复现文件保存在链接 。
SycLang 64位trans_IR。主要是看那个txt文件。经过化简,可以得到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 var15<+56> -> aa var16<+64> -> bb var17<+72> -> cc var18<+80> -> dd var19<+88> -> ee var20<+96> -> ff var21<+104> -> gg var12<+32> -> hh var13<+40> -> kk var11 -> arr1 var22 -> cp1 var23 -> cp2 var24 -> cp3 var25 -> cp4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 STRUCT exp : ARRAY .key(int)[24]<+0> ARRAY .L(int)[8]<+192> ARRAY .R(int)[8]<+256> ARRAY .X(int)[8]<+320> FUNCTION read - 8 : PARAM var2<+8> LABEL Flabelread : FUNCTION writes - 0 : LABEL Flabelwrites : FUNCTION writef - 0 : LABEL Flabelwritef : FUNCTION exit - 0 : LABEL Flabelexit : FUNCTION main - 1640 : ARRAY arr1(char)[24]<+0> STRUCT cp1(exp)<+488> STRUCT cp2(exp)<+872> STRUCT cp3(exp)<+1256> STRUCT cp4(exp)<+1640> ARG arr1<+24> // 输入 CALL read aa := 0 LABEL label4 : IF aa < 24 GOTO label3 GOTO label2 LABEL label3 : hh := 0 bb := aa hh ::= arr1<1+bb> dd := 23 - aa cp1.key[8+8*dd] = hh // 输入的倒序给cp1.key, aa=输入长度 aa := aa + 1 GOTO label4 LABEL label2 : aa := 23 LABEL label11 : IF aa > 0 GOTO label10 GOTO label9 LABEL label10 : dd := aa ee = cp1.key[8+8*dd] // 输入的第1个值给ee bb := aa - 1 cc = cp1.key[8+8*bb] // 输入的第2个值给cc gg := ee - cc cp1.key[8+8*aa] = gg // cp1.key[aa] = cp1.key[aa]-cp1.key[aa-1],见草稿纸(1) aa := aa - 1 GOTO label11 LABEL label9 : cp1(@exp.L[0])<+200><+488> := 0 // cp1.L = [0,15,2,10,6,9,1,4] cp1(@exp.R[0])<+264><+488> := 8 // cp1.R = [8,23,11,20,13,21,19,17] cp1(@exp.X[0])<+328><+488> := 11 // cp1.X = [11,-13,17,-19,23,-29,31,-37] cp1(@exp.L[1])<+208><+488> := 15 cp1(@exp.R[1])<+272><+488> := 23 cp1(@exp.X[1])<+336><+488> := -13 cp1(@exp.L[2])<+216><+488> := 2 cp1(@exp.R[2])<+280><+488> := 11 cp1(@exp.X[2])<+344><+488> := 17 cp1(@exp.L[3])<+224><+488> := 10 cp1(@exp.R[3])<+288><+488> := 20 cp1(@exp.X[3])<+352><+488> := -19 cp1(@exp.L[4])<+232><+488> := 6 cp1(@exp.R[4])<+296><+488> := 13 cp1(@exp.X[4])<+360><+488> := 23 cp1(@exp.L[5])<+240><+488> := 9 cp1(@exp.R[5])<+304><+488> := 21 cp1(@exp.X[5])<+368><+488> := -29 cp1(@exp.L[6])<+248><+488> := 1 cp1(@exp.R[6])<+312><+488> := 19 cp1(@exp.X[6])<+376><+488> := 31 cp1(@exp.L[7])<+256><+488> := 4 cp1(@exp.R[7])<+320><+488> := 17 cp1(@exp.X[7])<+384><+488> := -37 aa := 0 LABEL label43 : IF aa < 8 GOTO label42 GOTO label41 LABEL label42 : bb = cp1.L[200+8*aa] dd = cp1.R[264+8*aa] ff = cp1.X[328+8*aa] cc = cp1.key[8+8*bb] // cc = cp1.key[cp1.L[aa]] ee = cp1.key[8+8*dd] // ee = cp1.key[cp1.R[aa]] cc := cc + ff ee := ee - ff cp1.key[8+8*bb] = cc // cp1.key[cp1.L[aa]] = cp1.key[cp1.L[aa]] + cp1.X[aa] cp1.key[8+8*dd] = ee // cp1.key[cp1.R[aa]] = cp1.key[cp1.R[aa]] - cp1.X[aa] aa := aa + 1 GOTO label43 // 见草稿纸(2) LABEL label41 : aa := 1 LABEL label54 : IF aa < 24 GOTO label53 GOTO label52 LABEL label53 : cc = cp1.key[8+8*aa] bb := aa - 1 ff = cp1.key[8+8*bb] cc := cc + ff cp1.key[8+8*aa] = cc // cp1.key[aa] = cp1.key[aa] + cp1.key[aa-1] aa := aa + 1 // 见草稿纸(3) GOTO label54 LABEL label52 : aa := 0 LABEL label61 : IF aa < 23 GOTO label60 GOTO label59 LABEL label60 : bb := aa hh := cp1.key[bb] dd := aa + 1 kk := cp1.key[dd] kk := 0 cp1.key[bb] = hh ^ kk // cp1.key[aa] = cp1.key[aa] ^ cp1.key[aa+1] or cp1.key[aa] = cp1.key[aa] aa := aa + 1 // 见草稿纸(4) GOTO label61 LABEL label59 : cp3(@exp.L[0])<+200><+1256> := 0 // cp3.L = [0,9,9,8,10,9,1,0] cp3(@exp.R[0])<+264><+1256> := 12 // cp3.R = [12,10,12,19,12,13,22,23] cp3(@exp.X[0])<+328><+1256> := -19 // cp3.X = [-19,-10,3,-11,-9,3,-19,7] cp3(@exp.L[1])<+208><+1256> := 9 // cp3.key = [12,31,31,31,31,31,31,31,42,46,45,45,20,23,23,23,23,23,23,12,12,12,-7,0] cp3(@exp.R[1])<+272><+1256> := 10 cp3(@exp.X[1])<+336><+1256> := -10 cp3(@exp.L[2])<+216><+1256> := 9 cp3(@exp.R[2])<+280><+1256> := 12 cp3(@exp.X[2])<+344><+1256> := 3 cp3(@exp.L[3])<+224><+1256> := 8 cp3(@exp.R[3])<+288><+1256> := 19 cp3(@exp.X[3])<+352><+1256> := -11 cp3(@exp.L[4])<+232><+1256> := 10 cp3(@exp.R[4])<+296><+1256> := 12 cp3(@exp.X[4])<+360><+1256> := -9 cp3(@exp.L[5])<+240><+1256> := 9 cp3(@exp.R[5])<+304><+1256> := 13 cp3(@exp.X[5])<+368><+1256> := 3 cp3(@exp.L[6])<+248><+1256> := 1 cp3(@exp.R[6])<+312><+1256> := 22 cp3(@exp.X[6])<+376><+1256> := -19 cp3(@exp.L[7])<+256><+1256> := 0 cp3(@exp.R[7])<+320><+1256> := 23 cp3(@exp.X[7])<+384><+1256> := 7 cp3(@exp.key[0])<+8><+1256> := 12 cp3(@exp.key[1])<+16><+1256> := 31 cp3(@exp.key[2])<+24><+1256> := 31 cp3(@exp.key[3])<+32><+1256> := 31 cp3(@exp.key[4])<+40><+1256> := 31 cp3(@exp.key[5])<+48><+1256> := 31 cp3(@exp.key[6])<+56><+1256> := 31 cp3(@exp.key[7])<+64><+1256> := 31 cp3(@exp.key[8])<+72><+1256> := 42 cp3(@exp.key[9])<+80><+1256> := 46 cp3(@exp.key[10])<+88><+1256> := 45 cp3(@exp.key[11])<+96><+1256> := 45 cp3(@exp.key[12])<+104><+1256> := 20 cp3(@exp.key[13])<+112><+1256> := 23 cp3(@exp.key[14])<+120><+1256> := 23 cp3(@exp.key[15])<+128><+1256> := 23 cp3(@exp.key[16])<+136><+1256> := 23 cp3(@exp.key[17])<+144><+1256> := 23 cp3(@exp.key[18])<+152><+1256> := 23 cp3(@exp.key[19])<+160><+1256> := 12 cp3(@exp.key[20])<+168><+1256> := 12 cp3(@exp.key[21])<+176><+1256> := 12 cp3(@exp.key[22])<+184><+1256> := -7 cp3(@exp.key[23])<+192><+1256> := 0 aa := 23 LABEL label118 : IF aa > 0 GOTO label117 GOTO label116 LABEL label117 : dd := aa ee = cp3.key[8+8*dd] bb := aa - 1 cc = cp3.key[8+8*bb] gg := ee - cc cp3.key[8+8*aa] = gg // cp3.key[aa] = cp3.key[aa] - cp3.key[aa-1] aa := aa - 1 // 见草稿纸(5) GOTO label118 LABEL label116 : aa := 0 LABEL label126 : IF aa < 8 GOTO label125 GOTO label124 LABEL label125 : bb = cp3.L[200+8*aa] dd = cp3.R[264+8*aa] ff = cp3.X[328+8*aa] cc = cp3.key[8+8*bb] ee = cp3.key[8+8*dd] cc := cc + ff ee := ee - ff cp3.key[8+8*bb] = cc // cp3.key[cp3.L[aa]] = cp3.key[cp3.L[aa]] + cp3.X[aa] cp3.key[8+8*dd] = ee // cp3.key[cp3.R[aa]] = cp3.key[cp3.R[aa]] - cp3.X[aa] aa := aa + 1 // 见草稿纸(6) GOTO label126 LABEL label124 : aa := 1 LABEL label137 : IF aa < 24 GOTO label136 GOTO label135 LABEL label136 : cc = cp3.key[8+8*aa] bb := aa - 1 ff = cp3.key[8+8*bb] cc := cc + ff cp3.key[8+8*aa] = cc // cp3.key[aa] = cp3.key[aa] + cp3.key[aa-1] aa := aa + 1 // 见(7) GOTO label137 LABEL label135 : cp2(@exp.key[0])<+8><+872> := 252 // cp2.key = [252,352,484,470,496,487,539,585,447,474,577,454,466,345,344,486,501,423,490,375,257,203,265,125] cp2(@exp.key[1])<+16><+872> := 352 cp2(@exp.key[2])<+24><+872> := 484 cp2(@exp.key[3])<+32><+872> := 470 cp2(@exp.key[4])<+40><+872> := 496 cp2(@exp.key[5])<+48><+872> := 487 cp2(@exp.key[6])<+56><+872> := 539 cp2(@exp.key[7])<+64><+872> := 585 cp2(@exp.key[8])<+72><+872> := 447 cp2(@exp.key[9])<+80><+872> := 474 cp2(@exp.key[10])<+88><+872> := 577 cp2(@exp.key[11])<+96><+872> := 454 cp2(@exp.key[12])<+104><+872> := 466 cp2(@exp.key[13])<+112><+872> := 345 cp2(@exp.key[14])<+120><+872> := 344 cp2(@exp.key[15])<+128><+872> := 486 cp2(@exp.key[16])<+136><+872> := 501 cp2(@exp.key[17])<+144><+872> := 423 cp2(@exp.key[18])<+152><+872> := 490 cp2(@exp.key[19])<+160><+872> := 375 cp2(@exp.key[20])<+168><+872> := 257 cp2(@exp.key[21])<+176><+872> := 203 cp2(@exp.key[22])<+184><+872> := 265 cp2(@exp.key[23])<+192><+872> := 125 aa := 0 LABEL label168 : IF aa < 24 GOTO label167 GOTO label166 LABEL label167 : bb := aa cc = cp2.key[8+8*bb] dd := aa ee = cp3.key[8+8*dd] gg := cc ^ ee cp2.key[8+8*aa] = gg // cp2.key[aa] = cp2.key[aa] ^ cp3.key[aa] aa := aa + 1 // 见(8) GOTO label168 LABEL label166 : aa := 0 LABEL label176 : IF aa < 8 GOTO label175 GOTO label174 LABEL label175 : bb := aa * 3 cc = cp1.key[8+8*bb] cp2.X[328+8*aa] = cc // cp2.X[aa] = cp1.key[aa*3] aa := aa + 1 // 见(9) GOTO label176 LABEL label174 : aa := 23 LABEL label181 : IF aa > 0 GOTO label180 GOTO label179 LABEL label180 : dd := aa ee = cp2.key[8+8*dd] bb := aa bb := bb - 1 cc = cp2.key[8+8*bb] gg := ee - cc cp2.key[8+8*aa] = gg // cp2.key[aa] = cp2.key[aa] - cp2.key[aa-1] aa := aa - 1 // 见(10) GOTO label181 LABEL label179 : aa := 0 LABEL label190 : IF aa < 8 GOTO label189 GOTO label188 LABEL label189 : bb = cp1.L[200+8*aa] dd = cp1.R[264+8*aa] ff = cp2.X[328+8*aa] cc = cp2.key[8+8*bb] ee = cp2.key[8+8*dd] cc := cc - ff ee := ee + ff cp2.key[8+8*bb] = cc // cp2.key[cp1.L[aa]] = cp2.key[cp1.L[aa]] - cp2.X[aa] cp2.key[8+8*dd] = ee // cp2.key[cp1.R[aa]] = cp2.key[cp1.R[aa]] + cp2.X[aa] aa := aa + 1 // 见(11) GOTO label190 LABEL label188 : aa := 1 LABEL label201 : IF aa < 24 GOTO label200 GOTO label199 LABEL label200 : cc = cp2.key[8+8*aa] bb := aa - 1 ff = cp2.key[8+8*bb] cc := cc + ff cp2.key[8+8*aa] = cc // cp2.key[aa] = cp2.key[aa] + cp2.key[aa-1] aa := aa + 1 // 见(12) GOTO label201 LABEL label199 : aa := 0 LABEL label208 : IF aa < 7 GOTO label207 GOTO label206 LABEL label207 : bb := aa cc = cp1.L[200+8*bb] dd := aa + 1 ee = cp1.L[200+8*dd] gg := cc ^ ee // gg = cp1.L[aa] ^ cp1.L[aa+1] IF gg > 23 GOTO label215 GOTO label214 LABEL label215 : gg := 23 LABEL label214 : cp4.L[200+8*aa] = gg // cp4.L[aa] = gg aa := aa + 1 GOTO label208 LABEL label206 : // cp4.L[7] = 0 cp4.L[256+7*8] = 0 // 见(13) aa := 0 LABEL label219 : IF aa < 7 GOTO label218 GOTO label217 LABEL label218 : bb := aa cc = cp1.R[264+8*bb] dd := aa + 1 ee = cp1.R[264+8*dd] gg := cc ^ ee // gg = cp1.R[aa] ^ cp1.R[aa+1] IF gg > 23 GOTO label226 GOTO label225 LABEL label226 : gg := 23 LABEL label225 : cp4.R[264+8*aa] = gg // cp4.R[aa] = gg aa := aa + 1 GOTO label219 LABEL label217 : cp4.R[320+8*7] = 23 // cp4.R[7] = 23 aa := 0 // 见(14) LABEL label230 : IF aa < 7 GOTO label229 GOTO label228 LABEL label229 : bb := aa cc = cp1.X[328+8*bb] dd := aa + 1 ee = cp1.X[328+8*dd] gg := cc ^ ee cp4.X[328+8*aa] = gg // cp4.X[aa] = cp1.X[aa] ^ cp1.X[aa+1] aa := aa + 1 // 见(15) GOTO label230 LABEL label228 : cp4(@exp.X[7])<+384><+1640> := 12 cp4(@exp.key[0])<+8><+1640> := 127 // cp4.key = [127,111,188,174,195,128,88,121,123,103,57,123,97,74,37,59,21,47,54,28,49,55,??,125] cp4(@exp.key[1])<+16><+1640> := 111 cp4(@exp.key[2])<+24><+1640> := 188 cp4(@exp.key[3])<+32><+1640> := 174 cp4(@exp.key[4])<+40><+1640> := 195 cp4(@exp.key[5])<+48><+1640> := 128 cp4(@exp.key[6])<+56><+1640> := 88 cp4(@exp.key[7])<+64><+1640> := 121 cp4(@exp.key[8])<+72><+1640> := 123 cp4(@exp.key[9])<+80><+1640> := 103 cp4(@exp.key[10])<+88><+1640> := 57 cp4(@exp.key[11])<+96><+1640> := 123 cp4(@exp.key[12])<+104><+1640> := 97 cp4(@exp.key[13])<+112><+1640> := 74 cp4(@exp.key[14])<+120><+1640> := 37 cp4(@exp.key[15])<+128><+1640> := 59 cp4(@exp.key[16])<+136><+1640> := 21 cp4(@exp.key[17])<+144><+1640> := 47 cp4(@exp.key[18])<+152><+1640> := 54 cp4(@exp.key[19])<+160><+1640> := 28 cp4(@exp.key[20])<+168><+1640> := 49 cp4(@exp.key[21])<+176><+1640> := 55 cp4(@exp.key[22])<+184><+1640> := var1<+8> cp4(@exp.key[23])<+192><+1640> := 125 aa := 23 LABEL