zpoline
zpoline:基于二进制重写的系统调用钩子机制
优势:钩子开销低、不会覆盖不应修改的指令、无需更改内核(什么意思?)、不需要用户态程序的源代码、不需要依赖特定的标准库、可用于系统调用仿真、详尽的钩子(exhaustive hooking)。
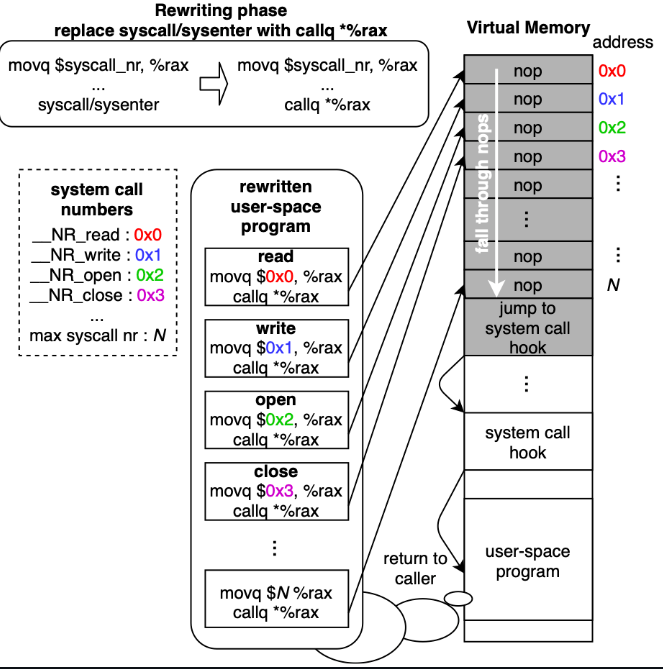
主要难点在于:很难用 jmp/call 替换 syscall/sysenter 来跳转到任意钩子函数,因为 syscall 和 sysenter 是两字节指令,并且通常需要更多字节来指定任意钩子函数地址。
zpoline用两字节 callq *%rax 指令替换了 syscall/sysenter,并在虚拟地址 0 处实例化了 Trampoline 代码。与现有机制相比,zpoline 的开销降低了 28.1~761.0 倍,现有机制确保了详尽的钩子、不覆盖不应修改的指令。由 zpoline 绑定的 Redis 和用户态网络与传统机制相比,性能仅降低了 5.2%,而现有机制会降低 72.3%~98.8% 的性能。
由于用户态程序总是通过系统调用来执行重要操作,因此系统调用钩子可以成为跟踪和更改程序行为的有效位置。因此,此钩子可以用在trace、沙箱、OS仿真、新操作系统子系统的二进制兼容性支持中。很多研究表明,由内核旁路框架(kernel-bypass frameworks)支持的用户空间操作系统子系统性能很优秀。原则上,系统调用钩子使我们能够透明地将用户态OS子系统应用到遗留软件工件(legacy software artifacts),并且透明度是用户态OS子系统适用性的重要因素(不太懂)。
注:
- 用户态OS子系统是运行在用户空间中的操作系统组件或服务。
exhaustive hooking(详尽的钩子)是一种对内核进行全面钩子的技术,允许用户空间程序对内核的各个部分进行监控和操作。这种技术使得用户空间程序可以拦截和修改内核的函数调用、系统调用、中断处理等操作。
现有的系统调用钩子有:
(1)Syscall User Dispatch (SUD)、int3的传统二进制重写、现有内核支持等技术,会导致极大的性能下降。
(2)二进制重写技术如instruction punning、E9Patch,函数调用替换(LD_PRELOAD)不能达到详尽的钩子这样一个目标(为什么?),因此不能用于需要可靠性的系统。
(3)二进制重写技术如Detours只能重写不该被修改的指令。
(4)针对内核的特定修改如Dune是硬件的不同,应用程序很难移植到上面。
(5)需要重新编译源代码,例如Unikernel,不太实用,很多情况下无法访问程序源代码。
(6)链接经过修改的libc,将系统调用替换为特定OS子系统的函数调用,无法钩取所有的调用,且无法钩取发生在外部标准库中的系统调用。
(7)BPF/eBPF允许用户钩取内核态函数,它们不能在没有修改内核源代码的同时模拟系统调用。
注:
syscall和sysenter这两个字节指令(分别为0x0f 0x05和0x0f 0x34)。- 系统调用的原理:当用户态程序执行
syscall/sysenter时,上下文会切换到内核,然后系统调用处理程序。为了切换到内核,执行特定的系统调用,用户态程序在触发系统调用前将系统调用号(例如,0 表示读取,1 表示写入,2 表示打开)存放到到rax,在内核中,系统调用处理程序根据rax寄存器的值执行其中一个系统调用。
0x00 原理
在本文中,将syscall/sysenter用callq *%rax(0xff 0xd0)代替,其中*表示间接引用,即访问%rax寄存器中的值所指向的地址。为什么不用callq *%rax?这是因为它仅占1字节。正常情况下,rax存放的是系统调用号,因此,此指令会跳转到虚拟地址0->500。
要重定向到用户定义的钩子函数,zpoline 在虚拟地址 0 处实例化了 Trampoline 代码(即0到最大系统调用数之间的虚拟地址被单字节nop指令填充),并且在最后一个nop指令后,有一段跳转到特定钩子函数的代码。
在trampoline代码实例化和二进制重写完成后,重写的部分(callq *%rax)将跳转到trampoline代码中的nop之一,同时将调用者的地址压入堆栈。执行会向下滑动后续的nop;执行完最后一个nop后,跳转到钩子函数。这里,钩子函数将具有与内核空间系统调用处理程序相同的寄存器状态。最后,钩子函数的返回跳转回callq *%rax压入栈的调用者地址。
注:zpoline 本身并不提供安全增强功能。如果用户希望提高zpoline应用系统的安全性,可以采用现有的机制。例如,seccomp可以过滤由 zpoline 的用户空间程序触发的内核空间系统调用的执行,而 CPU 支持(例如内存保护密钥MPK)可以隔离钩子函数的实现。
0x01 实现过程
(1)使用mmap分配虚拟地址为0的内存。注:默认情况下,仅允许root用户映射到虚拟地址0的内存,但可以通过将/proc/sys/vm/mmap_min_addr设置为0来允许所有非root用户映射到虚拟地址0。接着,将0-500存入nop,然后在后面存放跳转到钩子函数的代码。并在相应位置存放钩子函数。
