geekpwn2023
巅峰极客挑战赛2023-逆向&misc
此次比赛复盘,m1_read、Misc-一起学生物是根据wp来做的,而goRe-U与ezlua则是自己尝试做一做。总的来说,里面好多题都没见过,尤其是m1_read与ezlua,这两道题让我发现自己的脚本能力(frida、gdb、z3等)还是比较差。继续加油吧。
0x00 m1_read
这个题做完调试文件给删了…所以没在github上同步更新。
1 | 这个看起来是一个门禁系统的写卡程序,不过开发人员只写了半天并没有搞完,此外还有一个写卡程序相关的数据包 |
比赛中,这道题我看了一天。最后才知道是W&M的师傅出的题。
菜鸟的挣扎
这是一道RFID的门禁卡程序,分别给了m1_read.exe与out.bin,其中out.bin是RFID卡中存储的数据,m1_read.exe则是读写RFID卡的工具。
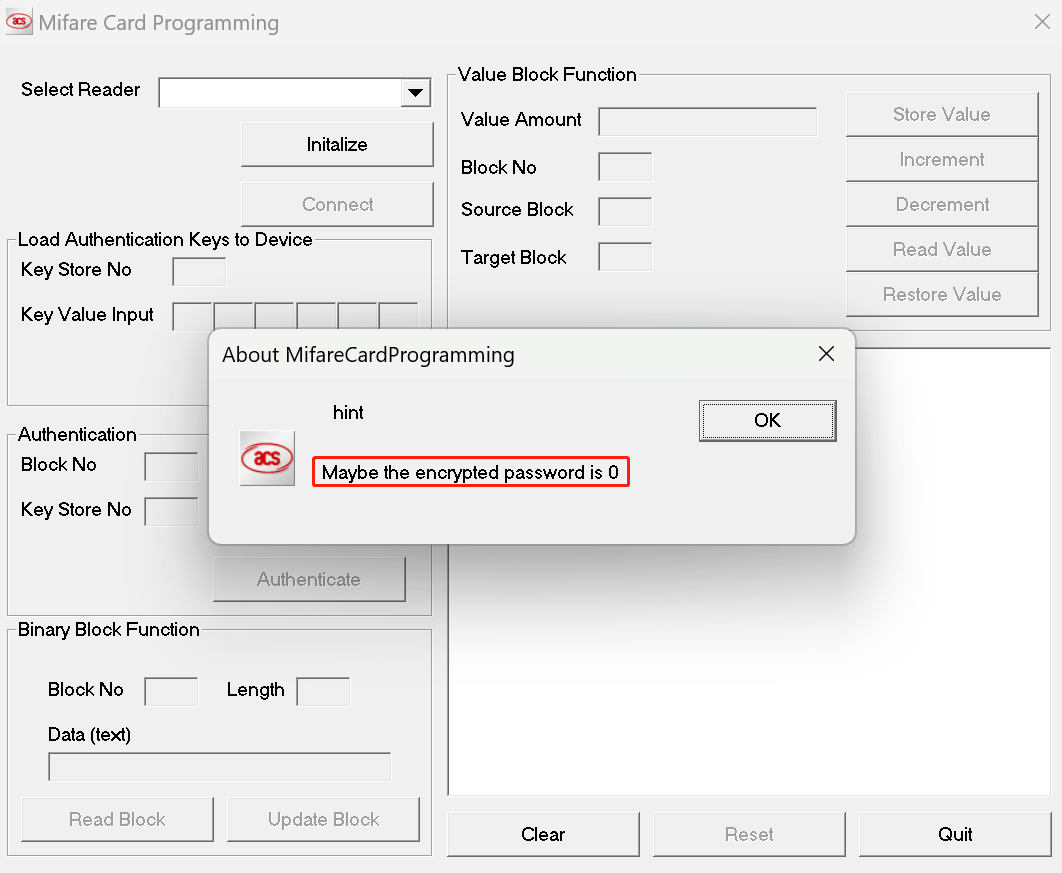
那天我的发现有:
(1)上图的hint。
(2)RFID的数据存储结构如下:

RFID卡共有16个扇区,每个扇区都有4个区块,共有1024个字节。
(3)RFID的数据块使用crypto-1算法加密(存疑),链接为:crypto算法
大爹的wp&自己的探索
链接为wp。其中,我并不理解为什么要用到AES加密,猜测是出题人将m1_read.exe魔改了,在其中读入读出数据时采用了加密处理。所以打算现在网上找到原始版本的程序。
找到了32位的此程序,链接如下:链接,这是youtube的链接,里面有相关的下载地址。关键是bindiff还出问题了,在ida7.7上总是有问题,最后降成ida7.5+bindiff6才行。然鹅,比较一看,根本木有重合。
