Password-Stealing-without-Hacking
WiKI-Eve:Wi-Fi Enabled Practical Keystroke Eavesdropping
摘要
Wi-Fi 的非接触式特性可以泄露隐私,但针对 Wi-Fi CSI(信道状态信息)的攻击需要攻击 Wi-Fi 硬件,这非常困难。为此,我们提出了 WiKI-Eve 技术,无需攻击即可窃听智能手机上的按键操作。 WiKI-Eve 利用了 Wi-Fi 硬件提供的 BFI(波束成形反馈信息)功能:由于 BFI 以明文形式从智能手机传输到 AP(路由器),因此它可以被切换到监听模式的 Wi-Fi 设备偷听。WiKI-Eve 还创新了对抗性学习方案,使其推理能够泛化到未见过的场景。结果表明,WiKI-Eve 对单个击键的推理准确率达到 88.9%,对窃取移动应用程序(例如微信)密码的准确率高达 65.8%。
没找到代码呜呜…
本文贡献
当前窃取手机密码需要好多前提:(1)窃听设备靠近受害设备;(2)流氓软件被植入受害设备;(3)窃听内容具有语言结构。
在所有侧信道中,Wi-Fi CSI(信道状态信息)似乎无需上述前提。 本质上,由于击键会影响无线通道(如下图所示),因此可推断输入的密码。
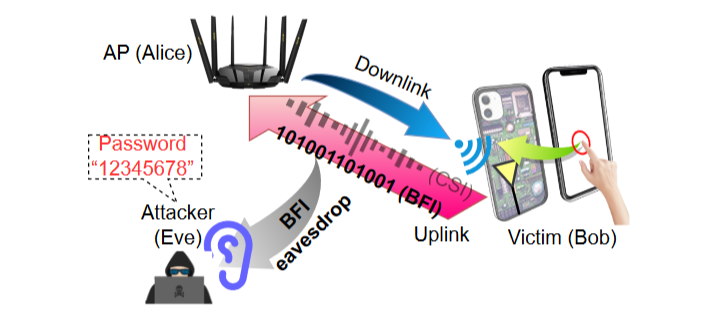
但是,尽管 CSI 很早就被 Wi-Fi 硬件黑客攻击,但到目前为止,只有少数此类硬件被黑客攻击,而 Wi-Fi 标准却在不断变化。因此,基于 CSI 的旁道攻击无法跟上技术的发展。
从 WiFi 5 开始,WiFi 硬件搭载了 BFI(波束成形反馈信息),即模拟 CSI 的压缩数字版本,其以明文形式控制帧。BFI 将下行链路信道状态反馈回接入点 (AP),以指导 AP 波束成形(AP信号指向移动设备,从而使得信号更好)。尽管只考虑了与 AP 侧有关的下行链路 CSI 的一部分,但击键可影响 Wi-Fi 天线,使得 BFI 包含有关击键的足够信息。因此,任何能够监听 Wi-Fi 流量的设备都可以免费获得 BFI,从而获得击键。
但是,我们要解决两个问题:(1)密码缺乏自然语言中的语言结构(例如单词结构和字母出现频率)来作为先验信息,因此,密码推断要么依赖于独立的击键特征,要么利用两次击键之间的转换特征。但是,这些特征具有很强的环境依赖性,由此推理方法很难泛化。尽管监督学习技术可以通过包含足够训练数据的数据集来解决此问题,但由于智能手机型号多样化和人类打字习惯,标记数据集非常困难。(2) BFI 可能是稀疏的,即在信号中很少出现 BFI。
WiKI-Eve 通过窃听按键引起的 BFI 变化来窃取密码。针对问题(1),使用识别单个击键的方法,利用具有自然分割为输入的深度学习模型来以消除基于规则的分割和环境干扰引入的噪声,利用对抗性学习来提取单个击键相关的特征。这种跨域训练利用有限的训练数据将击键推理泛化。针对问题(2),设计了稀疏恢复算法来解决数据不足问题。本文贡献如下:
- 利用明文 BFI,利用 Wi-Fi 设备窃听密码。
- 利用对抗性学习来消除环境依赖性,使 WiKI-Eve 的模型可推广到未见过的场景。
- 稀疏恢复算法来解决BFI的稀疏性问题,处理训练击键推理模型时的数据缺乏问题。
