Frida逆向与协议分析 起因是第七期分享会,有师傅推荐这本书,正好自己在frida脚本上很欠缺,所以买来看看。重点是实操,和C++反汇编不一样,别懒!
0x00 安卓逆向环境搭建 htop:动态查看当前活跃的,占用高的进程。
jnettop:查看下载速度与对应的 IP。
解锁OEM时会出现waiting for any device的情况,解决办法 。刷机过程见P9。adb devices只有进入系统时才能看到,fastboot devices只有进入bootloader时才能看到。
Kali NetHunter刷机:针对移动设备的安卓渗透测试平台。它主要修改安卓内核的内容,这些修改对日常使用无影响。最后使用链接 下载SuperSU-2.82。对于用NetHunter刷完机无法被虚拟机发现的情况,看链接 。
0x01 Frida Hook基础与快速定位 基础 frida基础 两种操作模式:(1)CLI模式:通过命令行将js脚本注入到进程中。(2)RPC模式:通过py脚本间接完成js脚本的注入。本章重点关注CLI模式。
两种操作App的方式:(1)spawn(调用)模式:将启动App的权利交给Frida来控制,即使目标App已启动,在使用Frida对程序进行注入时,还是会重新启动App并注入。frida -f就会调用spawn模式。(2)attach(附加)模式:在目标App已启动的前提下,利用ptrace原理注入程序进而完成Hook操作,默认以attach模式注入。
注:ida attach调试程序时,无法以frida attach模式注入;但是当先进行frida attach模式注入后,可以使用ida attach调试(先后问题)。
对于在App启动时执行的方法(so库的.init_array、.init_proc),使用spawn方式hook。而对于频繁运行的函数,可以使用attach方式hook。
frida连接手机的两种模式:(1)usb数据线:使用adb链接,加入-U参数即可。(2)网络模式:adb链接,frida-server在运行时使用-l监听ip与端口,主机上的frida通过-H参数指定手机的ip和端口。
frida hook基础 xposed使用java代码编写hook模块后,需要重启后才能使hook代码运行起来 。而frida只需在手机上运行frida-server,然后在主机上将js脚本注入即可。frida注入成功后,即使脚本被修改,hook效果也能及时生效。
针对显示->主动显示的钩取如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 function hook ( Java .perform (function ( var settings = Java .use ("com.android.settings.DisplaySettings" ); var getMetricsCategory_func = settings.getMetricsCategory .overload (); getMetricsCategory_func.implementation = function ( var result = this .getMetricsCategory (); console .log ("getMetricsCategory called, result => " , result); return result; } }) } function main ( hook (); } setImmediate (main)
之后运行:frida -U com.android.settings -l hello.js。
注:
(1)所有针对java层函数的hook脚本必须处于Java.perform的包装中。
(2)Java.use获取指定类的handle后,使用类似于调用类静态方法的方式获得对应函数(上述代码中的settings.getMetricsCategory)。如果函数存在多个重载,还需要添加.overload(<signature>)获取指定函数。
如下所示,subString函数有两个重载:String substring(int)与String substring(int, int)。我们只想要钩取substring(int),如下所示:
1 2 3 4 5 6 7 8 9 10 11 function hookSubString ( Java .perform (function ( var String = Java .use ('java.lang.String' ) var subString_int_func = String .substring .overload ('int' ) subString_int_func.implementation = function (index ){ var result = this .substring (index) console .log ("substring called" ,'index =>' ,index,',result =>' ,result) return result } }) }
objection基础 frida提供了API供用户自定义使用,在此基础上可以实现很多具体功能。而objection则是将各种常用功能整合 并可在命令行使用的利器。在安卓中使用objection,可以快速完成内存、类与模块搜索、方法hook、打印参数等。
以movetv.apk为例,通过jadx查看AndroidManifest.xml,获取到包名为com.cz.babySister。安装到手机上,并启动frida-server,之后运行:
1 objection -g com.cz.babySister explore
之后,就可以对进程进行操作:
(1)打印内存:可打印出内存中已加载类的相关信息,从而快速定位app中的关键类。
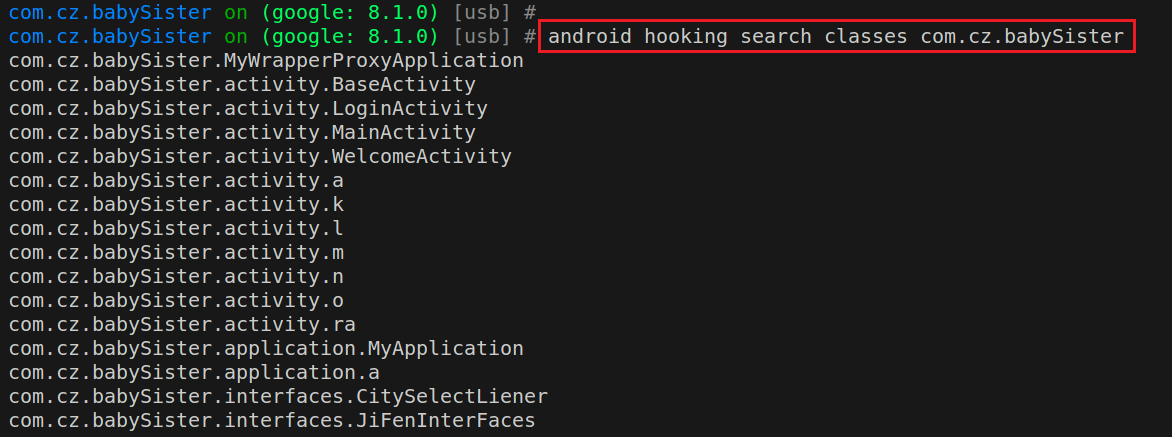
1 android hooking list classes // 列出进程加载过的类
1 android hooking search classes <pattern> // 列出加载的类名中包含<pattern>格式的类
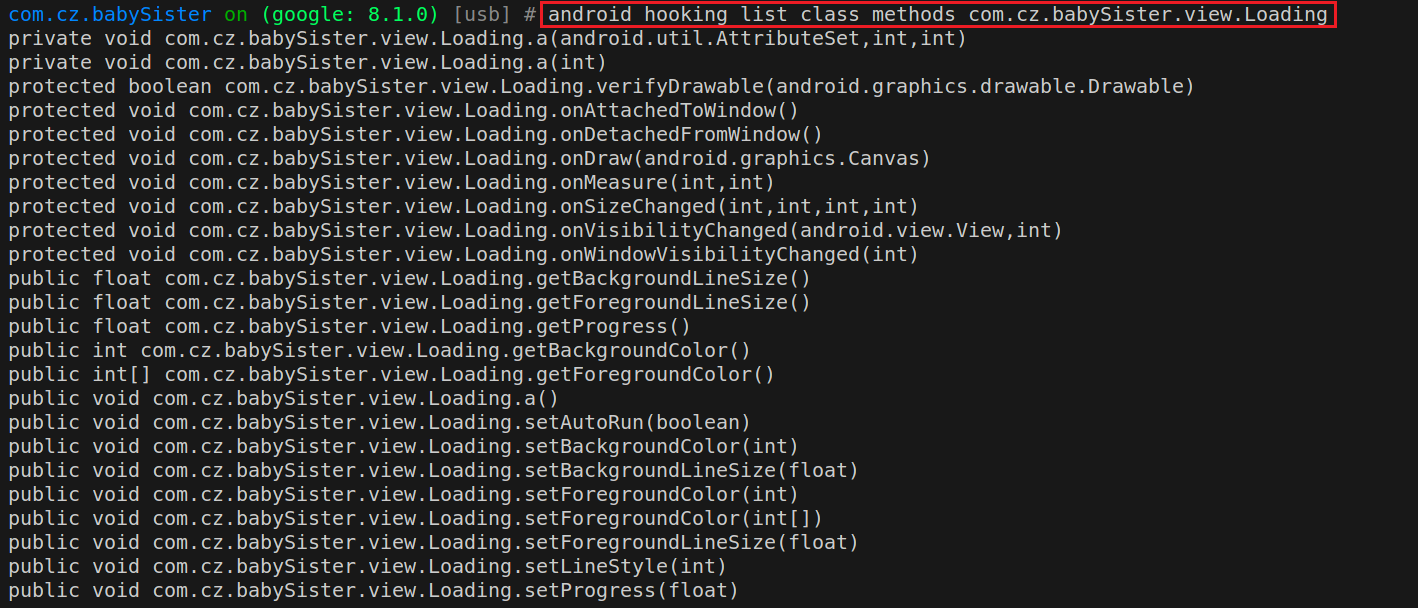
1 android hooking list class_methods <class_name> // 获取指定类中所有非构造函数的方法名
(2)Hook函数:
objection可以hook一个类中所有函数。
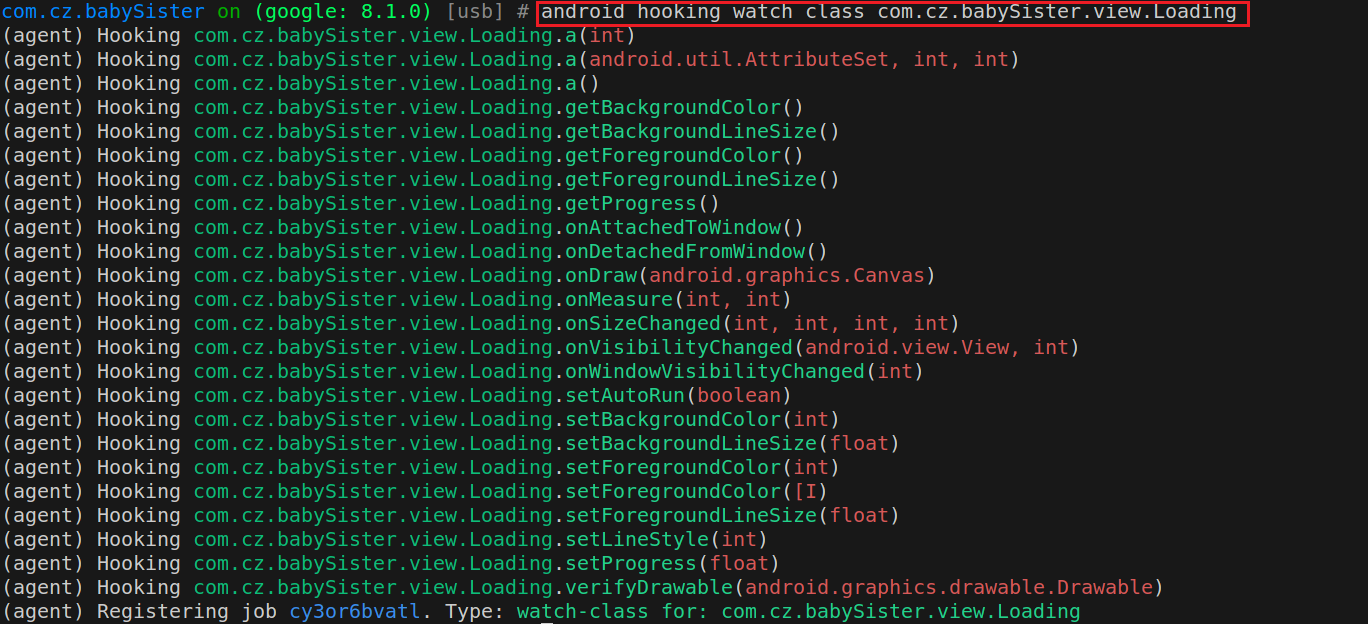
1 android hooking watch class <class_name> // 钩取某个类中所有非构造函数
1 2 3 4 5 // hook 指定函数 // classMethod 为方法名 // option 支持的参数有:--dump-args(函数执行时打印参数内容),--dump-return(打印返回值),--dump-backtrace(打印调用栈) // overload 表示具体是哪个函数(函数可能有重载),如果没指定那么默认为所有重载的函数 android hooking watch class_method <classMethod> <overload> <option>
下图就默认hook了所有setForegroundColor重载函数:
如果要指定钩取参数为int数组的setForegroundColor函数,那么就写为:
1 android hooking watch class_method com.cz.babySister.view.Loading.setForegroundColor "[I" --dump-args --dump-return --dump-backtrace
(3)jobs:hook任务管理,android heap:用于操作内存中类的实例。这些略。
