starCTF2023
starCTF2023
7.29的startCTF,我以为打两天呢,第二天刚准备上线,没想到只打一天…
0x00 SIMPLEX-WMM
1 | 有人真的可以模拟或仿真 ARM 机器吗? |
本体有两个hint,一个是让了解WMM弱内存模型,第二个是simplex算法。64位arm64。
弱内存模型
C++的out of thin air:线程1先写入变量X,之后线程2再写入变量X,但是由于内存模型的灵活性,可能出现线程1占主导的情况,这种情况叫做out of thin air,它还会导致其他好多问题,例如数据竞争、死锁与崩溃。
最经典的内存模型就是串行模型(Sequentially Consistent:SC),即并发程序按串行执行(之前计算机组成原理的知识)。举一个例子:
1 | 最初:x=y=0 |
按照原始的内存模型,r1与r2至少有一个为0。
但是实际上,的确有可能出现r1=r2=0。这是为什么呢?编译器在编译时发现这两个线程并没有数据依赖关系,那么编译器就会根据需要颠倒线程内指令的执行顺序。这样,执行顺序就可能为:r1=y -> y=1 -> r2=x -> x=1,就与原始的SC模型不符,这就叫弱内存模型(Weak Memory Model)。
simplex算法
单纯形算法。在线性规划中,解空间是由一个多面体决定的,最优解一般多面体的某个顶点。单纯形法的基本思想是:以巧妙的方式从一个角到另一个角移动,直到可以证明最优性为止。
针对优化问题:
写成矩阵形式为:
标准形的形式为:
(1)目标函数要求max
(2)约束条件均为等式
(3)决策变量为非负约束
普通线性规划如何转化成标准形:
(1)若目标函数为最小化,可以通过取负,求最大化
(2)约束不等式为小于等于不等式,可以在左端加入非负松弛变量,转变为等式,比如:
(3)若存在取值无约束的变量,可转变为两个非负变量的差,比如:
例如,将如下线性规划转化为标准形:
其可行域为:
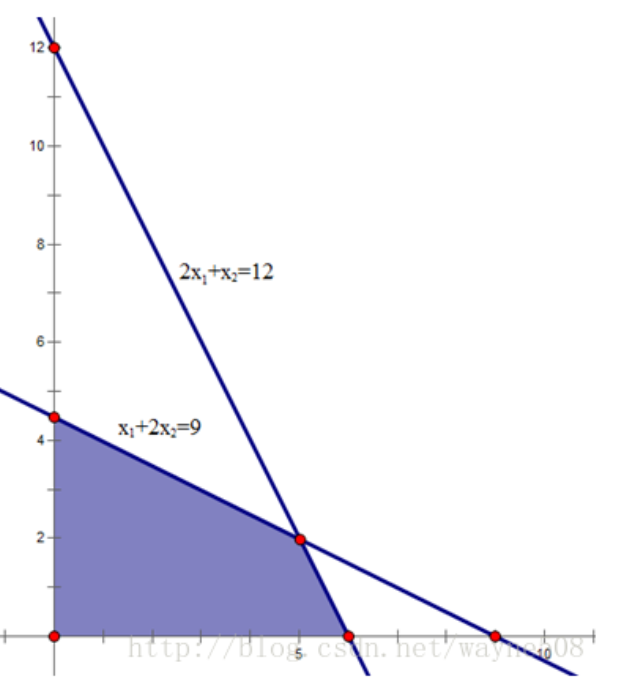
线性规划问题的目标函数最优解必然在可行域的顶点上达到最优。可以总结出:在标准形中,假设有$m$个约束条件(不包括非负约束),$n$个决策变量,那么有$n>=m$。