那这样的话,只能自己看m1_read.exe了。
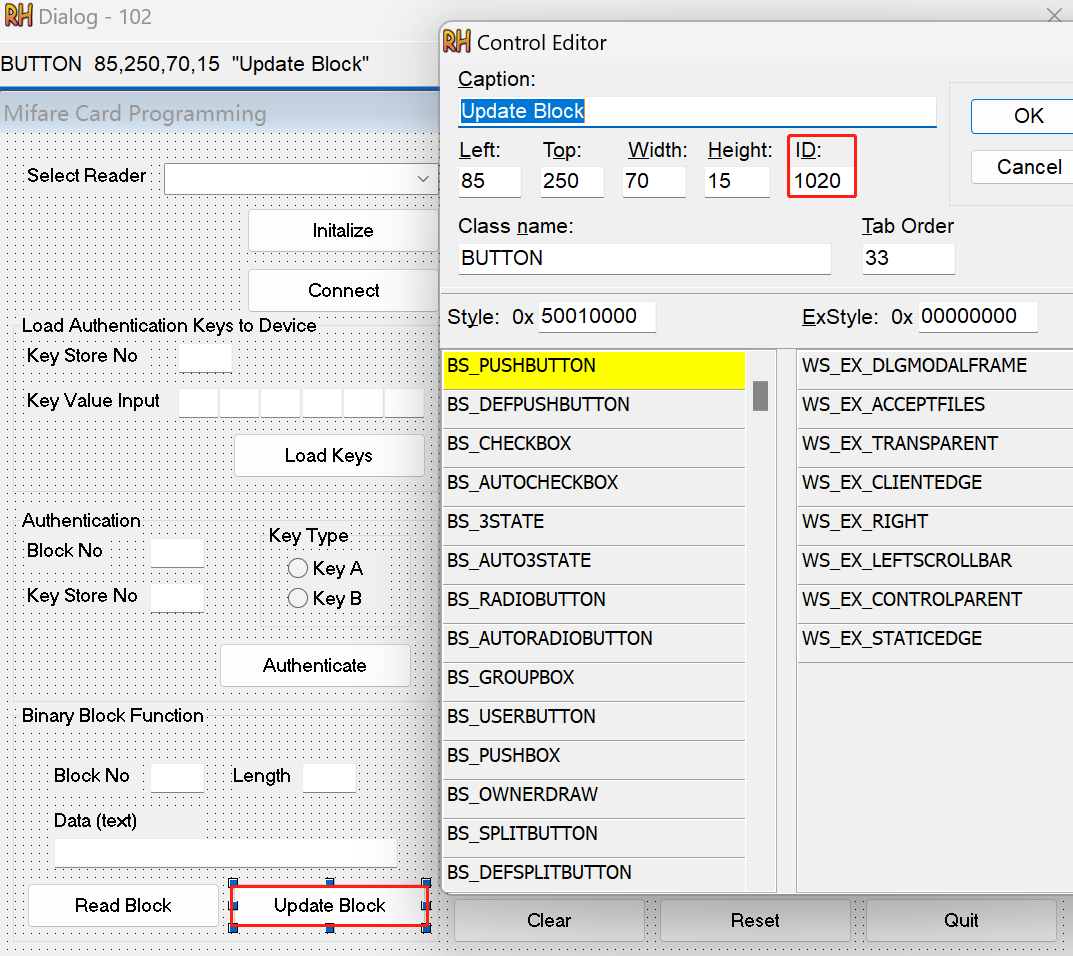
通过ResourceHacker获得UpdateBlock控件的ID(因为要写文件),可以发现ID=0x3FC。在IDA中找0x3FC,并筛选出rdata段中的条目,并将其转为AFX_MSGMAP_ENTRY结构体。最后可以获得消息映射表:
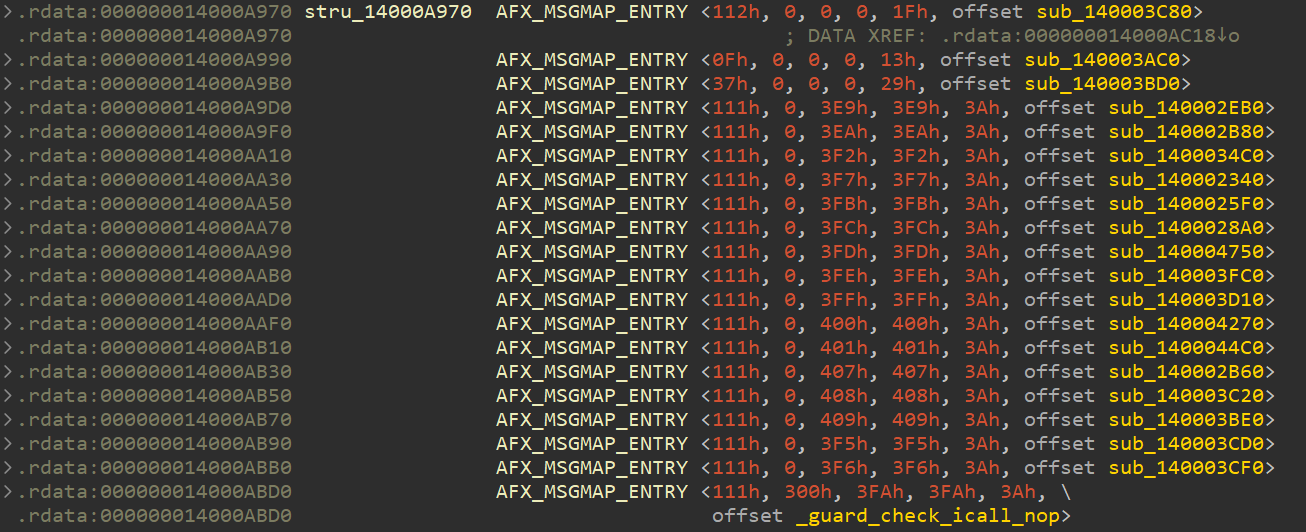
最后,可以定位到updateBlock对应的函数:sub_1400028A0。通过分析此函数,如下所示,其中hint函数比较重要,它控制着结果的输出:
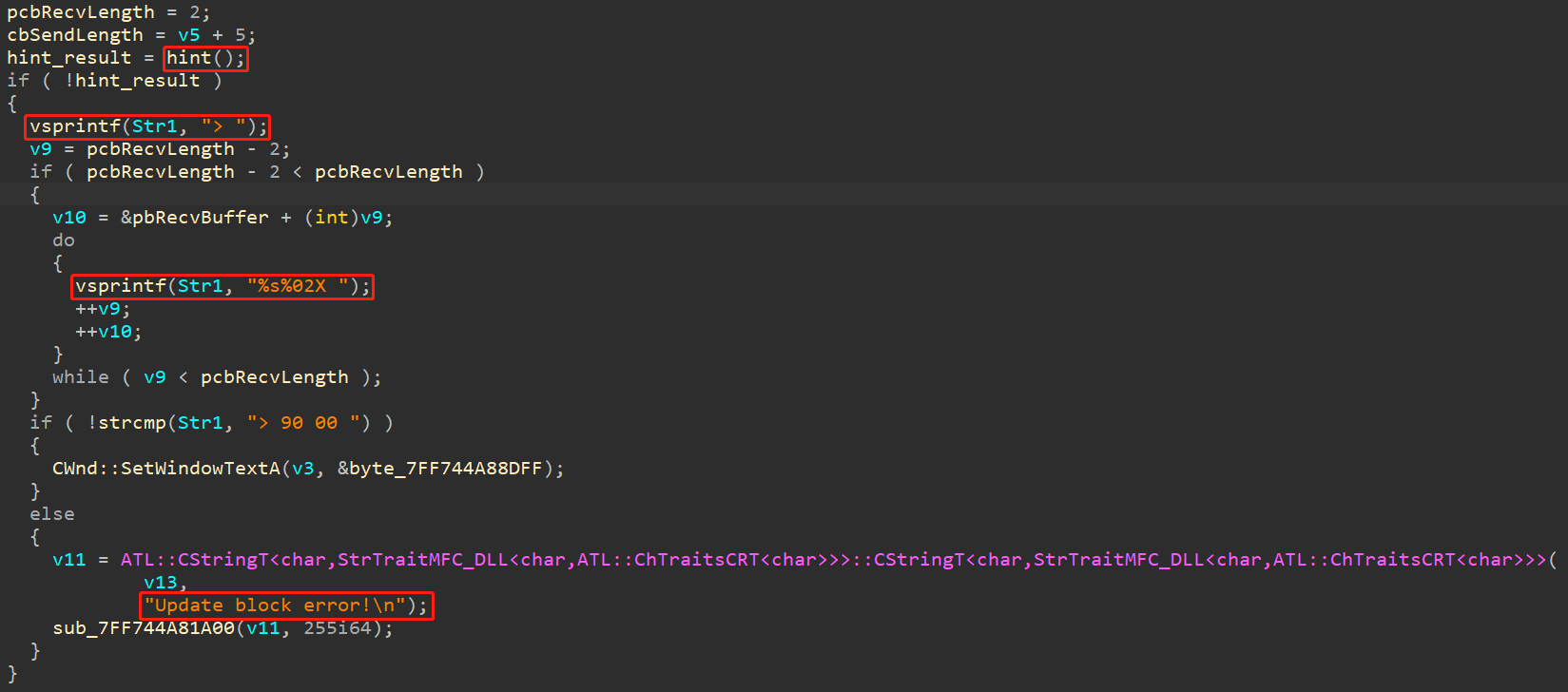
于是跟进到hint函数(需要说明一下,这里我找到hint函数的过程有很大一部分原因是根据AES函数分析调用反推出来的,但是正常分析时,也可以分析到此函数,只不过花费的时间可能长一些),可以发现:
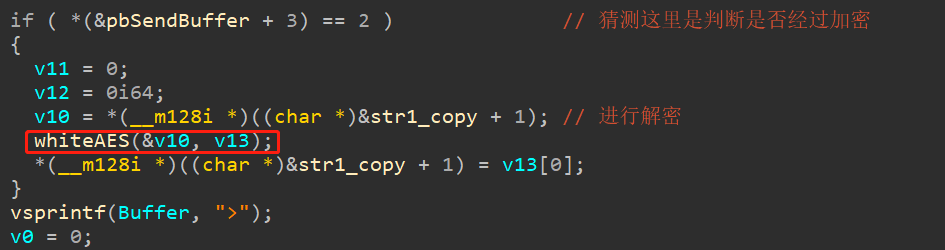
pbSendBuffer是向卡中写入的数据,且str1_copy与pbSendBuffer挨得很近,猜测是将pbSendBuffer与str1_copy一块写入到卡中。接下来,我们再来分析whiteAES函数(此函数名是我后来加的)。
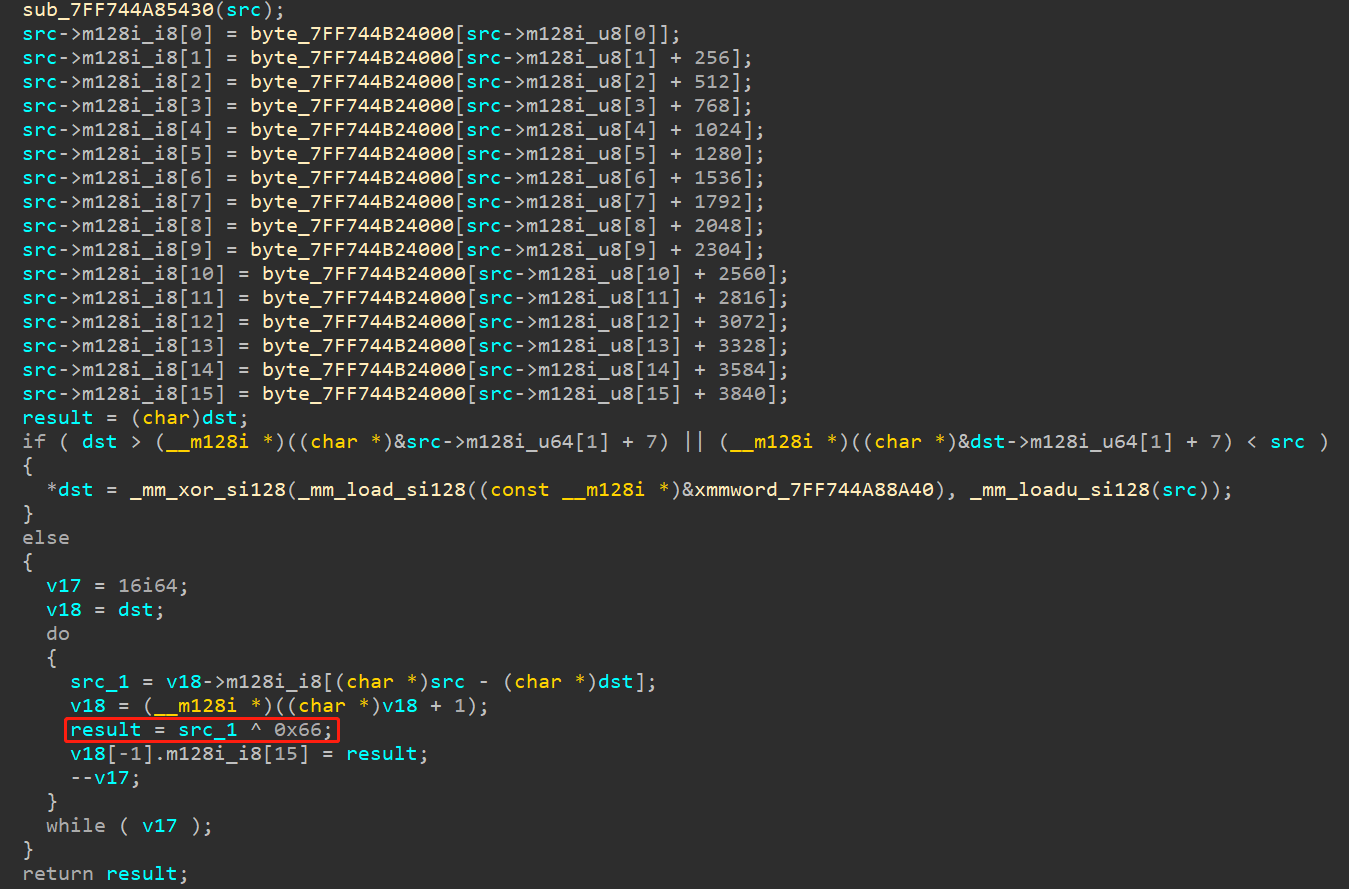
由上图可以发现,先经过了一系列操作,最后经过异或,得出结果。
看了大爹的wp,发现这一系列操作是AES白盒,目的是为了掩盖密钥。大爹的思路是:
(1)使用frida(windows下使用frida,技能点get),随机生成数据并经过whiteAES,得到一系列数据。
1 | # windows exe hook |
(2)将得到的数据异或66,就得到白盒操作后的数据。
(3)使用phoenixAES,例如第3个例子处理数据,可以得到第N轮的密钥。再使用Stark反推出第1轮的密钥,为00000000000000000000000000000000。这一步其实有Hint,大爹没看到。
(4)用拿到的密钥解密out.bin中的数据:0B987EF5D94DD679592C4D2FADD4EB89 ^ 0x66。就可以得到flag{cddc8d28dabb4ea9}。
0x01 g0Re-U
1 | gogogo |
发现是UPX的壳。工具脱壳(UPX Unpacker)失败,打算动调找OEP。
苦逼动调upx
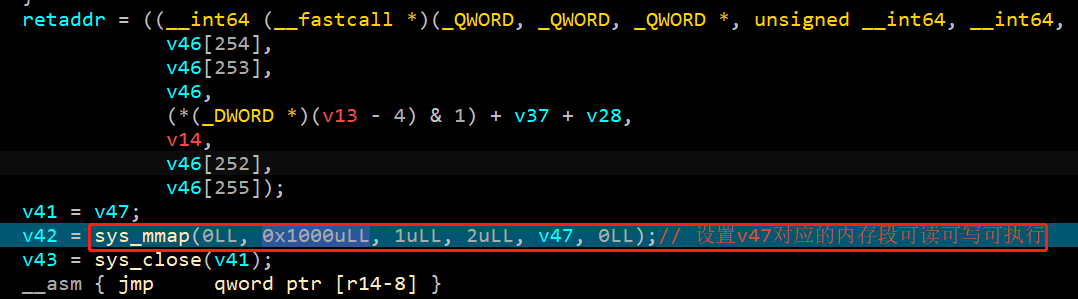
将上图所示内存dump下来,发现是ELF头部以及各种Go表,说明还未解密完。
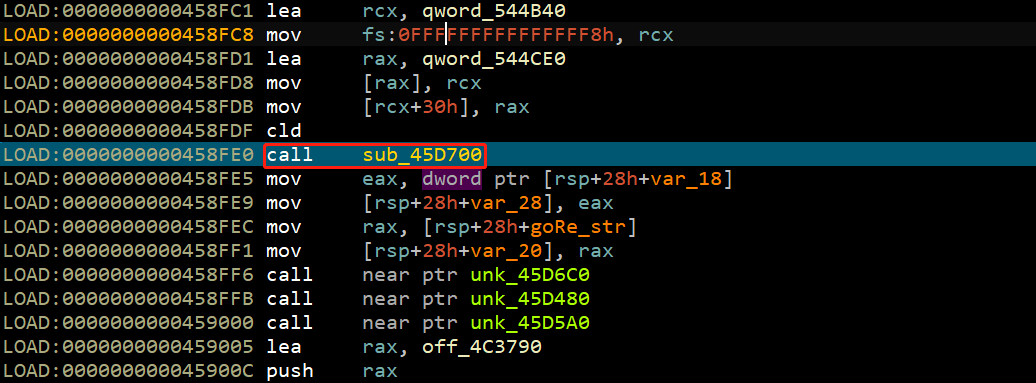
sub_45D700貌似是一个解密函数,用于对上上图所示的内存进行解密。
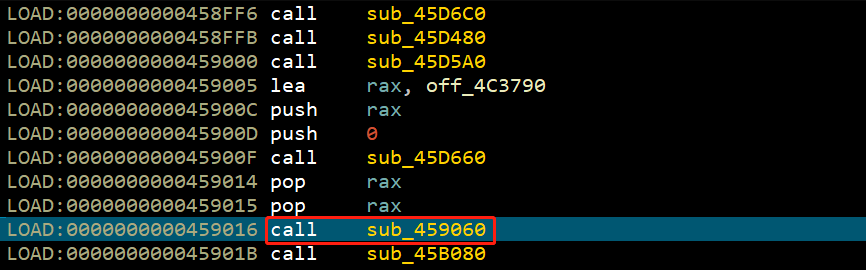
F8上图出现”input flag”字样。之后跟进到sub_434C00函数,定位到sub_434CA0函数,发现:
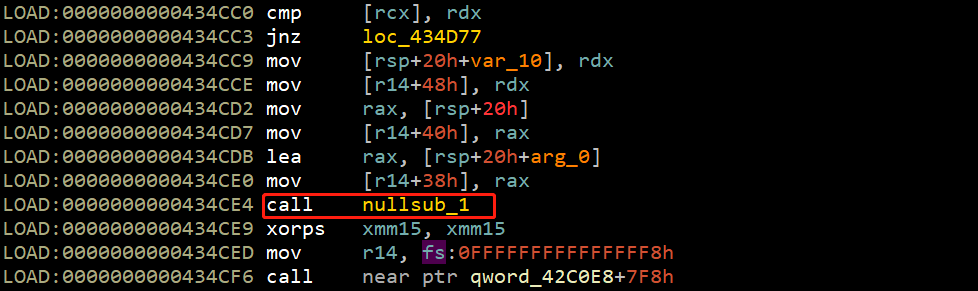
