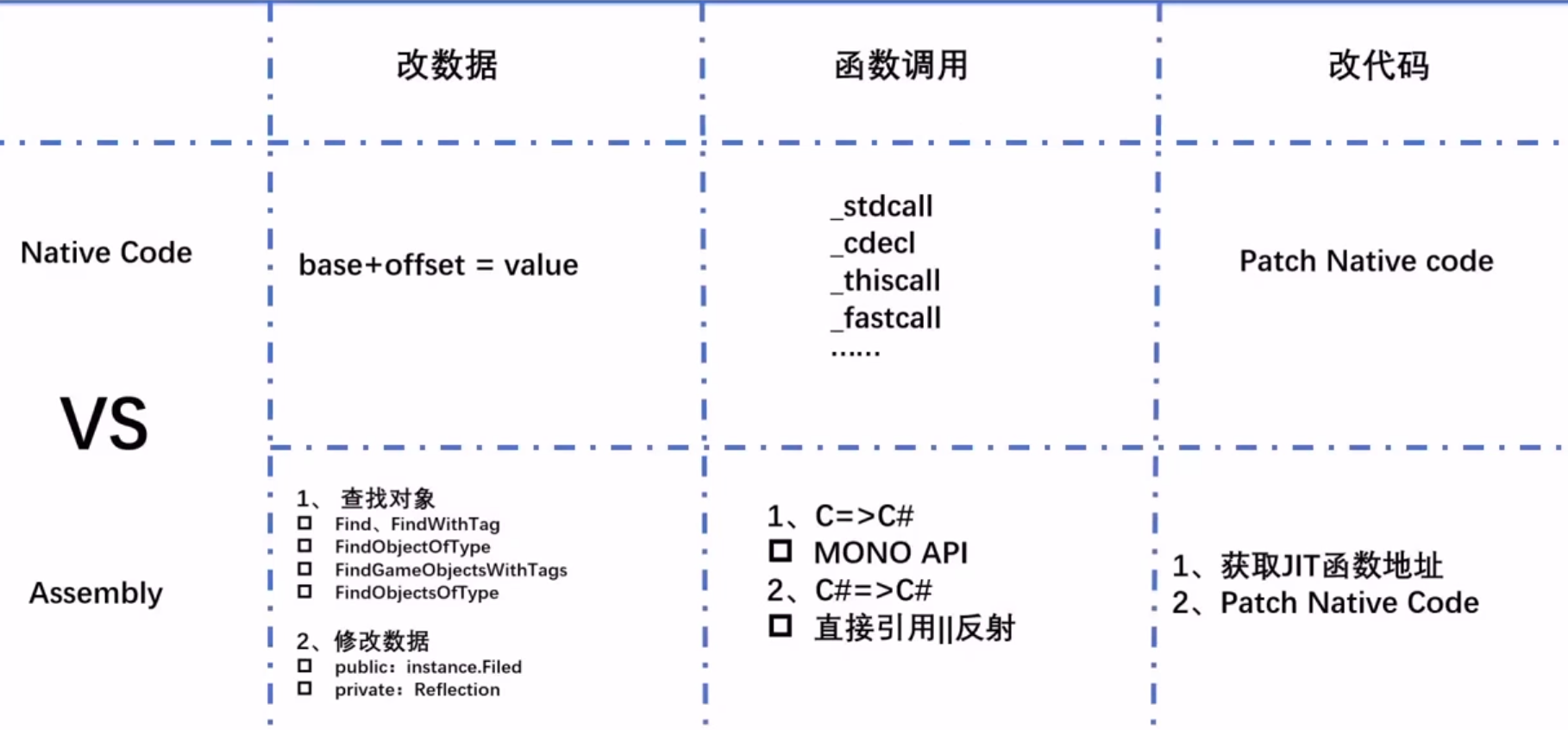
内存读写与监控: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 用户层内存读写方式: (1)OpenProcess + ReadProcessMemory(VM_READ权限)。 (2)劫持句柄+ReadProcessMemory,有一些进程有内存读写句柄(process hacker,ark 工具)。 (3)映射物理内存到自进程。 取目标进程 PID,拿到其 EPROCESS。 获取物理内存范围。 ZwOpenSection。 ZwMapViewOfSections。映射到自己内存中。 内核层内存读写方式: (1)ZwReadVirtualMemory/NtReadVirtualMemory。 (2)MmCopyVirtualMemory(非常多)。 PsLookUpProcessByProcessId MmCopyVirtualMemory (3)MmCopyMemory。通过获取CR3值(页表地址),计算虚拟地址所在的物理地址,调用MmCopyMemory即可直接拷贝转换后的物理地址内存。 (4)RtlCopyMemory(需要先附加到目标进程中)。通过强行切换CR3值切换到目标进程后(附加的方式),直接拷贝需要读取的内存地址即可。