(2)遍历可执行内存区域,将`syscall/sysenter用callq *%rax(0xff 0xd0)代替。
注:此实现不会更改用户态程序的二进制文件,因为二进制重写是在加载到内存的代码二进制上完成的。上述过程是通过导入库libzpoline.so完成的。
0x02 进一步优化
优化1
如果要修改钩子函数的代码,就要修改libzpoline.so。然而,若钩子函数中如果也执行有syscall/sysenter,就会陷入无限循环。为了避免这种情况,使用了dlmopen(dlopen的扩展)。dlopen用于向用户态程序加载库文件,而dlmopen允许用户指定加载库的命名空间,并在同一个命名空间中进行关联。
因此,dlmopen可以帮我们屏蔽导入的libzpoline.so中的钩子函数。使用dlmopen打开libzpoline.so,且使用dlsym(动态链接库操作句柄与符号,返回符号对应的地址)获得钩子函数的指针。钩子函数在libzpoline.so中实现,并通过指针来调用它。
优化2
通常虚拟地址0是null指针,你占掉不太合适吧,这会导致null访问终止无法进行下去。null访问终止是一种保护机制,当变量为null时,就会触发此机制。为了让此机制继续运行下去,做了如下优化:
(1)为了终止null的读写,zpoline将trampoline代码配置为eXecute-Only Memory (XOM);用户态程序要读写XOM处的内存时会显示错误。
注:在支持内存保护密钥MPK的CPU上运行Linux,mprotect系统调用当参数为PROT_EXEC时,会配置为XOM(仅执行,不可读写)。
(2)为了终止null的执行,zpoline收集所有syscall/sysenter地址,并检查调用钩子函数的是替换syscall/sysenter的地址来的,还是由于null执行来的。如果是null执行来的就终止。地址可以由bitmap存储,虽然看似占据很大空间,但是物理内存消耗很小,因为所有位都清零的虚拟地址页不需要底层物理内存页。
0x03 约束(此方案的缺陷)
(1)此方案无法钩取libzpoline.so初始化之后出现的syscall/sysenter,可以通过借用X-Containers中提出的在线二进制重写的思想来解决这个问题(具体思想是啥俺也不懂,没看还)。
(2)内核可以通过vDSO(虚拟动态共享对象),使得用户态程序使用多种系统调用。zpoline无法钩取基于vDSO的系统,但是我们能禁用vDSO呀。
(3)如果虚拟地址0不可用的话,那么zpoline将无效。例如虚拟地址0已经被其他用途使用,或者内核不许映射到0。
(4)windows不可使用zpoline,这是因为最小可分配虚拟地址不得小于0x10000。但是windows提供了针对linux的兼容层,叫做Windows Subsustem for Linux(WSL)。zpoline是可以运行在WSL2中的。macos也不能使用zpoline,因为虚拟地址0被特殊的段__PAGEZERO所占据。
(5)某些CPU架构也不能使用zpoline,这些CPU架构特点为:指令长度固定,而且跳转地址必须为某值的倍数,例如arm就不能用zpoline。这是因为,跳转可能为虚拟地址0-500的任意值。
0x04 其他挂钩机制的原理
ptrace
这是UNIX系统的机制,跟踪器进程可以钩取被跟踪进程尝试运行的系统调用。由于ptrace是内核的特征,因此它可以实现详尽的钩子。但是由于跟踪器进程与被跟踪进程之间的上下文切换,它的钩子开销是巨大的。
int3 信号
int3可以导致软件中断,内核处理它并向执行 int3 的用户态进程发出SIGTRAP。使用int3代替syscall/sysenter,并将SIGTRAP的handler当作钩子函数。它的开销也是巨大的,因为它涉及内核的上下文操作。
Syscall User Dispatch(SUD)
最初目的是在linux上运行windows游戏时兼容性更高,可以直接使用系统调用调用ring3的函数。它提供了一种重定向到任意用户态代码的方式。内核在系统调用的入口实现了钩子,当SUD启用时,挂钩点向用户态进程发送SIGSYS信号,从而使用户态程序使用SIGSYS的handler当作系统调用的钩子(类似于int3)。由于handler处理需要时间,因此也会造成性能损失。
利用LD_PRELOAD的函数替换
ld.so提供的LD_PRELOAD特性使得在程序main函数执行前加载特定共享库,这样的话就可以选择性的重写共享库中的函数调用。此机制性能损失很小,因为钩子只需要函数指针重写后就可部署。
函数调用的钩子与系统调用钩子不同。此方法只能钩取函数,而对于没有包装函数(或者内部函数包装的)的syscall/sysenter则无法钩取(例如glibc),即无法实现详尽的钩子,即,不是将用户态OS子系统应用于现有用户态程序的适当选项;例如,如果系统调用未正确挂钩,则由用户态OS子系统打开的文件描述符将被传递到内核态OS子系统,并导致系统出现异常行为。
0x05 项目注释+链接
https://github.com/WD-2711/zpoline
Done!
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!