记得之前Go程序的Start入口有这个函数,猜测我已找到OEP。将模块0x400000-0x483000 dump出来,因为这是goRe原始模块的文件。如下图所示:
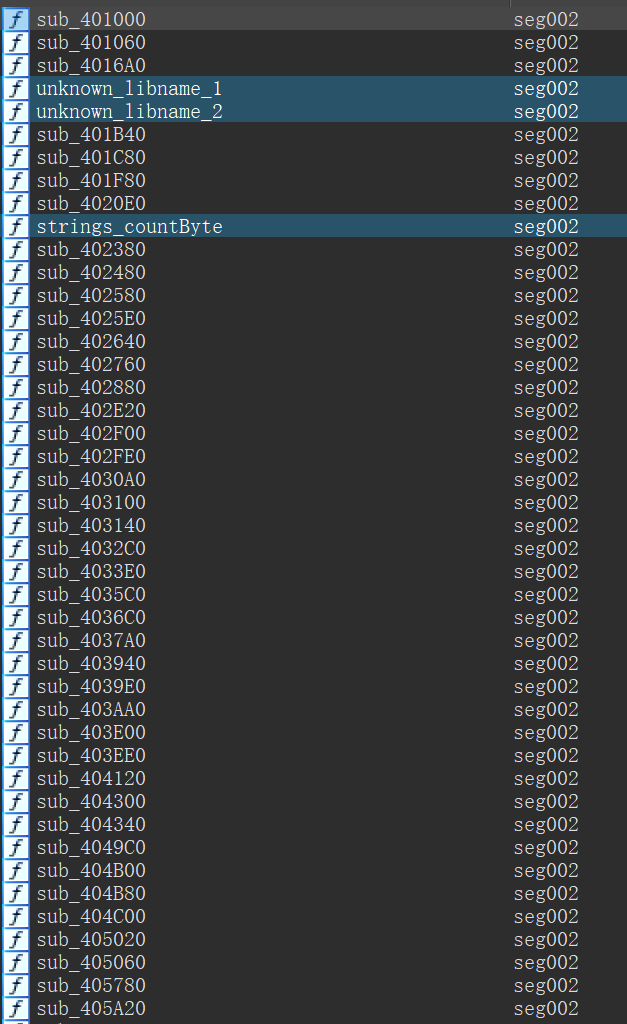
但是go_parser找不到first_moduledata,所以无法解析。那怎么办?
一筹莫展之际,发现文件中有函数aes加密,如下图所示:
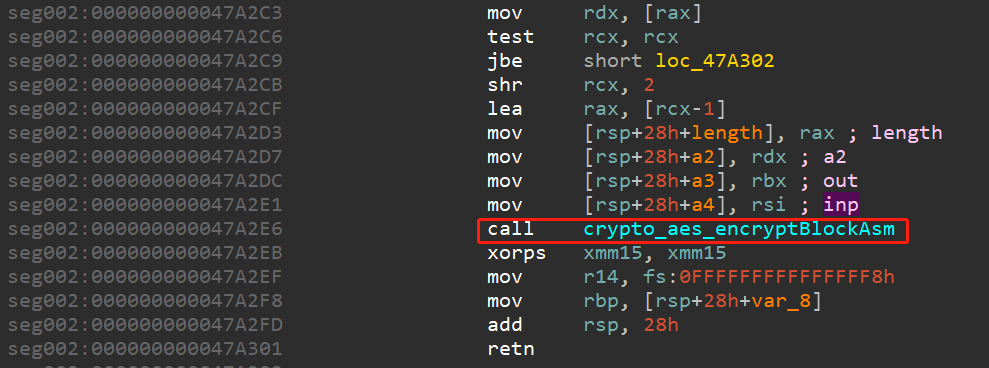
动态调试,发现为10轮AES加密。加密的明文是输入的字符串,扩展为16字节。加密密钥为:wvgitbygwbk2b46d。那么就可以猜测,本题是明文加密然后与某密文比较。
如何找到密文呢?又一次一筹莫展之际,发现,如果将0x400000-0x578580dump出来,就可以正常运行go_parser脚本。这是偶然发现的,因为经过调试发现解密过程还包括0x483000后的内容。
程序分析
经过分析,此程序共有3步:
(1)输入input,使用AES加密,密钥为:wvgitbygwbk2b46d,iv为0。(需要注意的是,这里的加密是按16字节作为一个Block加密)
(2)将加密结果使用Base64转换,Base64码表为:
1 | 456789}#IJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123ABCDEFG |
(3)将转换后的结果做如下处理:
1 | (step2_result[i]^0x1A)+key[i&0xf] |
最终可以得到wp:
1 | #!/usr/bin/env python |
0x02 ezlua
1 | luajit 5.1 |