物理地址与虚拟地址转换 物理地址(Physical Address)和虚拟地址(Virtual Address)之间的转换通常涉及到操作系统的内存管理单元(MMU)来完成。在操作系统中,通常采用分页(Paging)或分段(Segmentation)等技术来实现虚拟地址到物理地址的转换。
分页(Paging):在分页系统中,虚拟地址被分成固定大小的页(Page),物理内存也被分成相同大小的页框(Page Frame)。虚拟地址的高位表示页号,低位表示页内偏移。通过页表(Page Table)来映射虚拟地址到物理地址。页表中的每一项包含了虚拟页号和对应的物理页框号。物理地址可以通过以下公式来计算:
1 物理地址 = (物理页框号 << 偏移位数) + 页内偏移
分段(Segmentation):在分段系统中,程序被划分成逻辑段(Segment),每个逻辑段有自己的基地址和长度。虚拟地址由段号和段内偏移组成。通过段表(Segment Table)来映射段号到段基地址。物理地址可以通过以下公式来计算:
在现代操作系统中,内存管理技术更加复杂,可能会涉及到多级页表、TLB(Translation Lookaside Buffer)等结构来提高地址转换的效率和灵活性。
各种断点: 1 2 3 4 5 6 7 8 9 10 11 用户层内存读写监控方式: (1)硬件断点:DR0-DR3。 (2)INT3断点:0xcc。 (3)页面异常断点:页面可读可执行的修改。 (4)ProcessWorkingSet:微软提供的工作集内存,pagefault的时候拿到这个异常。 内核层内存读写监控方式: (1)VT EPT断点监控(CE)。VT EPT 断点监控利用了硬件的扩展页表功能。简单来说,EPT 是一种在虚拟化环境中使用的页表,它负责将虚拟机内部的虚拟地址映射到物理地址。VT EPT 断点监控的原理如下: 1. 设置断点:当需要在虚拟机内的某个地址设置断点时,监控程序(如调试器)会修改虚拟机的 EPT 表,将目标地址所在的页面标记为只读(Read-Only),或者将其映射到一个特殊的页面,该页面用于捕获断点触发时的事件。 2. 执行监控:当虚拟机执行到被设置断点的地址时,由于该地址所在页面被标记为只读或者映射到特殊页面,虚拟机会触发一个 EPT 违规(EPT Violation)。这个违规会导致虚拟机陷入到虚拟机监控程序(VMM)中。 3. 处理违规:VMM 接管虚拟机的执行,根据触发违规的地址和其他上下文信息,确定是否是断点触发,并进行相应的处理。处理可能包括暂停虚拟机执行、触发断点事件、收集相关信息等。
客户端安全开发基础-移动端 客户端逆向分析基础-PC端 unity 游戏很容易使用 dnspy 看源码。而且 UE 与 unity 都有反射机制,使程序能在运行时查询对象的名称、类型、包含的方法、方法参数等等。
