go-bin-re-study-2
Go二进制文件逆向分析-2
之前学过一点Go逆向,但是学的不深,主要是看到SCTF2023-hiddenInNetwork这个题目就蒙了哈哈,插件也不好使。本文主要是接着看JiaYu师傅的博文,深入了解一下Go逆向。
0x00 itab_link(interface映射表)
Interface(接口) 用来定义一组行为(Interface Methods),所有实现了这一组行为的类型,都可称之为实现了这个接口。接口的底层定义如下:
1 | type interfaceType struct { |
在Go文件中,还保留了 Interface 与实现 Interface 的类型之间的映射关系。每一组映射关系,叫 itab(Interface Table),itab 的结构如下:
1 | type itab struct { |
查找并解析itab
Go 二进制文件中可能存在几百组 Interface 与具体数据类型的映射关系,即几百甚至上千个 itab 结构,如何把它们都找出来并解析呢?
firstmoduledata 中有字段 itab_link,itab_link 是指向 Go 二进制文件中的 Interface 映射表。itab_link 这个结构通常会在 ELF 文件中一个单独的 Section,叫 .itablink,但是这种按节区找itab_link的方式不靠谱。从 firstmoduledata 结构中 itab_link 字段定位到的 itablink 是一个 itab 结构的地址列表,其中每一项,都是一个 itab 结构的地址。每个 itab 结构体的命名规则,都是 (前缀)go_itab + 实际类型名 + Interface 名。最后, firstmoduledata 中也标明了 itablink 结构中 itab 地址的数量,所以根据 itablink 的起始地址和数量,依次解析相应的 itab 即可。
0x01 字符串
string 类型是值类型(相对于引用类型),是 Go 支持的基础类型之一。一个字符串是一个不可改变的字节序列,字符串可以包含任意的数据,但是通常是用来包含可读的文本,字符串是 UTF-8 字符的一个序列(当字符为 ASCII 码表上的字符时则占用 1 个字节,其它字符根据需要占用 2-4 个字节)。