单纯形法就是通过设置不同的基向量,经过矩阵的线性变换,求得基可行解(可行域顶点),并判断该解是否最优,否则继续设置另一组基向量,重复执行以上步骤,直到找到最优解。所以,单纯形法的求解过程是一个循环迭代的过程。
具体步骤如下:
(1)选取$m$个基变量$x_{j}^{\prime}(j=1,2,…,m)$,基变量对应约束系数矩阵的列向量线性无关。通过矩阵的线性变换,基变量可由非基变量表示(值得琢磨):
如果令非基变量等于0,那么基变量的值为:$x’_i=b_i$。如果为可行解的话,$b_i>0$。
下面探讨它的几何意义(以上面的线性规划为例):如果选择x2、x3为基变量,那么令x1、x4等于0,可以去求解基变量x2、x3的值。对系数矩阵做行变换,如下所示:
因此,可以得到:$x_2=\frac{9}{2}$、$x_3=\frac{15}{2}$。
$X_1=0$表示可行解在y轴上;$X_4=0$表示可行解在$x_1+2x_2=9$的直线上。那么,求得的可行解即表示这两条直线的交点,也是可行域的顶点。所以,通过选择不同的基变量,可以获得不同的可行域的顶点。
(2)那么,如何判断最优呢?首先,目标函数也可以由非基变量表示(因为基变量可以由非基变量表示),如下所示:
当达到最优解时,所有的$\sigma_j$应小于等于0。当存在$j$,$\sigma_j>0$时,当前解不是最优解。为什么?这是因为:当所有非基变量取0时,有$z=z_0$。由上述分析可知,某个非基变量取0代表可行域的边界。如果可行解逐步离开这个边界,$x’_j$会变大,由于$\sigma_j>0$,那么目标函数取值会变大,因此当前解不是最优解。
(3)如何选择新的基变量?如果存在多个$\sigma_j>0$,选择最大的$\sigma_j>0$对应的变量作为基变量,这表示目标函数随着$x’_j$的增加,增长的最快(我们要保留增长最快的,以获得更大的目标函数)。
(4)如何选择被替换的基变量?
假如我们选择非基变量$x’_s$作为下一轮的基变量,且基变量$x’_j$变为非基变量。被替换的基变量$x’_j$要满足的原则:替换后应该尽量使$x’_s$尽量大,因为目标函数会随着$x’_s$的增大而增大。