背景知识
攻击场景及方式
我们考虑这样一种场景:受害者 Bob 使用他的移动设备连接到没有密码保护的 Wi-Fi 接入点 (AP), Bob连接到AP上网后,需要访问受密码保护的敏感账户(例如在线支付),这使得他成为Eve发起的攻击目标。 从这里开始,我们的方法与现有的方法不同,现有的方法要么需要恶意 AP 来欺骗 Bob 使用其服务,要么需要设置额外的 Wi-Fi 通信链接来窃取Bob 的打字。
WiKI-Eve 的攻击方法利用配备网络接口卡 (NIC) 的笔记本电脑。其中,Bob 和 AP 之间的 Wi-Fi 链路(CSI)被用来窃取密码,如下图 (a) 所示,WiKI-Eve 进行了创新,将我们的方法称为 o-IKI(无意中窃听带内击键推理),不再需要破解 Wi-Fi NIC 并欺骗 Bob 将其用作 AP。
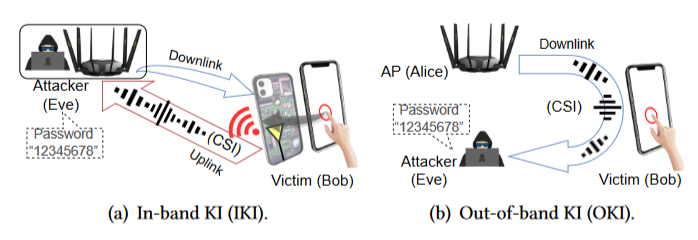
另一种方法称为带外击键推理 (OKI),如上图 (b) 所示,要求 Eve 使用 Wi-Fi NIC 和另一个设备(例如 AP)创建一个与 Bob 无关的单独通道,Eve 通过观察该通道的 CSI 来推断 Bob 的击键。与依赖模拟 CSI 的 OKI 相比,o-IKI 窃听 BFI 的数字特性有更大的传感范围,而击键推理 KI 的带内传感则确保了足够高的信噪比(SNR)。与 IKI 让 Eve 通过其恶意 AP 直接观察数据流量不同,o-IKI 和 OKI 要求 Eve 能够识别 Bob 的设备,而这在 OKI 下很难实现。
为什么选择 BFI?
(1)BFI 易于获取。
(2)BFI 对通道变化的敏感度低于 CSI,使得传感结果更加稳定,尤其是 IKI 对 Wi-Fi 通道的密切影响(来自屏幕上的击键)。这种稳定性源于 BFI 的生成方式,给定下行链路 CSI 表示为 $H = Y/X$,其中 $X$ 和 $Y$ 分别表示发送 (Tx) 和接收 (Rx) 信号,BFI 是通过将 H(它代表的信道)划分为单独的 Tx 和 Rx 组件,仅 Tx 分量反馈至 AP 以指导 AP 波束成形。由于这种通道分割,BFI 不太容易受到 IKI 屏幕上按键引起的通道变化的影响,否则会导致支持 CSI 的 KI 中出现明显的歧义。
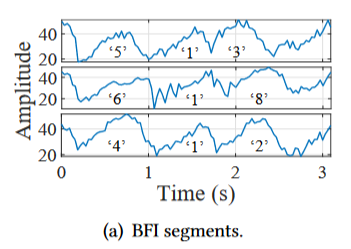
为了验证上述原因,利用 iPerf 生成饱和流量并仅收集原始 BFI 和 CSI 样本,下图显示了单击四个不同键的 BFI 时间序列和频谱图,证实了这些键之间的显着区别:
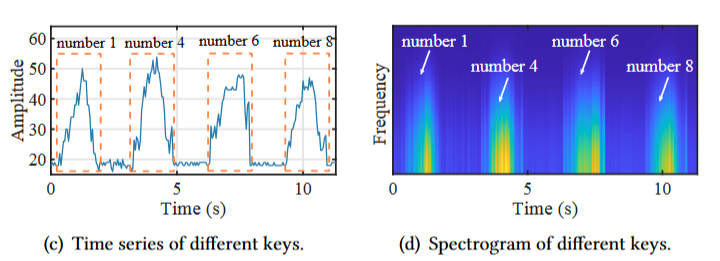
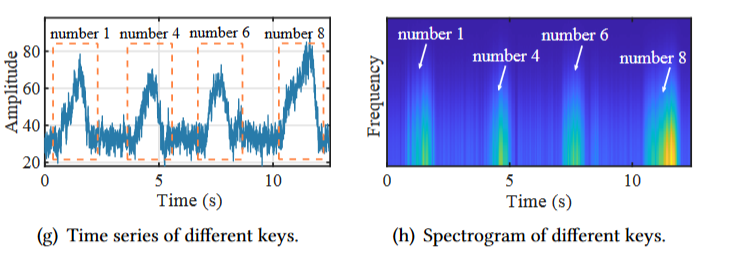
同时,下图对于 CSI 的四键测试也表明进行 KI 之前需要进行一些重度去噪,因为某些键之间的区别(例如4和“6)似乎被噪音淹没了,因此需要预处理:
WiKI-Eve的设计
设计流程包括五个步骤:(1)识别受害者;(2)确定受害者访问目标应用服务时的攻击时间;(3)捕获受害者的BFI时间序列;(4)解析和恢复稀疏的 BFI 系列;(5)对 BFI 系列进行分段并执行 KI 来恢复密码。如下所示:
步骤1&2
Eve 可以通过流量监控来识别受害者:将各种 MAC 地址的网络流量与用户行为相关联,从而识别 Bob 的 MAC 地址。 受害者识别只能通过 IKI 实现,因为 OKI 的模拟性质禁止使用标头信息来区分多个主体。
一旦锁定了 Bob 的 MAC 地址,Eve 就会当 Bob 即将输入密码时发起攻击。Eve 可以j监视对支付服务提出的请求,对微信而言,Eve 创建了一个与支付服务相关的 IP 地址数据库:虽然此类 IP 地址可以是动态的,但实验表明,来自同一地区的用户在一定时间内会被定向到相同的 IP 地址。
步骤3&4
首先解释一下 BFI 是如何生成的:BFI 是 CSI $H$ 的发送组件,并被反馈以指导 AP 波束成形。 通过 SVD(奇异值分解),它将 $H$ 分解为 $H=USV$。 在这些组件中,右侧矩阵 $V$ 为 BFI, $U$ 和 $S$ 分别代表接收端波束成形和通道增益。 Bob 的密码输入会影响手机周围 Wi-Fi 信号的衍射。 这种改变反映在下行链路 CSI 中,而下行链路 CSI 用 SVD 分解以获得 BFI 。
由于 BFI 以明文形式传输,Eve 可以使用处于监视模式的 Wi-Fi 设备以及 Wireshark 抓取,遵循 802.11ac 的帧结构,可在VHT 波束成形报告字段中来定位 BFI。为了完全提取 BFI,可以根据 Tx 和 Rx 天线的数量计算场的长度(这是什么意思?)。如果由于时间窗口内控制帧率较低(BFI在控制帧中)而导致 BFI 时间序列过于稀疏,WiKI-Eve 会恢复 BFI 序列。
步骤5
我们将详细介绍 WiKI-Eve 如何进行 BFI-KI(击键推断)。首先讨论以前方案的缺点并提出改进。指定 BFI 系列上的信号分割来启动 KI,然后设计 KI 神经模型及其对抗性学习框架,将 KI 泛化。
现有技术的缺点
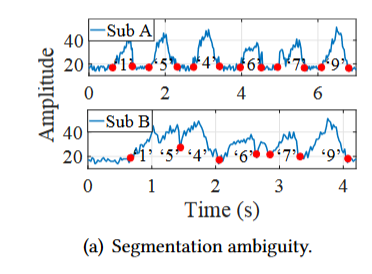
WindTalker 通过独立的基于规则的 CSI 分割对各个击键进行分类。这种分割可能导致信息丢失,我们要求两名受试者在各自的智能手机上输入密码,下图显示了他们相应的 CSI 系列。显然,由于受试者不同的打字习惯,虽然基于规则的分割对于打字更稳定的主体 A 可能有效,但对于 B 来说可能失败。
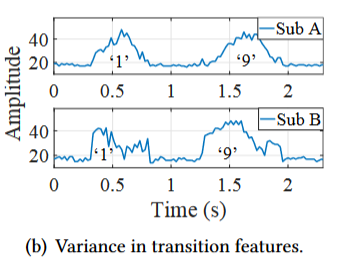
WINK 通过系列学习(series learning)(应该是一个密码序列)来提高 KI 性能。 然而,它继承了基于规则的分割,因此也有同样的弱点。 此外,由于语言结构不能用于系列学习,WINK 认为击键之间的过渡特征可以作为提高 KI 准确性的替代方法。但是,打字习惯和智能手机类型等因素可能会在过渡期间影响 CSI,从而导致同一密码具有不同的特征,如下所示,可见过渡特征也不靠谱:
WiKI-Eve 使用由 WindTalker 执行的推断单个击键的规范方法。为了防止分割中的信息丢失,WiKI-Eve 将过渡期视为同一数字击键的不同域。因此,利用对抗性学习来训练 KI 模型,旨在消除域干扰(即环境依赖性),从而将 KI 推广到未见过的场景。请注意,WiKI-Eve 不太可能使用系列学习,如果这样,它需要一个非常大的训练数据集,其大小随着密码长度增长呈指数增长。