Hook快速定位 逆向分析时遵循hook->主动调用->RPC,这是什么?即,协议分析的流程为:(1)用hook的方式确定关键业务逻辑的位置;(2)通过主动调用实现关键业务逻辑的调用;(3)通过RPC远程过程调用(python+js)的方式进行关键业务逻辑的批量调用。frida将hook工作成功地从xposed模块每次编译都需要重启的循环中解放出来 。
关键类定位:基于trace的枚举 DDMS(Dalvik Debug Monitor Server)是早期android studio中用于调试和监视 Android 设备和模拟器的工具。其中method trace功能可以获得一段时间内app执行的函数记录,但是,它有以下缺点:(1)要求app的debuggable为true。(2)会记录所有函数,包括系统函数。
而frida无需处于debuggable状态,且支持跟踪指定类中的函数,支持跟踪特定类中的所有函数。在此节中,不直接编写frida脚本来进行trace,而是使用frida封装的可用于进行trace定位的工具。
objection trace 以movetv.apk为例,首先搜索包含com.cz.babySister的类:
1 android hooking search classes com.cz.babySister
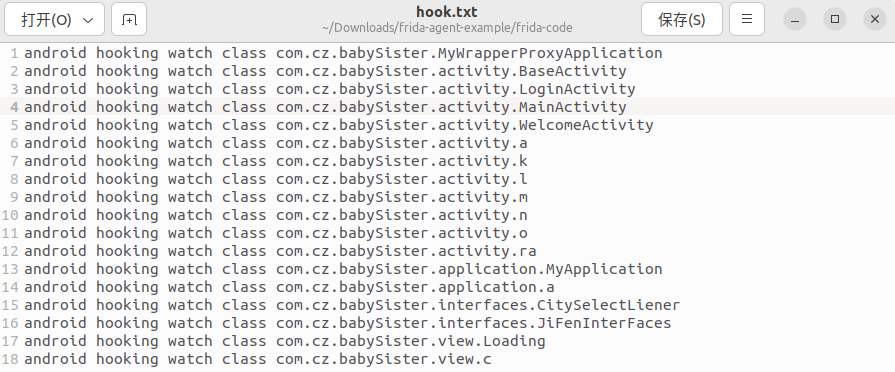
将输出保存为文件hook,并在每一行开头加入android hooking watch class,表示钩取所有与com.cz.babySister.xxx类相关的函数,如下所示:
通过如下命令,使用objection对所有com.cz.babySister.xxx类相关的函数进行钩取:
1 objection -g com.cz.babySister explore -c hook.txt
此时再触发我们所关心的业务逻辑,就能快速筛选出业务逻辑所在类的范围。
注1:search classes是先获取所有已加载类,之后再筛选。因此,它可能无法涵盖应用中所有的类。因此,在hook之
前,要尽可能多的使用app,以求加载足够多的类。 objection中trace的核心源码见P37。
注2:如果app加壳,那么最好选择attach模式进行trace/hook。否则在应用还未启动时,真实的类还没有被释放。此时会报ClassNotFoundException错误,这是因为app的ClassLoader在运行时的切换问题所导致的。
ZenTracer 具体见P39。
总结一下,frida相比于DDMS,能够依据使用者的想法对执行函数进行跟踪,同时无需样本处于debuggable状态。但是,由于frida本身不太稳定,因此被测试的程序会经常崩溃。
关键类定位:基于内存的枚举 当逆向者通过分析发现某些类可能是关键类时,可以通过对此关键类进行hook去验证分析的结果。相比于xposed,frida不仅不用重启,还支持对内存进程的漫游功能,即:能够通过Java.choose()在目标进程的java堆中寻找和修改已存在的java对象实例 。这使得我们不仅能够对未执行的函数设置hook,还能对已经创建的实例进行操作 。
以OkHttp中的hook抓包进行介绍。OkHttp的核心是拦截器。一个完整的网络请求被拆分为多个步骤,每个步骤都由拦截器完成。拦截器由okhttp3.OkHttpClient类中的List成员_interceptors数组管理,此数组包含Client中的所有拦截器。那么,如果写一个打印日志的LogInterceptor拦截器,并添加到_interceptors数组中,就可以完成对所有数据包的抓取。
如何做?通过Java.choose从内存中找到okhttp3.OkHttpClient的实例对象,并修改_interceptors数组内容,使得此数据包含我们刚才写的LogInterceptor拦截器,从而完成数据的抓包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 function searchClient ( Java .perform (function ( var gson2 = Java .use ("com.google.gson.Gson" ); Java .openClassFile ("/data/local/tmp/muok2curl.dex" ).load (); console .log ("loading dex successful" ); const curlInterceptor = Java .use ("com.moczul.ok2curl.CurlInterceptor" ); const loggable = Java .use ("com.moczul.ok2curl.logger.Loggable" ); var Log = Java .use ("android.util.Log" ); var TAG = "okhttpGETcurl" ; var MyLogClass = Java .registerClass ({ name : "okhttp3.MyLogClass" , implements : [loggable], methods : { log : function (MyMessage ){ Log .v (TAG , MyMessage ); } } }) const mylog = MyLogClass .$new(); var curlInter = curlInterceptor.$new(mylog); Java .openClassFile ("/data/local/tmp/okhttplogging.dex" ).load (); var MyInterceptor = Java .use ("com.r0ysue.learnokhttp.okhttp3Logging" ); var MyInterceptorObj = MyInterceptor .$new(); Java .choose ("okhttp3.OkHttpClient" , { onMatch :function (instance ){ console .log ("1. find instance" , instance) console .log ("2. instance.interceptors():" , instance.interceptors ().$className ); console .log ("3. instance._interceptors:" , instance._interceptors ().value .$className ); console .log ("5. interceptors:" , Java .use ("java.util.Arrays" ).toString (instance.interceptors ().toArray ())); var newInter = Java .use ("java.util.ArrayList" ).$new(); newInter.addAll (instance.interceptors ()); console .log ("6. interceptors:" , Java .use ("java.util.Arrays" ).toString (newInter.toArray ())); console .log ("7. interceptors:" , newInter.$className ); newInter.add (MyInterceptorObj ); newInter.add (curlInter); instance._interceptors .value = newInter; }, onComplete :function ( console .log ("Search complete" ); } }) }) } setImmediate (searchClient)