继续以上例说明,上述例子的最后一行:$x_1$的系数为$\frac{1}{2}>0$,所以选$x2,x3$为基变量并没有使目标函数达到最优。下一轮选取$x_1$作为基变量,替换$x_2$、$x_3$中的某个变量。
探索
Step1:先跑起来再说。发现啥输出都没有。
Step2:IDA瞅瞅。是rust的题目,之前没做过。打算看wp。
佬的wp
链接,没看懂啊,不知道在哪儿去找约束什么的。
于是,自己看了几道rust的例题,我发现,rust的反汇编代码,就是一坨答辩。直接搬运佬的WP,此题通过ARM的WMM去触发异常分支,此题开了两个线程,分别对内存进行操作,从而引发竞争,最终导致WMM的内存不一致。为了增加竞争的可能性,此题在主线程增加了线程的随机调度。
X86为传统的TSO内存模型,而ARM是WMM内存模型。因此必须在ARM架构上才能能正常打印flag。
此外,为了防止动态调试,此题使用了1G的内存污染,如果输入正确,那么就会在一段时间后打印出flag,否则会在3分钟左右打印错误提示。此题可以对数据流进行追踪来解题,或者是找到打印flag的条件(一个全局变量)来解题。我通过后一种方法,交叉引用得到程序逻辑(在sub_A1BC中):
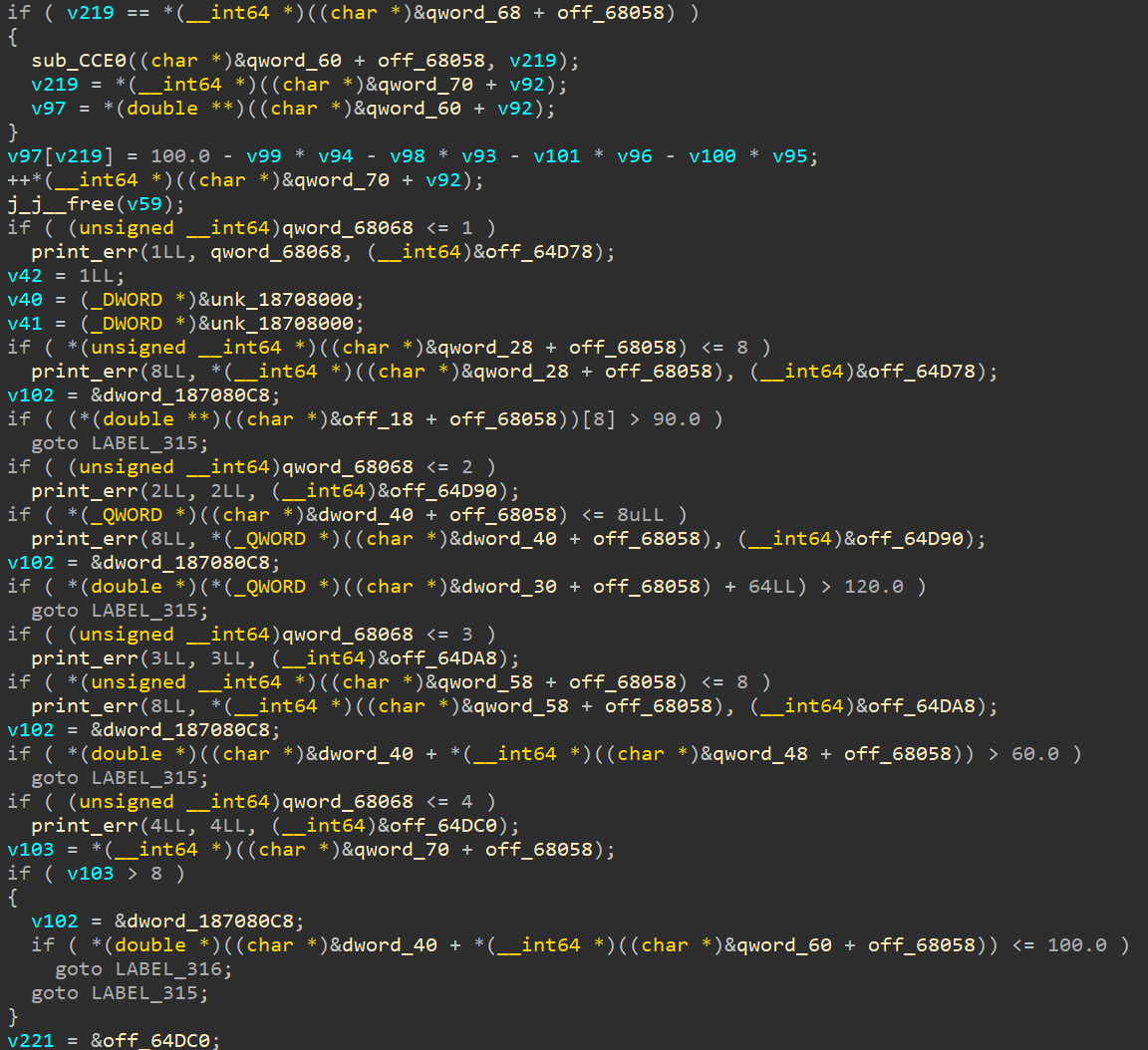
这是一个线性规划问题,总结如下:
求其最优解即可。至于单纯性算法的应用,是在验证逻辑中,即:如果输入的答案还能松弛得到非0目标值(还能优化),那么说明输入的答案不是最优解,如果是最优解,就无法松弛。
最终得到:
1 | #!/usr/bin/env python |
将上值使用float编码并链接:
(1)0的float编码为00000000。
(2)15转为二进制1111,二进制部分为1.111,指数部分为3,符号位为0。最终,指数为3+127=b(10000010),尾数为11100000000000000000000,最终转为16进制为:41700000,小端序存放为:00007041。见cpp-reverse-analysis。
…