之前没做过lua的题,lua是大多嵌入式环境使用的脚本语言,好多游戏也是Lua写的。64位文件。
Hint为luajit,说明这是用针对lua5.1版本的jit编译器编译的(代码转为机器码)。luajit是保护lua代码的一种方式,可以使用luajit-lang-toolkit进行反汇编。
使用luajit对dump出的字节码进行反汇编,但是一直显示不兼容。
准备看wp了,一直没找到兼容的版本啊。
但是,今天看了一天lualualua,感觉和picStore那道题很像,只不过是luajit版本的。因此,很容易想到,是在加载lua字节码,即LuaL_loadbuffer函数中做了手脚,如下所示:
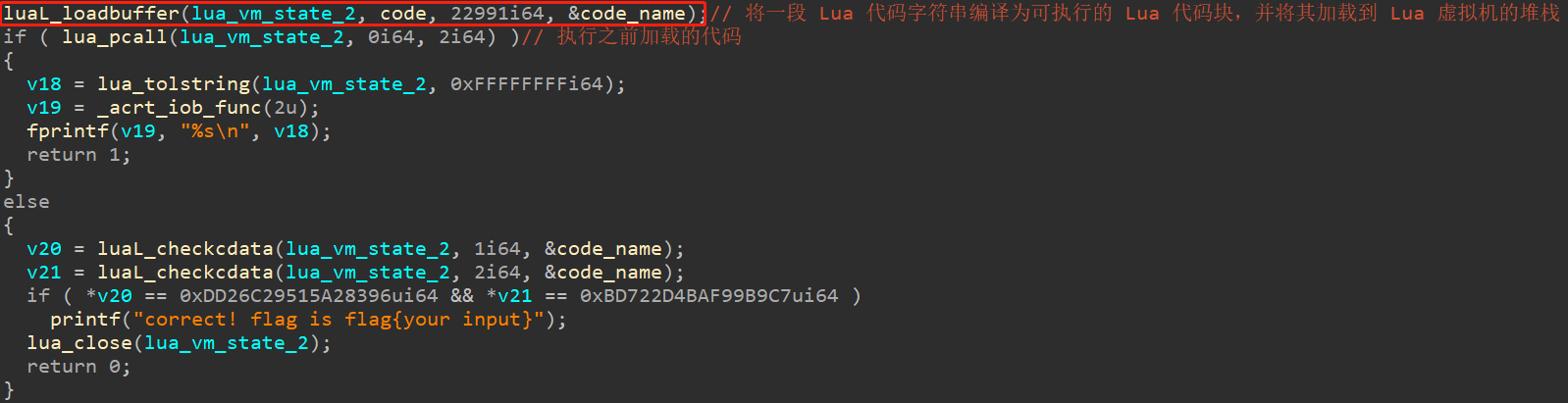
luaL_loadbuffer函数分析
首先,找到luaL_loadbuffer的源码,与反汇编后的代码比较:
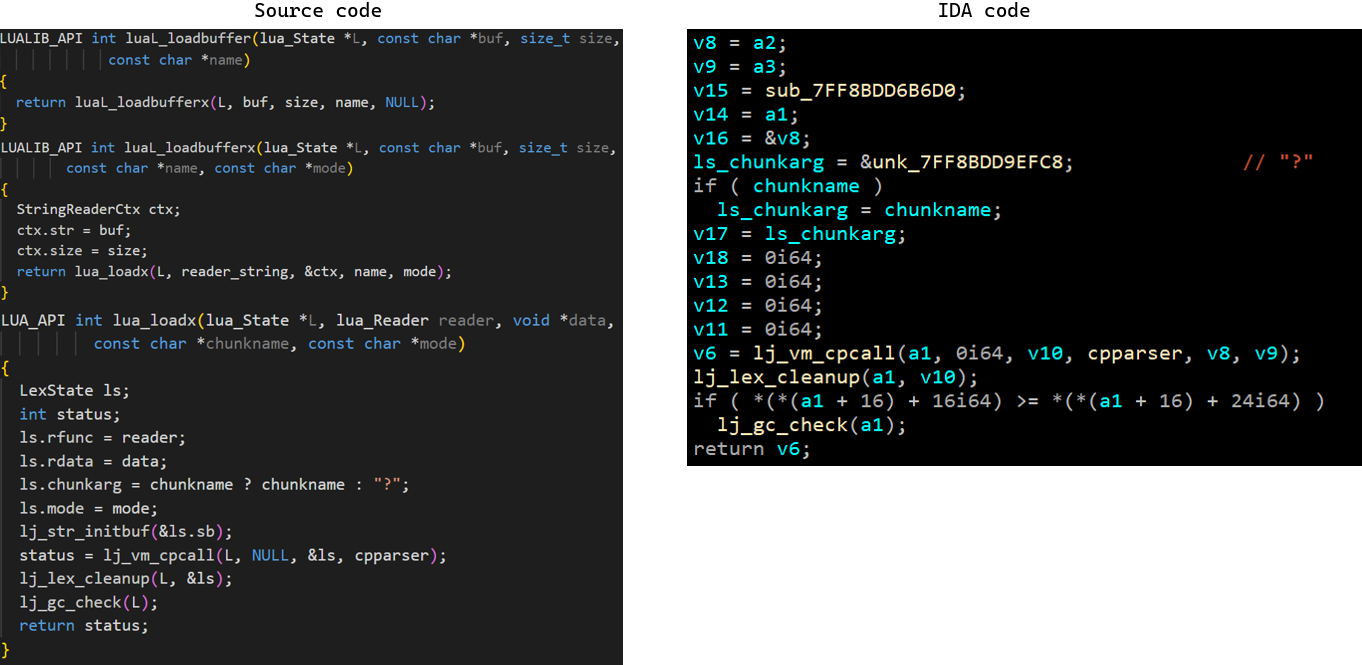
容易发现,IDA反汇编结果实际上是将lua_loadx加载进了luaL_loadbuffer函数中(根据字符”?”)。因此,可以根据源码对函数进行命名。其中,cpparser作用是将 Lua 源代码解析为 Lua 函数,并将其保存在 Lua 虚拟机中,以供后续执行,于是跟进此函数:
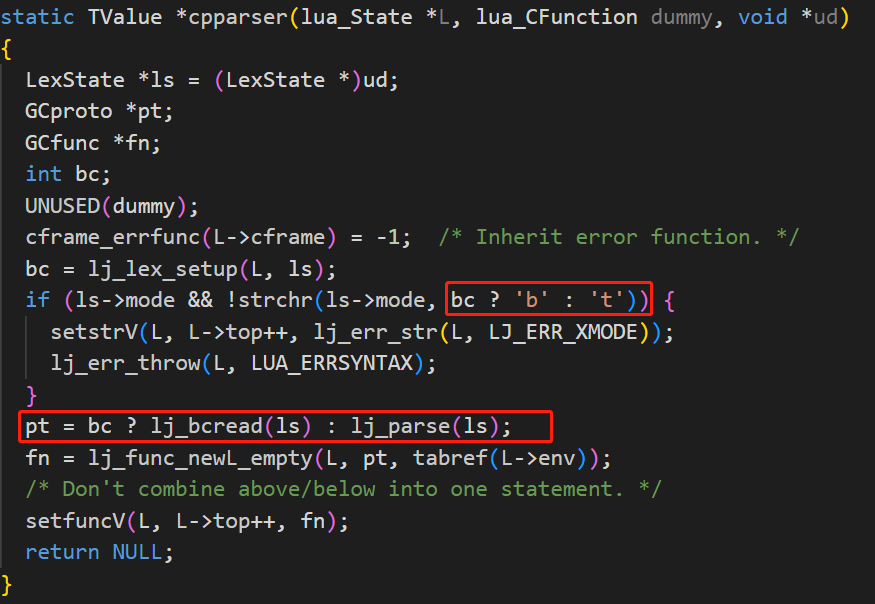
在此判断加载的Buffer是binary文件还是text文件,由于是binary文件,于是跟进lj_bcread,与源代码比较如下:
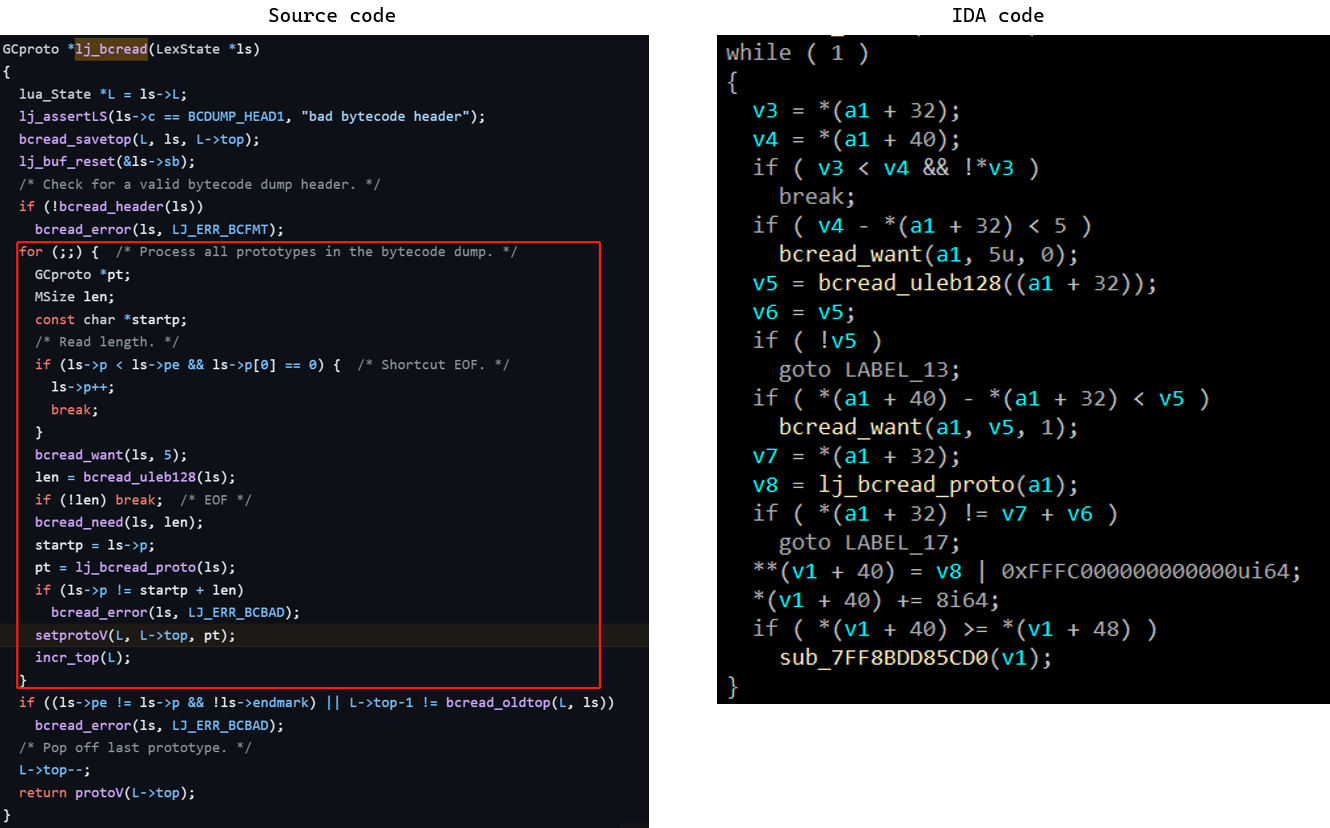