找游戏目标代码。
根据内存变化定位目标代码截获游戏日志;
分析日志找到目标代码;
拦截系统API,推测软件行为,找到目标代码;
基于对游戏引擎的分析找到目标代码;
reclass 看内存数据结构,分析游戏可能的结构体。
客户端逆向分析基础-移动端 外挂实例细节剖析-PC端 Unity有:糖豆人、元神(引擎基础加固)、永劫无间(IL2CPP 的 metadata 进行保护)、锁区(固定区域)。
Unity 使用 C#(反射,内存自动管理,有严重的信息泄露风险),UE4 使用 C++。
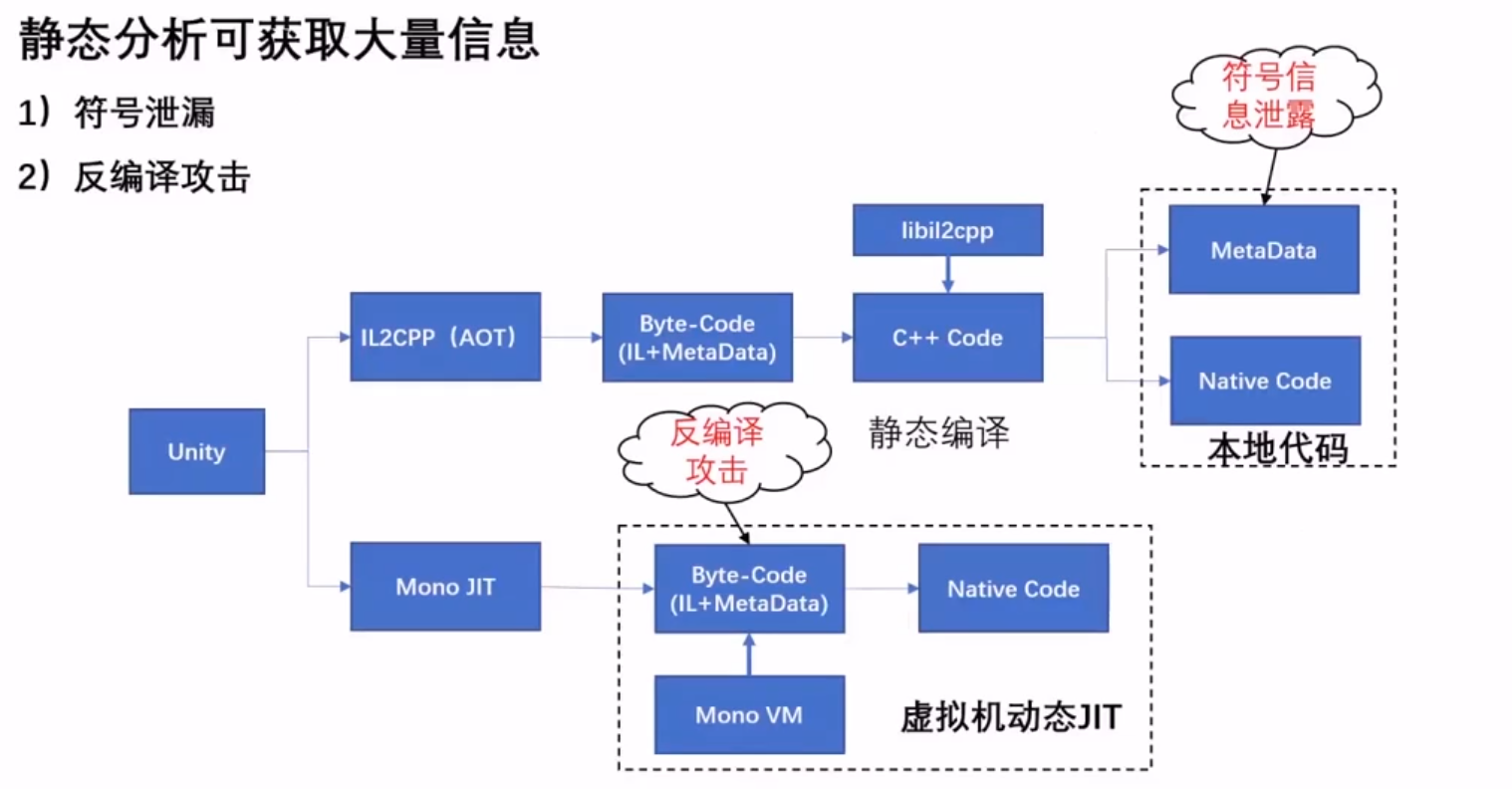
Unity 的安全风险 静态风险
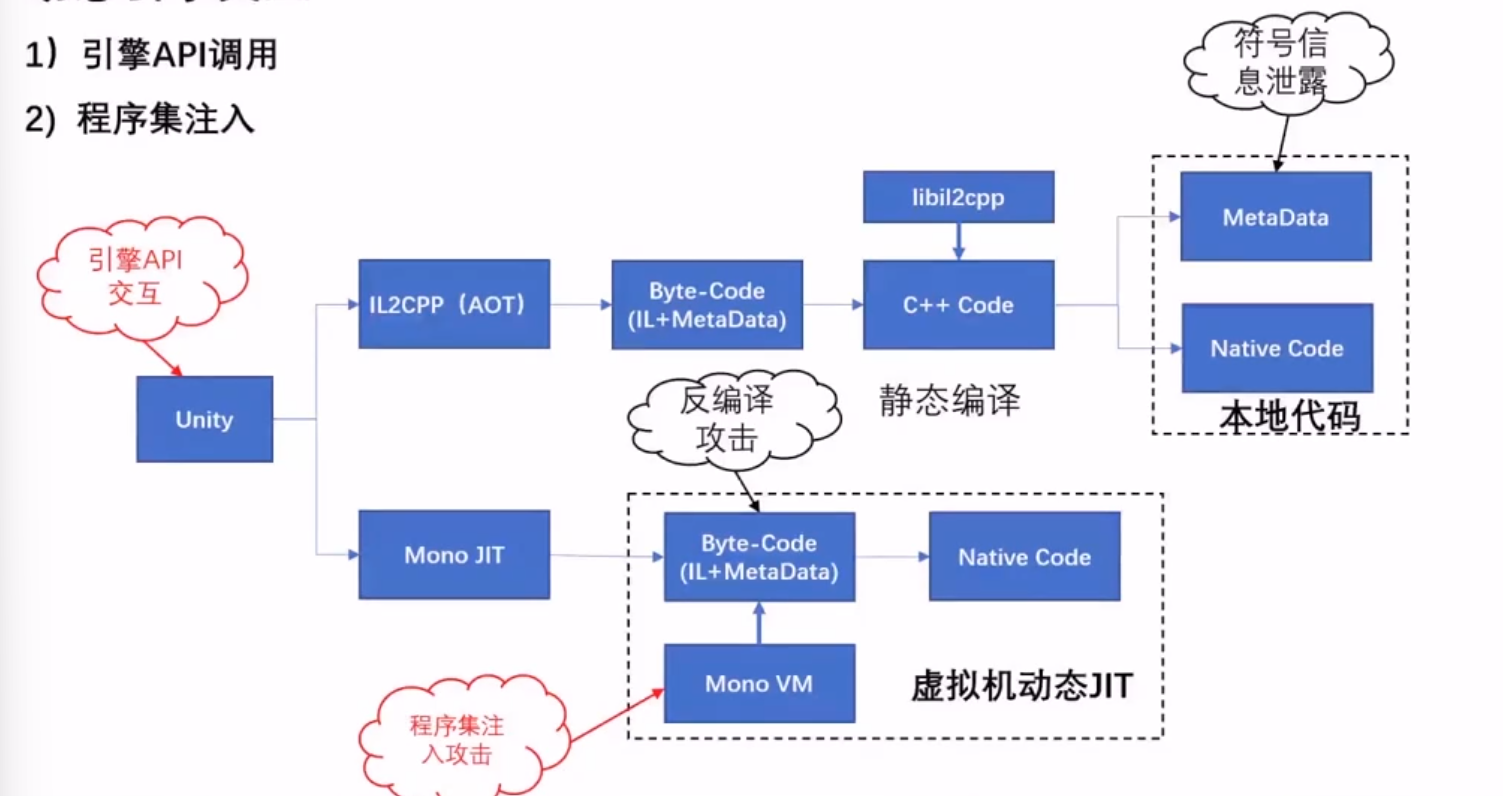
符号泄露(IL2CPP):IL2CPPdumper,获得符号信息,包括类名、方法名。
反编译攻击(Mono):dnspy。
保护方法:符号加密、opcode乱序、metadata加密、方法加密、il加密。
动态引擎风险
引擎 API 调用:C#特性,可以使用 CE 可获得类名、方法名、方法地址等(assembly-sharp)。
程序集注入(Mono):获取 mono 导出接口,注入程序集(针对 mono虚拟机)(sharpMonoInjector)。