信号分割
BFI 序列可能不会显示连续击键之间的明显边界,从而使信号分割变得非常复杂。下图提供了这种情况的示例,其中 BFI 序列显示了与 Bob 的手指敲击屏幕相对应的突出峰值,以及代表其手指的过渡运动的两个峰值之间的波动。由于过渡期携带先前和后续击键的信息,因此相邻击键的片段应包含该过渡。因此,我们建议采用重叠分割方法,该方法合并位于两个连续峰值之间(从前一个峰值到后续峰值)的所有数据样本。
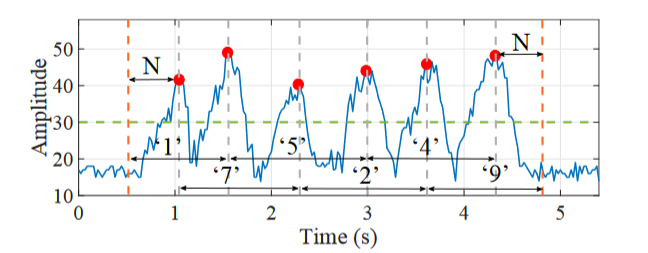
分割方法首先利用恒定误报率 (CFAR) 算法来识别 BFI 系列中的峰值。假设 Bob 输入 K 位数字密码,经过稀疏恢复后产生长度为 L 的 BFI 序列,CFAR 算法对该序列进行统计分析,以确定一个自适应阈值,并选择超过该阈值的峰值作为候选人。在这些候选峰中,我们进一步消除了距主峰 W 个采样点距离内的次要峰(主峰如何判断?)。然后,我们在 W 个采样点的峰间距离的辅助下,选择与密码中的 K 个数字相对应的前 K 个峰值,其中$W=\alpha\times\frac{L}{K}$。由于密码中的第一个和最后一个数字没有前后数字,因此我们选择扩展前后的 $N$ 点作为段边界,其中$N=\beta\times\frac{L}{K}$。我们将根据经验确定 $\alpha$ 和 $\beta$ 值。如上图,这种方法有效地将 BFI 系列(密码175249)划分为与各个击键相对应的片段。
对抗性学习框架
本节解释如何利用对抗性学习将 KI 推广到未见过的领域。时间序列分类可以使用一维 CNN 有效解决。然而,BFI 段的长度可能不同,这对传统的一维 CNN 提出了挑战。为了克服这个问题,采用自适应平均池层(减少参数量)来增强一维 CNN 的灵活性。具体来说,该层自动计算生成固定大小的输出特征图所需的适当内核大小,从而使一维 CNN 能够适应不同长度的输入。
上面的深度学习方法忽略了域对每次击键的影响。域指的是击键前到击键后的转换所产生的上下文,它由打字速度、相邻击键等影响。如下所示,考虑三个不同域中的数字键”1”:”5-1-3”、”6-1-8”和”4-1-2”,并呈现它们相应的特征图,可以发现有极大的不同。
上述域干扰需要一种确保 KI 对此类干扰不变的方法,因此采用域适应的思想来学习跨不同域不变的击键表示。 WiKI-Eve 利用对抗性学习,将域适应与 KI 集成到统一的训练过程中,从而在不同领域实现一致的特征空间表示。训练过程如下所示:
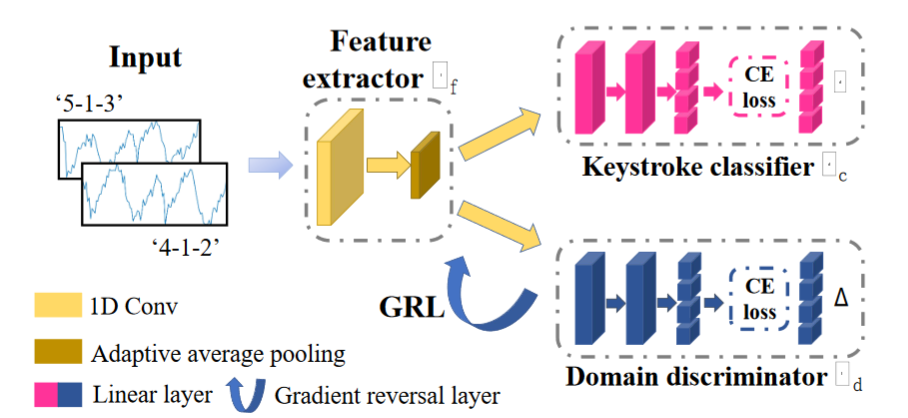
在训练阶段,首先准备随机成对的 BFI 片段组成的数据集,这些片段对应于相同的密钥(例如”1”),但在不同的域下,例如”4-1-2”和”5-1-3”。我们将这对连接起来作为输入 $x$ 并过特征提取器 $G_f$ ,然后输出给到击键分类器 $G_c$ 和域鉴别器 $G_d$ :$G_c$ 推断出对中两个段相同的键 $y$,$G_d$ 预测域差异 $\Delta\in{0,1}$,其中 0/1 分别表示密钥来自/不来自同一域。虽然 $G_d$ 的目标是提高预测 $\Delta$ 的准确性,但对抗性学习策略通过使用梯度反转层(GRL)来反转损失,从而欺骗 $G_d$;此过程抑制 $G_f$ 输出中的特定于域的特征,从而允许一维 CNN 学习跨域不变的击键表示。