上述代码中,myok2curl.dex负责具体拦截器的实现,okhttplogging.dex负责具体拦截器的实现。这样做的目的是为了避免将Java翻译成js的复杂工作。Java.openClassFile("xx").load()用于导入dex文件,在内存中注册一个类,当然也可以使用Java.registerClass完成。
注:objection的插件WallBreaker,可以快速定位类中所包含的属性与函数,也可以直接通过对象的句柄获取所在类中所有属性的值。其基本原理就是使用Java.choose对内存中对象进行搜索,然后通过对对象的句柄进行反射,从而获得相应成员与函数。
frida也可以在native层进行hook。以脱壳为例,hexdump工具的核心原理是在目标进程的内存空间中遍历搜索包含DEX文件特征的数据,匹配成功则将dex dump出来,它主要使用了frida的Memory.scanSync函数。hexdump仅仅能够解决一代整体加固,对于二代抽取加固,有工具frida_fart。其通过hook app运行过程中的native函数,即LoadMethod函数(此函数处于加载与执行dex文件的ART虚拟机 中),利用此函数的参数,可以获得加载的java函数所在的dex文件与函数代码。
0x02 Frida脚本开发之主动调用与RPC入门 之前的内容讲了如何定位到算法的关键函数,之后我们就需要反复调用此函数,以进行调试,了解此函数真正的程序逻辑。但是如果按部就班的进行调用,函数传入的参数往往是变化的。 因此,就需要主动调用 ,即:目标函数的参数是可控的。远程过程调用(RPC)(就是python脚本的frida)也是与主动调用一起使用的一种技术。
之前说过Frida调试的3板斧:(1)Hook定位关键逻辑;(2)主动调用构造参数进行利用;(3)RPC导出结果进行规模化利用。 Frida实际上是基于Python和JS的进程级Hook框架,其中JS承担Hook函数的工作,Python相当于提供给外界的绑定接口,使用者可通过Python将JS脚本注入到进程中。其中,官方提供了frida-python来进行远程过程调用。
python实现frida注入的基本知识 获取设备 1 2 3 4 5 6 7 8 import fridadevice = frida.get_usb_device() print (device)device = frida.get_device_manager().add_remote_device('192.168.75.1:6666' ) print (device)
获取到设备后,实现进程注入同样有spawn(重新启动app)与attach(附到已启动的app)。如下所示:
注入进程-两种方式 1 2 3 4 5 6 7 8 9 10 11 12 import timeimport fridapid = device.spawn(["com.android.settings" ]) device.resume(pid) time.sleep(1 ) session = device.attach(pid) session = device.attach("com.android.settings" )
成功注入进程后,之后要进行hook脚本的注入,实际上就是将js脚本作为字节流通过frida提供的api加载到相应进程的session中。
hook脚本注入 方式1:js字符串
1 2 3 4 5 6 7 8 9 10 script = session.create_script(""" setImmediate(Java.perform(function(){ console.log("hello python frida"); })) """ )script.load()
方式2:js文件
1 2 3 with open ("hook.js" ) as f: script = session.create_script(f.read()) script.load()
rpc学习 学习rpc实际上是学习js脚本与python进行交互的方式。 rpc脚本示例如下,功能主要是打开settings,并调用两个函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from __future__ import print_functionfrom frida.core import Sessionimport fridaimport time device = frida.get_usb_device() pid = device.spawn(["com.android.settings" ]) device.resume(pid) time.sleep(1 ) session = device.attach(pid) script = session.create_script(""" rpc.exports = { hello: function(){ return 'Hello'; }, failPlease: function(){ return 'oops'; } }; """ )script.load() api = script.exports print ("api.hello() => " , api.hello())print ("api.fail_please() => " , api.fail_please())
调用结果如下:
注意js脚本中带大写字母的导出函数变成了小写加下划线的形式,例如failPlease变为fail_please。可以这么说,rpc介绍了在python中主动调用js中函数的方式 。下面再来介绍js主动向python发送数据的方式 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from __future__ import print_functionimport sysimport fridaimport timedef on_detached (): print ("on_detached" ) def on_detached_with_reason (reason ): print ("on_detached_with_reason:" , reason) def on_detached_with_varargs (*args ): print ("on_detached_with_varargs:" , args) device = frida.get_usb_device() pid = device.spawn(["com.android.settings" ]) device.resume(pid) time.sleep(1 ) session = device.attach(pid) print ("attached" )session.on('detached' , on_detached) session.on('detached' , on_detached_with_reason) session.on('detached' , on_detached_with_varargs) sys.stdin.read()
上述两个脚本是frida-python给出的两个简单的例子,js还可以用过send函数向python脚本发送数据。frida-python还包括:(1)child_gating.py:子进程注入;(2)bytecode.py:将脚本编译为字节码然后再加载脚本;(3)inject_library文件夹:手动向进程中注入一个动态库。等等。
这对于之前的ZenTracer项目,其真实用于Hook的代码只有traceClass函数,剩下的部分都是js与python之间的数据传递,主要是:通过send将js中的数据传输到python用于接收数据的FridaReceive函数中。
注:frida中session.on、script.on、device.on的区别?