Go 中字符串底层由两个元素来定义:字节序列的地址 和 字节序列的长度,而不是像 C 语言那样以一个起始地址和 0x00 结尾就能表示一个字符串。在 Go 二进制文件中,操作一个字符串也要同时引用这两个元素。比如某函数需要一个字符串类型的参数,传参时就要在栈上的参数空间留两个位置,一个位置把相应字节序列的地址传进去,另一个位置把字节序列的长度传进去。
在静态逆向分析 Go 二进制文件时,在操作字符串的汇编代码片段中,最多只能看到目标字符串的长度,而字符串还是处于未分析的原始字节序列的状态。大量的字符串处于这种状态时,会使逆向分析变得很费劲。所以我们要把这些字符串尽量都解析出来,然后在引用这个字符串的汇编代码处打 Comment 或者加上 Data Reference。
如何解析?能用的办法,就是分析调用、操作字符串的的汇编指令片段的 Pattern,然后从所有汇编指令中暴力检索可能操作字符串的位置,提取到相应字符串的地址与长度进而解析能够查找到的字符串。
Go 二进制文件中的字符串,可以分为三种:(1)字符串常量;(2)字符串指针;(3)字符串数组/切片。
字符串常量
操作字符串常量的汇编代码,会直接引用字节序列的地址,然后把字符串的长度当作汇编指令的一个立即数来使用。示例代码如下:
1 | mov ebx, offset aWire ; "wire" # 获得字符串 |
字符串指针
示例代码如下:
1 | mov rcx, cs:qword_BC2908 ; str len |
但是有的长度不是按随机数来的,所以可能会有漏报。但是字符串指针都是存放到一个固定区域的。可以找到某一块区域的起始地址与结束地址,然后进行匹配。另一种思路是是遍历 string 类型定义的交叉引用,然后看看有没有如上的汇编指令片段的 Pattern。如果一段汇编代码中拿 string 类型定义去解析一个字符串,那么就可以顺藤摸瓜找到字符串指针,字符串指针的地址后面紧挨着就是字符串的长度,这样也可以把字符串解析出来。
字符串数组
字符串数组,在 Go 二进制文件里的展示方式,比上面的情况要再多“跳转”一步:整个数组用元素起始地址和数组长度 两个元素来表示,而元素的起始地址处则依次存放了每一个字符串的地址和长度。
0x02 Go逆向补充
Go 中函数内存空间布局如下:
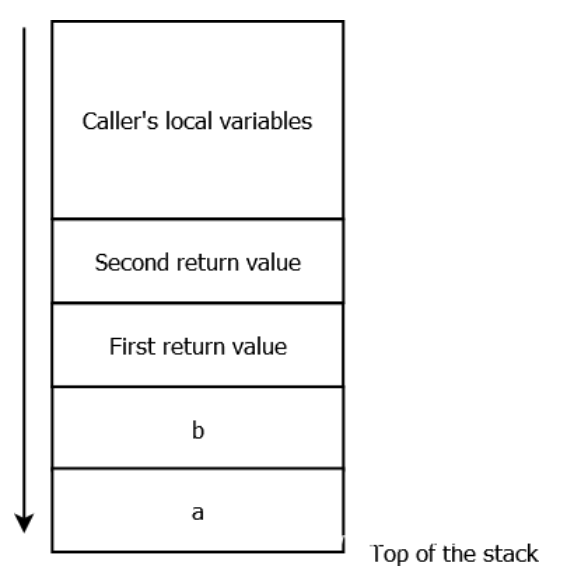
如何确定函数头部的arg哪些是传入的参数,哪些是返回值:是先去函数末尾找有没有返回值,确定了返回值,剩下的arg就是需要传入的参数。或者,如果函数有返回值的话,返回值总是最后面的arg,即距离栈底较近的位置。