label263 : IF aa > 0 GOTO label262 GOTO label261 LABEL label262 : dd := aa ee = cp4.key[8+8*dd] bb := aa bb := bb - 1 cc = cp4.key[8+8*bb] gg := ee - cc cp4.key[8+8*aa] = gg // cp4.key[aa] = cp4.key[aa] - cp4.key[aa-1] aa := aa - 1 // 见(16) GOTO label263 LABEL label261 : aa := 0 LABEL label272 : IF aa < 8 GOTO label271 GOTO label270 LABEL label271 : bb = cp4.L[200+8*aa] dd = cp4.R[264+8*aa] ff = cp4.X[328+8*aa] cc = cp4.key[8+8*bb] ee = cp4.key[8+8*dd] cc := cc - ff ee := ee + ff cp4.key[8+8*bb] = cc // cp4.key[cp4.L[aa]] = cp4.key[cp4.L[aa]] - cp4.X[aa] cp4.key[8+8*dd] = ee // cp4.key[cp4.R[aa]] = cp4.key[cp4.R[aa]] + cp4.X[aa] aa := aa + 1 // 见(17) GOTO label272 LABEL label270 : aa := 1 LABEL label283 : IF aa < 24 GOTO label282 GOTO label281 LABEL label282 : cc = cp4.key[8+8*aa] bb := aa - 1 ff = cp4.key[8+8*bb] cc := cc + ff cp4.key[8+8*aa] = cc // cp4.key[aa] = cp4.key[aa] + cp4.key[aa-1] aa := aa + 1 // 见(18) GOTO label283 LABEL label281 : hh := 0 kk := 0 aa := 0 LABEL label292 : IF aa < 24 GOTO label291 GOTO label290 LABEL label291 : // 比较cp1的key与cp2的key是否相等 bb := aa hh = cp1.key[8+8*aa] dd := aa kk = cp2.key[8+8*aa] IF kk != hh GOTO label298 GOTO label297 LABEL label298 : CALL writef CALL exit LABEL label297 : aa := aa + 1 GOTO label292 LABEL label290 : CALL writes CALL exit LABEL Flabelmain :
使用z3约束器求解即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 ''' # @Time : 2023/06/17 17:52:54 # @Author: wd-2711 ''' from z3 import *if __name__ == "__main__" : cp1_key = [Int(('key_%d' % i)) for i in range (24 )] for i in range (23 ): i = 23 - i cp1_key[i] -= cp1_key[i-1 ] cp1_L = [0 ,15 ,2 ,10 ,6 ,9 ,1 ,4 ] cp1_R = [8 ,23 ,11 ,20 ,13 ,21 ,19 ,17 ] cp1_X = [11 ,-13 ,17 ,-19 ,23 ,-29 ,31 ,-37 ] for i in range (8 ): cp1_key[cp1_L[i]] += cp1_X[i] cp1_key[cp1_R[i]] -= cp1_X[i] for i in range (23 ): i = i + 1 cp1_key[i] += cp1_key[i-1 ] cp2_key = [252 ,352 ,484 ,470 ,496 ,487 ,539 ,585 ,447 ,474 ,577 ,454 ,466 ,345 ,344 ,486 ,501 ,423 ,490 ,375 ,257 ,203 ,265 ,125 ] cp2_X = [0 for i in range (8 )] for i in range (8 ): cp2_X[i] = cp1_key[i*3 ] for i in range (23 ): i = 23 - i cp2_key[i] -= cp2_key[i-1 ] for i in range (8 ): cp2_key[cp1_L[i]] -= cp2_X[i] cp2_key[cp1_R[i]] += cp2_X[i] for i in range (1 , 24 ): cp2_key[i] += cp2_key[i-1 ] solver = Solver() for i in range (24 ): solver.add(cp1_key[i] == cp2_key[i]) if sat == solver.check(): m = solver.model() res = {} for d in m.decls(): res[d.name()] = int (str (m[d]), 10 ) for i in range (24 ): print (chr (res["key_" + str (i)]), end = "" )
让s0rry师傅先做出来了,呜呜呜,其实主要是没及时更新协作文档,以后注意!!!今天打了一天,感觉和平时做题的感觉还不一样,就很紧张,之后的stm32也没精力看了。
Digital_circuit_learning 参考链接1
参考链接2
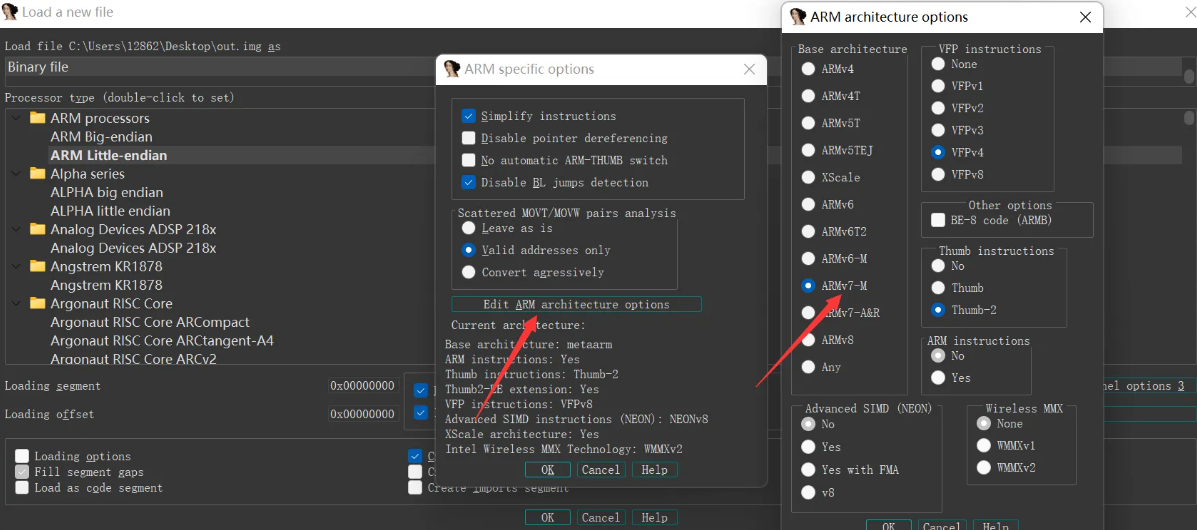
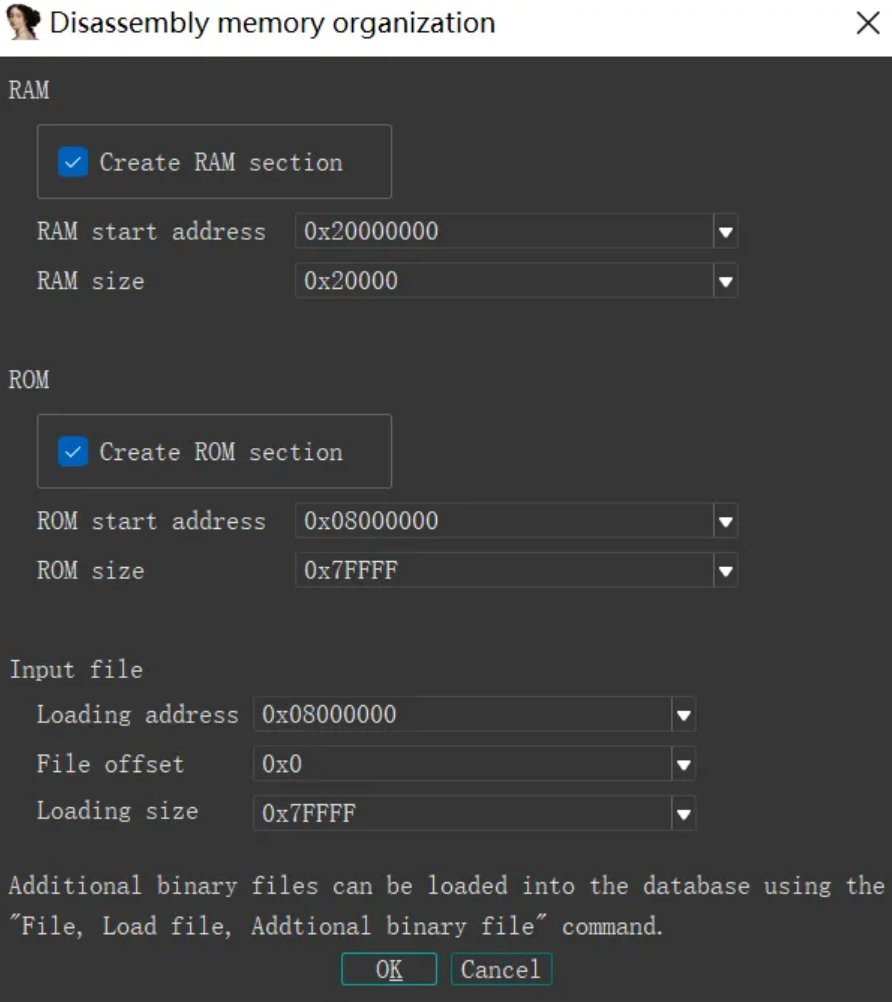
首先,题目没告诉板子型号,所以直接按最常见的(STM32F103ZET6)进行设置:
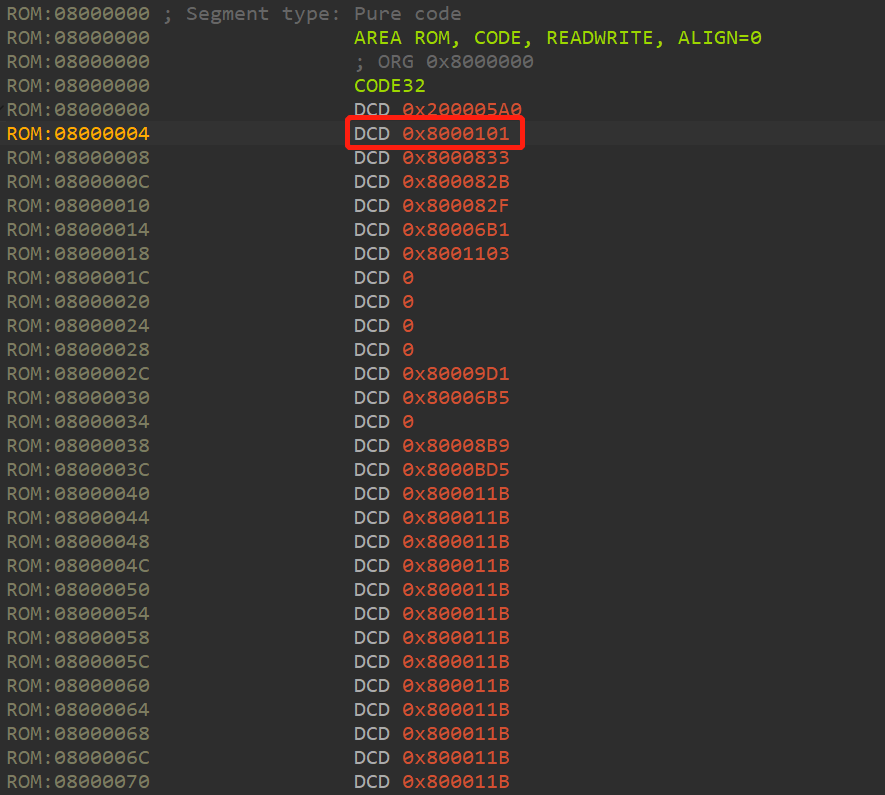
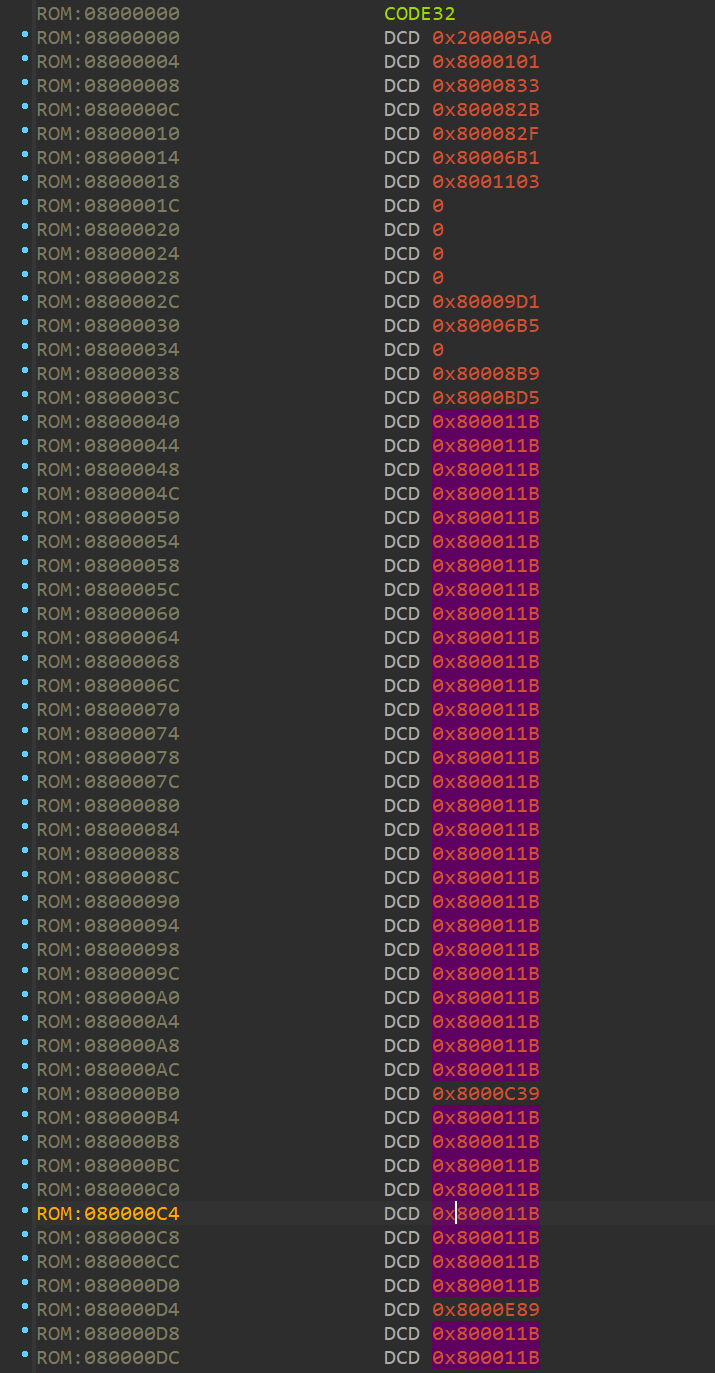
之后,对0x08000000-0x080000EC转为四字节,因为这是中断向量表。且第二个中断向量默认为入口函数。如下所示:
跟进0x8000101,并对0x8000100进行反编译处理,得到:
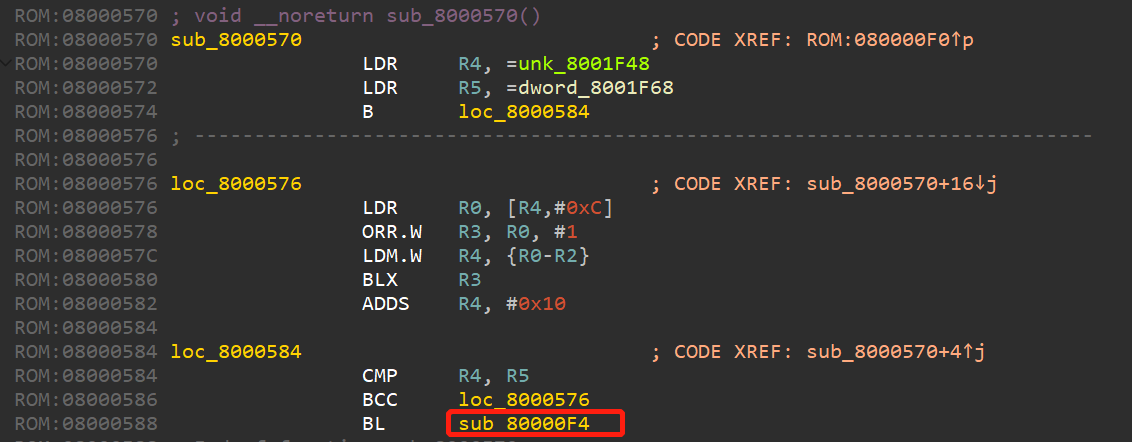
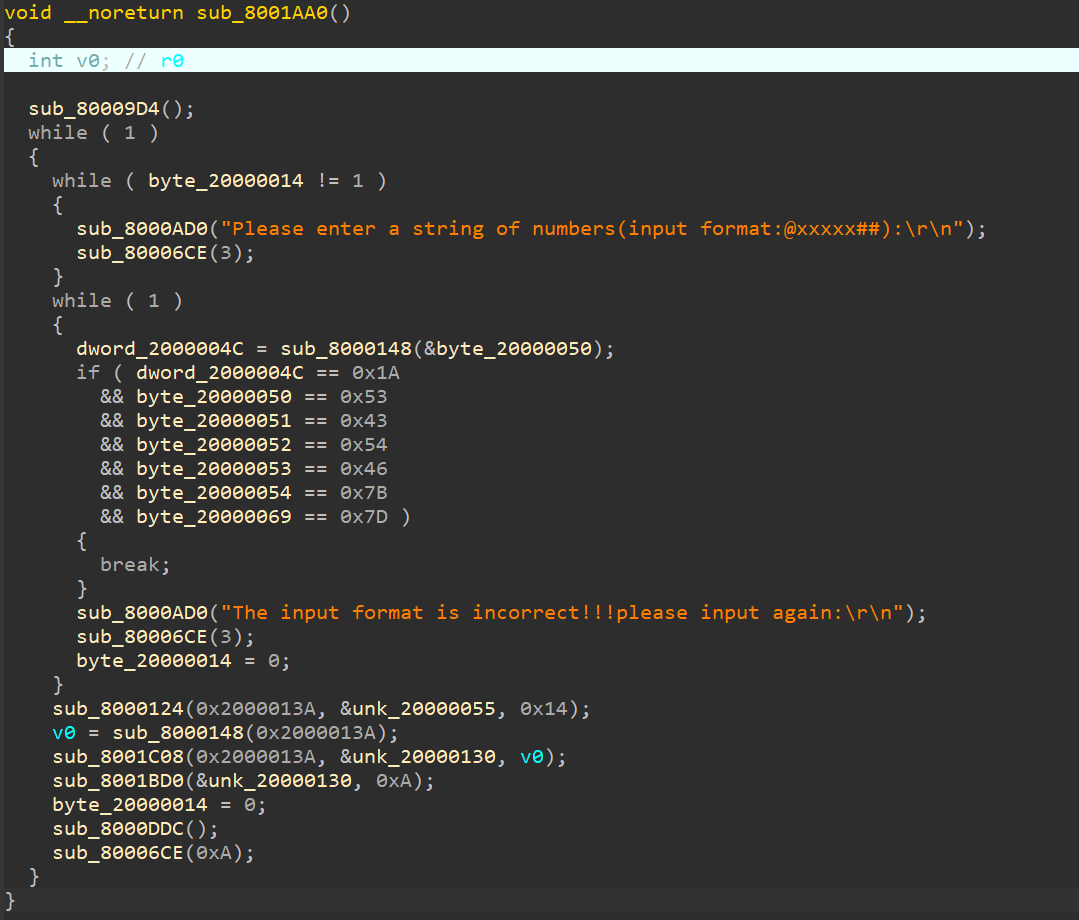
根据之前的stm-re文章,跟进unk_80000EC。一直跟进,可以找到主函数sub_8001AA0。
首先,有很多标红的,例如:
因此,我们要添加SRAM段与Peripherals段(stm-re一文中叙述,用于程序运算时存放变量)。
但是没有调试符号,所以按照参考链接2,直接打开正点原子的某个项目(尽可能包含各种库函数)。我打开的是内存分配项目,编译并拿到axf文件,用ida打开,就会得到对应的idb文件。之后用bindiff导入符号(技能Get),但是相似度都不是特别高。打算手动瞅瞅(stm-re一文中叙述,用手册恢复符号)。手动恢复后大概长这样:
接下来就是查看中断函数:
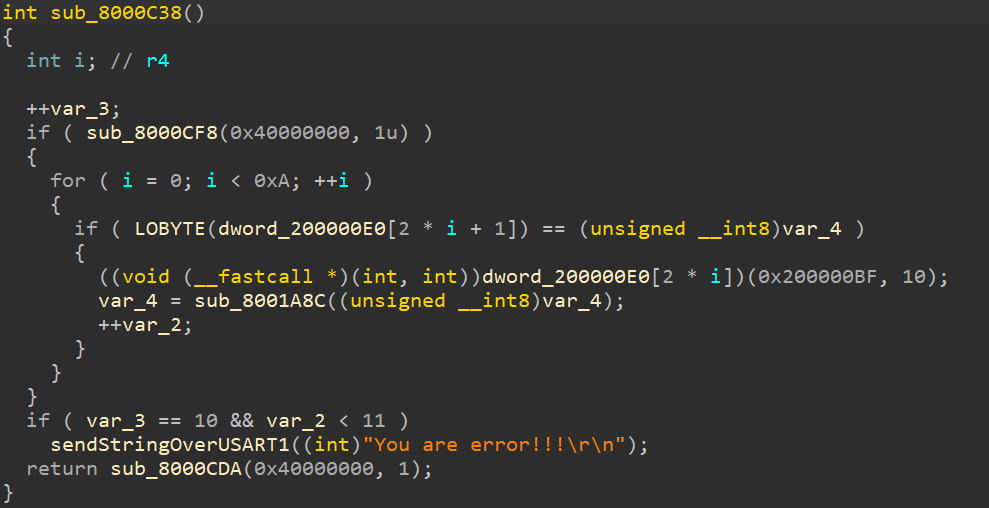
下图为验证代码,其中重点关注0x200000E0中的数据是如何来的。
发现0x200000E0的赋值语句:
其中0x200000BF的来源如下,是来源于输入:
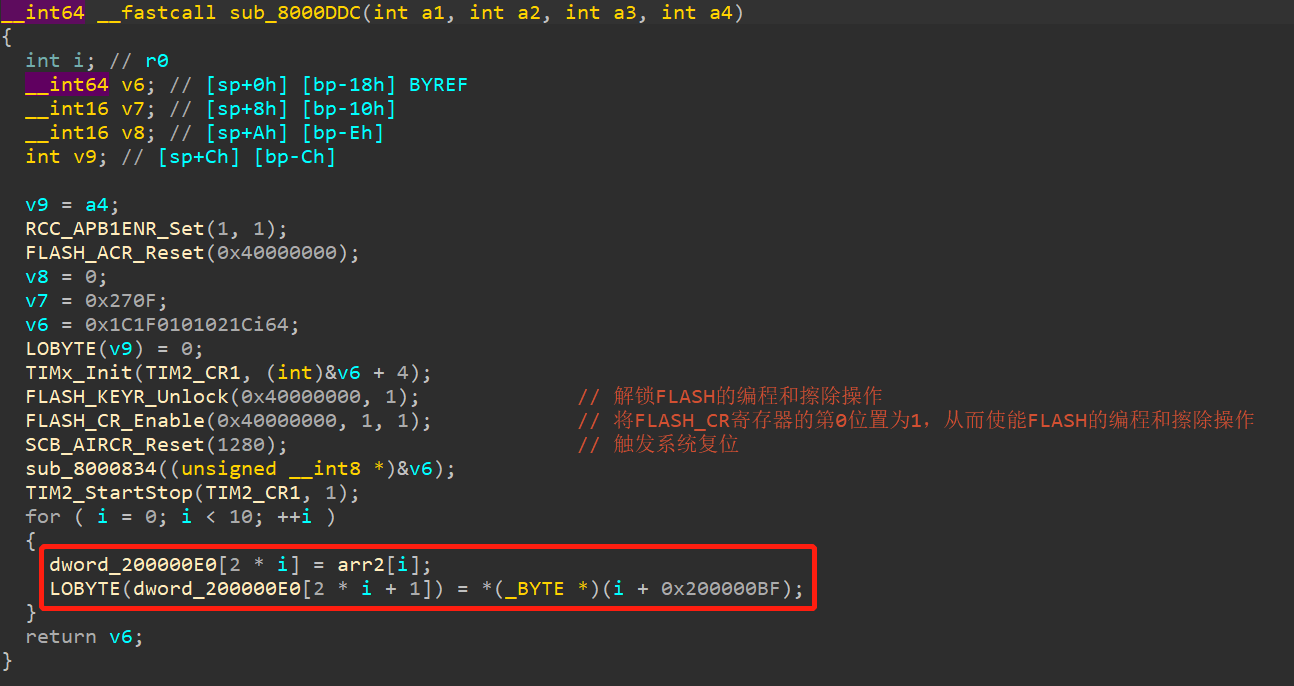
下面看arr2(0x20000024)的来源,可以查找到:
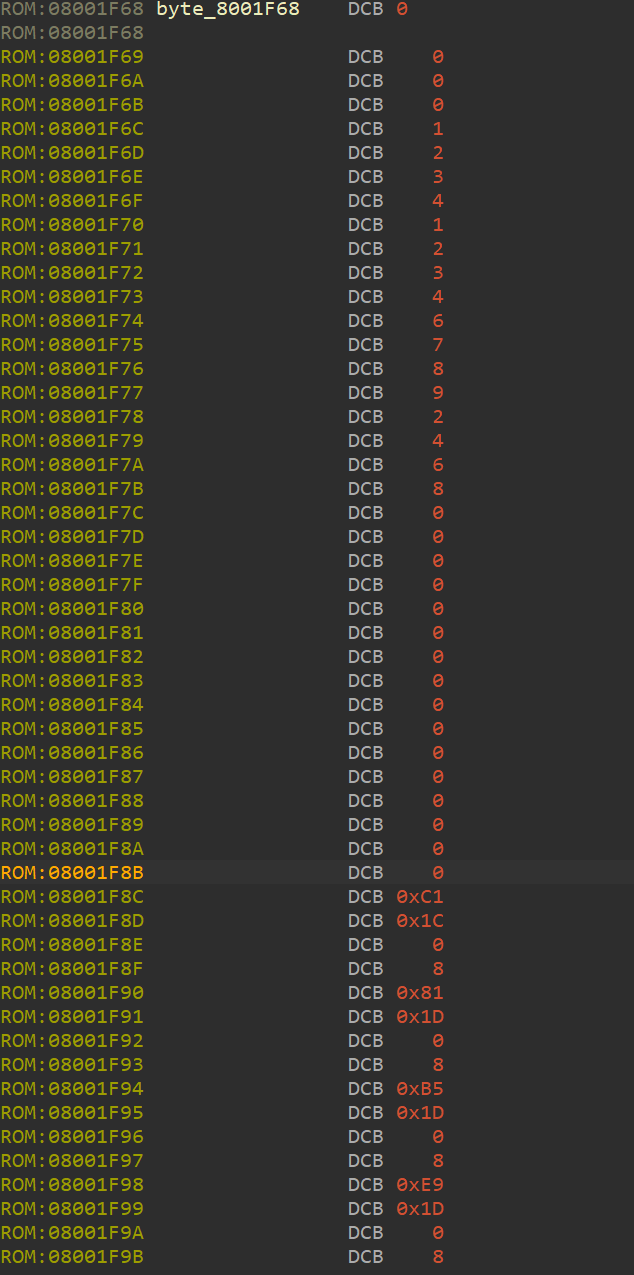