session.on:这个方法用于在Frida会话(Session)对象上注册事件处理程序。Frida会话是与目标应用程序通信的主要接口。通过session.on方法,可以注册多种类型的事件处理程序,如detached(会话与目标应用程序断开连接时触发)和message(接收到来自目标应用程序的消息时触发)等。script.on:这个方法用于在Frida脚本(Script)对象上注册事件处理程序。Frida脚本是在目标应用程序中执行的用户定义代码。通过script.on方法,可以注册多种类型的事件处理程序,如message(接收到来自目标应用程序的消息时触发)和destroyed(脚本被销毁时触发)等。device.on:这个方法用于在Frida设备(Device)对象上注册事件处理程序。Frida设备是与目标设备或模拟器通信的接口。通过device.on方法,可以注册多种类型的事件处理程序,如spawned(目标应用程序被启动时触发)和output(设备的输出消息时触发)等。
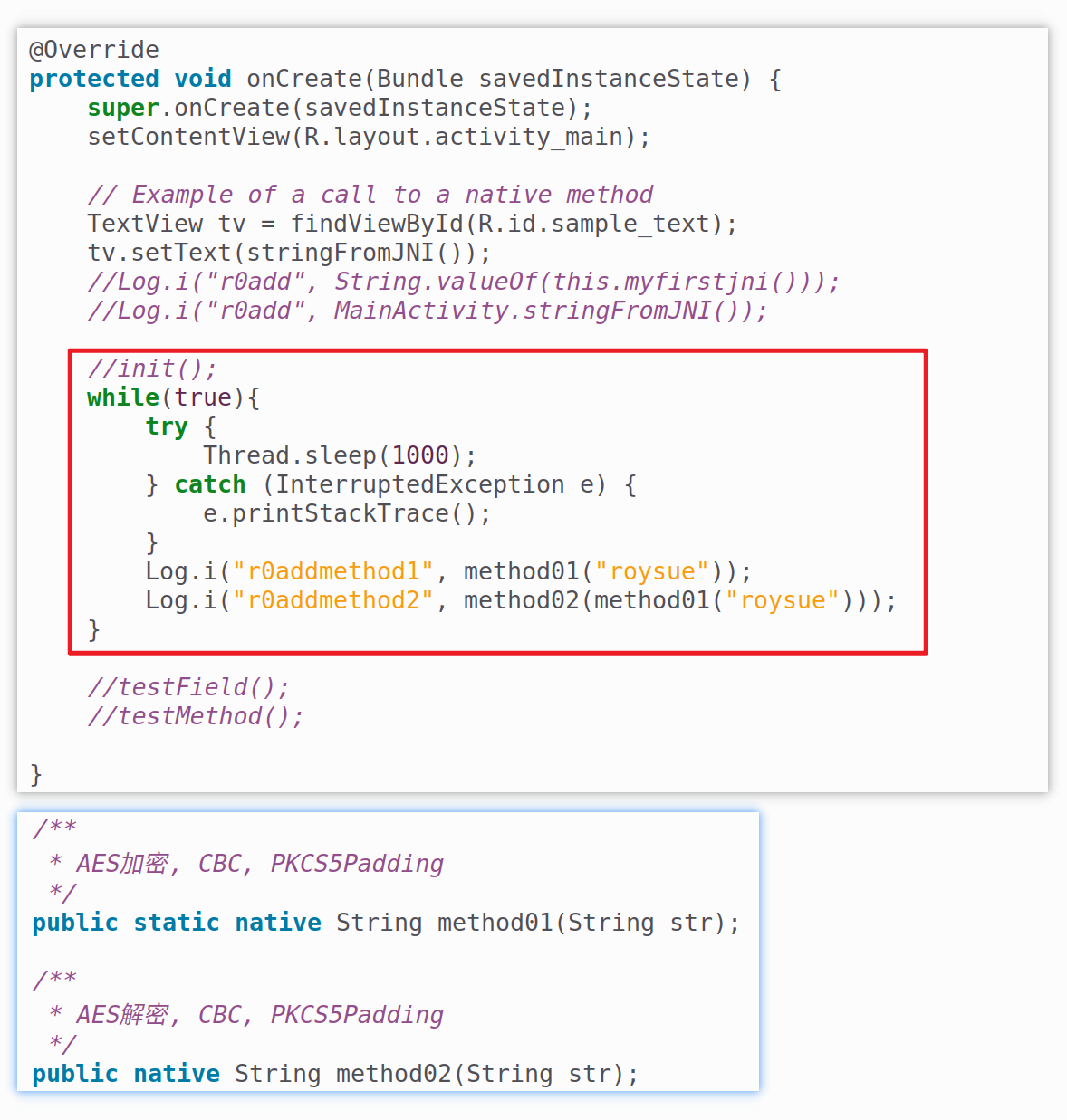
frida java层主动调用与rpc 以demoso1工程为例,此工程中存在两个native函数,在应用打开后被循环调用。其中method01是静态函数,对输入进行加密并返回,method02是成员函数,对密文解密并返回。其java层声明如下:
注:如果native函数是静态注册的,那么so层最终生成的函数是以Java_开头的导出函数。然而此静态注册方式不安全,因此用RegisterNatives()函数对上述两个函数进行了动态注册,以加强安全性。注册过程如下:
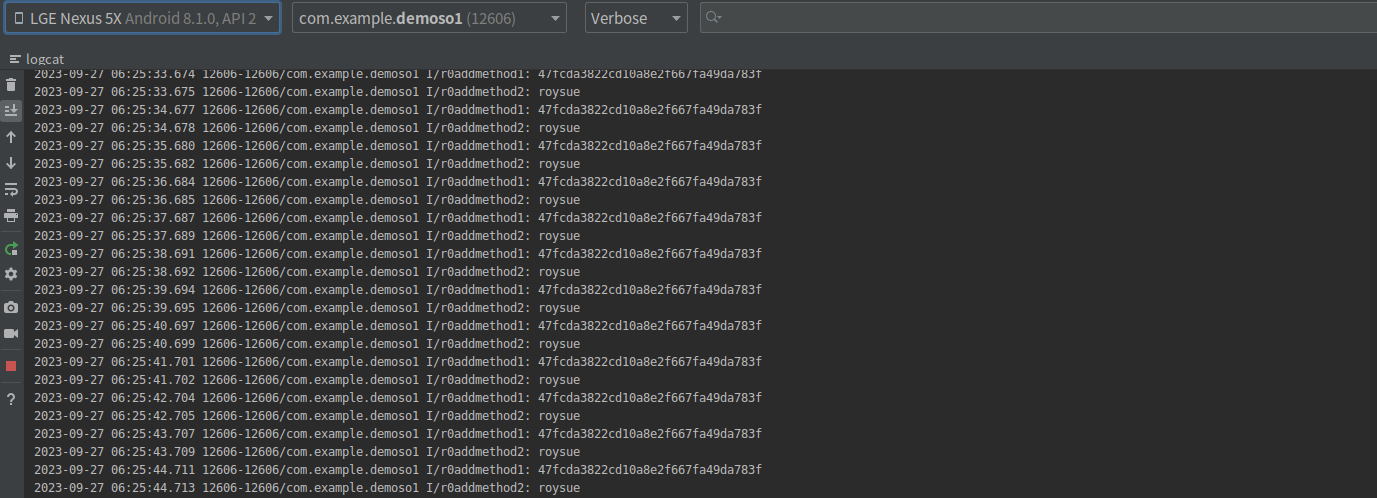
运行日志如下:
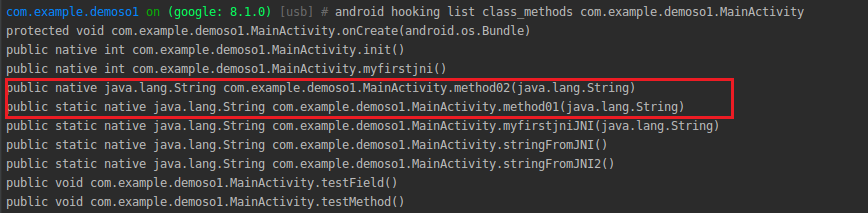
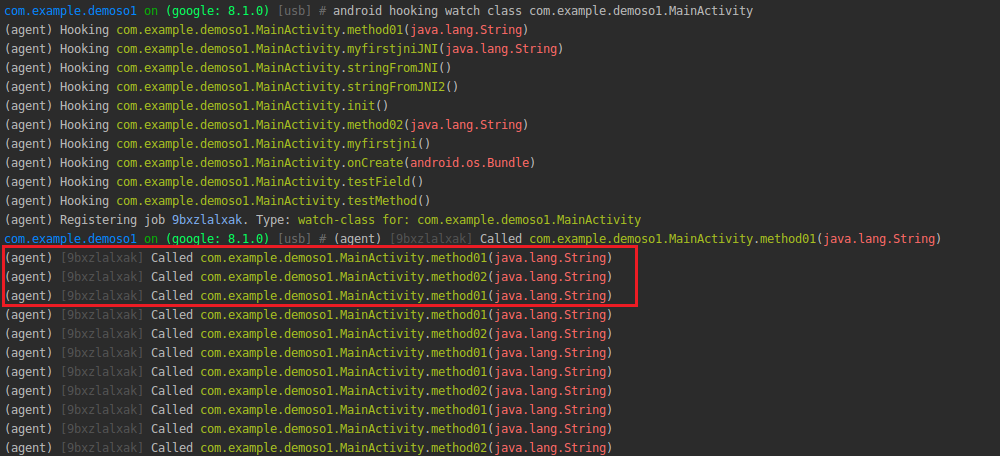
首先使用上一章介绍的objection工具来注入目标进程,以确定method01与method02的签名与调用情况。
1 2 3 4 5 6 // 使用 objection 注入到进程 objection -g com.example.demoso1 explore // 获取 com.example.demoso1.MainActivity 中所有非构造函数的方法名 android hooking list class_methods com.example.demoso1.MainActivity // 钩取 com.example.demoso1.MainActivity 中所有非构造函数 android hooking watch class com.example.demoso1.MainActivity
函数签名如下:
调用情况如下:
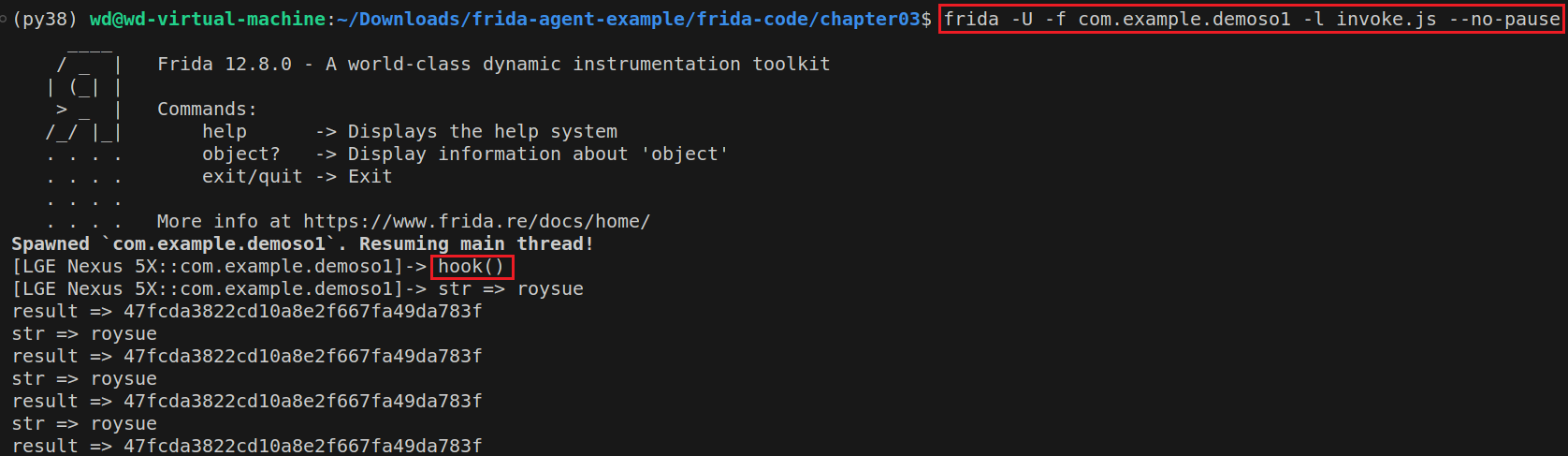
可以看出,此程序主动调用了method01。之后,我们就要写hook脚本,从而对此函数进行主动调用。主动调用最重要的是参数的构造,主动调用其实就是构造和hook时使用的参数类型一致的参数。首先,编写invoke.js如下:
1 2 3 4 5 6 7 8 9 10 11 12 function hook ( Java .perform (function ( var MainActivity = Java .use ("com.example.demoso1.MainActivity" ); MainActivity .method01 .implementation = function (str ){ var result = this .method01 (str); console .log ("str =>" , str); console .log ("result =>" , result); return result; } }) }
当注入并调用Hook函数时,结果如下所示:
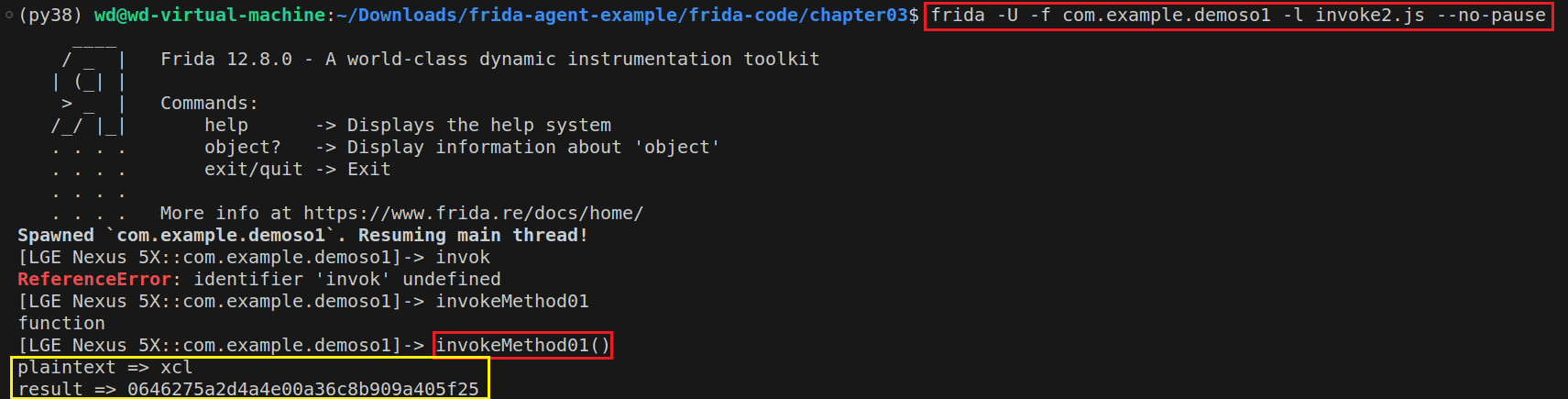
重写一下invoke.js,目的是调用method01函数,并对xcl进行加密:
1 2 3 4 5 6 7 8 9 10 function invokeMethod01 ( Java .perform (function ( var MainActivity = Java .use ("com.example.demoso1.MainActivity" ); var javaString = Java .use ("java.lang.String" ); var plaintext = "xcl" ; var result = MainActivity .method01 (javaString.$new(plaintext)); console .log ("plaintext =>" , plaintext); console .log ("result =>" , result); }) }
结果如下所示:
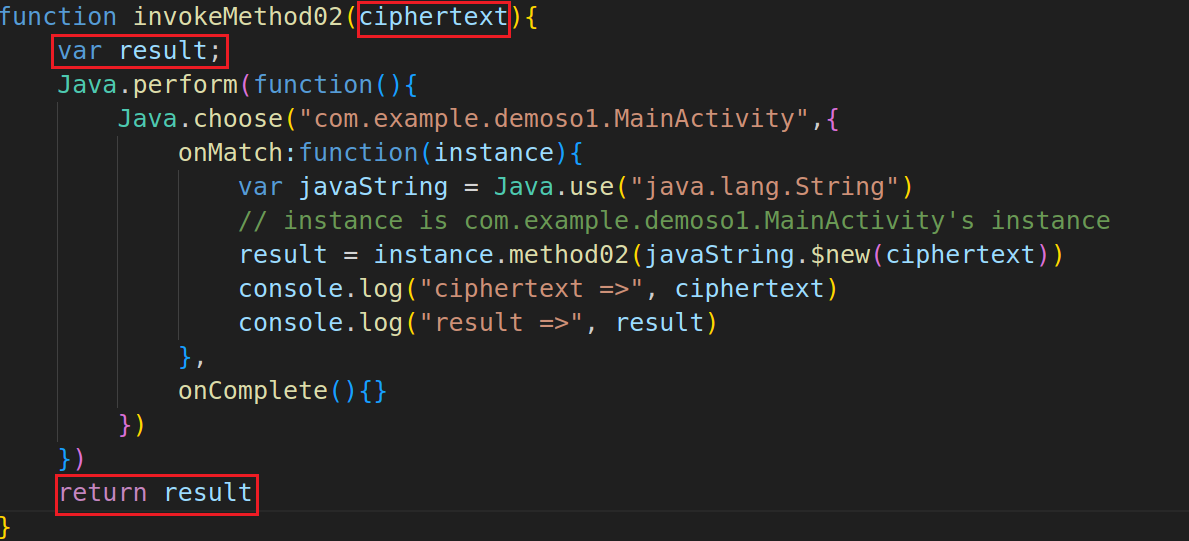
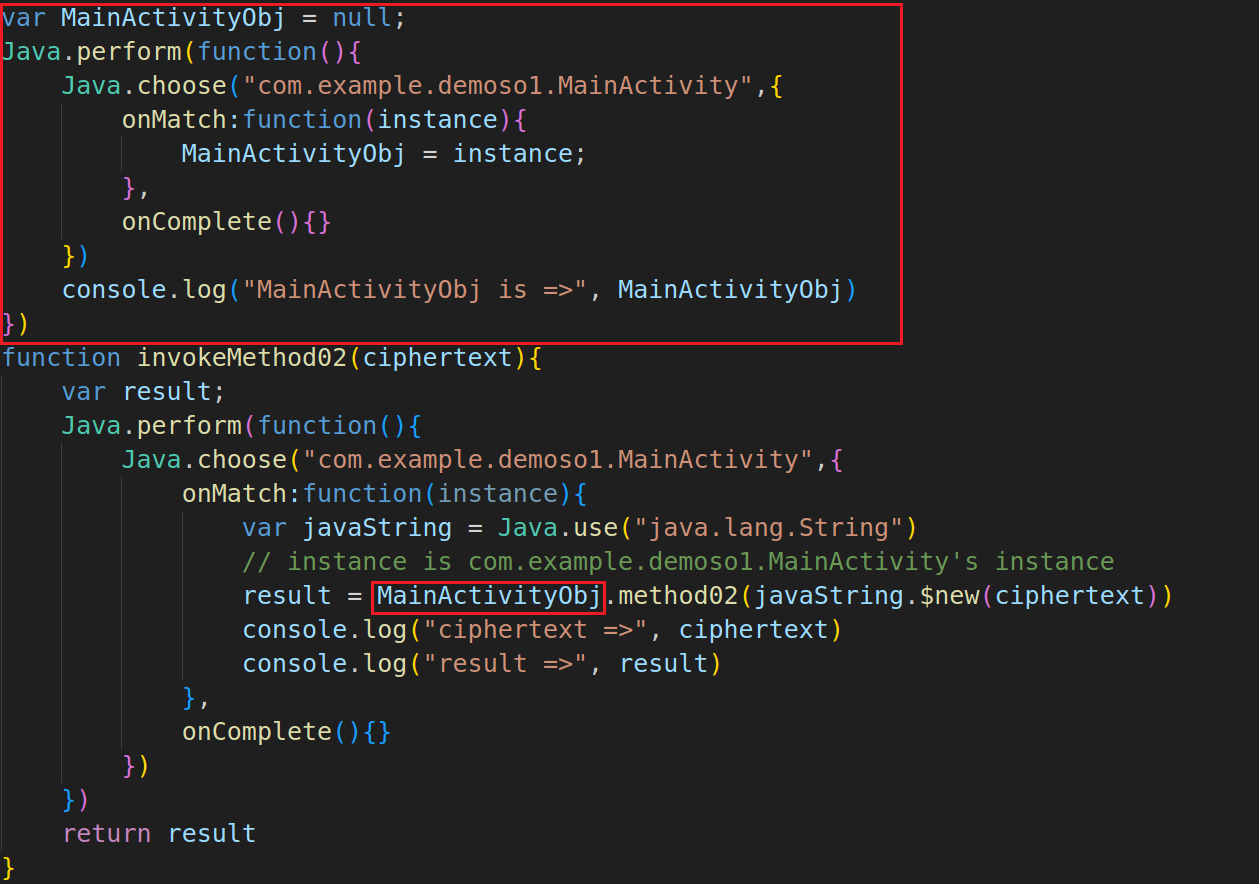