保护方法:不让调用 mono api,即使注入了也能发现。
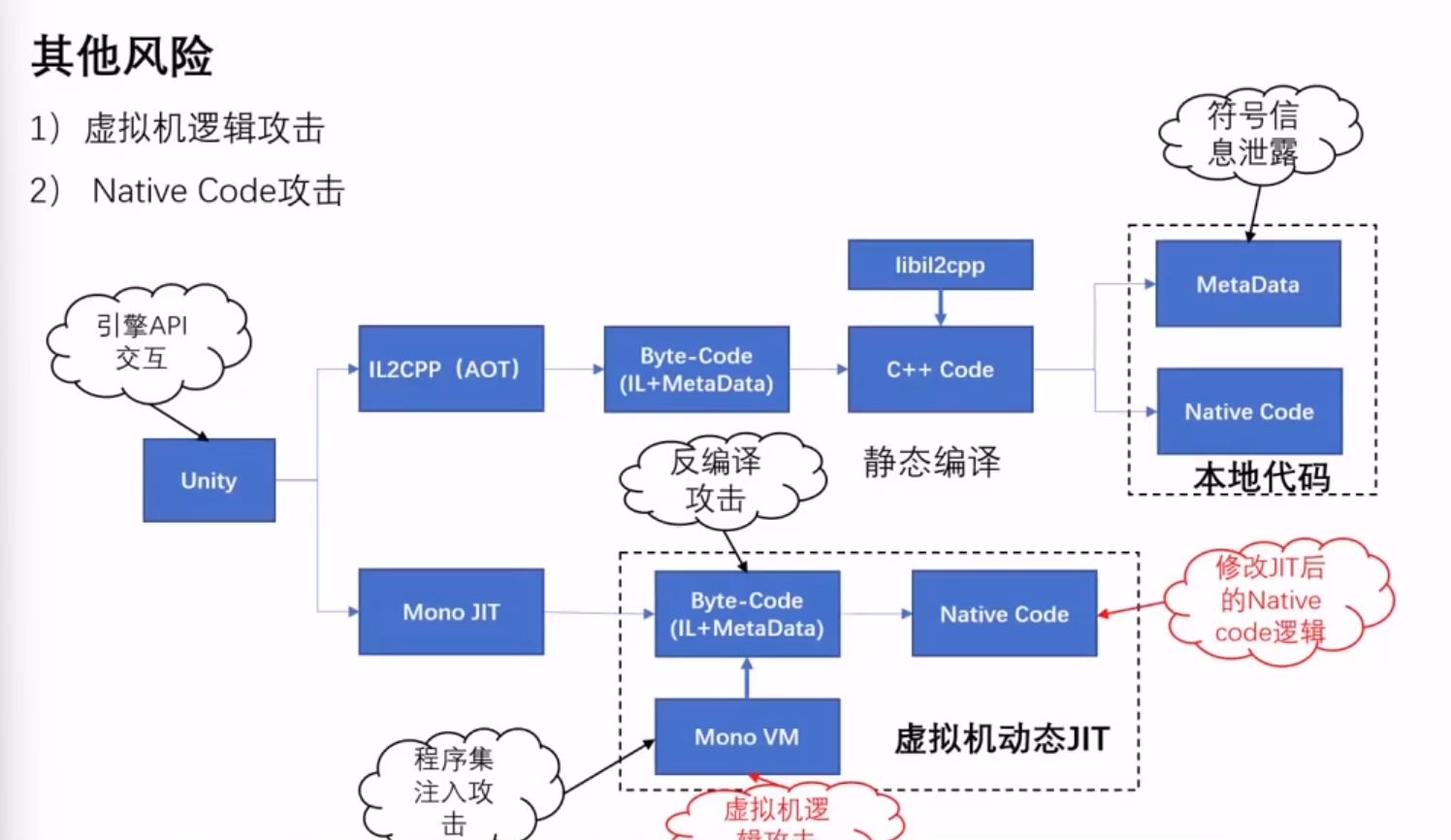
其它风险
虚拟机逻辑攻击:c# 调用到 c++ 的代码,相互调用的机制(mono_add_internal_call)被hook的话就可以整。
Unity 游戏基础
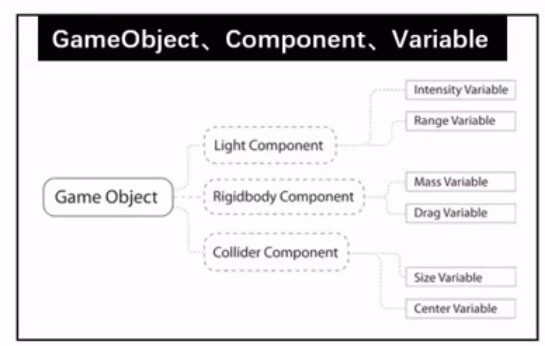
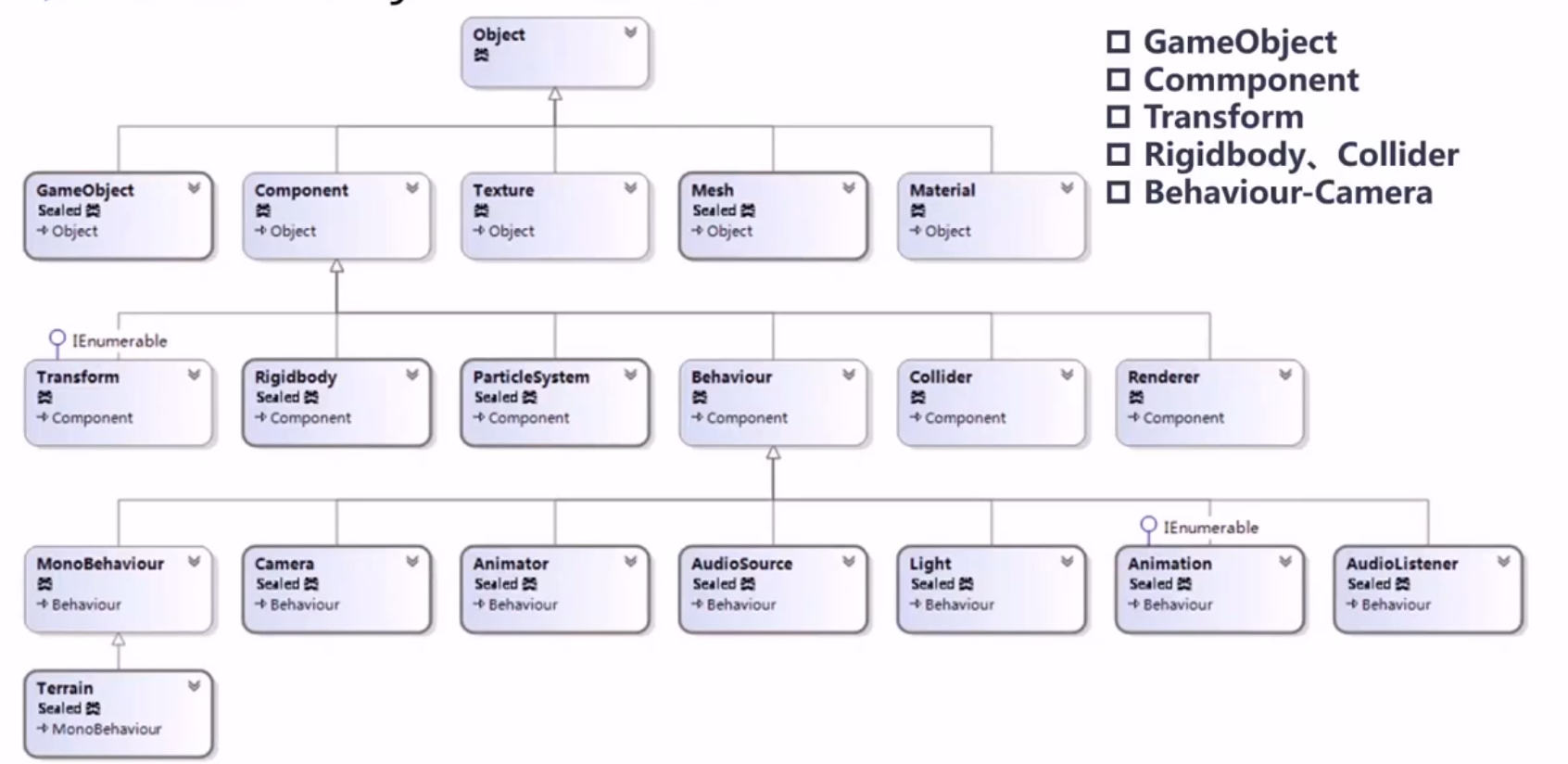
GameObject 至少有 transform 这个组件(component),代表坐标。
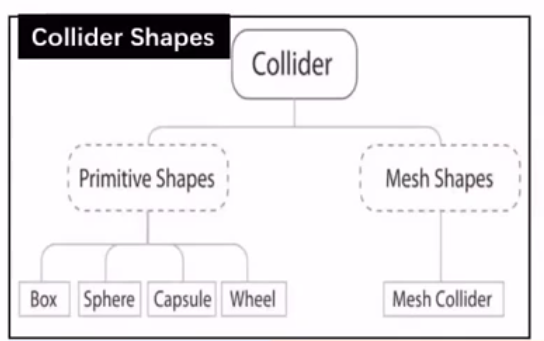
1 2 3 4 弹跳球: 1. 球状网格碰撞(sphere mesh)的gameobject。 2. 刚体(rigidbody component),有重力,摩擦力等。 3. collider component有弹性的物理特性(collider component)。
Unity 类:
unity tag 标签表示属于什么类型。Layer 通常被摄像机用来渲染部分场景,它们也可以用来做射线检测时忽略一些collision使用(穿墙)。
工具:UnityExplorer。
Unity mono 外挂实战
从程序集与 native code 两方面来写外挂。
