cpp_reverse_analysis
C++反汇编与逆向分析技术揭秘
0x00 工作环境与相关工具
VS编译选项设置:
(1)Debug:不对汇编代码做优化。
(2)Release:对编译代码做优化,默认为01优化(最小文件优化),还有一种是02优化(最快执行速度优化)。
IDA函数名称识别:
IDA可以识别出库函数(例如MessageBoxA),这是由于IDA的SIG文件的作用。我们可以自己制作SIG文件,放到IDA安装目录的SIG文件夹下。制作步骤如下:
Step1:将OBJ或LIB文件制作成PAT文件。OBJ文件包含函数名与对应代码的机器码,而LIB文件包含OBJ文件。
制作PAT的过程中,会将机器码特征与函数名保存在PAT文件中。使用pcf.exe将COFF文件格式(obj或lib文件)制作成PAT文件,使用pelf.exe将ELF格式(.o文件与.a文件)制作成PAT文件。随书文件中给出了pcf.exe与pelf.exe。
Step2:多个PAT文件联合编译成SIG文件。使用sigmake xxx.pat xxx.sig,若为多个PAT文件,则为:sigmake -r *.pat xxx.sig。
制作sig文件的bat脚本:
1 | if %1=="" goto end |
此脚本的功能为:在当前目录下打包所有lib与obj文件并生成xx.sig文件。
书中还介绍了反汇编引擎的工作原理,主要是ollydbg、ida如何将机器码转为汇编指令的。由于之前学习过,所以不再赘述。书中还具体介绍了preview反汇编引擎的源码。
0x01 基本数据类型表现形式
整数类型不再赘述,有符号整数:正数0x00000000-0x7FFFFFFF,负数0x80000000-0xFFFFFFFF。
浮点数
浮点存储:用一部分二进制位存放小数点的位置信息(指数域),其他的数据位用来存储没有小数点时的数据与符号(数据域)。通过结合指数域与数据域来得到真实数据。例如,67.625,数据域记录为67625,指数域记录为10的-3次方。浮点数的操作不会用到通用寄存器,而是会使用专门的浮点寄存器进行处理。
(1)float类型
float编码格式为32位,结构如下:

例如,float类型的12.25,转为二进制为1100.01,用科学计数法表示,二进制部分为1.10001,指数部分为3。最终,符号位为0;指数位为:3+127=130(固定要加127),转为二进制为10000010;尾数为10001000000000000000000。最终编码为:
1 | 01000001010001000000000000000000 |
再比如,float类型的-0.125,转为二进制为0.001,用科学计数法表示,二进制部分为1,指数部分为-3。最终,符号位为1;指数位为:(-3)+127=124,转为二进制为01111100,尾数为00000000000000000000000。最终编码为:
1 | 10111110000000000000000000000000 |
但是,针对无法用二进制表示的小数位,例如0.3,那么我们只能用23位尾数表示近似于0.3的值。
(2)double类型
与float类似,最高位表示符号,指数位占11位,剩余52位表示尾数。它是float类型所占空间的两倍。
浮点数指令
浮点数操作是用浮点寄存器实现的,普通数据类型使用的是通用寄存器。
早期CPU中,浮点寄存器通过栈结构实现的,由ST(0)-ST(7)8个寄存器,每个浮点寄存器占8字节,这些浮点寄存器是用栈实现的。浮点寄存器的使用就是压栈、出栈的过程。当ST(0)中存在数据时,执行压栈操作,ST(0)中的数据将装入ST(1),如果没有出栈操作,将按顺序向下压栈,直到将浮点寄存器占满为止。
97年开始,Intel和AMD引入了媒体指令(MMX),它允许多个操作并行。近些年来又有很多的发展,存浮点数的寄存器中:MM寄存器是64位的,XMM是128位的,YMM是256位的。YMM寄存器一共有16个。相应的还有常用的浮点数指令等,例如MOVSS(传送32位单精度数)、ADDSD(双精度加法)等。
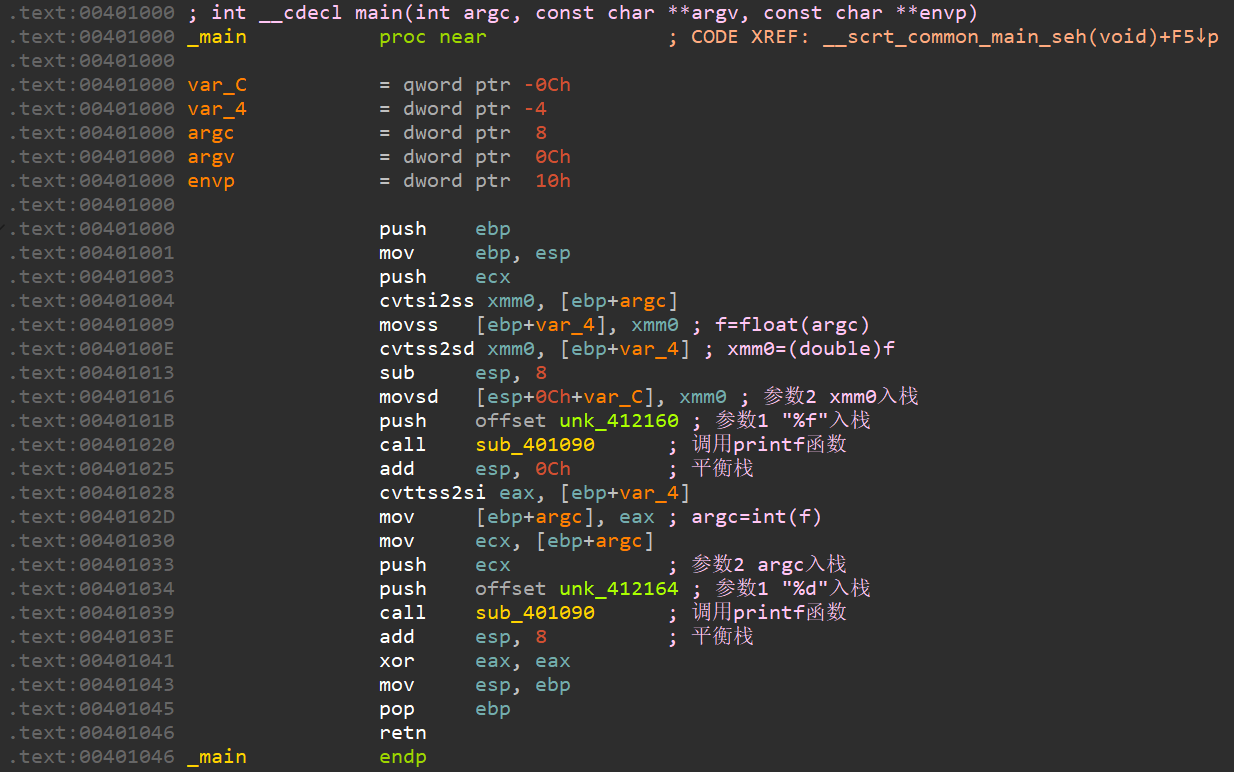
例子1
有程序:
1 |
|
其使用x86_vs、x86_gcc、x86_clang、x64_vs编译后的汇编代码与解析如下:
(1)x86_vs如下:
(2)x86_gcc如下(主要看传参):
略。
0x03 表达式求值过程
之前太懒了,之前没有边看边记。从自增与自减开始,要记笔记咯。之前对于除法的部分,非常有用,但是没记。
自增自减
(n++)是先用再加,(++n)是先加再用。
关系运算与逻辑运算
JZ、JE、JNZ、JNE、JNAE、JNB之流,用到什么查什么。TEST指令:在两个操作数的对应位之间进行 AND 操作,并根据运算结果设置标志位,但不修改目标操作数。
表达式短路:通过与运算和或运算使语句执行时发生中断,从而不执行后面的语句。具体原理为:与运算左表达式为假,则不运行右表达式;或运算左表达式为真,则不运行右表达式。例子如下:
1 |
|
条件表达式:A?B:C。4种情况,如下:
(1)表达式1为简单比较,表达式2与表达式3为常量且相差为1。其关键代码与相应汇编如下:
1 | argc == 5 ? 5 : 6 |
1 | cmp dword ptr [esp+4], 5 ; 比较argc与5 |
(2)表达式2与表达式3为常量且相差大于1。
1 | argc > 5 ? 4 : 10 |
1 | cmp dword ptr [esp+4], 5 |
(3)表达式2与表达式3有变量。
1 | argc ? n1 : n2 |
1 | mov eax, [esp+0Ch] ; eax=n2 |
(4)表达式2与表达式3有变量表达式。
1 | argc ? n1 : n2+3 |
1 | cmp dword ptr [esp+0Ch], 0 |
可以看到,使用了分支来实现条件表达式。分支一般效率比条件表达式高,因为CPU能对分支走那条路进行预测。