刚才的method01是静态函数,这类函数的主动调用只需要获得对应类的句柄。而对于一般的函数method02来说,这样调用就会出错,因为此函数需要通过实例进行调用,而不是一个类句柄。而之前学过,Java.choose()能够在内存中获取实例,因此对method02的主动调用脚本如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function invokeMethod02 ( Java .perform (function ( Java .choose ("com.example.demoso1.MainActivity" ,{ onMatch :function (instance ){ var javaString = Java .use ("java.lang.String" ) var ciphertext = "0646275a2d4a4e00a36c8b909a405f25" var result = instance.method02 (javaString.$new(ciphertext)) console .log ("ciphertext =>" , ciphertext) console .log ("result =>" , result) }, onComplete ( }) }) }
结果如下所示:
测试好主动调用后,下一步就是rpc(python脚本调用js中的函数)。此时需要将主动调用提供为外部接口,需要两步:
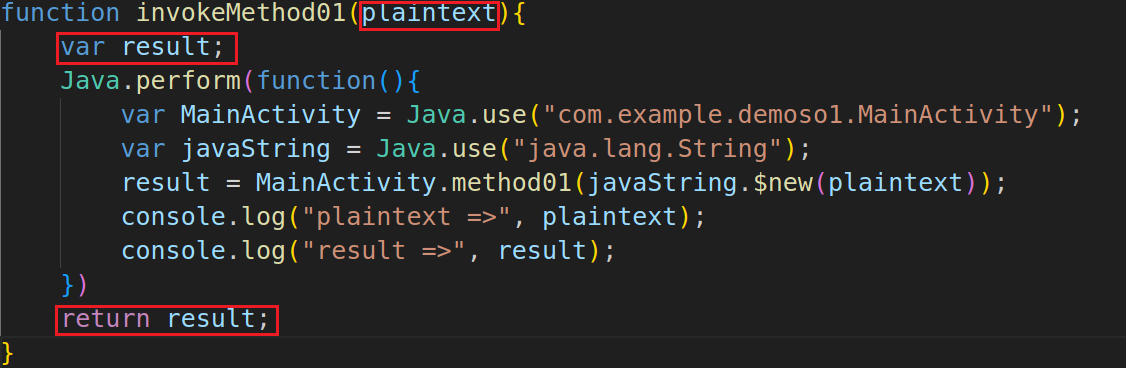
(1)将主动调用参数配置为js函数的参数并将主动调用的结果返回,以方便外部自定义参数进行主动调用,更改后的代码如下所示:
(2)将这两个主动调用的函数导出,最终export.js如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 rpc.exports = { method01 :invokeMethod01, method02 :invokeMethod02 } function invokeMethod01 (plaintext ){ var result; Java .perform (function ( var MainActivity = Java .use ("com.example.demoso1.MainActivity" ); var javaString = Java .use ("java.lang.String" ); result = MainActivity .method01 (javaString.$new(plaintext)); console .log ("plaintext =>" , plaintext); console .log ("result =>" , result); }) return result; } function invokeMethod02 (ciphertext ){ var result; Java .perform (function ( Java .choose ("com.example.demoso1.MainActivity" ,{ onMatch :function (instance ){ var javaString = Java .use ("java.lang.String" ) result = instance.method02 (javaString.$new(ciphertext)) console .log ("ciphertext =>" , ciphertext) console .log ("result =>" , result) }, onComplete ( }) }) return result }
到此,rpc中js部分完成,此时再写一个Python外部调用的脚本invoke.py,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import timeimport fridaimport jsondef my_message_handler (message, payload ): print (message) print (payload) device = frida.get_usb_device() pid = device.spawn(["com.example.demoso1" ]) device.resume(pid) time.sleep(1 ) session = device.attach(pid) with open ("export.js" ) as f: script = session.create_script(f.read()) script.on("message" , my_message_handler) script.load() api = script.exports ciphertext = api.method01("xcl" ) print ("method01 => encode_result: " + ciphertext)print ("method02 => decode_result: " + api.method02(ciphertext))