native code 用 CE 就行,函数调用就是创建一个函数,例如创建快捷键。
程序集就是改 C# 代码,类似于程序集注入,挂一个 component。
游戏破解分析实例-移动篇 外挂防御与检测基础 常规攻击方式
攻击资源文件 修改 CFM 的美化透视实现透视。
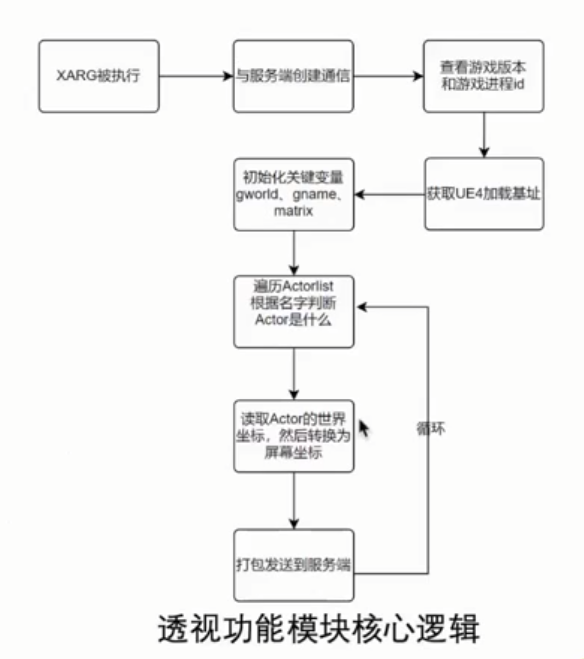
攻击游戏引擎 UE的方框透视。
使用 ULevel::Actors 或 Ulevel::ActorForGC 获取玩家坐标。或者是遍历 ActorChannel 的 tmap。
对于自瞄而言,需要关注 APlayerController::AddPitchinput,偏航角俯仰角。
PC:基于门槛与痕迹的检测防御 进入门槛 反注入、反hook、反调试。用到一些系统 API,拦截这些 API 的调用。以 OpenProcess api 为例:
1 OpenProcess -> ZwOpenProcess -> NtOpenProcess -> PsOpenProcess
但是 SSDT hook 容易被 ark 工具发现。
那么我们可以 hook 调用 obOpenObjectByPointer。还有其他的 API(反调试):
进入后的痕迹检测
移动端:基于门槛与痕迹的检测防御 移动端 app 只有普通权限,没有 root。