可以看出,arr2的值是来源于0x8001F68,跟踪一下:
OK,程序大体运行流搞清楚了。
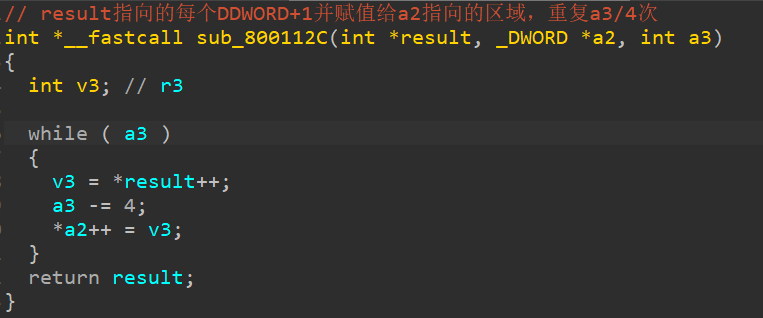
(1)sub_800112C函数给arr2赋值,最终,arr2如下:
[0x8001CC1,0x8001D81,0x8001DB5,0x8001DE9,0x8001E1D,0x8001E55,0x8001E95,0x8001ED1,0x8001F0D,0x8001C8D]。
(2)dword_200000E0[2*i] = arr2[i]。
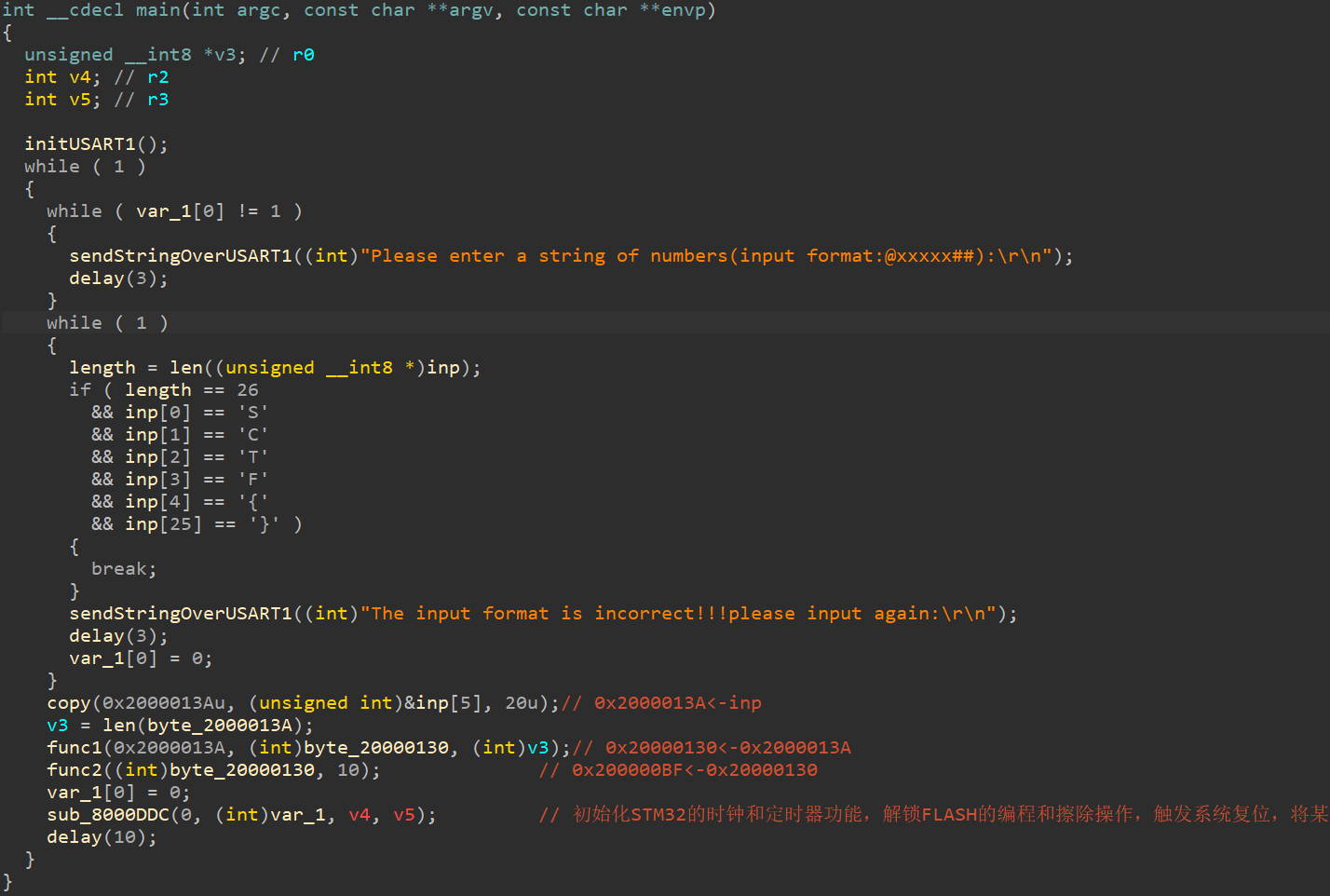
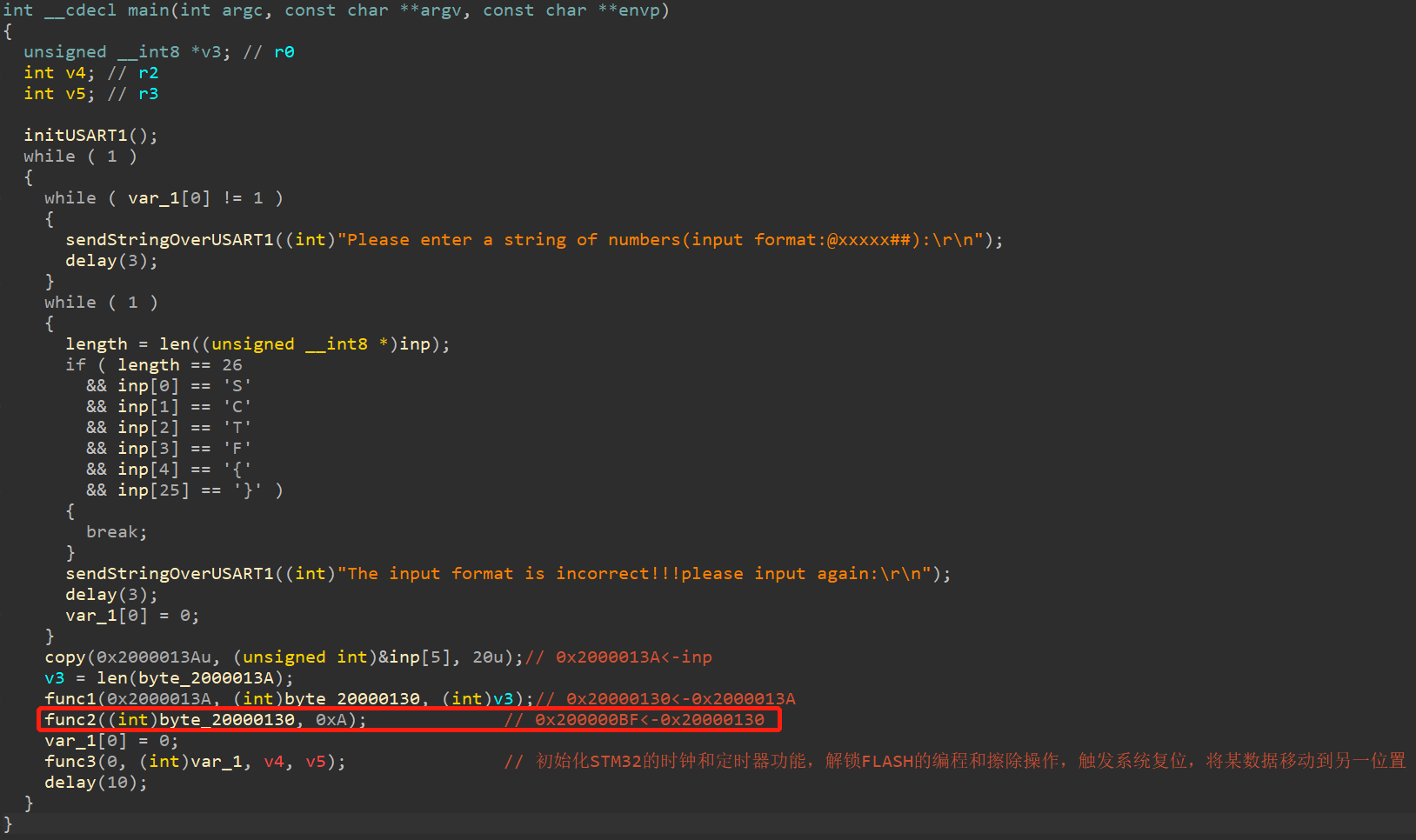
(3)输入为SCTF{xxx},长度为26,并将中间的xxx赋值给0x2000013A。
(4)对0x2000013A进行如下操作,并将结果赋值给0x20000130。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 for i in range(0, 20, 2): if src[i] < '0' or src[i] > '9': if src[i] < 'a' or src[i] > 'f': v5 = 3 else: v5 = src[i] - 'W' else: v5 = src[i] - '0' if src[i+1] < '0' or src[i+1] > '9': if src[i+1] < 'a' or src[i+1] > 'f': v6 = 0 else: v6 = src[i+1] - '0' det[i//2] = v6 + 16 * 5
(5)0x20000130赋给0x200000BF,var_4 = 'w',var_2 = 0,var_3=0。
(6)dword_200000E0[2*i+1] = 0x200000BF[i]。
(7)进行如下操作:
1 2 3 4 5 6 var_3 += 1 for i in range(10): assert var_4 == dword_200000E0[2*i+1] dword_200000E0[2*i](0x200000BF, 10) var_4 = (((var_4 >> 6) & (var_4 >> 2) & 1) == 0) | ((2 * var_4) & 0x7f) var_2 += 1
如果var_4 == dword_200000E0[2*i+1]一直成立,则输入正确。
arr2每个函数的功能如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 sub_8001CC0(a1): byte_200000B4[var_2 % 11] = 'a' byte_200000B4[++var_2 % 11] = 0 if var_2 == 10: if sub_8000156(byte_200000B4, "bdgfciejha"): fail else: sub_80019E8(0x200000C9, a1, 10) 0x200000C9 is flag sub_8000156(a1, a2): i = 0 while True: if a1[i] != a2[i] or !a1[i]: break i += 1 return a1[i-1] - a2[i-1] sub_8001D80(a1, a2): byte_200000B4[var_2 % 11] = 'b'; for i in range(a2): a1[i] -= 1 sub_8001DB4(a1, a2): byte_200000B4[var_2 % 11] = 'c'; for i in range(a2): a1[i] += 1 sub_8001DE8(a1, a2): byte_200000B4[var_2 % 11] = 'd'; for i in range(a2): a1[i] ^= '5' sub_8001E1C(a1, a2): byte_200000B4[var_2 % 11] = 'e'; for i in range(a2): a1[i] ^= a1[9-i] sub_8001E54(a1, a2): byte_200000B4[var_2 % 11] = 'f'; for i in range(a2): a1[i] ^= a1[i+1-a2*((i+1)//a2)] sub_8001E94(a1, a2): byte_200000B4[var_2 % 11] = 'g'; for i in range(a2): a1[i] = (16 * a1[i]) | (a1[i] >> 4) sub_8001ED0(a1, a2): byte_200000B4[var_2 % 11] = 'h'; for i in range(a2): a1[i] = (a1[i] << 6) | (a1[i] >> 2) sub_8001F0C(a1, a2): byte_200000B4[var_2 % 11] = 'i'; for i in range(a2): a1[i] = (a1[i] * 32) | (a1[i] >> 3) sub_8001C8DA(a1, a2): byte_200000B4[var_2 % 11] = 'j'; for i in range(a2): a1[i] ^= 0xF7
最后写脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 ''' # @Time : 2023/07/03 15:46:03 # @Author: wd-2711 ''' def sub_8001CC0 (a2 ): res = [0 for i in range (25 )] for i in range (0 , 20 , 2 ): if (a2[i//2 ] & 0xF ) > 9 : res[i+1 ] = (a2[i//2 ] & 0xF ) + 87 else : res[i+1 ] = (a2[i//2 ] & 0xF ) + 48 if (a2[i//2 ] >> 4 ) > 9 : res[i] = (a2[i//2 ] >> 4 ) + 87 else : res[i] = (a2[i//2 ] >> 4 ) + 48 return res def sub_8001D80 (a1, a2 ): for i in range (a2): a1[i] -= 1 return a1 def sub_8001DB4 (a1, a2 ): for i in range (a2): a1[i] += 1 return a1 def sub_8001DE8 (a1, a2 ): for i in range (a2): a1[i] ^= ord ('5' ) return a1 def sub_8001E1C (a1, a2 ): for i in range (a2): a1[i] ^= a1[9 -i] return a1 def sub_8001E54 (a1, a2 ): for i in range (a2): a1[i] ^= a1[i+1 -a2*((i+1 )//a2)] return a1 def sub_8001E94 (a1, a2 ): for i in range (a2): a1[i] = (16 * a1[i]) | (a1[i] >> 4 ) a1[i] = a1[i] & 0xff return a1 def sub_8001ED0 (a1, a2 ): for i in range (a2): a1[i] = (a1[i] << 6 ) | (a1[i] >> 2 ) a1[i] = a1[i] & 0xff return a1 def sub_8001F0C (a1, a2 ): for i in range (a2): a1[i] = (a1[i] * 32 ) | (a1[i] >> 3 ) a1[i] &= 0xff return a1 def sub_8001C8A (a1, a2 ): for i in range (a2): a1[i] ^= 0xF7 return a1 var_4 = [ord ('w' )] for i in range (1 , 10 ): tmp = (((var_4[i-1 ] >> 6 ) & (var_4[i-1 ] >> 2 ) & 1 ) == 0 ) | ((2 * var_4[i-1 ]) & 0xff ) var_4.append(tmp) origin_200000BF = [0 ] * len (var_4) i = 0 for c in "bdgfciejha" : origin_200000BF[ord (c) - ord ('a' )] = var_4[i] i += 1 arr_200000BF = sub_8001D80(origin_200000BF, 10 ) arr_200000BF = sub_8001DE8(arr_200000BF, 10 ) arr_200000BF = sub_8001E94(arr_200000BF, 10 ) arr_200000BF = sub_8001E54(arr_200000BF, 10 ) arr_200000BF = sub_8001DB4(arr_200000BF, 10 ) arr_200000BF = sub_8001F0C(arr_200000BF, 10 ) arr_200000BF = sub_8001E1C(arr_200000BF, 10 ) arr_200000BF = sub_8001C8A(arr_200000BF, 10 ) arr_200000BF = sub_8001ED0(arr_200000BF, 10 ) res = sub_8001CC0(arr_200000BF) print ("SCTF{" , end = "" )for i in res[:20 ]: print (chr (i), end = "" ) print ("}" )
hidden_in_the_network 1 2 你能帮助Sophia找到Christopher吗? Tips:压缩包中的三个附件几乎是一样的,只是略有不同,只需解决一个就可以了
发现是Go语言的64位程序。使用Go_parser 处理一下(使用的话是alt+F7执行go_parser.py脚本)。报异常Exception: Failed to find firstmoduledata address!,找不到第一个模块的地址。对main_1->main_4都是这样,且使用bindiff发现函数都是一样的,猜测bindiff只比较两个库的函数,四个文件中在某些代码或数据并不同。使用010editor进行比较,大多都相同。打算先从main_1入手。
换了个golang_loader_assist插件,找不到函数。打算先看看Go二进制文件逆向分析从基础到进阶(完结篇) 。
换成ida7.7,妈的竟然有作用了,也不知道为啥。
将main_main_func1与main_main_func2的call runtime_morestack给nop掉,这样就不会反汇编错误了。call runtime_morestack是为了扩展堆栈的,因为被调用函数的堆栈由调用者维护,所以要时常扩展。静态分析中没啥用,所以nop掉了。
0x00 main_1的分析 main_init_0 首先分析main_init_0:
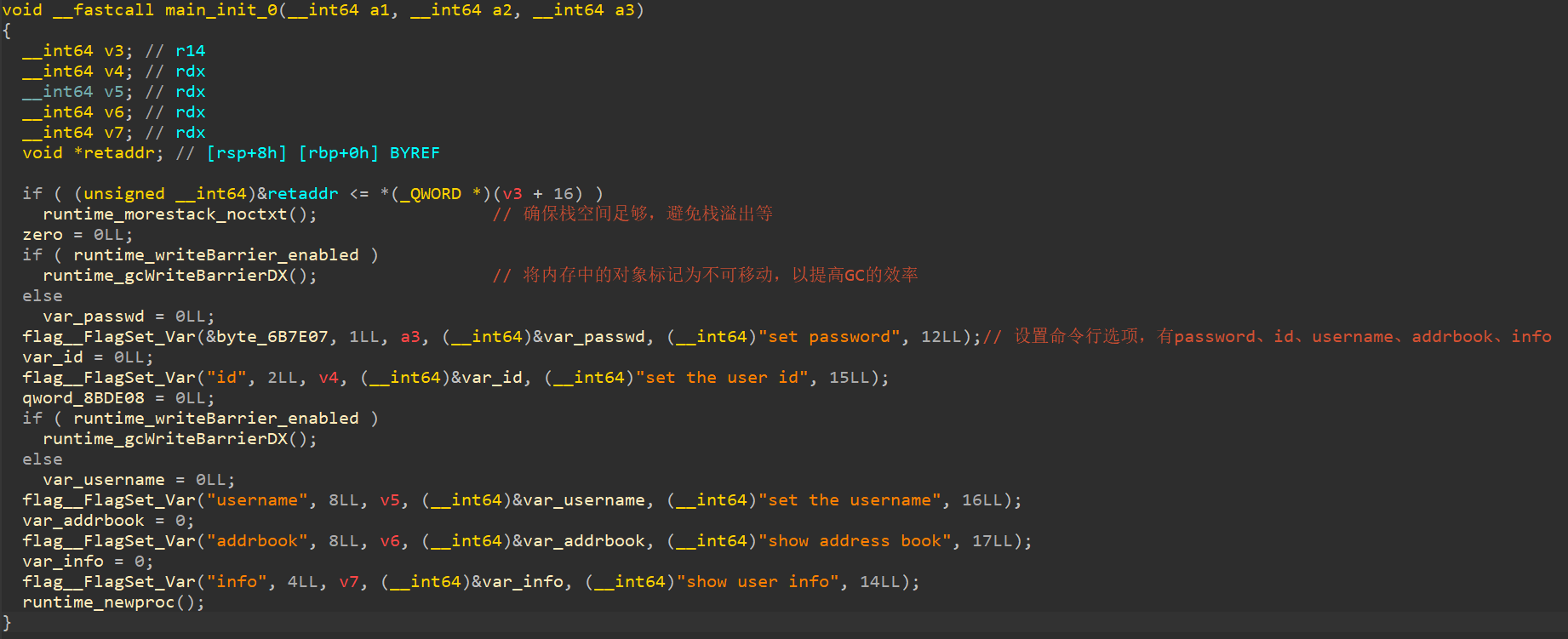
此函数大概流程如下:
(1)设置命令行参数p、id、username、addrbook、info,并分别赋值给变量var_passwd、var_id、var_username、var_addrbook、var_info。
main_main 之后,分析main_main函数:
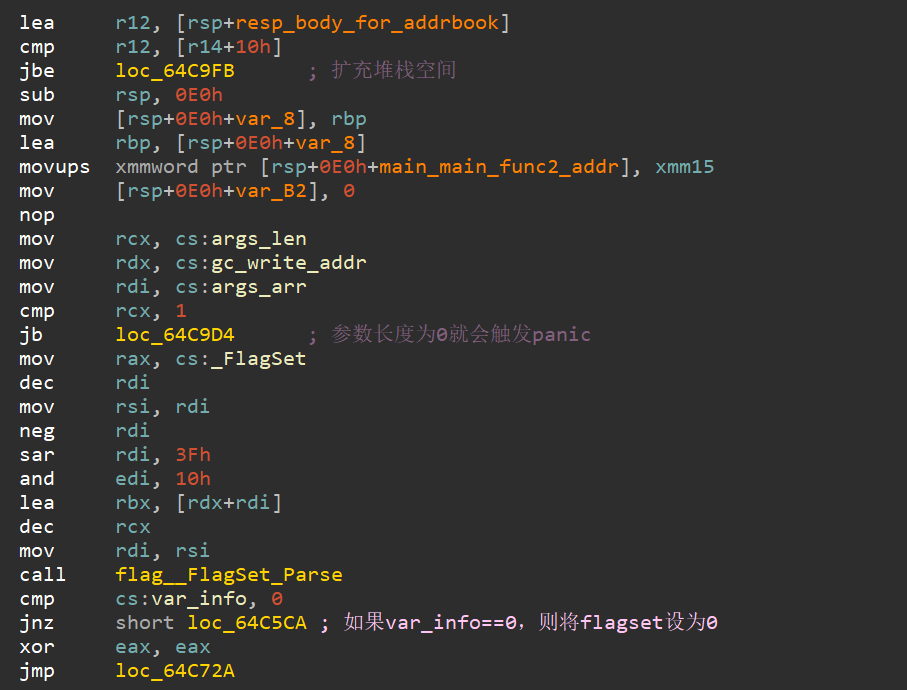
(1)对命令行参数使用flag__FlagSet_Parse进行分割,并将参数个数赋值给变量zero(猜测),若参数个数小于5,则直接退出程序。
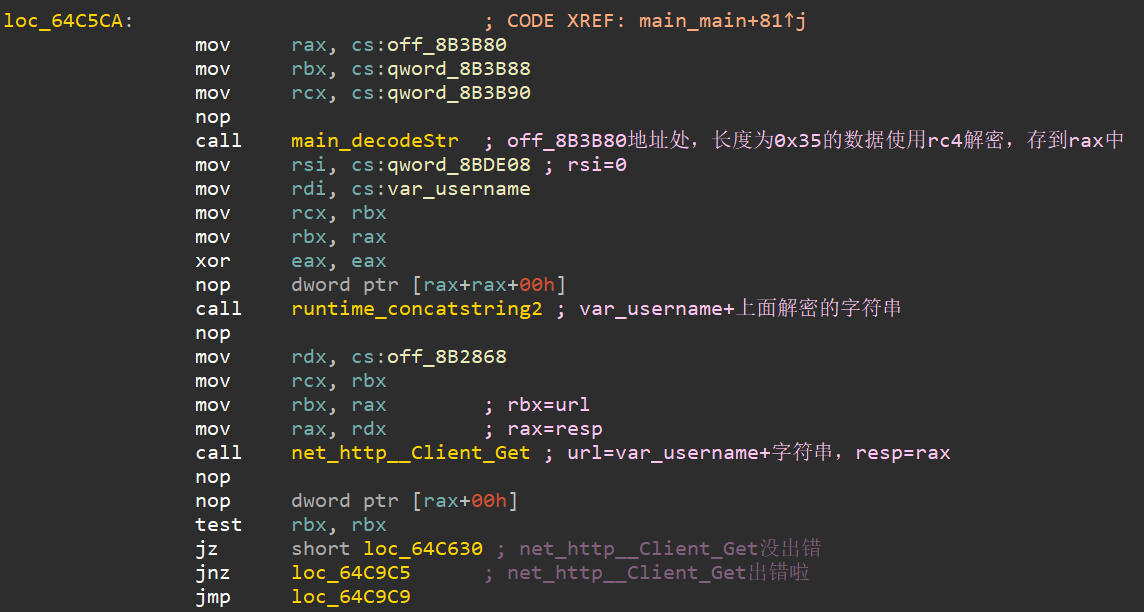
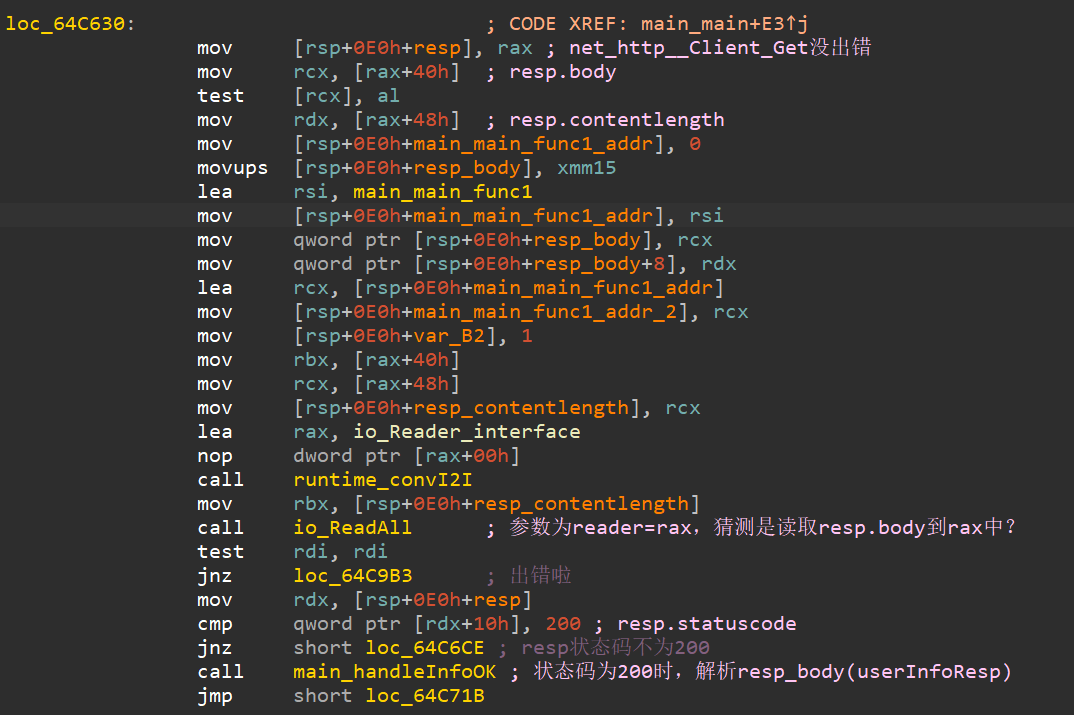
(2)使用main_decodeStr对off_8B3B80处长度为0x35的数据使用rc4解密。注意,main_decodeStr默认密钥为:[0xFF, 0xEE, 0xDD, 0xCC, 0xBB, 0xAA, 0x99, 0x88, 0x77, 0x66, 0x55, 0x44, 0x33, 0x22, 0x11, 0]。并使用net_http__Client_Get函数对url=off_8B3B80_decode||var_username进行访问。
(3)若返回值resp的状态码不为200,则直接进入解析addrbook环节。否则,则进入main_handleInfoOK函数,解析resp.body。
(4)判断是否有var_addrbook这个参数,如果没有,则进入(8);否则,进入(5),以解析addrbook参数。
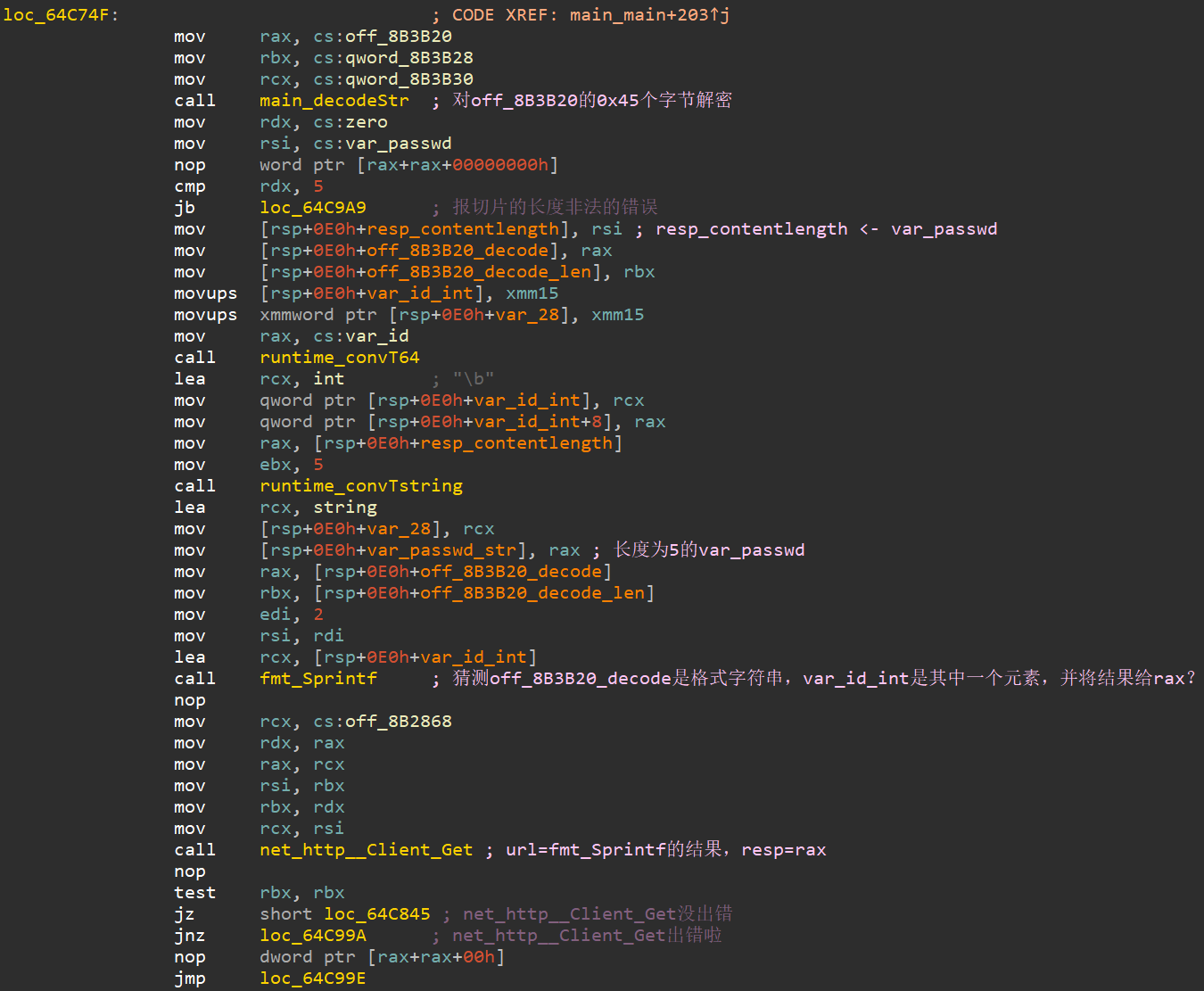
(5)使用main_decodeStr,对off_8B3B20的0x45个字节解密。这是一个格式字符串,在其中添加var_id与var_passwd(var_passwd取前5位),并将其作为一个url,使用net_http_Client_Get访问。
(6)使用main_handleAddrBookOK函数对resp.body进行解析。
(7)运行main_main_func2函数,此函数运行逻辑如下:
(a)执行resp_body_for_addrbook+18h。
(8)运行main_main_func1函数。
(a)执行resp_body_for_userInfo+18h。
main_handleInfoOK 此函数逻辑如下:
(1)调用main_decryptoJSONByte对resp.body做解密。(下面子流程是main_decryptoJSONByte的步骤)
(a)使用main_decodeStr对off_8B3BA0处长度为0x8的数据使用rc4解密。
(b)将步骤(a)解密出的数据当作rc4密钥,对resp.body做解密。
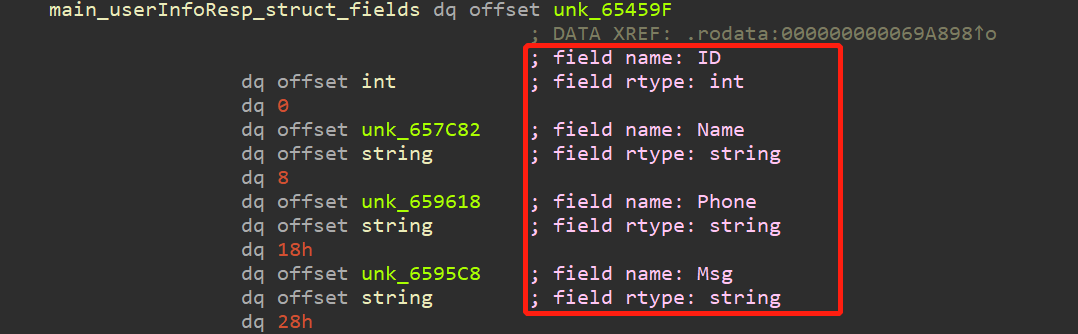
(2)将resp.body结构化,最终可以获得:{ID:xx,Name:xx,Phone:xxx,Msg:xxx}。
(3)使用main_decodeStr,分别对off_8B3BC0、off_8B3BE0、off_8B3C00、off_8B3B60处长度为8、10、11、14的数据使用rc4解密,并将结果打印到终端。
main_handleAddrBookOK 此函数逻辑如下:
(1)与main_handleInfoOK的第1步相同。
(2)将resp.body结构化,最终可以获得:{Phones:xxx}。
(3)使用main_decodeStr,分别对off_8B3B40处长度为0x20的数据使用rc4解密,并将结果打印到终端。
0x01 题目思路 可以通过A查到B,然后从B查到C。那么我们就能得到:A如何查找到C,即Sophia到Christopher。