位运算
<<:左移,最高位到CF中。>>:右移运算,最低为到CF。大多数位运算会导致信息的丢失。对于左移运算而言,有无符号数都是一样的,而对于右移运算而言不一样。
编译器优化技巧
本章讨论基于奔腾处理器的优化。代码优化的方向为:(1)执行速度;(2)内存空间;(3)磁盘空间。编译器编译大型软件通常要好长时间,其流程为:预处理、词法分析、语法分析、语义分析、中间代码生成、目标代码生成。优化一般存在于中间代码生成与目标代码生成两部分。由于中间代码生成在不同的硬件环境下都能通用,因此主要是在这方面做优化。
常见的中间代码生成优化方案如下:
(1)常量折叠,例如x=1+2,可优化为x=3。
(2)常量传播,例如x=3;y=x+3,可优化为y=6。
(3)减少变量,例如x=i*2;y=j*2;if(x>y){...},可优化为if(i>j){...}。
(4)公共表达式,例如x=i*2;y=i*2;,可以优化为:x=i*2;y=x;。
(5)复写传播,例如x=a;...;y=x+c,可以优化为y=a+c。
(6)剪枝,例如if(1>2){}else{}。
(7)顺序语句代替分支,例如上述的条件表达式优化。
(8)强度削弱,用移位代替乘法,用乘法代替除法。
(9)数学变换,x=a*y+b*y优化为x=(a+b)*y,只需一次乘法。
(10)代码外提,例如while(x>y/2){...中并未修改y},因此可优化为t=y/2;while(x>t){...},此时无需每次循环都要计算y/2。
目标代码生成方面的优化(生成二进制代码)与硬件环境有关。针对奔腾处理器,主要的代码生成优化方案有:
(1)流水线优化。针对指令add eax, dword ptr ds:[ebx+40DA44],其机器码为038344DA40000,流水线的工作流程如下:
(a)取指令。取0x03,eip+1。
(b)指令译码。得知为加法,但信息不够,先把0x03放入指令队列缓存中。
(c)取指令。取0x83,eip+1。
(d)指令译码。得知参与寻址的寄存器为ebx,存放目标为eax,其后有4字节偏移,把0x83放入指令队列缓存中。
(e)取指令0x44DA40000,放入内部暂存器。同时,ebx的值保存到ALU(计算单元)。
(f)将eax的值传送到ALU。调度MMU(内存管理单元),得到内存单元中的值并传送到ALU,最后进行加和。
(g)将结果保存到eax中。
引入流水线后,例如mov eax, 1; add esp, 8;,第1条流水线执行mov指令时,此时第2条流水线可以对add esp, 8进行读取与译码。奔腾处理器采用长流水线,即每条指令划分为很多阶段,每个阶段执行的工作内容都很简单,这样的优点是容易设计电路,加快工作效率。但是缺点是发生错误后损失较大。例如jmp A; add esp, 8;,第1条流水线正在译码jmp A,此时第2条流水线正在读取add esp, 8指令。但是这是一条jmp指令,因此根本无需分析add esp, 8。ARM使用多流水线,并行程度更高,但是电路设计更复杂,流水线的管理成本也高。
流水线虽好,但是也有些注意事项:
(1)指令相关性。后一条指令依赖于前一条指令的硬件资源,例如add edx, esi; sar edx, 2;。因此只能先执行完第1条,再执行第2条。
(2)地址相关性。前一条指令需要访问并回写到某一地址,而后一条指令也要访问这个地址,例如add [00401234], esi; mov eax, [00401234]。因此只能先执行完第1条,再执行第2条。
为了配合流水线工作,处理器增加了分支目标缓冲器。分支目标缓冲器可以记录跳转指令的目标地址,就像表格一样。若遇到分支结构,则利用分支目标缓冲器预测指令的目标地址。分支目标缓冲器所预测的目标地址不一定对。因此,在写循环时,大循环尽量放在内层,这是因为:内层的时候会对目标地址进行预测,预测对了就会提高程序的执行效率,大循环写到内层,分支预测对的次数就会变多。
由于内存的访问效率比处理器更慢,因此增加了片上高速缓存(cache)。cache存放以表格形式存放数据。访问数据时,先找cache。对于分页而言,为了避免频繁访问三级页表转换地址,处理器准备了页表缓冲(TLB),和cache使用的方法类似。TLB与cache都在处理器中。高速缓存是数据对齐的,对于x86而言,因为地址如果不是4对齐的,那么访问数据的时候需要访问多次才能拿到。
这里还给了一个例子,是判断密码是否在正确的。比较好且简单,这里不做过多分析。
0x04 流程控制语句的识别
C语言是根据代码行的位置决定编译后二进制代码地址的高低的。IF与上节的条件表达式类似,注意02优化选项的不同。switch的效率高于if。在汇编代码中,if结构会在条件跳转后紧跟语句,而switch则会将所有条件跳转放置到一起,当分支过多且各分支比较的值有序时(或者基本有序),switch会使用数据寻址的方式,例如ds:off_401xxx[eax*4],其中off_401xxx为各分支地址表(跳转表),eax为有序字符。
对于难以构成跳转表的switch,可以采用构建索引表的方式来优化。索引表包括:case语句块地址表、case语句块索引表。地址表包括每一个case的起始地址,是编号到起始地址的映射。索引表中保存地址表的编号,索引表的大小为最大case-最小case,例如switch number,且number在0-255之间,则索引表的大小为255字节,是序号到编号的映射。有两次查表过程,第一次查索引表,得到地址表中的索引,第二次根据地址表的索引查地址。
如果case比较稀疏时,会浪费好多空间。这样的话,可以使用判定树来对索引表所占内存进行优化。每一个case代表一个节点。对于01优化选项来说,体积优先,因此不允许占地方的索引表,而是使用判定树。是if结构,不过是树的形式,不必多言。突然想到曾经做的题中有好多类似于这个的。