最终,flag为:*CTF{0000000000007041000020410000000000e0dd44}。但是在我环境下没跑出来,确定是多核ARM处理器。启动参数为:
1 | sudo qemu-system-aarch64 \ |
再探索
发现WP中给出了原始的rust源码,阅读一波。
两个线程的运行流程如下:
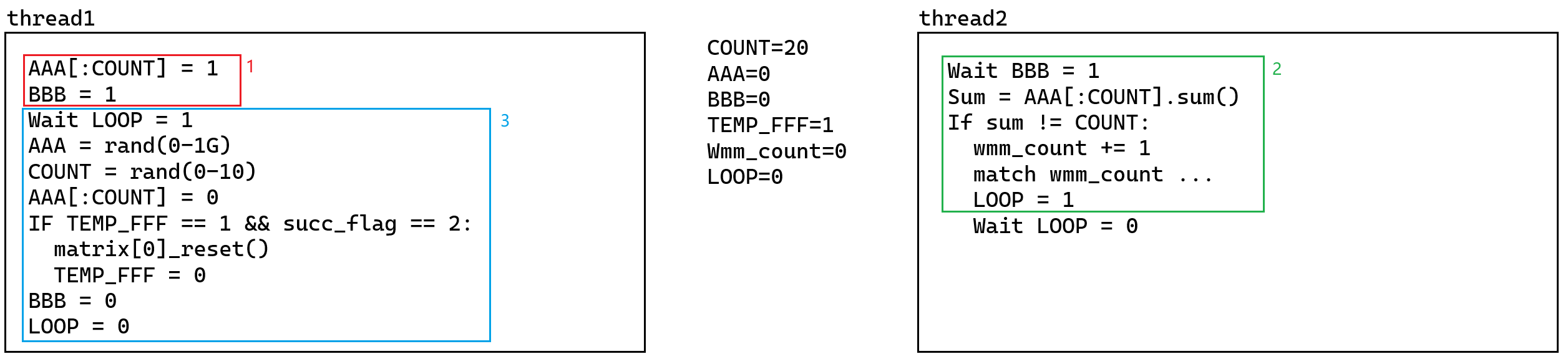
正常情况下,sum==COUNT一定成立,但是由于是WMM弱内存模型,因此执行顺序可能发生变化,从而出现sum!=COUNT的情况(上图thread2最后两条语句应该靠左对齐)。
当第一次出现sum!=COUNT时,wmm_count=1,相继进入place_inp_data()与check_inp_data()。
(1)若检查输入数据不满足约束,则wmm_count+=1。等待下一次出现sum!=COUNT时,wmm_count=3,然后进入check_result()阶段。若check_result()检查输入的数据自洽(不一定是最优解,不一定满足约束),那么succ_flag+=1。
(2)若输入数据满足约束,则等待下一次出现sum!=COUNT时,wmm_count=2,然后进入solve()阶段。solve()函数就利用了单纯性算法进行判断。
1 | // 引入libc |
总结一下:
(1)首先注册定时函数,若3分钟没有结果,则输出错误。
(2)thread1与thread2相互竞争,WMM弱内存模型保证其会在一段时间内执行验证程序。
(3)验证程序使用单纯性算法,具体在gaussian()与pivot()内,但是没具体看,主要是将原理搞懂了。
(4)题目好难。
0x01 GoGpt
1 | This is a eazy reverse challenge provided by gpt-4. Show me if you can win over AI ! |
64位go。go_parser处理一波。非常简单的逻辑:
1 | #!/usr/bin/env python |
0x02 ez_code
1 | 小明是一个windows的骨灰级用户,他精通各种脚本语言。有一天他突然发给我一份奇怪的文件,你能帮我看看里面藏了什么吗? |