1 2 3 4 5 6 7 import idcst = 0x883C80 ed = 0x883CB5 for addr in range (st, ed): byte_data = idc.get_wide_byte(addr) print (hex (byte_data), end = " " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ''' # @Time : 2023/07/05 13:16:59 # @Author: wd-2711 ''' userinfo = [0xed ,0x2f ,0xd8 ,0x27 ,0xa8 ,0x8 ,0x4e ,0xb4 ,0xc1 ,0x69 ,0x97 ,0x2 ,0xa7 ,0x6b ,0x4f ,0xa7 ,0x39 ,0xeb ,0xa1 ,0x63 ,0x92 ,0x2d ,0xb3 ,0x1e ,0x58 ,0x91 ,0x24 ,0x10 ,0x3e ,0x91 ,0x88 ,0x7a ,0x2a ,0xf5 ,0x9a ,0xdc ,0x75 ,0x45 ,0xe0 ,0x43 ,0xdf ,0x11 ,0xf7 ,0x7d ,0x58 ,0x14 ,0x19 ,0x8c ,0x3a ,0x40 ,0xd ,0x6e ,0x7e ] userinfo = bytes (bytearray (userinfo)) addrbook = [0xed ,0x2f ,0xd8 ,0x27 ,0xa8 ,0x8 ,0x4e ,0xb4 ,0xc1 ,0x69 ,0x97 ,0x2 ,0xa7 ,0x6b ,0x4f ,0xa7 ,0x39 ,0xeb ,0xa1 ,0x63 ,0x92 ,0x2d ,0xb3 ,0x1e ,0x58 ,0x91 ,0x24 ,0x1f ,0x24 ,0x89 ,0x8f ,0x32 ,0x30 ,0xf3 ,0xda ,0xde ,0x67 ,0x44 ,0xf6 ,0x58 ,0xd4 ,0x4 ,0xeb ,0x20 ,0x42 ,0x8 ,0x17 ,0xc1 ,0x21 ,0x52 ,0x5 ,0x79 ,0x2a ,0xdc ,0x95 ,0x9d ,0xc5 ,0x59 ,0x20 ,0xc0 ,0xc2 ,0xf4 ,0x69 ,0xaf ,0x60 ,0x97 ,0x9f ,0x76 ,0x25 ] addrbook = bytes (bytearray (addrbook)) def main_decode_str (data ): key = [0xFF , 0xEE , 0xDD , 0xCC , 0xBB , 0xAA , 0x99 , 0x88 , 0x77 , 0x66 , 0x55 , 0x44 , 0x33 , 0x22 , 0x11 , 0 ] key = key[::-1 ] key = bytearray (key) key = bytes (key) enc = ARC4.new(key) res = enc.decrypt(data) res = str (res,'gbk' ) return res print (main_decode_str(userinfo))print (main_decode_str(addrbook))
由于http://190.92.230.233:8080已无法访问,因此无法进行下去。考虑接下来的步骤:
(1)访问http://190.92.230.233:8080/nologin/userinfo?username=sophia,并解析,获得其ID,name,phone,Msg。之后,访问http://190.92.230.233:8080/auth/showaddressbook?userid=sophia.id&password=xxx,由于password共5位,因此可以遍历获得密码,从而获得sophia的addrbook。
(2)类似(1)的方法,最终找到christopher,猜测在其Msg信息中就有其flag。
0x02 Nu1L’s WP 真实的解题步骤更加复杂。
(1)使用sqlmap可以发现http://190.92.230.233:8080/nologin/userinfo?username=xx存在sql注入,爆破得到所有用户的信息(共50个)。
(2)爆破所有用户的密码,从而获得所有用户的addrbook。
(3)使用nx.Graph,画出社交关系图。并使用nx.dijkstra_path找出最短路径。最终,flag=sctf{md5(path)}。但是我猜测,其实就是用main1-4一个一个找。
checkFlow 1 2 Input the flow to test the channel.(输入流量以测试通道) flag format:sctf{Caps MD5}(flag格式:`sctf{Caps MD5}`)
64位ELF。显示为ABI。Linux ABI 4.4.0 定义了许多与操作系统交互的规则,包括系统调用(system call)的参数和返回值、函数调用的参数和返回值、异常处理、动态链接等方面的内容。它规定了二进制可执行文件应该如何与操作系统进行交互,从而实现二进制兼容性。 猜测类似于一个linux的dll库(其实这种猜测是不准确的,具体看什么是ABI ,简略说:ABI是一组规则,规定了数据类型占几个字节、函数调用传哪些参数等),运行之后则是一个真实程序(要求输入Flow,并作检查)。因此,猜测此文件与linux的交互都用api实现了,并静态编译到此文件中。
经过好几天的分析,这个还挺麻烦的,主要是没有符号表,所有函数都得手动看。总结一下这个题目的流程:
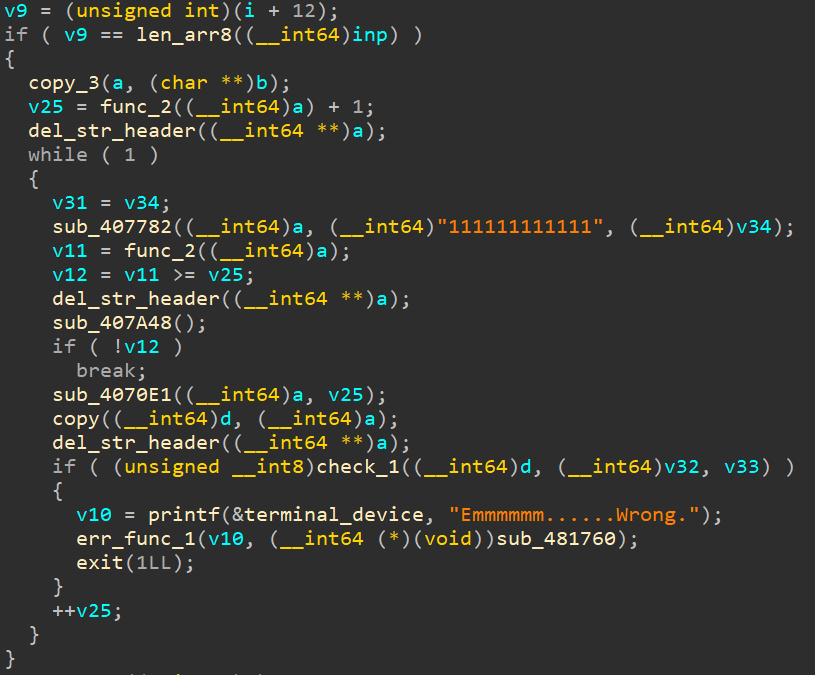
(1)输入长度为12的整数倍的0/1字符串。字符串c='000000000000'。
(2)每次取12位字符str,之后check_1检验,若函数返回0则失败。
(3)v23 = -1 or func_2(c)。
(4)若v23 >= func_2(str),则失败。
(5)再次做检验,重点函数为sub_4070E1和check_1。如下所示:
(6)当马上到字符串结尾时,再次做检验,如下所示:
此题的逻辑不难,难的是函数的分析,其中sub_4070E1与check_1函数很难分析,里面层层嵌套,非常容易令人混乱。wp如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 ''' # @Time : 2023/07/10 20:34:43 # @Author: wd-2711 ''' import hashlibdef func_2 (str1 ): res = 0 for i in range (0xC , 0 , -1 ): if str1[0xC -i] == '1' : res |= (1 <<((i-1 )&0x3F )) return res def sub_4070E1 (str1, j ): def count_head_zero (j ): if j == 0 : return 0xC j = bin (j)[::-1 ] cnt = 0 for jj in j: if jj == '1' : break elif jj == '0' : cnt += 1 return cnt def sub_4087C6 (j, i ): if i+1 > 0x3F : return 0xC if j>>(i+1 ) == 0 : return 0xC return count_head_zero(j>>(i+1 ))+(i+1 ) j = j & 0xfff str1 = "000000000000" result = count_head_zero(j) i = result while True : if i > 0xB : break str1 = str1[:0xB -i] + '1' + str1[0xB -i+1 :] result = sub_4087C6(j, i) i = result return str1 def check_1 (inp ): inp = [ord (i) - 48 for i in inp] arr1 = [ [1 , 1 , 0 , 0 , 1 , 0 ,], [1 , 0 , 1 , 1 , 0 , 0 ,], [1 , 0 , 1 , 0 , 1 , 0 ,], [0 , 1 , 1 , 0 , 1 , 0 ,], [1 , 1 , 0 , 0 , 1 , 0 ,], [1 , 0 , 0 , 1 , 0 , 1 ,], [0 , 1 , 1 , 1 , 0 , 0 ,], [1 , 1 , 0 , 0 , 0 , 1 ,], [0 , 0 , 1 , 1 , 1 , 0 ,], [1 , 1 , 0 , 1 , 0 , 0 ,], [0 , 0 , 0 , 1 , 1 , 1 ,], [1 , 0 , 1 , 0 , 0 , 1 ,], ] out = [0 ] * 6 for j