1 2 门槛方案:仅能局限在普通权限下进程空间本身。 痕迹检测:仅能在普通权限下进行一些文件,进程等信息进行检测。
门槛方案 加固
关键模块自实现不使用 syscall ,而是使用中断。反调试的方法:
端口号23946是否使用?/data/local/tmp 是否有 frida 相关?
调试陷阱:触发异常,关键信息放到信号处理函数(IDA 会截获)(如果没有执行信号处理,则就是反调试状态)。
代码混淆
痕迹检测 1 2 3 4 5 6 7 8 9 10 11 12 文件读写: (1)针对进程自身pid下的各文件,写入文件/so等 (2)inotify可感知外部进程对指定文件的操作,示例:/proc/pid/mem 内存遍历: (1)内存页属性(可读可写可执行的页)+页名称,/proc/pid/maps (2)内存页属性+匿名 破解版: (1)针对透视破解版需创建界面用于绘制透视方框的特点进行检测,截不到界面,悬浮,不响应触摸,是否有叠加层权限? (2)alert_window权限 (3)windowsmanager,遍历所有的 view,是否响应触摸?
基于行为与表现的检测方法 基于过程 以透视为例:渲染,人物在前,建筑物在后。
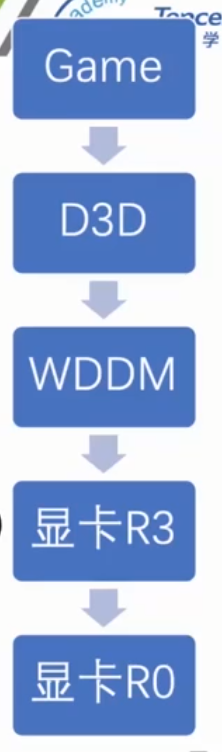