do、while、for循环不再多说,非常简单啦。在优化方面,do循环无需优化,因为它只有一个跳转指令(跳转到开头),而while循环则需要两个jmp(一个判断,一个跳转到循环开头),for循环可能更多。do的执行效率最高。任何while循环都可以转化为do循环。例如:
1 | int sum = 0; |
转为:
1 | int sum, i = 0, 0; |
其次,将代码外提,不必每次都要计算。例如:
1 | int sum, i = 0, 0; |
转为:
1 | int sum, i = 0, 0; |
还有优化方法为强度削弱,例如用加法代替乘法,这里不给出例子。
0x05 函数的工作原理
当栈顶esp小于栈底ebp时,就形成了栈帧。栈帧中保存寻址局部变量、函数返回地址、函数参数。
栈平衡:函数调用时,要对被调用的函数形成所需的栈空间,函数结束调用时,需要清除刚刚形成的栈空间。
三种调用方式,核心原理里有,复习一下:_cdecl为调用方平衡栈,参数不确定的函数用这个。_stdcall为被调用方平衡栈。_fastcall为被调用方平衡栈,寄存器方式传参(只用ecx与edx)。printf函数使用_cdecl平衡栈,特殊的是,在02优化选项下,会采用复写传播优化,将每次参数平衡的操作进行归并,一次性进行栈平衡。例子如下:
1 | push "hello" |
参数寻址使用ebp或esp进行寻址,例如:
1 | int n = 1 ==> mov dword ptr [ebp-4], 1 |
但是上面所示的ebp寻址的方式,大多只发生在非02选项下,因为这样做可以方便调试与检测栈平衡。而在02选项下,省略了检测栈平衡的操作,而是直接用esp访问局部变量。例子如下:
1 | int n = 1; |
其反编译为:
1 | var_5 = byte ptr - 5 |
使用esp寻址后,如果函数执行过程中esp发生了改变,那么在此访问变量时就需要重新计算偏移。为了解决这个问题,ida在分析过程中事先将函数中的每个变量的偏移值计算出来,得出一个固定的偏移值,并用标号进行记录,例子如下所示:
1 | var_0 = -4 |
如果函数使用过程中用栈来传参,那么在ida中,正数表示参数,负数表示局部变量,0表示返回地址。注意,对于有push reg但是没有相应pop操作的情况,大概率是代替sub esp, 4,因为这样效率更高。对于不定数量参数的函数,其参数类型传入时都为dword,且需要在某一参数中描述参数的总个数(例如printf)或将最后一个参数赋值为结尾标记。
对于函数的返回值,一般使用eax来进行返回值的传递,对于多返回值(结构体)的情况,一般使用eax和edx进行返回值的传递。
x86有3种函数调用方式(__stdcall,__cdecl,__fastcall),但是x64只有寄存器快速调用约定。前四个参数使用寄存器传递(rcx|rdx|r8|r9)后面的使用栈传递。任何大于8字节或者不是1字节/2字节/4字节/8字节的参数使用引用(指针)传递。所有浮点参数使用XMM寄存器传递(XMM0|XMM1|XMM2|XMM3)。例如,void fun(float, int, float, int)的参数传递顺序为XMM0|rdx|XMM2|r9。虽然前4个参数使用寄存器传递,但是栈中仍然为这4个参数预留了空间,这里称之为栈预留空间,这是为了在函数复杂时不占用多余的寄存器。
0x06 变量在内存中的位置与访问方式
通常,在PE的只读数据节中,常量的节属性被修饰为不可写,而全局变量和静态变量则在属性为可读写的数据节中。具有初始值的全局变量,其值在链接时被写入创建的PE文件中,当用户执行该文件时,操作系统首先分析并加载PE中的数据。因此,全局变量在程序的任何地方都可以访问,不受作用域的影响。
全局变量与常量相似,都是写入到了文件中,因此生命周期与所在模块相同。全局变量与局部变量的生命周期不同,全局变量的生命周期起始于所在执行文件被操作系统加载后,当程序退出时,全局变量销毁。而局部变量的生命周期则局限于函数作用域。简单理解,生命周期是时间方面衡量的,作用域是空间方面衡量的。
局部变量一般保存在栈中,是通过栈指针来访问的,而全局变量的内存地址在全局数据中,通过固定的地址来访问。先定义的全局变量在低地址,后定义的全局变量在高地址。
局部静态变量的工作方式
对于静态变量(例如static int a = 1;),分为全局静态变量于局部静态变量。全局静态变量只能在当前文件中使用,可以看作:全局静态变量等价于编译器限制外部源码文件访问的全局变量。局部静态变量的生命周期与全局变量相同,但是作用域仅限于函数体内。局部静态变量会预先被作为全局变量处理,而其初始化部分是在做赋值操作。
当某函数(例如showStatic)被频繁调用时,其中的静态变量只能初始化一次,此时编译器是如何做的呢?如下所示:
1 | cmp flag, 0FFFFFFFFh |
还有一个问题,编译器是如何让其他作用域对局部静态变量不可见的呢?答案是粉碎法,即在编译期将静态变量重新命名。例如,g_static变为_stdio_printf_options@@9..g_static...@?1??sh之类的。重新命名的过程中,在原有名称中加入其所在的作用域以及类型等信息。
堆变量
C++中,使用malloc或new申请堆空间,返回的数据便是申请的堆空间地址。使用free或delete释放堆空间。以商场中的商铺为例,malloc是从商场的空地中划分出一块作为商铺,而new则是直接租用划分好的商铺。因此,malloc需要将申请好的堆进行强制转换以说明其类型,而new无需此操作。
在申请堆空间的过程中,调用了_malloc_dbg,之后又调用了heap_alloc_dbg_internal,此函数中使用__CrtMemBlockHeader结构描述了堆空间的成员。堆结构的节点是使用双向链表存储的,__CrtMemBlockHeader结构中,定义了前指针pBlockHeaderPrev和后指针pBlockHeaderNext,通过这两个指针可以遍历程序中申请的所有堆空间。除此之外,结构中还有request_number来记录当前堆是第几次申请,gap则为保存数据的数组。