入口函数与初始化函数
IDAPro 的自动化分析过程结束后,会自动跳转到一个入口函数的位置。对于 Go 二进制文件,64bit PE 文件通常会自动跳转到 _rt0_amd64_windows 函数,64bit ELF 文件通常会自动跳转到 _rt0_amd64_linux 函数。然而,这两个函数是入口函数。真正的 Go 语言程序逻辑的入口,其实是 main.main() 函数。 Go 语言规范中还有个特殊的函数init(),会在main() 函数之前就执行。
init() 函数作用如下:(1)全局变量初始化;(2)运行只需计算1次的模块,像sync.once的作用,或全局数据库连接句柄的初始化等;(3)等等。init()函数的特性有以下几个:init 函数先于 main 函数自动执行,不能被其他函数调用;init函数没有输入参数、返回值;每个包可以有多个 init 函数;
举例, DDG(DarkDelivery Trojan Group)木马样本里,就通过多个init()函数实现了不同的初始化设置:(1) ddgs_common_init() 中,DDG 换了 Base64 码表。(2) ddgs_global_init() 中,DDG 创建一对全局 ed25519 密钥,用以在后续存取数据时对数据进行签名和校验;(3) ddgs_global_init() 中,DDG 调用了一个函数 ddgs_global_decodePasswords ,在这个函数中解密并校验内置的弱口令字典,这些弱口令将在后续阶段被用来暴破 SSH 服务;等等。
由此可见,分析 Go 二进制文件时,应该先看是否实现 init() 函数,然后再分析它的 main() 函数。但是,也不能就只看 main.init() 函数,因为一个 Go 项目中可能用到了不同的 Package,每个 Package 甚至每个源码文件都可以实现自己的 init() 函数,而这些被导入的 Package 中的 init() 函数,会在 main.init() 之前被调用执行。需要分析的一般是指二进制文件里导入的私有 Package 中的 init() 函数。
GC垃圾回收
Golang 内部有比较高效的垃圾回收(GC)机制。Golang 中的内存写操作,会先通知 GC,在 GC 中为目的内存做标记。通知 GC 的方式,是在内存写操作之前检查 runtime.writeBarrier.enbaled 标志位,如果设定了这个标志位,就会通过 runtime.gcWriteBarrier 来进行内存写操作。