运行结果如下所示:
再丰富一下上述代码,使其能够通过浏览器访问批量调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from flask import Flask, requestimport jsonapp = Flask(__name__) import timeimport fridaimport jsondef my_message_handler (message, payload ): print (message) print (payload) device = frida.get_usb_device() pid = device.spawn(["com.example.demoso1" ]) device.resume(pid) time.sleep(1 ) session = device.attach(pid) with open ("export.js" ) as f: script = session.create_script(f.read()) script.on("message" , my_message_handler) script.load() @app.route('/encrypt' , methods=['POST' ] def encrypt_class (): data = request.get_data() json_data = json.loads(data.decode('utf-8' )) postdata = json_data.get("data" ) res = script.exports.method01(postdata) return res @app.route('/decrypt' , methods=['POST' ] def decrypt_class (): data = request.get_data() json_data = json.loads(data.decode('utf-8' )) postdata = json_data.get("data" ) res = script.exports.method02(postdata) return res if __name__ == "__main__" : app.run()
启动之后,运行:
1 curl -X POST http://127.0.0.1:5000/encrypt -H "{Content-Type:application/json}" -d '{"data":"xcl"}'
注:-X指定http请求的方法,-H指定http请求的头部,-d指数据体。
运行结果如下:
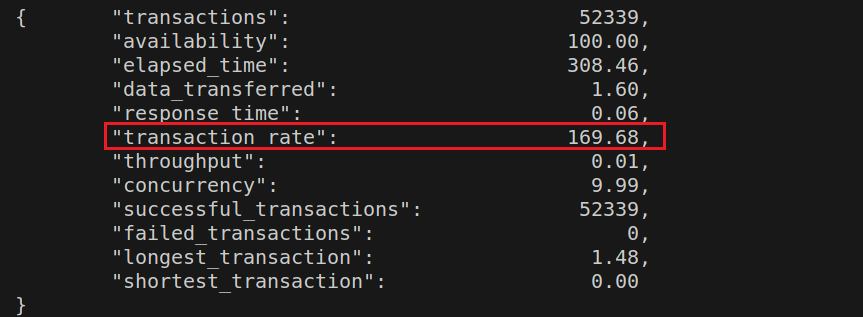
如果进一步想要将rpc变成批量化集群调用,则可以部署到服务器上。但是需要考虑手机性能、frida版本的稳定性、网络状况等。使用siege压力测试工具进行测试:
1 siege -c10 r100 "http://127.0.0.1:5000/encrypt POST < encrypt.json"
1 2 // encrypt.json {"data":"xcl"}
注:-c10代表并发数为10,-r100代表重复次数为100。结果如下所示:
这个速率还可以。对于method02而言,由于其中有Java.choose(),且此操作非常耗时,因此会降低method02调用的速度。为什么此操作耗时?因为每次调用Java.choose都会在内存中重新搜索实例。
我们改进如下:将对象始终保存在程序的外部全局变量中,这样每次调用method02的时候不至于重新寻找。
但是这利用了app的特殊性,即app不会退出(一直循环调用method01与method02 ),且调用的函数处于MainActivity中,即只要app不退出,MainActivity就会一直存在于内存中。那么,如果在其他app中,对象被系统进行垃圾回收了怎么办?这就需要下一节知识:Native层的主动调用。
frida native层函数的主动调用 虽然method01与method02分别是static与成员函数,但是他们都是native层的。这样的话,我们可以直接在native层进行主动调用,而无需考虑对象是否被回收的问题。Ok,那我们要完成native层的主动调用。继续三板斧。
(1)找到java函数在native层对应的函数符号,并以此找到函数地址。此时分为两种情况:
(a)静态注册的jni函数,其函数符号为Java_<类名>_<函数名>,例如stringFromJNI,此时hook脚本为:
1 2 3 4 5 6 7 8 9 10 11 function hookmethod ( var method01 = Module .findExportByName ('libnative-lib.so' , 'Java_com_example_demoso1_MainActivity_stringFromJNI' ) Interceptor .attach (method01, { onEnter :function (args ){ }, onLeave :function (retval ){ } }) }