堆释放过程中,只需将要释放的堆从链表中脱链,即可完成堆释放操作。堆的增长方向通常是向上的,即从低地址向高地址增长。书中给了一个分析的示例,比较有意义,但是这里并不记录,具体见P256。
0x07 数组与指针的寻址
C++中,字符串也被当作数组,其使用寄存器来进行复制,因此一次复制4字节/8字节。
数组作为参数,是如何传递的呢?是直接传递数组头指针。需要注意的是,当将数组传递到使用它的函数时,不能使用sizeof来判断数组的长度,而是要使用strlen。对于数组作为返回值而言,有一个特殊的地方:由于数组在函数内以局部变量形式存储在栈中,且函数返回时会平衡栈,因此当其以指针形式返回时,栈中的数据会变得不稳定。因此,要尽量避免这种情况的发生。
数组的寻址方式有下标寻址与指针寻址两种。指针寻址效率更低,因为指针寻址中,指针指向数组的某地址,要先取出这个地址,然后根据偏移算出最后的目标地址。而下标寻址中,由于数组名本身就是常量地址,因此可以直接针对数组名代替的地址值及逆行偏移计算。(这段不是特别懂)直接上例子:
1 | ------------------------------- 指针寻址 ------------------------------- |
从上例来看,指针寻址需要经过2次寻址才能得到目标数据,而下标寻址方式只需要1次。
使用下标寻址时,要注意:编译器不会对数组的下标进行访问检查,因此很容易出现越界访问的错误。
多维数组与一维数组在内存中的存储方式相同。寻址不再多说,非常简单。
存放指针类型的数组,各个数据元素都是相同类型的指针。例如:char *ary[3] = {"hello", "world", "!"};,注意与二维字符数组char ary[3][10] = {{"hello"}, {"world"}, {"!"}};的区别。char *ary[3]的每个元素都是一个指针,可以使用二级指针来寻址,例如变为char **p;。
与存放指针类型数组很像的,是指向数组的指针变量,例如:char ary[3][10] = {{"hello"}, {"world"}, {"!"}};,把他变成指向数组的指针变量为:char (*p)[10],其中*p可以看作A,那么就是char A[10]。char (*p)[10]的每个元素都是一个数组,需要+10才能到下一个指针,因为此时数据类型为10字节数组。
上述两段还挺重要的,之前做题经常迷糊的点。
函数指针是保存函数首地址的指针变量,其由返回值、参数信息、调用约定组成,他们决定了函数指针在函数调用过程中参数的传递、返回值信息以及如何平衡栈顶。为了区分函数调用与函数指针的调用,给出如下例子:
1 | void _cdecl show(){ |
1 | mov dword ptr [ebp-4], offset sub_401000 |
由于与其它指针不同,函数指针保存的地址是处于代码段的,而不是数据段。因此,编译器不允许函数指针做无意义的加减法操作。
0x08 结构体与类
C++中,结构体与类都有构造函数、析构函数和成员函数,但不同的是:结构体的访问控制默认为public,类的默认访问控制为private。public、private、protected的访问控制都是在编译期进行检查。编译成功后,程序在执行过程中不会做检查。因此,在反汇编中,类与结构体没有区别。
对象的内存布局
C++中的类示例如下:
1 |
|
类中不能定义自己,因为如果这样计算长度的时候就会崩掉。但是,可以定义自身的指针。空类的长度为1字节。C++默认对齐值为8字节的倍数,当然也可以是4字节的倍数,也可以使用#pragma pack(N)设置对齐的大小。当设定的对齐值大于结构体中的数据成员类型的时候,对齐值是无效的。也就是说,对齐值=min(设定的对齐值, 结构体中最大的数据类型大小)。例如:
1 | struct { |
上述结构体一共占8字节,对齐值为2字节。当结构体中又出现结构体时,会将嵌套结构体的对齐值作为衡量,进行比较。如下所示,stTwo的对齐值为4:
1 | struct sstOne { |
当类中的数据成员为静态时,其存放位置与全局变量一致(数据区),只是编译器增加了作用域的检查,作用域之外不可见。同类对象将共享静态数据成员的空间。
对象的内存布局不简单,除了数据变量,如果类是某父类的派生,且父类有虚函数,那么此类的内存布局中将含有虚函数表和父类数据成员等信息。当对象为全局对象时,其内存布局与局部对象相同,不同的是所在内存地址(全局对象在数据区,局部对象在栈)、构造函数与析构函数的触发时机。
this指针
this指针保存了所属对象的首地址。举一个例子:
1 | struct A { |
起始这里的&p,就可以看作this。看一个具体的例子,来访问类对象的数据成员:
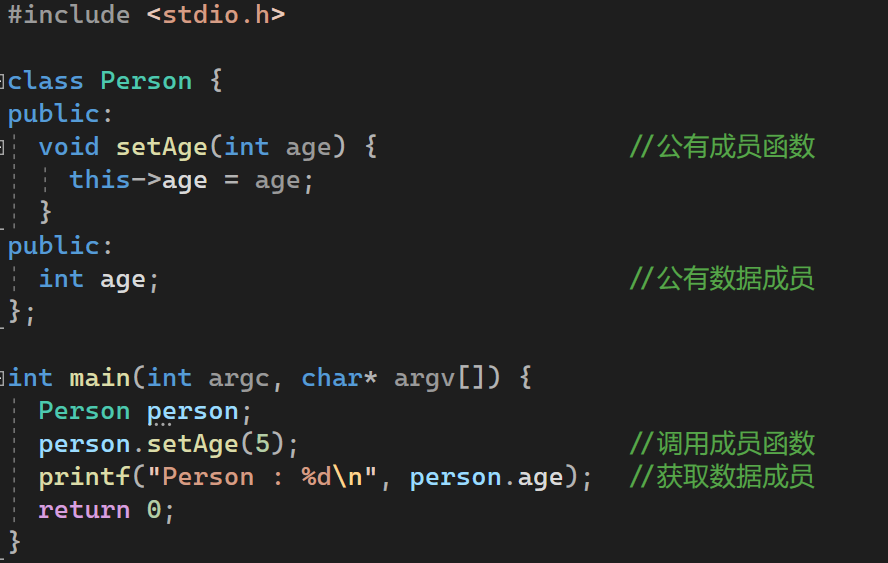
其反汇编为:
1 | Main: |
可以看到,虽然setAge只有一个参数,但是在汇编中却添加了一个对象的地址ecx。这就是this指针的由来。在分析过程中,如果看到某函数使用ecx传递参数,且ecx中保留了对象的this指针,即可怀疑此函数为成员函数。当然,这个规律也不是一定成立的,当使用其他调用方式(例如__stdcall)时,this指针便使用栈来传递,此时就很难区分是否为成员函数。
静态数据成员
静态数据成员的初值会被写入编译链接后的执行文件。类中的静态数据成员不属于某一对象,其与对象之间是一对多的关系,多个对象也可以拥有同一个静态数据成员。在计算类的长度的时候,静态数据成员不被计算在其中。静态数据成员是常量地址,可通过立即数间接寻址的方式访问。且静态数据成员属于全局变量,且不属于任何对象,因此访问时无须this指针。
对象作为函数参数