runtime.growslice()
每当一个切片类型的数据在进行Append操作时如果需要动态增长(扩容),就会在底层由 runtime 调用runtime.growslice()来调整切片的内部空间。
runtime.growslice()的函数声明如下:
1 | func growslice(et *_type, old slice, cap int) slice |
即该函数会在调整旧 Slice 内部元素之后,返回一个基于旧 Slice 扩容后的新 Slice。
Go语言调试
Go调试与dlv与GDB的Go插件有关。但是这两个工具的使用需要有调试符号。对于我们要分析的 Go 恶意软件,绝大部分是没有调试符号的,strip 处理的很干净。我们可以通过静态分析掌握足够的信息,把没符号的 Go 二进制文件扔调试器里,就可以动态调试。
Go 二进制文件调试面临的唯一一个问题就是断点(记得之前调试的时候也有这个问题)。只能直接在想要断下来的地址处直接给地址下断点。另外需要注意的是,Go 语言 runtime 内部通过协程来实现高并发。在调试器中可以看到代码在不同的函数中跳来跳去,所以断点务必要打准,不然很容易就被 Go runtime 的协程调度给搞蒙。
0x03 案例演示
Go 二进制文件还有一个独特的方面:复杂数据结构解析。Go 语言中可以通过 Struct 来定义复杂的数据结构,通常可以跟一个 JSON 数据结构相互转换,即它可以定义一个结构复杂的 JSON 数据。
下面给一个例子,以 DDG 样本中的一个最新版关键配置数据 slave configure 的解析,来演示一下逆向过程。
DDG 中的 Slave Configure
DDG 是一个专注于扫描控制 SSH 、 Redis 和 OrientDB,并攫取服务器算力挖矿的僵尸网络。后来的版本升级中,DDG 还加入了对 Supervisord 和 Nexus 的漏洞利用来传播自身。2019 年 11 月,DDG 又新增 P2P 协议,把自己打造成了一个 P2P 结构的挖矿僵尸网络。