将 $Gf$ 、$G_c$ 和 $G_d$ 的参数分别表示为 $\theta{\mathbf{f}}$、$\theta{\mathbf{c}}$ 、$\theta{\mathbf{d}}$,上述训练过程可以表示为:
其中,有$\mathcal{L}(y,\Delta,\boldsymbol{x})=\mathcal{L}{\mathrm{C}}(y,G{\mathrm{C}}(G{\mathrm{f}}(\boldsymbol{x})))-\lambda\mathcal{L}{\mathrm{d}}(\Delta,G{\mathrm{d}}(G{\mathrm{f}}(\boldsymbol{x}))$,$\mathcal{L}{\mathrm{C}}$与$\mathcal{L}{\mathrm{d}}$代表$G_c$与$G_d$的交叉熵损失,$G_d$ 在推理阶段被丢弃,并且通过复制原始 BFI 段(一对片段”4-1-2”与”4-1-2”)来模拟段对 x 的输入。
恢复稀疏 BFI 时间序列
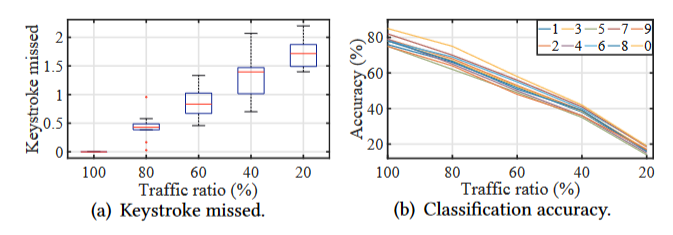
WiKI-Eve 的另一挑战是流量稀疏性。为了研究稀疏流量如何影响击键丢失和分类准确性,使用 iPerf 生成设备和 AP 之间的数据流量。以 6 位密码为例,我们可以观察到漏击的击键次数几乎随着稀疏度呈线性增加,如下图 (a) 所示。 当流量比例为20%时,最多可能会错过2次按键。 即使对于那些没有遗漏的击键,如下图 (b) 所示,当流量比例下降到 20% 时,对单个数字进行分类的准确率也会从 80% 下降到不到 20%。
我们提出了SRA(稀疏恢复算法)。具体而言,我们使用长度为 $\Delta t=1s$ 的滑动窗口来检查是否包含足够的样本,如果滑动窗口内50%的时间段没有BFI,则攻击失败,若大于50%,启动SRA(说明不能太稀疏)。如下图所示,SRA 首先对收集的序列进行重新采样,使其以 $f_s$ 的采样频率均匀分布。随后,该序列被归一化到[0, 1]的范围,没有数据样本的片段被标记为-1。重采样后,我们将 SRA 的输入数据表示为从BFI中提取的一维时间序列 $x_t$,其中 $t$ 是采样时间。 SRA 将输出均匀且密集采样的时间序列 $y_t$。
为了生成缺失样本,SRA 采用基于 AE(自动编码器)网络的 TCN(时间卷积网络,例如LSTM),由编码器和解码器组成,如下图所示。TCN 使用具有扩张内核的卷积层来捕获样本中的远程依赖性,同时保持参数数量的可控性。 TCN-AE 以自我监督的方式进行训练:首先使用饱和流量生成非稀疏 BFI 系列,然后随机删除数据样本以创建稀疏序列,通过遵循真实的时间分布来模拟现实的稀疏性。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!