当类的实例作为函数参数时,不会像数组一样将首地址传递过去,而是将对象中的所有数据进行备份,之后将备份的数据作为形参传递到调用函数中使用。但是有一个问题,类的长度不定,那么是如何传递的呢?就这么传呗,注意传参顺序为:最先定义的数据成员最后压栈,最后定义的数据成员最先压栈。
对于含有数组数据成员的对象传参,例子如下所示:
1 | class Person { |
其对应的汇编代码为:
1 | ... |
我们可以看到逻辑不通的地方:对象person占用的内存大小为40字节,但是esp只减了32字节,复制的时候又复制了40字节。那么会不会复制完了之后会造成越界访问么?其实不然,strcpy的调用方式是__cdecl,即调用者平衡栈顶,但是调用了strcpy没平衡栈顶,且strcpy的参数为两个,总共占8字节,所以懂了吧?
在64位程序中,因为栈顶为栈预留空间(就是寄存器的参数可以转移到这上面来),因此无法将对象的数据成员复制到栈顶,编译器将对象的数据成员先复制到临时对象,再将临时对象的地址传递给show函数。
对象当作参数传递时,会制作一份对象的复制数据,当向对象分配内存时,如果有构造函数,编译器会再调用一次构造函数,并作初始化操作。这等同于又定义了一个对象,在某些情况下会调用特殊的构造函数:复制构造函数。当代码执行到作用域结束时,局部对象将被销毁,此时再调用析构函数,对内存资源进行释放。这种情况下,由于重新复制了对象,且复制对象作为函数内的局部变量,在函数结束时将会被销毁。此时会产生一个问题,如下所示:
1 |
|
在这个例子中,当对象person作为参数传递时,参数obj复制了对象person中的数据成员name,最终产生两个Person的对象,分别为person与obj。由于没有编写复制构造函数,因此上述例子传递参数的时候是浅拷贝,即:obj与person对象的name字段都指向同一堆地址。当show函数结束时,会释放对象obj,此时name字段被释放掉,person对象就会一脸懵逼。即,再次调用show(person)的时候就会出错。
为了解决这个问题,可以使用深拷贝或者设置引用计数的方法。深拷贝就是调用复制构造函数把对象完全复制一份,包括其中的字段。引用计数也不再多说。
当参数为对象的指针时,不会出现此类问题,因为传的是指针类型,传递过程中无需调用构造函数与析构函数。
对象作为返回值
对象作为返回值与对象作为参数的处理方式类似。对象作为参数时,进入函数前预先保留对象使用的栈空间,并将实参对象中的数据复制到栈空间中。当对象作为返回值时,调用函数将申请返回对象使用的栈空间,并将返回对象的首地址压入栈中,用于保存返回对象的数据。所以,对象作为返回值时,传递是这样的:被调用函数内的局部对象->调用函数内的临时对象->调用函数内的正牌对象。为什么中间还要经过临时对象呢,是因为C++有的时候会有这种情况:直接访问函数A.变量,函数A的返回值是对象,这样的话,由于此时函数A已经退出,其栈帧被关闭,因此无法访问函数A中的对象所在的栈。因此,当函数A退出时,最好的办法是把返回的对象保存在调用者函数的栈中。
上一段中的返回值传递,使用了数据复制,但是仍是浅拷贝,因此也可能会出现同一资源多次释放的错误。对象作为返回值时,不能像作为参数值一样传递指针,因为返回值为局部变量,被调用函数执行完后会销毁这些局部变量。
小trick
在不产生对象的情况下取得成员偏移量:
1 | #define offsetof(s,m) (size_t)&(((s*)0)->m) |
0x09 构造函数和析构函数
构造函数负责初始化,析构函数负责销毁。构造函数支持重载,析构函数是无参函数。他们都不可定义返回值(不是没有),构造函数的返回值是对象首地址。
构造函数的出现时机
当对象作为参数或者返回值时,构造函数的出现时机是不同的。对象作为局部对象、堆对象、参数对象等类型,构造函数的出现时机也是不同的。且由于构造函数是成员函数,所以在调用的时候需要传递this指针。构造函数调用结束后,会将this指针作为返回值。
成员对象,进入函数作用域后调用构造函数:
1 | int main(){ |
堆对象,在申请完堆空间后调用构造函数:
1 | Person* p = new Person();` |
补充:有参构造函数与对象数组。
1 | int *p = new int(10); // 申请了int类型的堆变量并赋初值 |
参数对象,当对象作为函数参数时,调用复制构造函数,该构造函数只有一个参数,且类型为对象的引用。这相当于复制了一个全新的对象。复制构造函数会完成两个对象之间数据的复制。如果没有定义复制构造函数,则会使用默认复制构造函数,但是它是浅拷贝的。如下所示:
1 | Person obj1; |
因此,当类中有资源申请,并以数据成员来保存这些资源时,就需要使用者自己写一个复制构造函数,来实现深拷贝。例子如下所示:
1 | class Person { |
汇编代码看P339,很有意义。值得多看几遍。
返回对象,与参数对象类似,不同的是:参数对象是在进入函数前调用复制构造函数,而返回对象则是在返回前使用复制构造函数。也值得看,P345。
全局对象与静态对象:两者构造函数调用的时机相同,都是在mainCRTStartup -> _cinit -> _initterm函数中。代码片段如下:
1 | extern "C" void __cdecl _initterm(_PVFV* const first, _PVFV* const last){ |
执行(**it)()后并不会进入全局对象的构造函数,而是进入编译器提供的构造代理函数,然后再调用全局对象的构造函数。针对某一类,有对应的构造代理函数,此构造代理函数中包括多个全局对象的构造过程代码。
那我们如何找到全局对象构造函数的位置呢?(1)对于vs,定位mainCRTStartup -> _cinit -> _initterm,对于gcc,定位__main。(2)利用栈回溯,在全局对象那里下断点,之后可以看到构造函数。(3)在atexit函数下断点,因为构造代理函数中会注册析构函数,注册的方式就是使用atexit。
每个对象是否都有默认的构造函数?