如果不确定函数的符号,可以通过Objection来查看导出的函数列表:
1 objection -g com.example.demoso1 explore
列出libnative-lib.so模块中的导出函数。
1 2 // 列出so模块中的导出函数 memory list exports libnative-lib.so
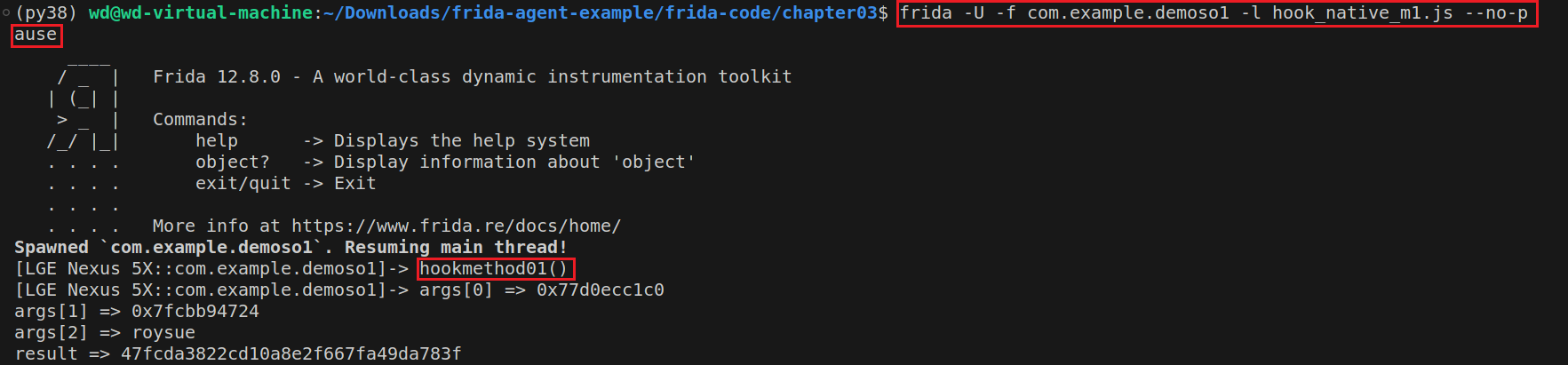
(b)使用RegisterNatives来进行动态注册的函数,例如method01与method02,可以使用frida_hook_libart项目中的hook_RegisterNatives.js脚本获取动态注册后函数所在的地址(注意由于实验版本的frida版本低,所以将脚本中的let改为var)。
1 frida -U -f com.example.demoso1 -l hook_RegisterNatives.js --no-pause
可以发现method01的名称改为:_Z8method01P7_JNIEnvP7_jclassP8_jstring。
(2)写Hook脚本,并改写为主动调用。可以写hook脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function hook_native_method (method_name ){ var m = Module .findExportByName ('libnative-lib.so' , method_name) Interceptor .attach (m, { onEnter :function (args ){ console .log ("args[0] =>" , args[0 ]) console .log ("args[1] =>" , args[1 ]) console .log ("args[2] =>" , Java .vm .getEnv ().getStringUtfChars (args[2 ], null ).readCString ()) }, onLeave :function (retval ){ console .log ("result =>" , Java .vm .getEnv ().getStringUtfChars (retval, null ).readCString ()) } }) } function hookmethod01 ( hook_native_method ("_Z8method01P7_JNIEnvP7_jclassP8_jstring" ); }
结果如下:
实际上,书中使用frida_hook_libart项目时只给出了method01在libnative-lib.so中的偏移量offset,此时脚本改为:
1 2 3 4 5 6 7 8 9 10 function hook_native_method (addr ){ Interceptor .attach (addr, { ... }) } function hookmethod01 ( var base = Module .findBaseAddress ('libnative-lib.so' ); var method01_addr = base.add (offset) hook_native_method (method01_addr); }
注:为什么要用Java.vm.getEnv().getStringUtfChars?这是因为Java中的string参数到native层变成了Jstring对象 。
上述脚本并没有涉及函数的主动调用,因为在脚本中并没有主动调用原来的函数。如果主动调用函数的话,应该是这样:
因此,将上述脚本修改如下,这样程序调用method01时,就会执行替换后的逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function hook_native_method (method_name ){ var m = Module .findExportByName ('libnative-lib.so' , method_name) var addr_func = new NativeFunction (m, 'pointer' , ['pointer' , 'pointer' , 'pointer' ]) Interceptor .replace (m, new NativeCallback (function (arg1, arg2, arg3 ){ var result = addr_func (arg1, arg2, arg3) console .log ("arg3 =>" , Java .vm .getEnv ().getStringUtfChars (arg3, null ).readCString ()) console .log ("result =>" , Java .vm .getEnv ().getStringUtfChars (result, null ).readCString ()) return result }, 'pointer' , ['pointer' , 'pointer' , 'pointer' ] )) } function hookmethod01 ( hook_native_method ("_Z8method01P7_JNIEnvP7_jclassP8_jstring" ); }