1 2 3 4 5 6 7 8 9 10 11 渲染类透视拆解: 输入:介入游戏的DrawIndexedPrimitive 中间过程:iStread 比较,SetRenderState 输出:人被显示了 检测方法: 输入:完整性校验(IAT,虚表),第三方组件(多版本,调用链) 中间过程:(隐蔽性,稳定性)。Callstack检测 输出:截图 D3D 实现图形渲染,WDDM 是显示驱动程序模型。
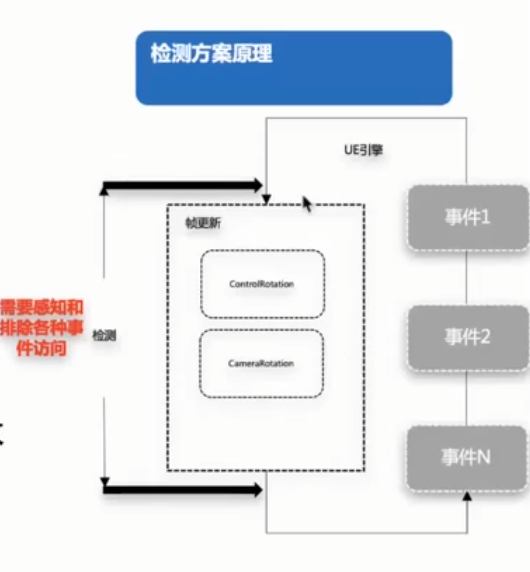
以自瞄为例:跨进程读数据,计算下一步秒哪儿(朝向数据变化),然后改游戏属性。
主要 API 就是 controlRotation 与 cameraRotation,在两帧之内是否有异常访问。
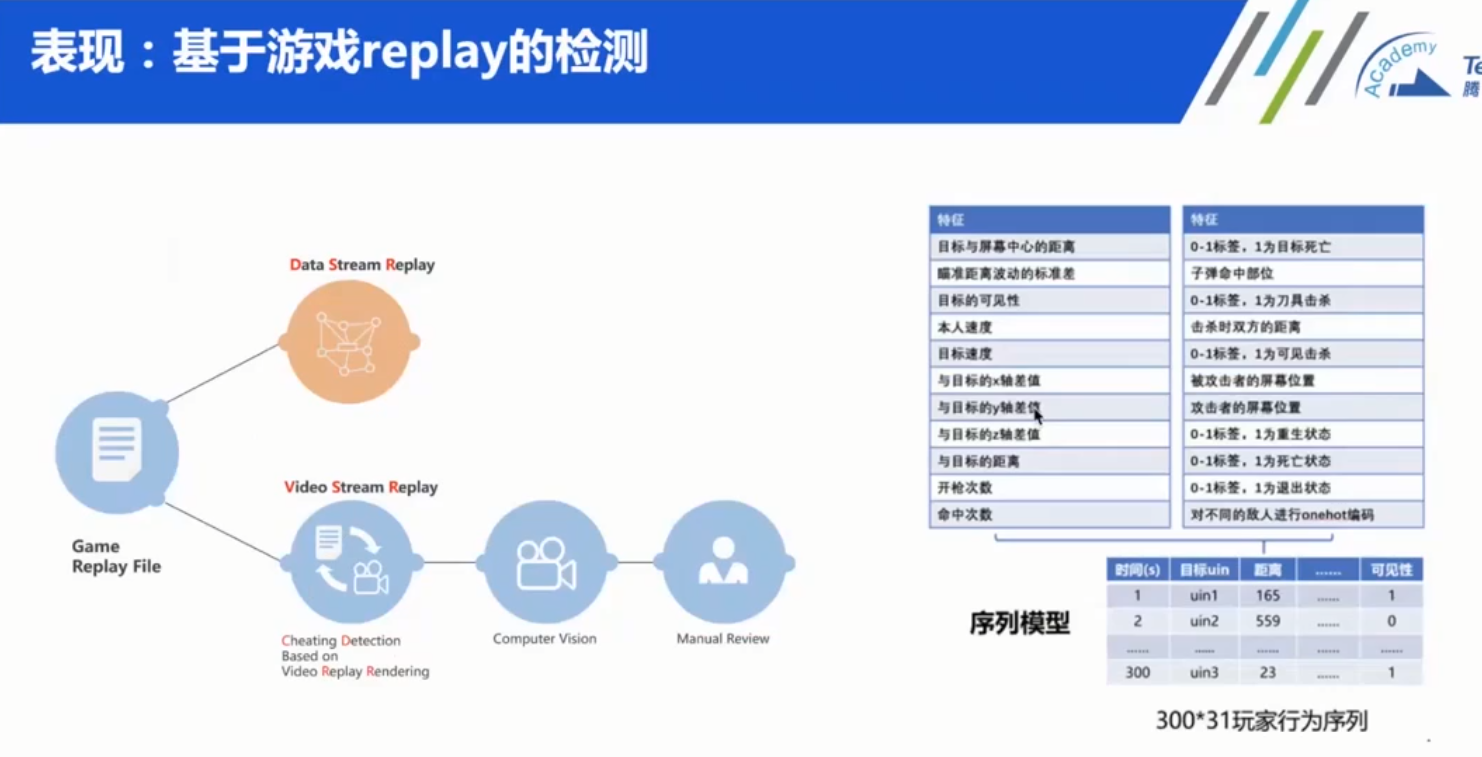
基于结果 服务端录制的,可以验证基于行为的策略的有效性。
难点:
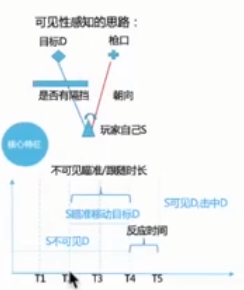
(1)从视频中数据解析与提取。
(2)可见性判定,如何判断用户能否看到对手。
0x01-16 游戏安全大赛题解(2024与2020) https://bbs.kanxue.com/thread-281334.htm
https://xia0ji233.pro/2024/03/30/tencent-race-2020-pre/






.png)