结论:编译器不是在任何情况下都提供默认构造函数的。提供默认构造函数的情况有:(1)类(父类)中有虚函数。因为需要初始化虚表,这个工作应该在构造函数中完成,所以编译器会默认添加。(2)类(父类)中的成员对象有构造函数。类中的成员对象实际上为派生类,这需要先构造父类再构造本身,这个调用过程需要在构造函数内完成。
析构函数的出现时机
局部对象:作用域的结束处。堆对象:delete处,且一开始调用了析构代理函数,析构代理函数中又调用了析构函数与delete函数。为什么不直接使用析构函数呢?其中一个原因就是又是需要释放的对象不止一个,如果直接调用析构函数,则无法完成多对象的析构。如下所示,就需要代理函数:
1 | Person *objs = new Person[3]; |
需要注意的是,在申请对象数组时,由于对象都在同一个堆空间中,因此32位程序编译器使用了堆空间的前4个字节数据保存对象的总个数。当我们并不使用delete[]而是使用delete来释放对象数组时,当数组元素为基本数据类型时不会出错,但是当元素为存在析构函数的对象时就会出错。这是为什么呢?
我们知道,由于类对象与其他基本数据类型不同,因此对象产生时需要用到代理函数,代理函数根据对象数组的元素逐个调用它们的构造函数,完成初始化过程。代理构造函数如下:
1 | // objs为第一个对象所在堆空间的首地址 |
此函数功能为:循环count次,针对objs数组中的每个对象,都调用构造函数。继续分析,当堆空间销毁时,分析如何调用析构函数的。最后分析得出,在使用delete[]时,函数会先判断是否是对象数组,如果不是则转为正常的delete,如果是,则进行delete[]操作,即先将目标指针减4(因为第一个指针指向的值为对象个数),之后调用析构函数。
补充一点,C语言中的free不负责触发析构函数(与delete不同)。再丰富描述一下以下代码:
1 | Person* getObject(Person* p) { |
这段代码是把person的地址作为隐含参数传递给getObject,在getObject函数内部完成复制构造的过程。而:
1 | person = getObject(); |
由于此代码并不是在person定义时赋初值,因此不会触发person的复制构造函数。这时候会产生临时对象作为getObject的隐含参数,这个临时对象会在getObject函数内部完成复制构造的过程。如果没有对=重载,则赋值属于浅拷贝。语句结束后(遇到分号;),则会将临时对象销毁。
全局对象与静态对象的析构函数由exit -> _execute_onexit_table实现。
全局构造函数的调用是在初始化函数内完成的,在执行每个全局对象构造代理函数时,都会先执行对象的构造函数,然后使用atexit注册析构代理函数。因为析构函数被定义为无参函数,因此在调用析构函数时无法传递this指针,因此编译器为每个全局对象都建立了一个中间代理的析构函数,用于传入全局对象的this指针。
问题:对于全局对象,能不能取消代理函数,直接在main函数前调用构造函数呢?不行,编译器在写__initterm函数时,将各类初始化函数的指针定义为:
1 | typedef void (__cdecl *_PVFV)(void); |
然而,由于构造函数可以重载,因此参数类型、个数无法预知,那么如何保证参数个数匹配,实现栈平衡,最好的办法就是代理函数,代理函数的类型被统一制定为PVFV。
0x10 虚函数
如果有虚函数,那么更好识别构造函数与析构函数。并且定义虚函数之后,即使没定义构造函数,编译器也会提供默认的构造函数。
对象的多态需要虚表和虚表指针完成,虚表指针被定义在对象首地址处,虚函数必须作为成员函数使用。
虚函数的机制
C++中,使用virtual关键字定义虚函数,编译器会将虚函数的首地址保存在虚表中。而虚表指针保存着虚表的首地址。例子如下:
1 | class P { |
如果没有虚函数,P所占空间为4字节,有了虚函数,所占空间为8字节(多4字节的虚表指针)。对象的虚表指针初始化是在构造函数内完成的,在用户没有编写构造函数时,因为必须初始化虚表指针,因此编译器会提供默认的构造函数。
需要注意的是,利用虚表访问虚函数的情况只有在使用对象的指针或引用虚函数的时候才会出现,当使用对象调用自身虚函数时,无需查表访问,直接调用即可。回过头想想,由于虚表指针初始化一般在构造函数中,因此这也可以当作识别构造函数的特征。析构函数中,也进行了类似于初始化虚表指针的操作,但是此操作的作用是:还原虚表指针,让其指向自身的虚表首地址,防止在析构函数中调用虚函数时取到非自身虚表,从而导致函数调用错误。
虚函数的识别
利用虚表可以轻松找到构造函数与析构函数。构造函数查找对象首地址指针有变动的区域即可。而析构函数的对象首地址指针一开始就指向虚表,当然还有一个办法可以识别析构函数:由于全局对象在构造代理函数中,调用了_atexit,而其参数为一个函数指针(就是代理析构函数),_atexit将会把函数放入_execute_onexit_table表中,并在main函数执行结束后倒序执行表中每一个函数。
0x11 从内存角度看继承与多重继承
识别类与类之间的关系
子类可以访问父类的public与protected的数据,对于private数据,虽然无法直接访问,但是子类对象内存结构中仍存有父类的private数据,访问控制权限仅限于编译层面。当子类中没有构造函数/析构函数,父类却有构造函数/析构函数时,编译器会为子类提供默认的构造/析构函数。父类B与子类A的内存结构关系与类A中定义了类B的内存结构一样:
1 | class B{}; |
在构造子类时,子类的构造函数会先运行父类的构造函数(先构造父类)。在销毁子类时,会先运行子类的析构函数,之后运行父类的析构函数。根据这种关系,我们可以找出类之间的继承关系。子类定义时,顺序为:先构造父类,然后按声明顺序构造成员对象和初始化列表中指定的成员,之后时自身的构造代码。
父类中的成员函数并未在子类中定义,但是子类却可以调用,编译器是如何判断子类有调用此函数权限的呢?答案是粉碎法,函数名进行重组后,会包含函数的作用域、原函数名、每个参数的类型、返回值等信息,可以利用这些信息来判断。那么,子类在调用父类函数时,虽然this指针传递的是子类对象的首地址,但是编译器发现子类对象的内存布局与父类对象相同(因为子类对象开头与父类对象一致)。
我们知道,类中的虚表指针可以使用查表+间接调用来运行虚函数,利用此特性可以让父类指针访问不同的派生类。在调用父类中的虚函数时,根据指针指向的对象中的虚表指针,可以得到虚表信息,调用虚函数,即构成了多态。多态的意思就是,针对父类中的函数,不同的子类进行了不同的重写。