plaintext。里面的符号有23种,分别为:
1 | {'@', ';', '}', '$', '{', ')', ']', '%', "'", '*', '(', '?', '|', '!', ' ', '#', '`', '"', '+', '-', '[', '=', '.'} |
猜测应该是github上某个项目。找了好久没找到(咋搜索的啊),看wp。wp中说是powershell混淆,日了狗。将chall另存为chall.ps1并执行,输出Do you konw PWSH(powershell)?。
首先尝试使用PowerShell日志去混淆,但是一直抓不到日志。使用PowerDecode解码,得到:
1 | Function A{ |
两次decode之后是*ctf{hhh_pwsh_is_easy_right?},这是假的flag。
看wp,使用ISE下断点,并通过${@*}这条特殊用法,将参数列表作为一个数组展开,然后使用通配符*将数组中的每个元素进行展开,让其解混淆。如下所示:

因此,可以猜出:程序主逻辑并不在脚本里,而是在参数列表中。将输出的参数列表保存到command.txt,并转为程序,脚本如下所示:
1 | #!/usr/bin/env python |
得到:
1 | class chiper(): |
魔改的xxtea,解密脚本为:
1 |
|
1 | #!/usr/bin/env python |
最终flag为*CTF{yOUar3g0oD@tPw5H}。
0x03 flagfile
1 | flag format: flag{} |
其中由flag(空文件)、flag.mgc(magic?)、readme.txt。readme.txt内容为:
1 | 生成您自己的 flag 文件,使用 file 命令进行验证,如下所示: |
思路:(1)找到这样的 file 命令行程序。(2)搞清file -m的原理。
在链接1安装file-5.41,在链接2下载file-5.41。但是出问题,搜索发现使用的是ubuntu20.04,好像得用22.04才行。弄完之后,输出:

搜索了一波file -m,发现是这样的:file -m aa.mgc bb,aa.mgc是格式文件,就像010editor的模板文件。我猜测,是将flag文件中放入东西,然后使用flag.mgc模板文件判断输入是否正确。
gdb调试一波。结合源码,可以发现:
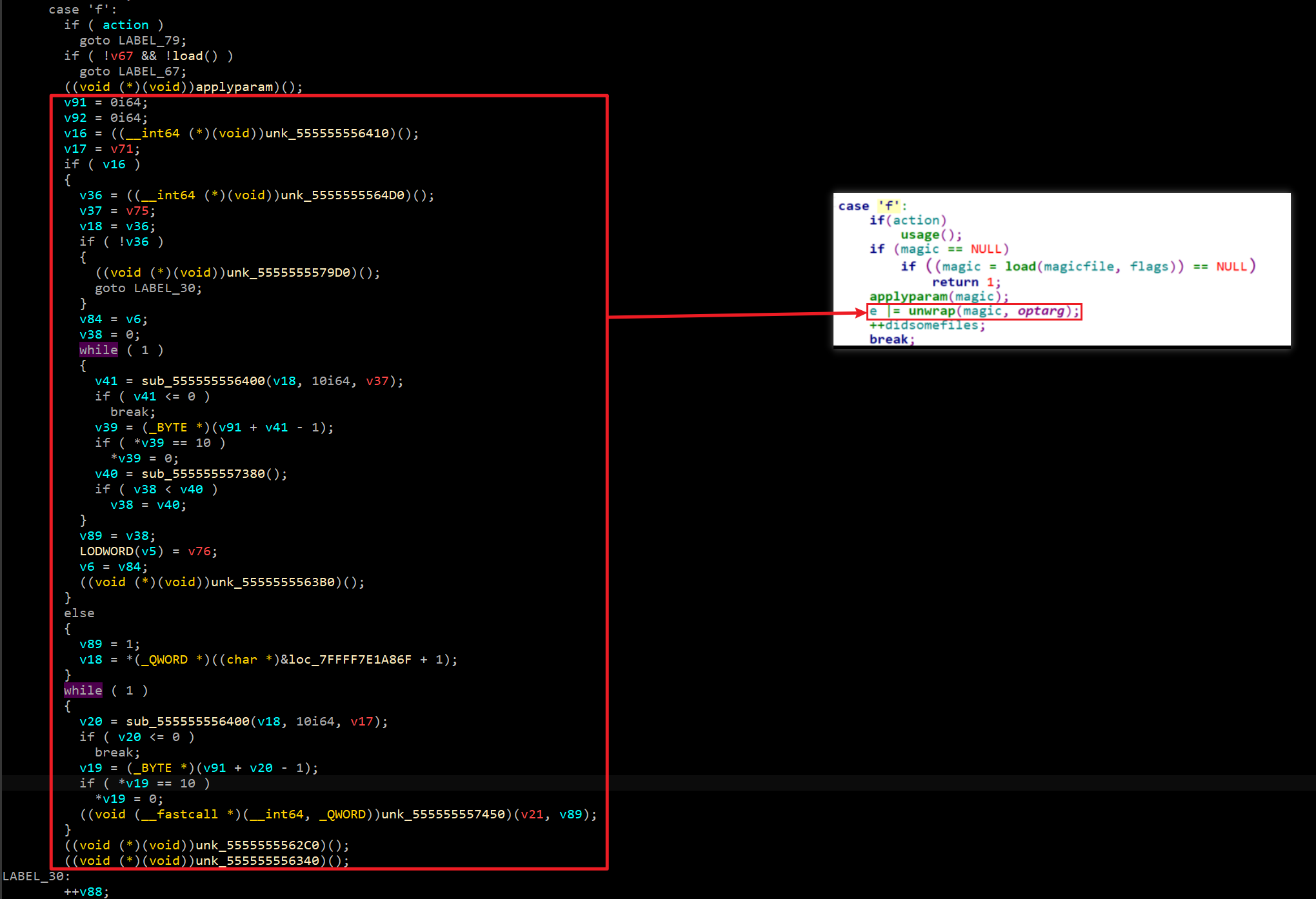
其中,applyparam表示要将mgc文件读取到magic_t对象中。但是我们的选项中没有添加-f,所以接着往下看hh。看到貌似处理函数process():
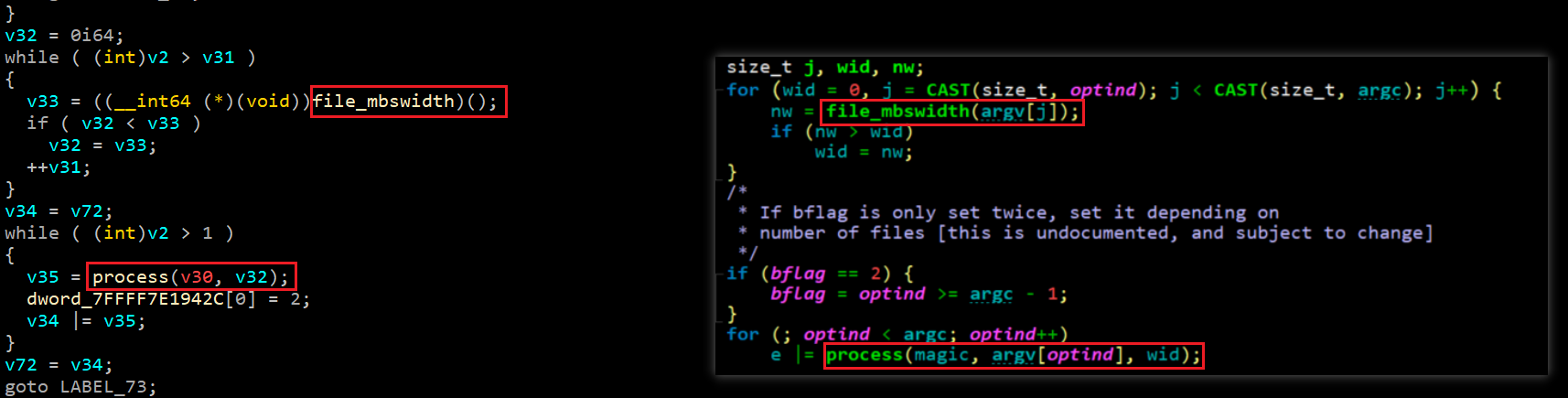
跟进process的源码:
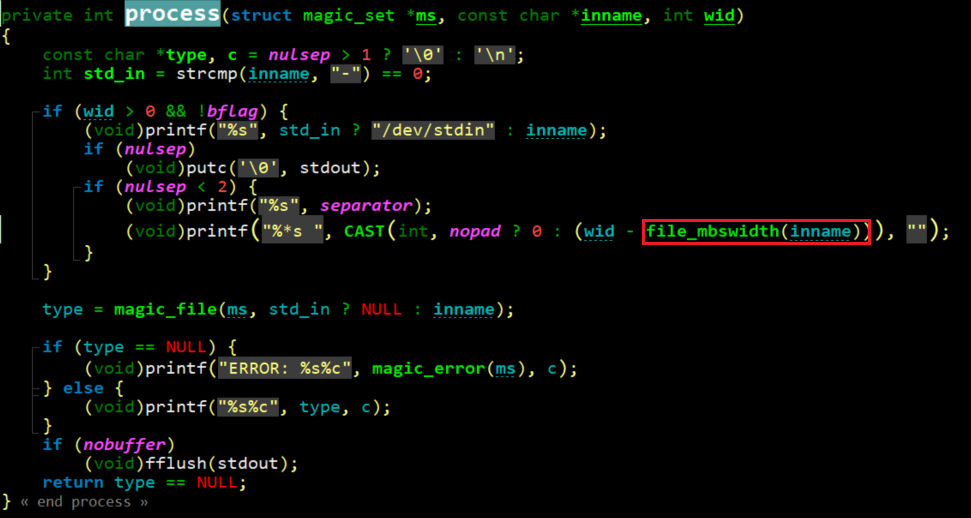
经过调试,感觉需要关注type字段,于是跟进magic_file函数,在magic_file结束后,会输出文件类型。进而跟进到file_or_fd函数。在其中,有:
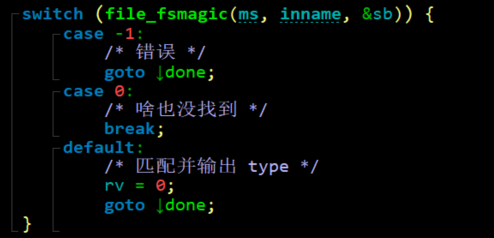
file_fsmagic函数表示:在文件中查找魔术值(magic value)。经过调试,此函数返回0,此时在flag文件中存放的12345678。审计一下file_fsmagic函数:
1 | // ms 是 magic_set |
调迷糊了。看wp。
wp
wp并不是调试出来的,而是看文档得出的。好,我也看文档,链接。
file-5.41的magic文件语法,举几个例子:
(1)例1:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(2)例2:
1 | 0 string MZ |
解释如下,其中(4.s*512)=hex(4*512)=0x400:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(3)例3:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(4)例4:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(5)例5:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(6)例6:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(7)例7:
1 | 0 string MZ |
解释如下:
1 | if 检查偏移地址 0 是否以字符串 "MZ" 开头: |
(8)例8:
1 | >18 clear |
解释如下:
1 | 偏移地址 0x18 清除之前设置的条件 |
关键问题是,flag.mgc如何转成上述这样的格式?
就要用到如下脚本(flag.mgc (binary)--> flag.magic (code)):
1 | import hexdump |
上述脚本中,table为字符,index为字符所在的位置。最后可以得到flag:flag{_oh_yes_you_got_the_flag___^_^__}。
总结:不知道他这脚本咋写出来的,感觉主要得靠猜(可能是我看的不仔细吧呜呜)
0x04 boring cipher
有一个cipher-release,输入字符串,输出与cipher-release同样大小的加密文件。看到用了llvm混淆+rust,感觉到了shit。
题目正向逻辑非常简单:
(1)输入32位字符串,根据每8位输入将0->15做混淆,混淆20轮。
(2)根据0->15的混淆对data[256]做混淆,混淆15轮。
(3)根据data[256]对当前文件做self_exe[ii] += data[self_exe[ii]]处理。
相关正向脚本如下:
1 | # (1)(2) 步对输入的混淆,得到 data[256] |
应该得到的data[256]数组为:
1 | # target data[256] |
如何由data[256]得到输入?这步没做出来。看wp(没找到wp..)
0x05 总结
拖了好久,终于基本完成了。遇到了 powershell 混淆,rust 等,学习到了很多,仍要再接再厉!
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!