DDG 的Slave Configure文件由msgpack编码(可以简单粗暴理解为压缩版的 JSON 数据通用序列化编码方案)组成。这份配置文件中指定了矿机程序的下载地址、另存为 Path 和 MD5;还指定了要启用的传播模块以及相关配置属性,比如是要内网传播还是公网传播、要爆破的 SSH 服务的端口列表,以及拿下肉鸡后要执行的恶意 Shell 脚本的下载链接等等。最后,还专门为这份配置数据加了一个签名,以防被别人篡改。
逆向分析
对 slave 配置文件的操作,都集中在 DDG 样本的 main.pingpong() 函数中。这个函数有一个参数是 C&C (攻击者服务器)的地址,它首先向 http://<C&C>/slave 发一个 POST 请求,然后等待 C&C 回复。收到 C&C 的响应之后,该函数继续执行以下逻辑:
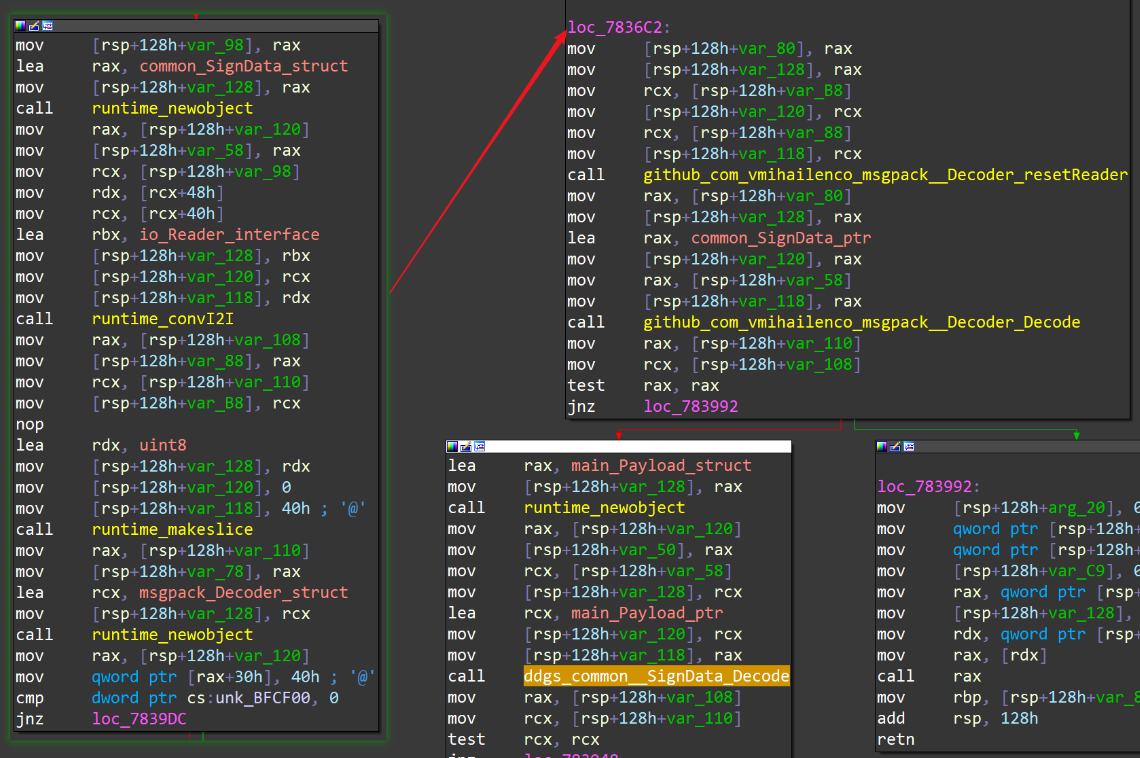
上图左边和右上方的代码块,显示该函数先用 common.SignData 这个 Struct 类型来对 C&C 返回的数据执行解码操作。然后右下方的代码块又用main.Payload 这个Struct类型,对前面解码出来的部分数据进行第二层 msgpack 解码操作。可以看到 common.SignData 这个类型的定义:
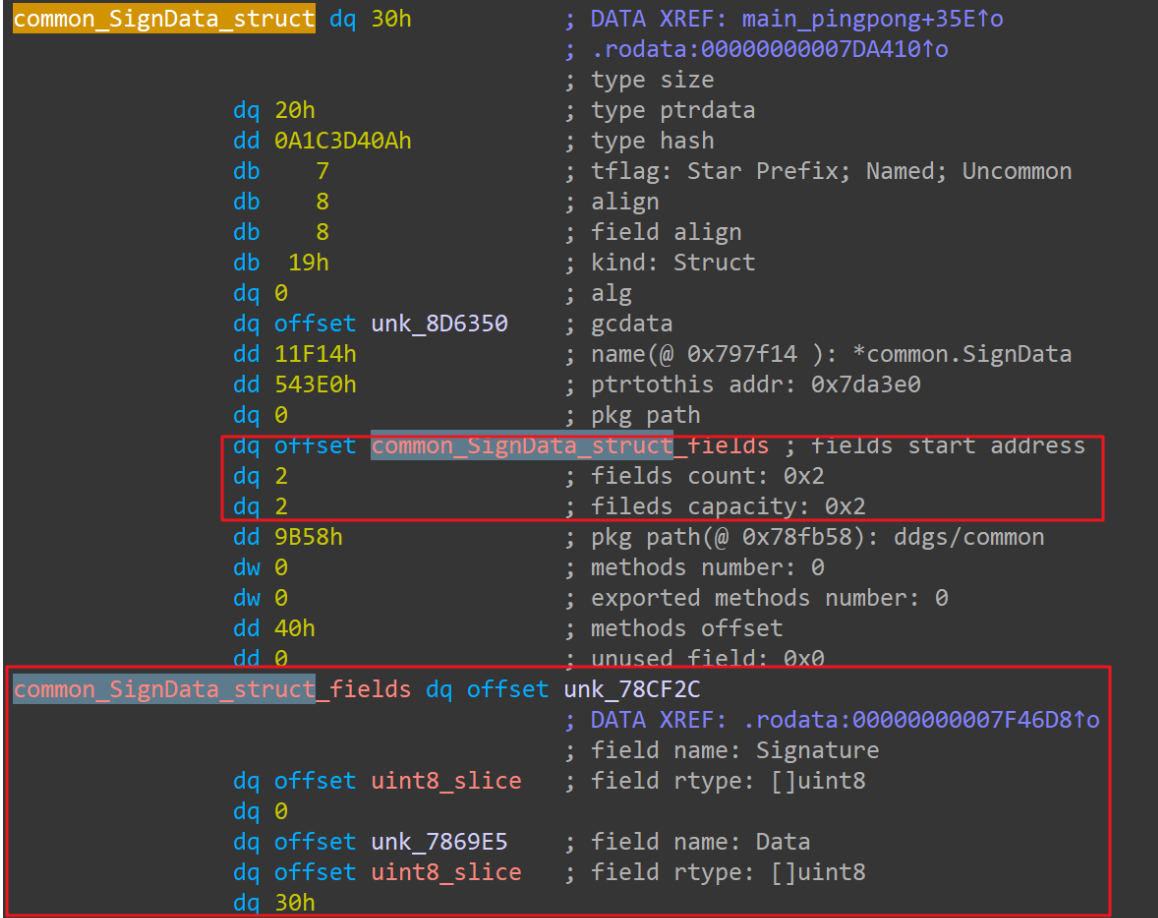
可以看到它包含两个字段:[]byte类型的Signature,和 []byte 类型的Data。其实,下面进行第二层msgpack解码的,是Data字段的内容。即 Slave 第一层编码是用来校验配置数据的 Signature,后面真正的配置数据还要再经过一层msgpack解码。第二层解码真正的配置数据main.Payload ,是在函数 ddgs_common__SignData_Decode() 中进行的,该函数很简单,先校验数据,后用msgpack解码(此处略去校验过程):
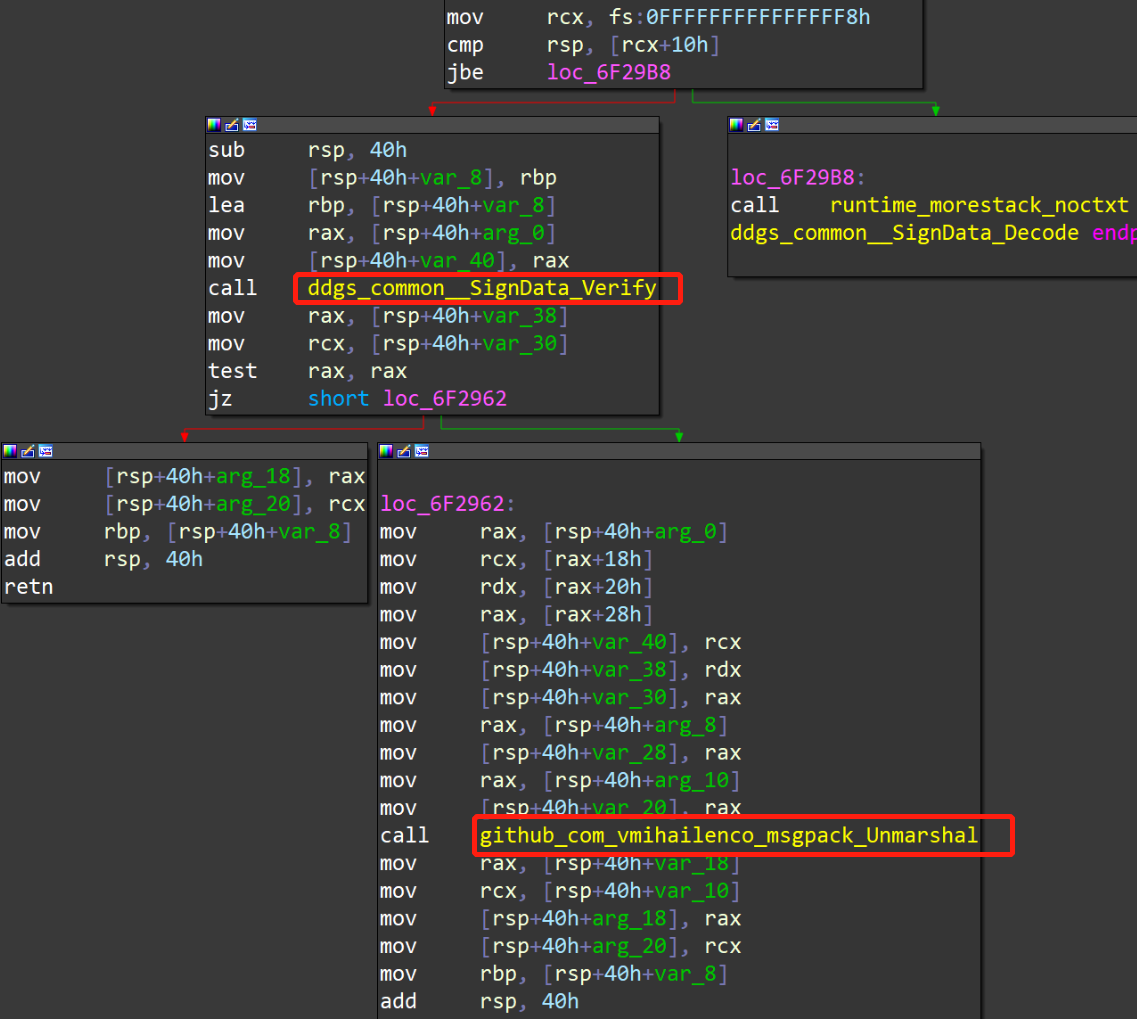
上文说过,Payload又加了一层msgpack 编码,如果要用 Go 代码来反序列化解码数据的话,必须要逆向、恢复出一个准确的数据结构定义,拿这个准确定数据结构定义去解码数据。这在 Go 语言二进制文件逆向的数据反序列化解码、解密方面,是一个常见的难题。但是 msgpack 是一个通用的序列化编码方案,用 Python 这种动态类型的高级语言来解的话,有一个好处是不需要提前知道数据的结构定义。后面的就不说了,用到再看。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!