当定义了父类定义虚函数的时候,子类对虚函数进行重写,这样的话子类的对象首地址的虚函数指针也会不同。这样的话,我们如果要调用子类的某个虚函数,完全可以把它转为父类,然后直接调用父类中对应的虚函数即可。具体看P402,写的非常清楚。
如果在构造函数中使用虚函数,那么在执行父类构造函数时会将虚表指针改为父类的虚表指针,这样可以防止在子类中构造父类时,父类会根据虚表错误的调用子类的成员函数。
假设类A中定义了成员函数f1和虚函数f2,且类B继承类A并重写了f2。那么,由于先执行A的构造函数,如果此时A的构造函数中调用f1,f1又调用f2,此时就会调用到B的f2,但是此时B还未构造完成,就会导致异常。在析构时,先调用自身的析构函数,再调用成员对象的析构函数,最后调用父类的析构函数。具体例子看P405,例子中,先调用了父类的构造函数,然后设置虚表指针为当前类的虚表首地址,而析构函数中的顺序则时先设置虚表指针为当前类的虚表首地址,然后调用父类的析构函数。
析构函数被定义为虚函数的好处?这样的话就可以使用父类指针保存子类对象的基址,那么使用delete释放空间时,如果没有被定义为虚函数,对于代码Person *p = new chinese;,那么编译器就会调用父类的析构函数,发生错误。如果定义了,那么就会访问虚表并调用对象的析构函数。因此,对于类的继承,父类的析构函数要为虚函数。P411是对release源码的分析。
调用析构函数和释放堆空间(delete)是两回事。 这里于一个问题,对象在执行构造函数时,虚表已经完成了初始化,在析构函数执行时,其虚表指针已经是子类的虚表,为什么编译器还要再析构函数中再次将虚表设置为子类虚表呢?答案:编译器无法预知这个子类以后是否会被其它类继承,如果被继承,那么当前虚表就不对了,需要再次设置一波。
多重继承
当子类有多个父类时,便构成了多重继承关系。子类在内存中首先存放的是父类的数据成员。在多重继承中,存放好多父类的数据成员,数据成员的排列顺序有继承父类的顺序决定,从左向右依次排列。因为有多个父类,因此子类在继承时也将他们的虚表指针一起继承了过来,也就有了多个虚表指针。这些虚表指针将在子类对象转换为父类指针时使用,每个虚表指针对应一个父类。
单继承类的特点:类对象占用的内存空间只有一份虚表指针;只有一个虚表;虚表中保存了类中虚函数的地址;构造时先构造父类,再构造自身,且只调用一次父类构造函数;析构时先析构自身,再析构父类,且只调用一次父类析构函数。多重继承类特点:保存多个虚表指针,多个虚表,…。和类中有对象的情况很相似。
抽象类
抽象类,我的理解是啥也没有,很抽象。抽象类需要配合虚函数使用,在虚函数声明结尾处添加=0,就会变为纯虚函数。纯虚函数是没有实现只有声明的函数,它的存在是为了让类具有抽象类的功能,让继承于抽象类的子类都有虚表。如下所示:
1 | class Ac{ // 抽象类 |
在其汇编代码中,由于纯虚函数没有实现代码,所以在虚表中也没有首地址,为了防止误调用,需表中保存的纯虚函数首地址替换成__purecall,用于结束程序。这可以作为识别抽象类的特征,即是否有__purecall函数。
虚继承
菱形继承是最复杂的对象结构,其含义为:类D继承自B与C,B与C继承自类A。此时,D存放B与C的数据,而B与C存放A的数据,这会造成D存放的数据是有冗余的(多份A)。为了解决这个问题,虚继承应运而生,这使得在D中只需保留一份A的成员。虚继承是在B和C继承A的时候使用virtual的方式。
看D的内存结构,如P431所示,其中B与C都存有虚基类偏移表,由于保存类A的信息。其中,虚基类便宜表有两项:(1)虚基类偏移表所属类对应的对象首地址相对于虚基类偏移表的偏移值。(2)虚基类对象首地址相对于虚基类偏移表的偏移值。对于vs与clang而言,在D的构造函数中,需要先构造父类,由于B和C有共同的父类,为了防止重复构造,需要使用构造标记来防止此问题。但是对于gcc而言,编译器使用父类构造代理函数来解决此问题。
由于精力有限,所以并未将汇编代码记录到笔记中,书中已写的非常详细,如有忘记,wd记得查阅。
0x12 异常处理
由于C++标准中并未规定异常处理的流程,所以不同编译器的异常处理代码也不同。gcc、clang的异常处理代码取决于异常库,此章主要使用vs编译器,其与seh机制很相关,正好复习一波。
异常处理相关知识
C++中,try负责监视异常,throw负责抛出异常,catch用于捕获异常并处理。异常处理是由编译器于操作系统共同完成,不同的操作系统环境下的编译器堆异常处理的分派过程是不同的。VS C++在处理异常时会在具有异常处理功能的函数入口处注册异常回调函数,当函数内有异常抛出时,会执行已注册的异常回调函数。所有的异常信息会被记录在表格中,异常回调函数根据表格中的信息进行异常的匹配处理工作。记录异常信息的表格结构如下:
1 | FuncInfo struc |
表格中,maxState记录了异常需要展开的次数,展开时需要执行的函数由UnwindMapEntry表结构记录。UnwindMapEntry记录了好多析构函数的地址。而TryBlockMapEntry表则用于判断异常产生于哪个try块中,还记录了catch块的信息。具体而言,每个catch块都对应一个_msRttiDscr表。此表中的关键数据结构有pType、CatchProc、dispCatcgObjOffset,在抛出异常对象时,需要复制抛出的异常对象信息,而dispCatcgObjOffset用于定位异常对象在当前EBP中的偏移位置,CatchProc用于保存catch块的地址,pType用于保存异常的匹配信息记录(异常名称等)。
以上是处理异常时所需的表格信息。抛出异常时,同样需要很多表格。书中写的很详细,具体看P450,其中图13-11总结的很好。
异常为基本数据类型的处理流程
1 |
|
其反汇编流程为:压入异常回调函数,用于在产生异常时接收并分配到对应的异常处理语句块中。异常回调函数__ehhandler$main调用了__CxxFrameHandler,再调用了_InternalCxxFrameHandler。_InternalCxxFrameHandler主要完成了异常类型的检查,最后调用查找try与catch的FindHandler。其中,FindHandler通过3层嵌套的for循环,完成了try与catch的检查,利用TypeMatch函数完成了对异常匹配的判定并得到了结果,又调用了CatchIt完成了异常处理(包括产生异常对象、析构try中的对象,跳转到对应的catch地址、返回到异常catch块的结尾地址)。