跟进lj_bcread_proto,发现此函数可能被魔改了。经过分析,发现下左图红框的两行代码魔改为下右图红框的代码:
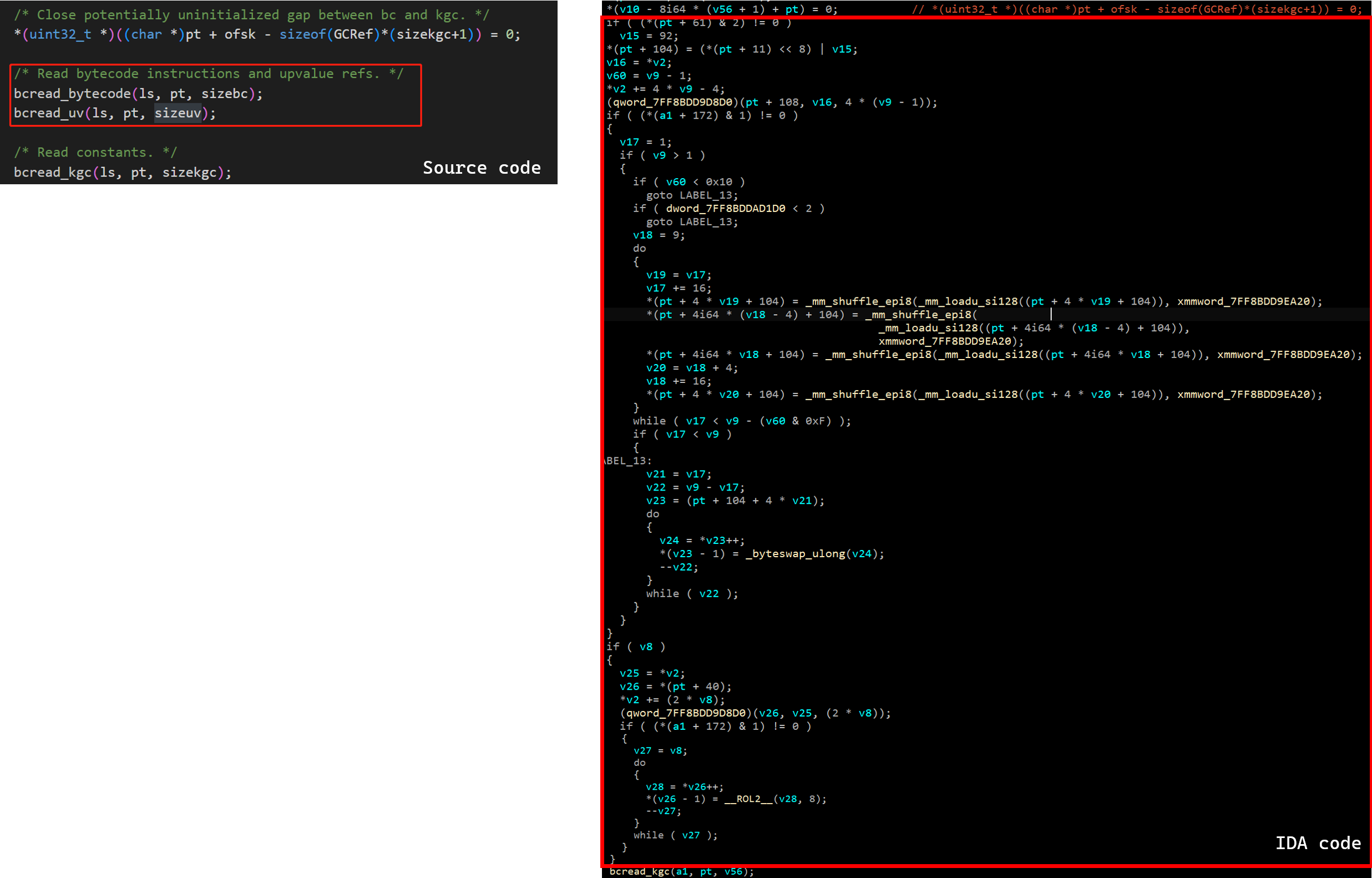
进一步分析,发现是在lj_bcread_proto中的bcread_bytecode函数中动了手脚,如下图所示:

源代码中,bc[i]为4字节,lj_bswap函数作用是改变字节序并返回。发现并没有魔改,寄!看来和picStore还不一样。
佬的wp
对输入打内存断点。若输入1123456789112345678911234567891123456789,则在luajit字节码区域为:
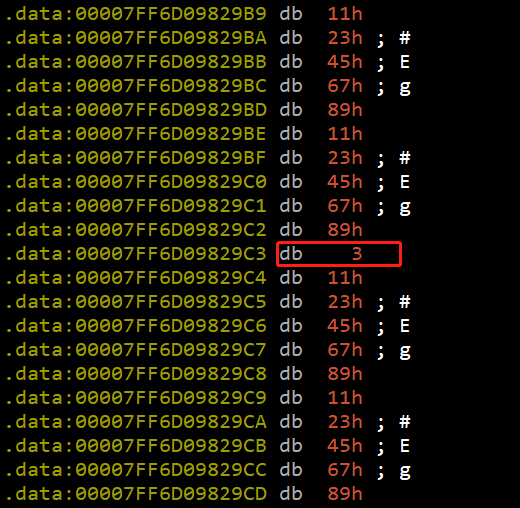
中间有0x3。对输入打断点,卡在了bcread_uleb128中,回溯发现在bcread_kgc函数中,这是一个加载常量的函数,如下所示:

在此补充一下uleb编码:uleb通过字节的最高位来决定是否用到下一个字节。如果最高位为1,则用到下一个字节,直到某个字节最高位为0或已经读取了5个字节为止。对于函数bcread_uleb128而言,它读取1-5字节。
其实,能正常反编译,就是自己没找对版本和x86/x64的而已。具体看luajit常用的反编译方法。
Step1:dump出luajit字节码,使用bt模板解析,但是在解析常量时报错。猜测原因是:输入也会改变字节码的值,具体是改变字节码中存储常量的部分。因此,要输入符合uleb128格式的输入,再dump字节码。此时输入可以为:9999999911999999991199999999119999999911。再解析,便成功了。发现Luajit版本为2,如下所示:
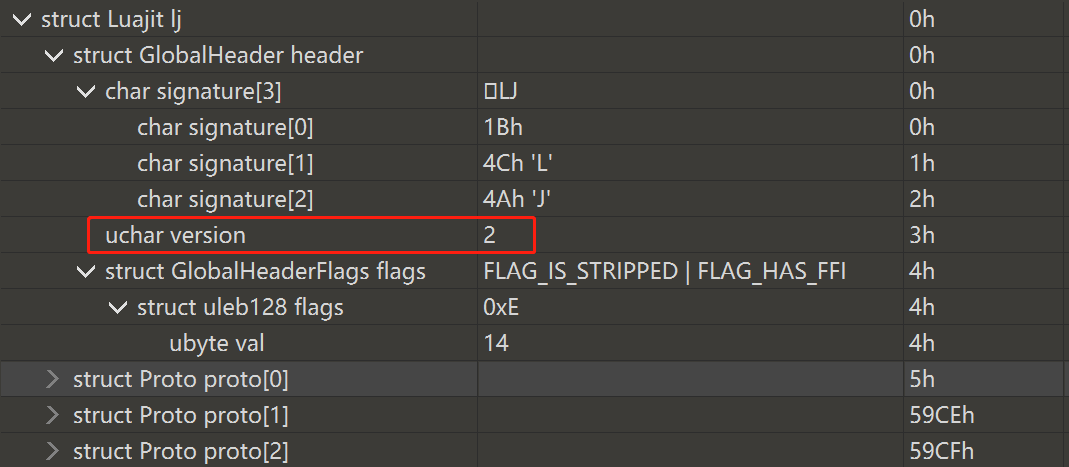
Step2:可以发现这是64位的luajit字节码文件,原因如下:第5字节为0x0E=b1110,其中采用2-slot frame info` 模式(FLAG_FR2 = 0b00001000),后者是 64 位引入的新特性。
Step3:目前,反编译luajit字节码文件的工具有ljd与luajit-decomp,由于ljd并未找到x64版本的,所以使用luajit-decomp进行反编译,具体步骤见luajit反编译。最后使用luajit-decompiler进行反编译,但是出错了,如下所示:
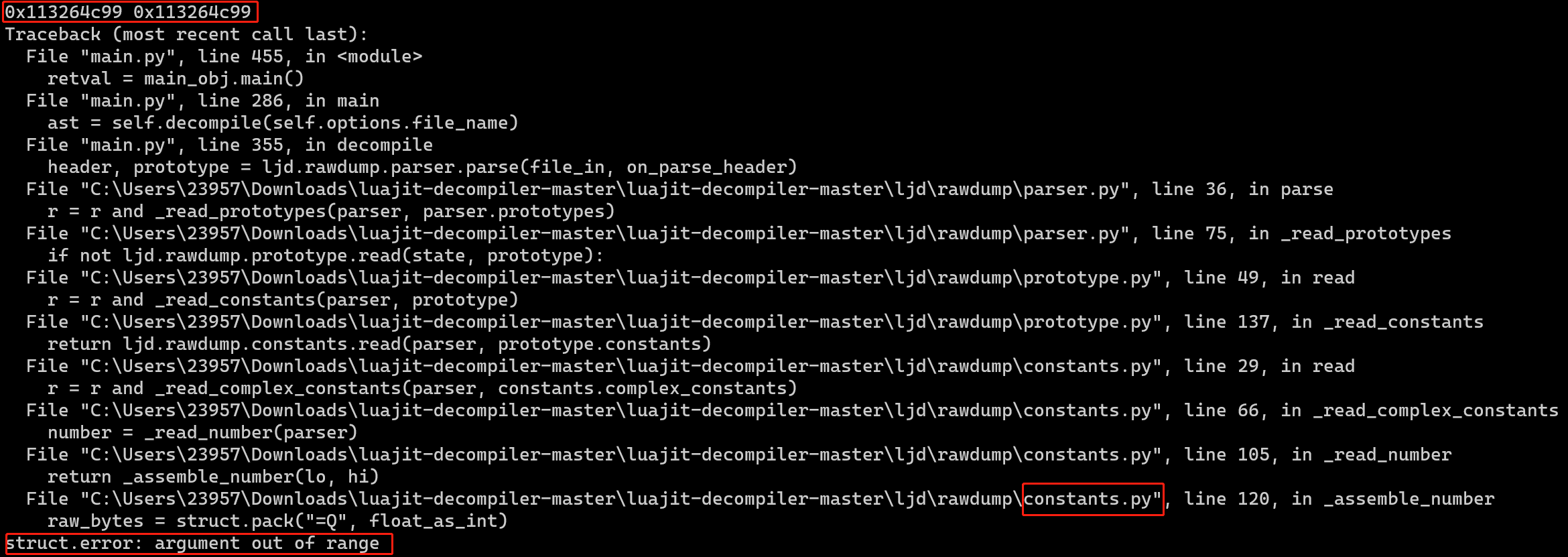
猜测是输入的最后使用11,多占了1字节,于是将输入改为9999999901999999990199999999019999999901。还是报错:
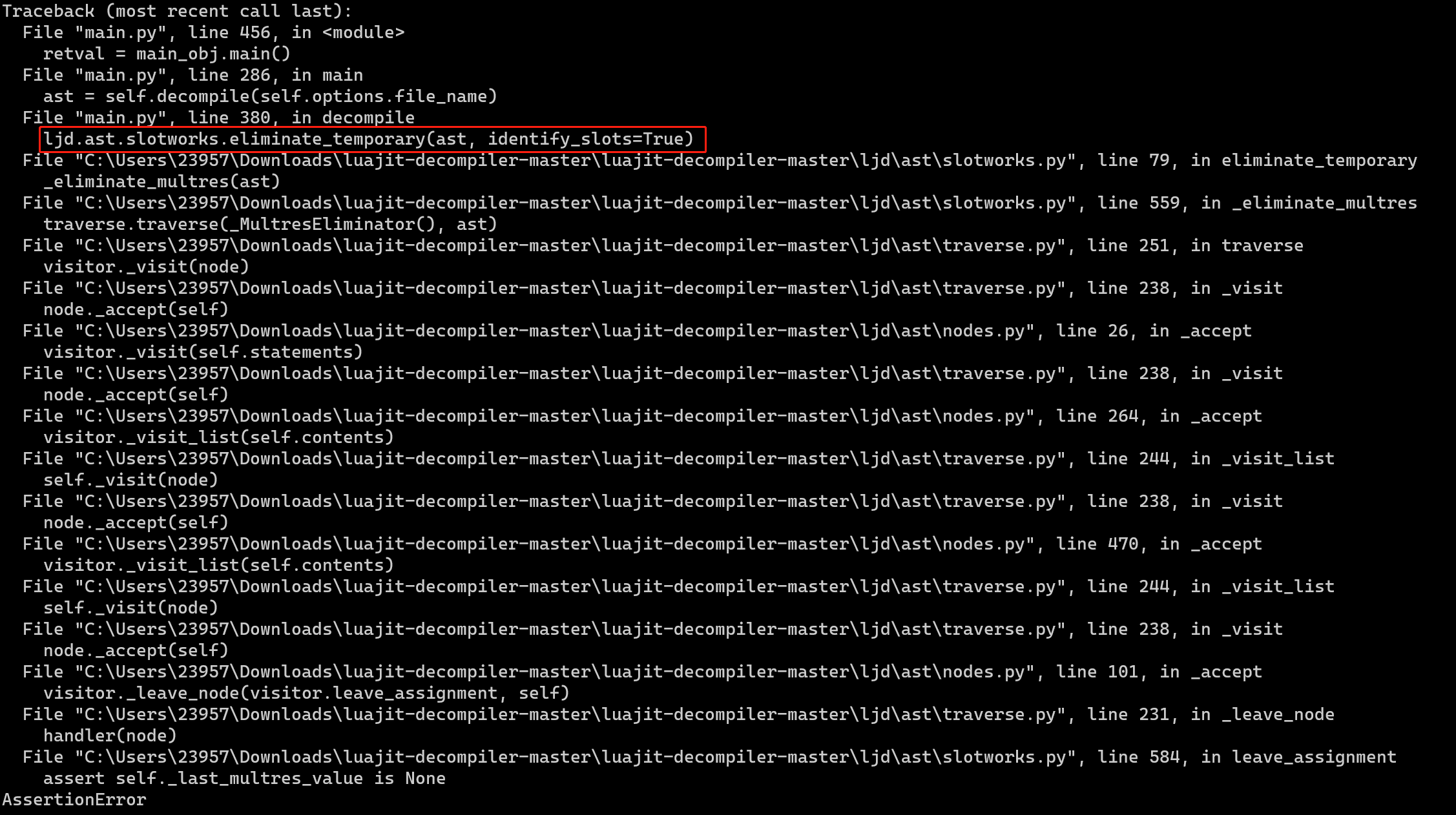
这是去除中间项的代码,把这行注释掉,并开启no_unwarp,最终得到反汇编代码。但是有7000行代码,猜测是将去除中间项的代码注释掉的结果,妈的。
看了佬的wp,他对于此错误的改进为:修改./luajit-decompiler/ljd/rawdump/code.py为:

(注:由于我并不是先转汇编再转lua代码,因此并没有调试出是在CALL处除了错误,其实,我就算知道了CALL出了错误,也不知道怎么改,呜呜呜。)
再运行,得到:
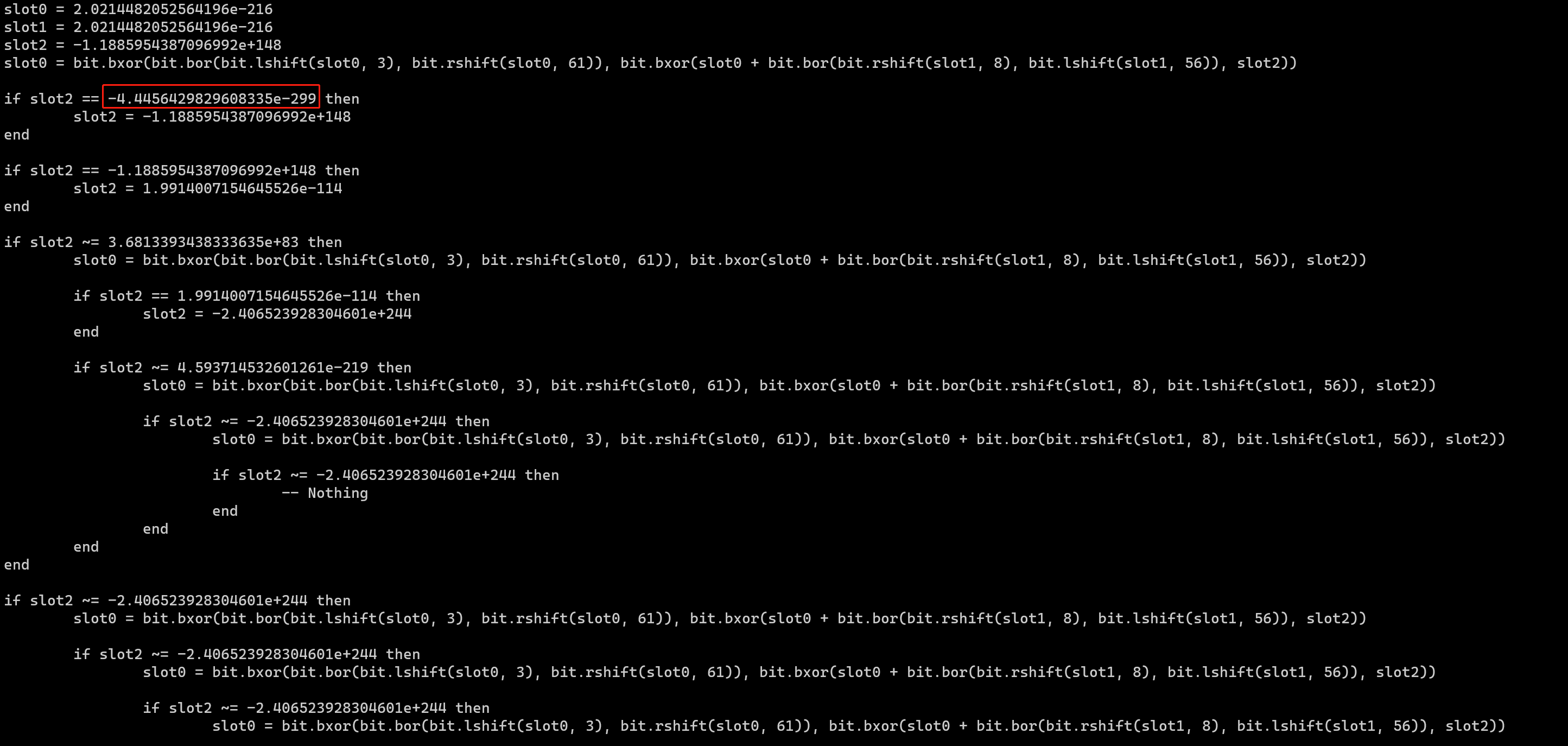