可改写为针对method01的主动调用,这样就可以主动调用native层的method01(最终形态):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 function hook_native_method (method_name, data ){ var result = null var m = Module .findExportByName ('libnative-lib.so' , method_name) var addr_func = new NativeFunction (m, 'pointer' , ['pointer' , 'pointer' , 'pointer' ]) Java .perform (function ( var env = Java .vm .getEnv () console .log ("data =>" , data) var jstring = env.newStringUtf (data) result = addr_func (env, ptr (1 ), jstring) result = env.getStringUtfChars (result, null ) }) return result } function hookmethod01 ( var result = hook_native_method ("_Z8method01P7_JNIEnvP7_jclassP8_jstring" , "xcl" ) console .log ('result =>' , result) }
注:(1)JNI函数(native层的函数),第一个参数一定是JNIEnv的指针;第二个参数为jclass或jobject,分别表示jni函数在Java层中是静态还是动态函数。由于method01中没有使用第二个参数,因此可以任意传递相同类型的数据,这里使用ptr(1)构造了一个指针。(2)由于函数主动调用时使用了Java.vm.getEnv这个API,因此需要包裹在java.perform()中。
执行结果如下:
(3)对native函数进行导出,并配置rpc,前面说过,因此不再赘述。
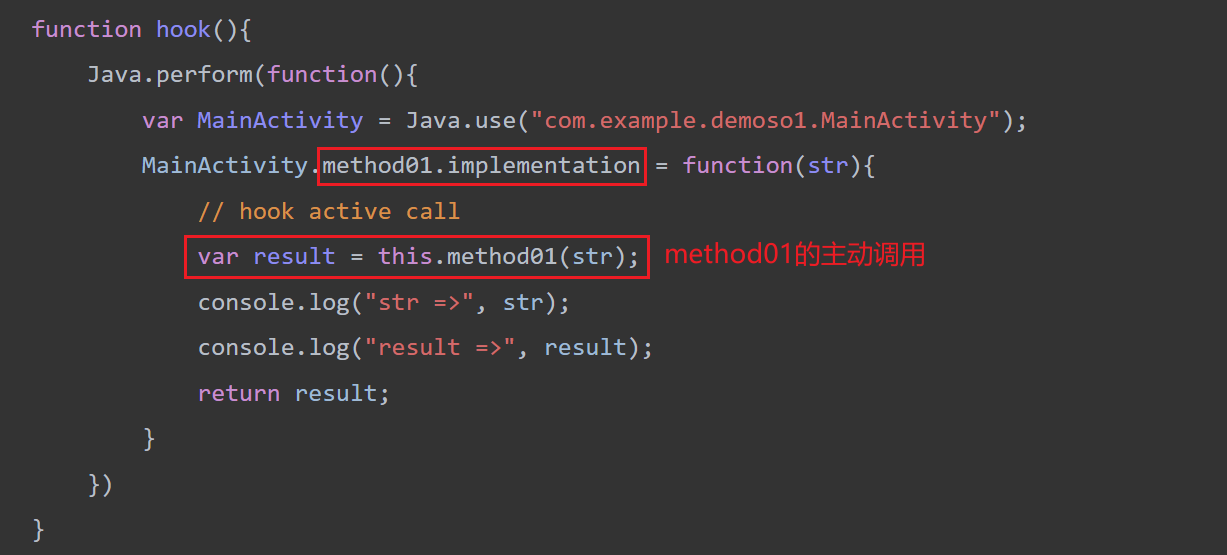
native函数调用的另类之法 以method01为例,此法脱离特定apk加载模块并调用native的固有模式。
(1)将apk解压,并将method01所在模块libnative-lib.so导出到/data/app目录下(必须要放到这个目录下 ),并赋予权限。
(2)编写主动调用脚本,如下所示:
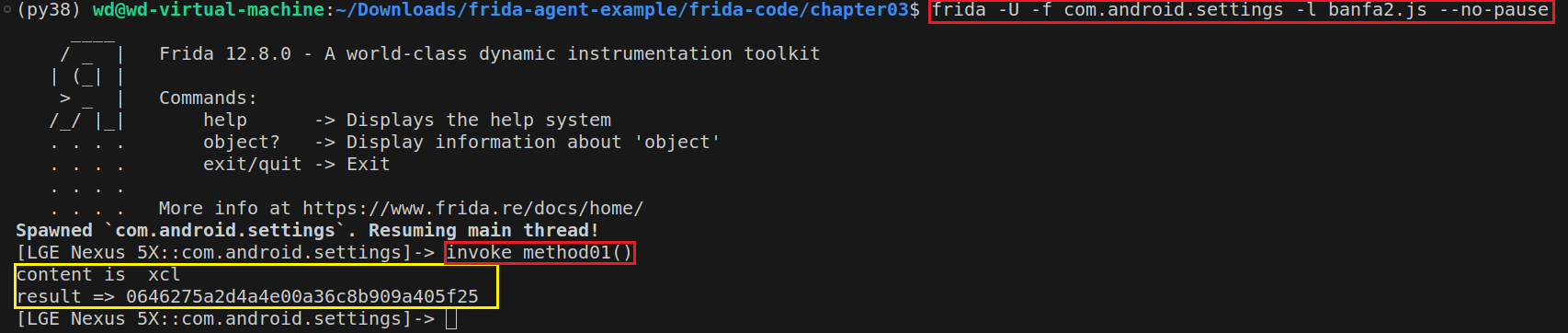
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function invoke_func (addr,contents ){ var result = null ; var func = new NativeFunction (addr,'pointer' ,['pointer' ,'pointer' ,'pointer' ]); Java .perform (function ( var env = Java .vm .getEnv (); console .log ("content is " ,contents) var jstring = env.newStringUtf (contents) result = func (env,ptr (1 ),jstring) result = env.getStringUtfChars (result, null ) }) return result; } function invoke_method01 ( var method_name = "_Z8method01P7_JNIEnvP7_jclassP8_jstring" var m = Module .findExportByName ('/data/app/libnative-lib.so' , method_name) var result = invoke_func (m, 'xcl' ) console .log ("result =>" , result.readCString ()) }
注:frida-server仅在python脚本下需要手动启动,在命令行下会自动启动(有时也需要手动),objection使用时也需要手动启动frida-server。
此时注入任何应用都会并调用invoke_method01,都会成功,如下所示(注入了com.android.settings):
注:真实的情况是,脱离app进行模块函数调用时会发生各种问题,例如签名校验,native层调用Java函数 等,这个时候此方法就行不通了。
总结:此章的作用就是非常便捷的模拟app中的某些函数,且仅需要知道函数的参数与返回值。