异常为对象的处理流程
与基本数据类型不同的是,当异常为对象时,需要重点关注CatchIt函数,其具体功能为:(1)使用BuildCatchObject函数对抛出的异常对象进行处理,此函数共有4种不同的对象产生方式,分别为指针直接赋值、简单对象复制、有虚表基类复制构造函数、无虚表基类复制构造函数。(2)使用__FrameUnwindToState进行处理,具体而言,将FuncInfo表结构与EHRegistrationNode结构中记录的相关栈展开信息进行比对判断,以检索展开过程中调用的函数,当栈展开与生产对象的流程执行完毕后,调用CallCatchBlock完成catch块的调用工作,最后由_JumpToContinuation跳转回catch结束的地址。
异常识别处理
异常处理分析的流程如下步骤所示:
(1)在函数入口处设置异常回调函数,回调函数先将eax设置为FuncInfo的地址,然后跳往__CxxFrameHandler。
(2)异常的抛出由__CxxThrowException完成,该函数使用的参数有两个,一个是throw的参数指针,一个是抛出信息类型的指针(ThrowInfo *)。
(3)在异常回调函数中,可以得到异常对象的地址、对应ThrowInfo数据的地址、FuncInfo的地址。根据异常类型,进行try块的匹配工作。若没有找到try块,则析构异常对象,返回ExceptionContinueSearch,继续下一个异常回调函数的处理。当找到了对应的try,则通过TryBlockMapEntry中的pCatch找到catch信息表,用ThrowInfo中的异常类型遍历查找匹配的catch块,比较关键词名称(整形为.h,单精度浮点为.m),找到有效的catch块。
(4)执行栈展开操作,产生catch块中使用的异常对象。正确析构生命周期已结束的对象,并跳转到catch块,执行catch代码,最后调用_JumpToContinuation返回所有catch语句块的结束地址。
书中给了一个例子,看P464。
x64异常处理
此时,VS编译器不再采用在函数中注册SEH完成异常处理的方式,而是将异常信息表存放在PE文件的.pdata节中。这个节中记录各种异常函数的相关信息(以RUNTIME_FUNCTION结构体保存)。对于动态生成的函数,必须使用Rt1InstallFunctionTableCallback将此信息提供给操作系统,否则将导致不可靠的异常和进程调试。
RUNTIME_FUNCTION结构体中的UnwindInfo结构为展开数据信息结构,记录函数对堆栈指针的影响以及非易失寄存器保存在堆栈上的位置。这里没太看明白,还给了个例子,具体看P481。
0x13 PEiD的工作原理分析
PEiD是PE文件分析工具,和die差不多,它不仅可以分析出PE文件的编译器版本,还可以在PE文件经过加壳处理后,分析出相应的加壳版本。这里只是看了分析流程,没跟着走。其分析流程为:
(1)读取分析文件到内存中,分析出相关PE文件的信息,然后保存。
(2)检查OEP,计算地址偏移并修正OEP。
(3)检查OEP地址的合法性。
(4)将OEP的机器码与特征码进行比较。检查分析文件是否存在.rdata节,并根据分析结果获取对应处理函数所在数组的下标并保存。
(5)循环调用处理函数,在处理函数中再次检查,最后显示编译器版本。
书中还给出了一个例子,以欺骗PEiD是VC6++的程序,具体见P496。
0x14 调试器Ollydbg的工作原理分析
Ollydbg的断点功能是基于异常处理实现的,断点类型有:INT3断点、内存断点、硬件断点。
INT3断点是修改机器码为0xCC制造异常,Ollydbg捕获此异常并等待用户处理。Ollydbg实现INT3断点的主要流程:
(1)检查INT3断点是否记录在断点信息表中。
(2)将INT3断点信息记录到表中。
(3)记录INT3断点处的机器码信息。
(4)将INT3断点处的机器码修改为0xCC,并设置断点记录表。
INT3断点属于执行断点,只能打到执行代码中,对于数据的读/写操作,则需要内存断点来完成。内存断点的类型与特征码:0x7E/0x23(访问断点)、0x7F/0x24(内存写入断点)、0x80/0x25(清除内存断点)。其大概流程如下:检查断点所处的内存位置,并通过修改内存属性制造异常信息,然后由Ollydbg捕获并处理,从而实现断点的功能。在设置了内存属性后,会对内存断点结构执行赋值操作。内存属性的修改通过VitualQuery与VirtualProtectEx完成,通过前者获取原内存页的属性,以便于还原;通过后者修改内存页的属性,以制造内存访问异常。
INT3与内存断点是通过软件完成的,而硬件断点是通过CPU中的调试寄存器实现的,断点长度只能为1/2/4。Ollydbg使用了保存硬件断点信息的结构表,记录每个硬件断点的相关信息。其具体实现过程主要依赖GetThreadContext与SetThreadContext,前者获取当前线程中寄存器的信息,后者设置当前线程中寄存器的信息来对调试寄存器完成修改。
异常处理机制
前面3种断点都是通过异常使得ollydbg进行捕获,从而实现断点功能。内存断点的触发是内存访问类的错误,其处理流程为:
(1)得到线程信息,跳转到相应的异常处理分支中。
(2)若得到线程信息,则根据线程信息的eip进行赋值,否则根据异常地址进行赋值。得到异常处模块的信息并反汇编,进行检查。若模块为自解压(SFX)模式,则进行相应检查与错误处理。
(3)检查内存断点是否在kernel32.dll中,弹出提示窗口并去除断点。
(4)调整优先级并退出。
硬件断点的捕获过程是由调试寄存器完成的,因此ollydbg并没有捕获处理过程。
加载调试程序
Ollydbg通过CreateProcess以调试模式开启新进程。在此之前,需要进行一些检查工作,例如调试进程路径的获取、是否为合法的调试文件等信息,这是通过OpenEXEfile完成的。具体而言,首先根据文件后缀名判断是否为快捷方式,如果为快捷方式则会找到此快捷方式的对应程序的路径,接下来检查DOS头与NT头分析是否是合法的PE文件。之后,当调试的文件是DLL动态库时,使用自带的LoadDll.exe加载dll文件。
0x15 总结
用处有,但不是特别大。其中重点就是除法、虚函数、构造与析构。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!