针对浮点数的情况,佬的改进如下:修改./luajit-decompiler/ljd/rawdump/constants.py为:
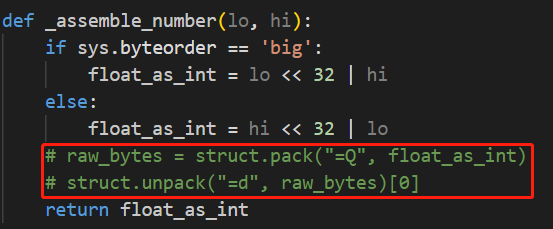
得到的结果out.lua为(其中slot1与slot0为输入的uleb128编码):

其中,可以分析得出,slot2负责控制程序流。最后返回处理后的slot0与slot1。有一个很坑的点是:
1 | slot0 = bit.bxor(bit.bor(bit.lshift(slot0, 3), bit.rshift(slot0, 61)), bit.bxor(slot0 + bit.bor(bit.rshift(slot1, 8), bit.lshift(slot1, 56)), slot2)) |
上述式子的中间值slot1没赋值,应该是这样(也太坑了):
1 | slot1 = bor(rshift(slot1, 8), lshift(slot1, 56)); |
再分析IDA反汇编代码,luaL_checkcdata函数表示从栈底开始取值,取到的分别是slot0与slot1,并判断是否是某个值。
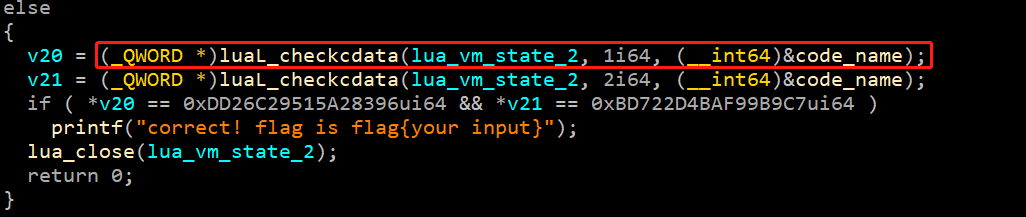
Step4:通过运行out.lua,可以得到一共运行了32次上述4行代码,其中slot2都不同,最终可以写脚本:
1 | import leb128 |
0x03 Misc-一起学生物
To be continued…
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!