in range (6 ): for k in range (0xC ): out[j] ^= (arr1[k][j]&inp[k]) if sum (out) == 0 : return 1 return 0 def generate_inps (): res = [] for i in range (0xfff +1 ): binary_string = bin (i)[2 :] bit_array = [int (bit) for bit in binary_string] if len (bit_array) < 0xC : bit_array = [0 ]*(0xC -len (bit_array)) + bit_array bit_array = "" .join(str (i) for i in bit_array) res.append(bit_array) return res def test_length (leng ): res = "" inps = generate_inps() c = "000000000000" i = 0 while True : for inp in inps: f = i if f >= leng: return 1 , res a = inp b = a if check_1(a) == 0 : continue if i: g = func_2(c) else : g = -1 if g >= func_2(a): continue j = g + 1 wrong = 0 while True : a = b if j >= func_2(a): break a = sub_4070E1(a, j) if check_1(a): wrong = 1 break j += 1 if wrong == 0 : res += inp pass else : continue if i + 12 == leng: a = b e = func_2(a) + 1 while True : a = "111111111111" if func_2(a) < e: break a = sub_4070E1(a, e) if check_1(a): return 0 , None e += 1 c = b i += 12 if __name__ == "__main__" : for i in range (1 , 1000 ): suc, res = test_length(12 * i) if suc == 1 : print ("success length" , 12 * i) print ("res" , res) m = hashlib.md5() m.update(res.encode()) print ("flag is" , m.hexdigest())
W&M没做出来,Nu1L是用frida做的,没太看懂。感觉是用frida动调,使用程序自己的函数。将字符串输入,检验flag是否正确:
可以发现,没有报错,因此0/1字符串正确。
SycLock 1 2 3 4 题目flag为:flag{password0+password1+password2} 这是一个恶意app,尽量跑在模拟器或调试机上(>=Android5.0),必要时通过adb uninstall packagename卸载。此app仅供本次比赛使用,不要随意转发给他人。 点击后等待30s左右便会开始锁机,测过Android7模拟器,Android10 pixel2真机,均可正常运行。 玩的愉快。
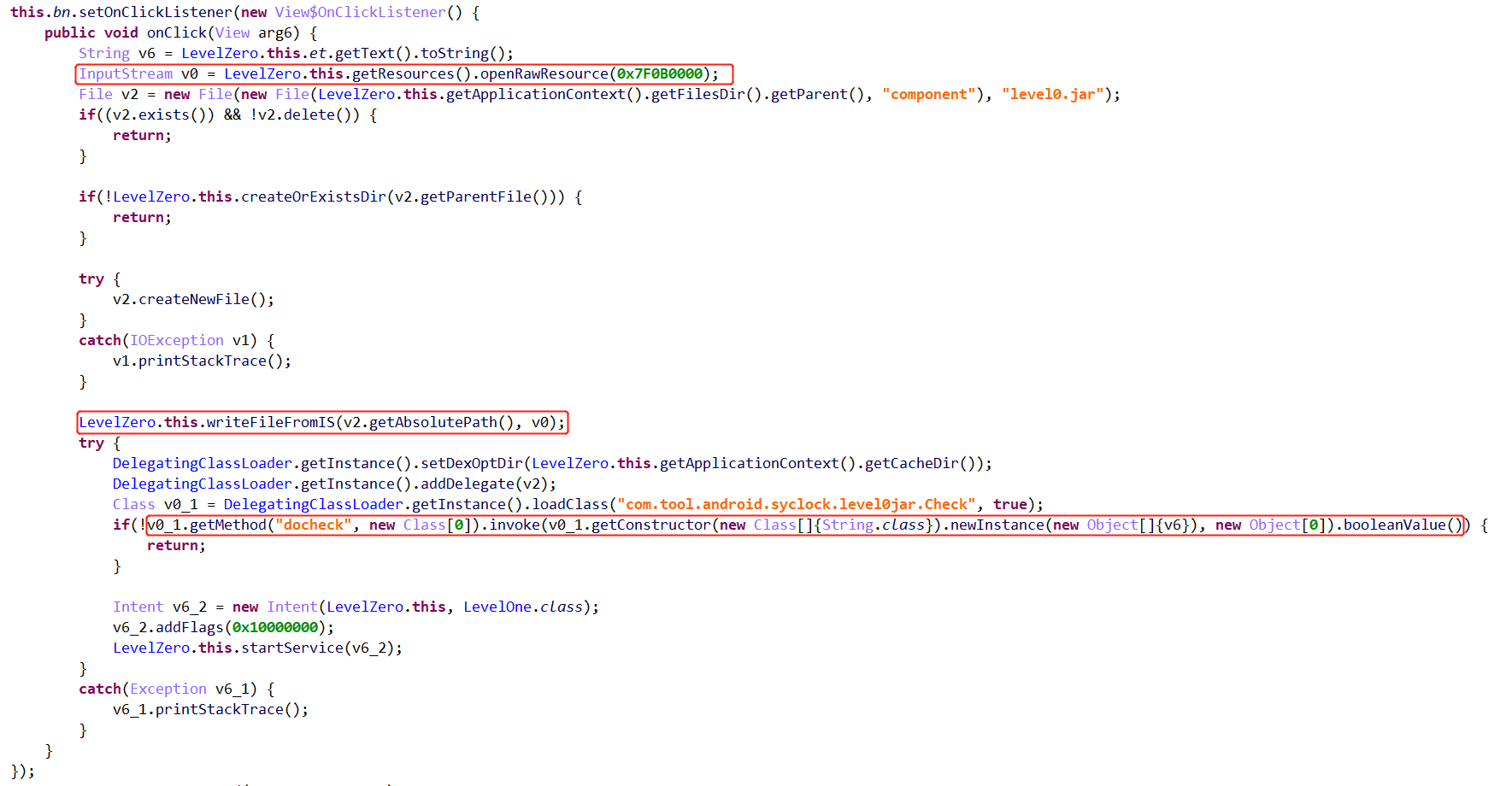
0x00 level0 审计代码,其重点如下:
此程序逻辑为:将原始level0.jar中的数据,使用writeFileFromIS函数处理,并重新写入到level0.jar中,之后调用level0.jar中的Check.docheck函数,参数为password0=xxx。writeFileFromIS函数逻辑如下:
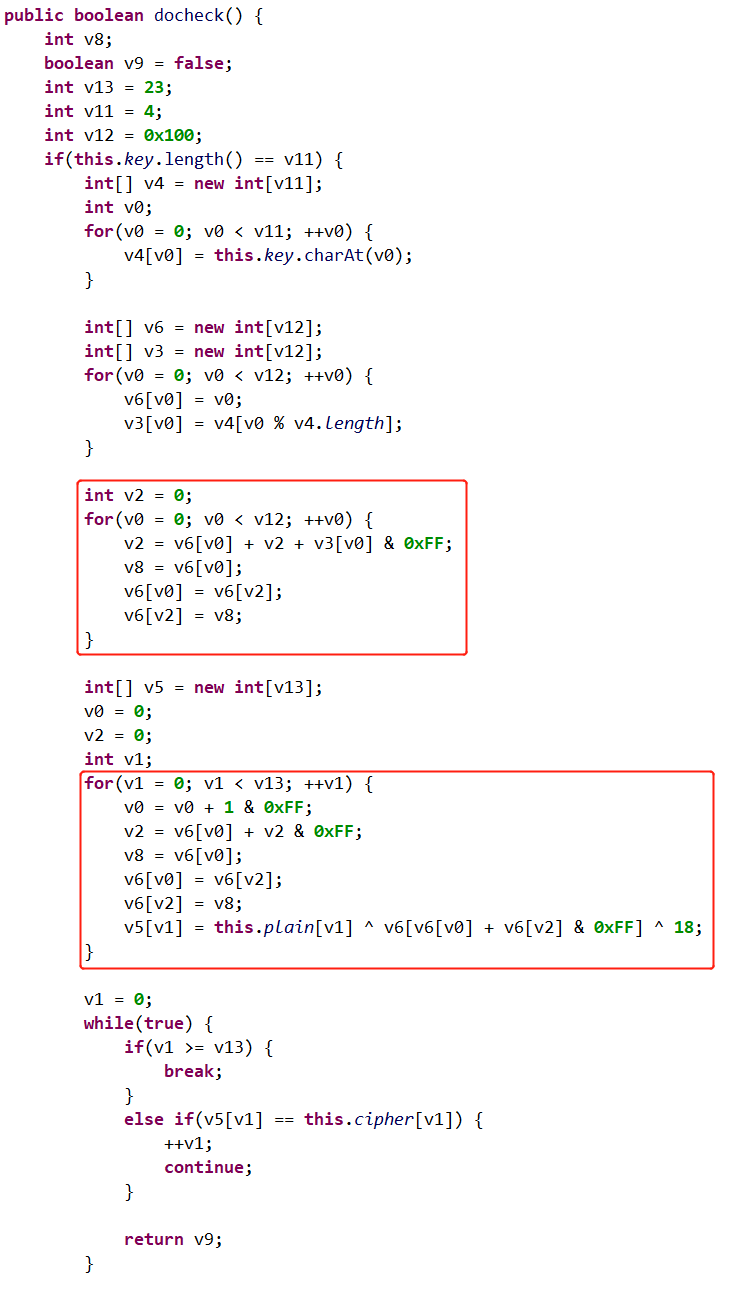
是一个简单的异或,最终可以得到level0_decode.jar。其重要代码如下:
不知道是什么加密算法(RC4?),反正最终遍历就可以得到password0=good。
0x01 level1
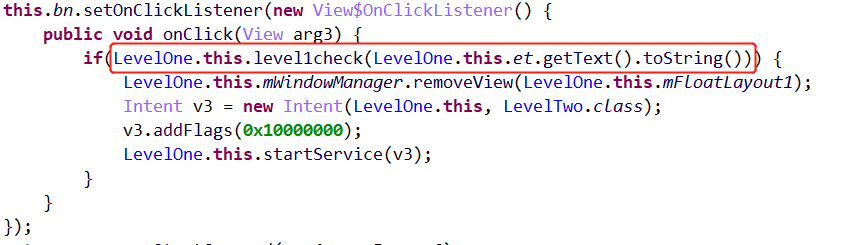
其中,level1check函数是从liblevel1.so中导入的。
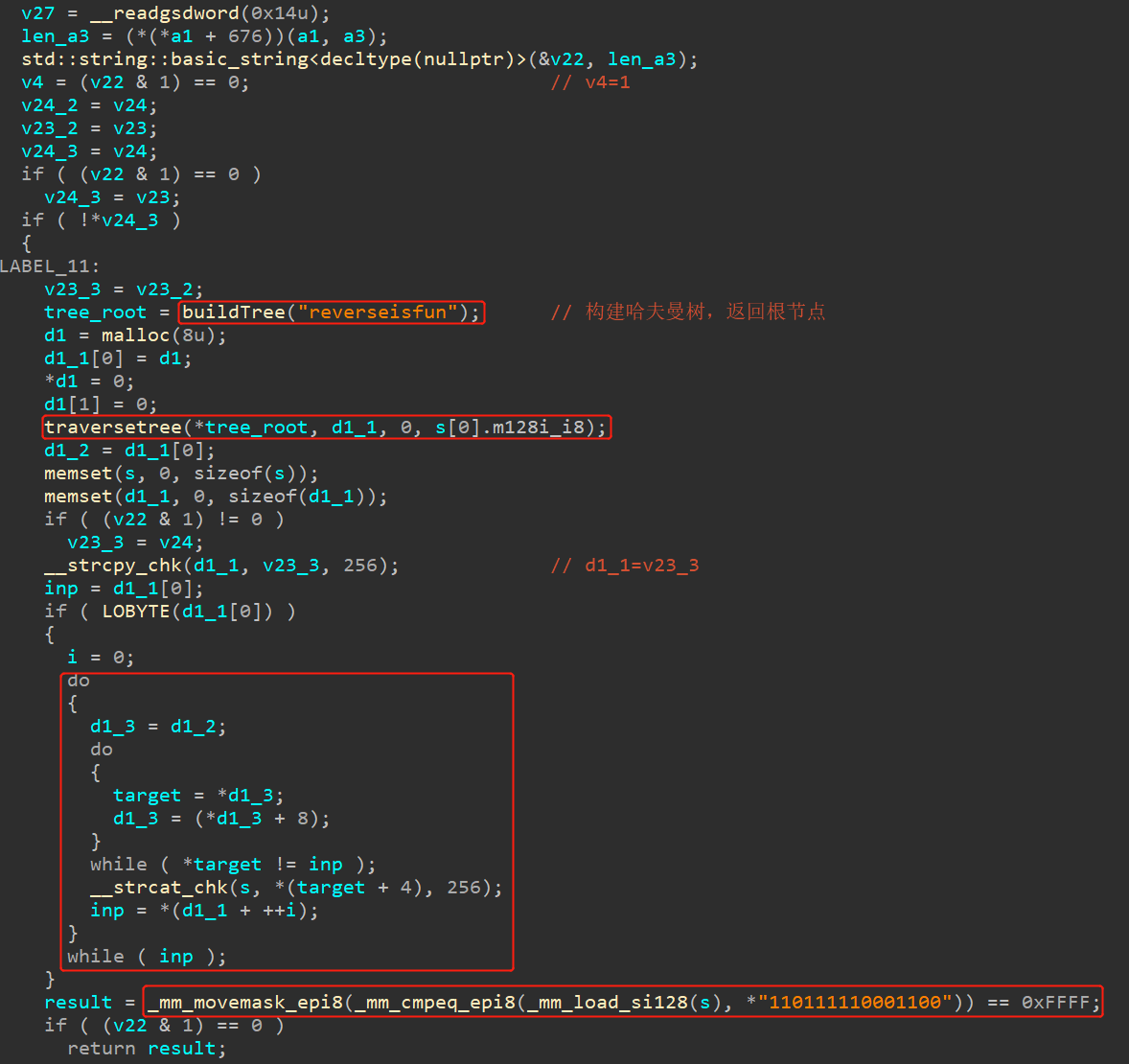
buildTree函数是构建一个哈夫曼树,其逻辑如下:
(1)统计reverseisfun字符串出现频次,并按照26个英文字母先后顺序来排序。
1 2 3 4 5 6 7 8 e:3 f:1 i:1 n:1 r:2 s:2 u:1 v:1
(2)之后将出现频次按顺序压入到一个sortqueue,最终可以得到:
1 v:1 -> u:1 -> n:1 -> i:1 -> f:1 -> s:2 -> r:2 -> e:3
(3)每次取出sortqueue的头两个元素,第一个元素为左节点,第二个元素为右节点,把这两个节点合并,并重新压入sortqueue。
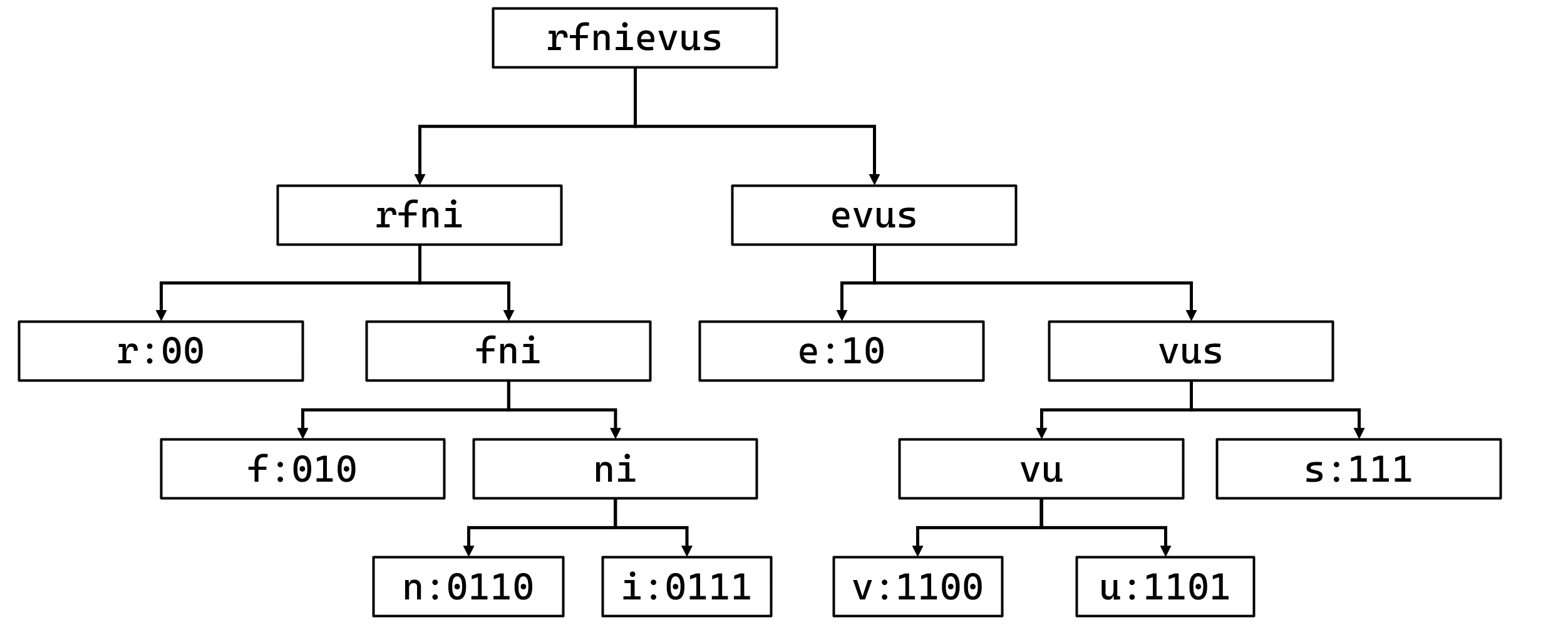
(4)最终可以得到哈夫曼树如下(其中traversetree用于给树的叶子节点添加诸如00/0110的路径符号):
得到此树之后,由于要匹配110111110001100,因此可以得到password1=userv
0x02 level2
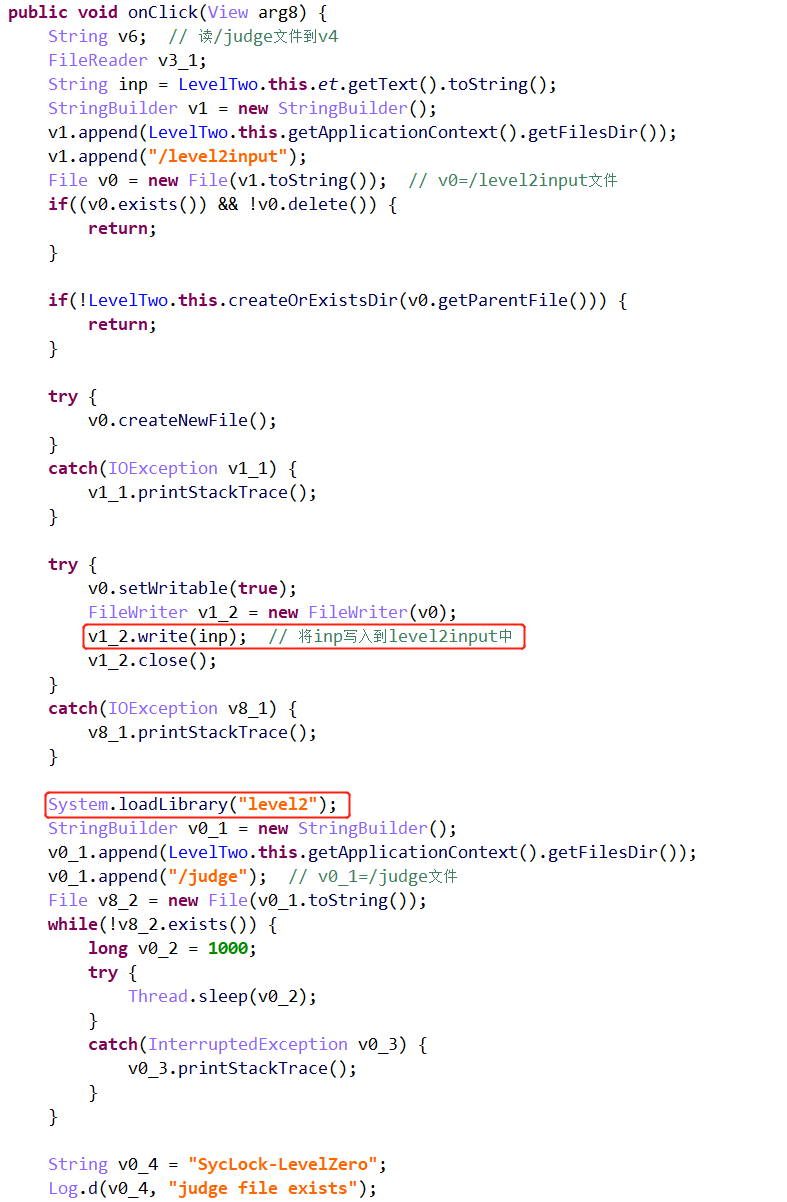
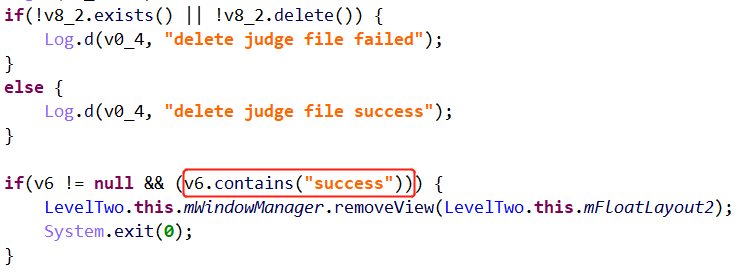
上述逻辑为:将输入写入到/level2input文件中,并通过check(并未体现),检查生成的/judge文件中是否包含success,若有则挑战成功。
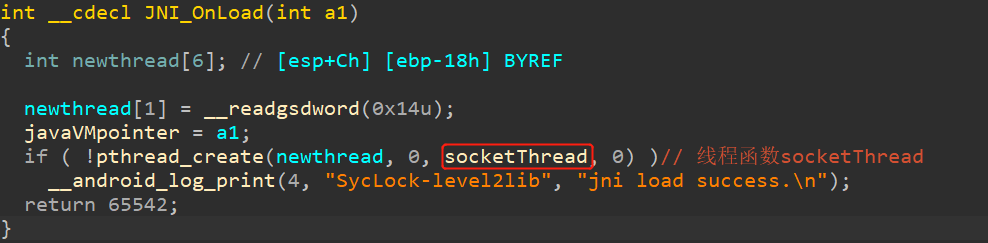
那check()体现在哪里呢?体现在LoadLibrary("level2")那里。在导入liblevel2.so库时,默认会自动运行JNI_OnLoad方法,如下图所示:
跟进socketThread,可以跟进到extractLevel2函数。
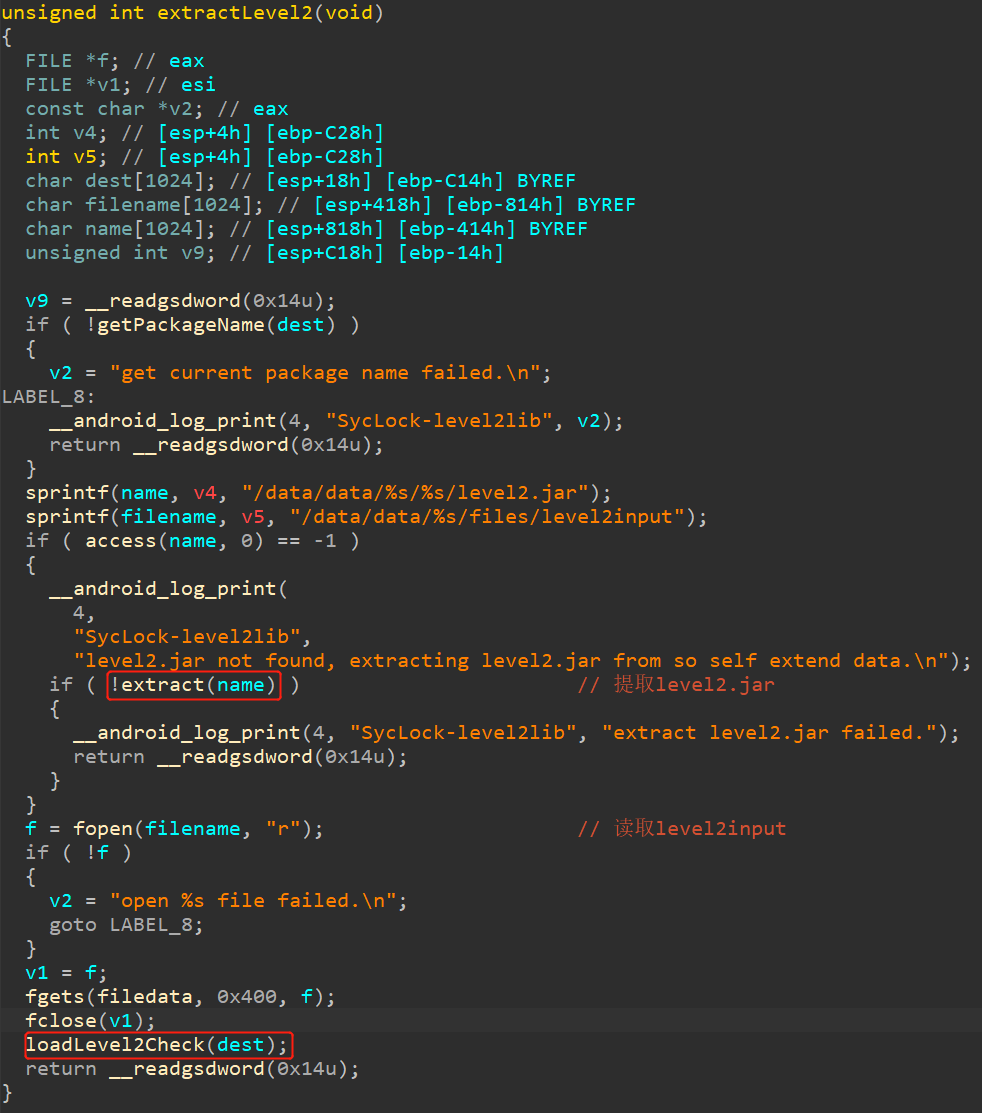
其中extract是提取level2.jar所用,跟进:
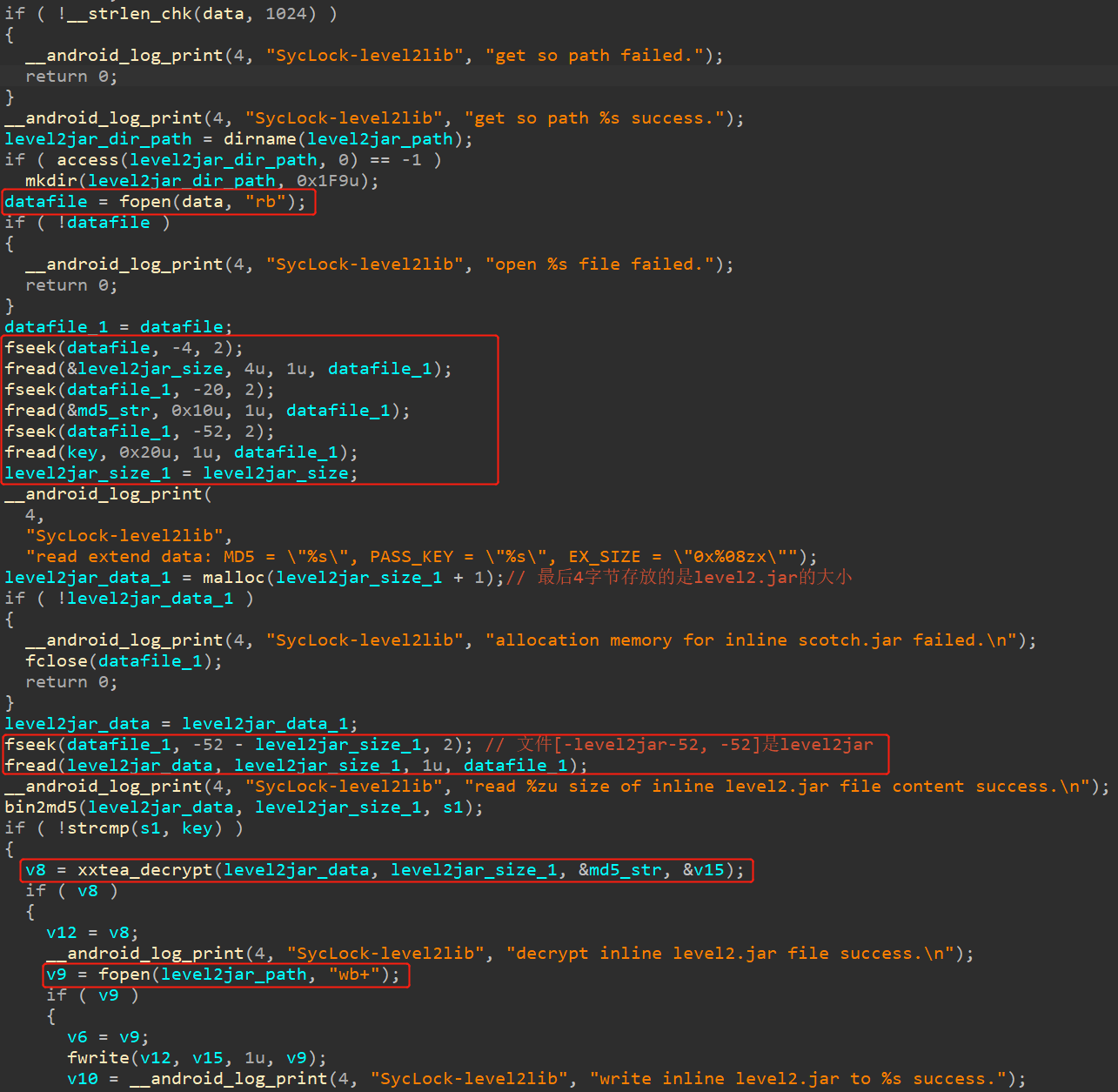
可以发现,此函数读取liblevel2.so的最后4个字节,作为长度size。读取最后20到最后4字节,作为xxtea解密的key。读取最后[-52-size, -52]的字节,作为要解密的数据。最终将解密后的数据存入到level2.jar中。
按照上述流程进行操作,可以得到level2.jar,如下所示:
可以得到password2=4ndroidisfun。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 ''' # @Time : 2023/07/12 21:39:58 # @Author: wd-2711 ''' import structfrom tqdm import tqdmfrom ctypes import c_uint32def challenge0 (): def decode_level0 (): with open ("C:\\Users\\23957\\Desktop\\Syclock\\level0jar" , "rb" ) as f: d = f.read() with open ("C:\\Users\\23957\\Desktop\\Syclock\\level0_decode.jar" , "wb" ) as f: for dd in d: inp = dd ^ 52 f.write(inp.to_bytes(1 , 'little' )) def change (a1, a2 ): return a2, a1 def get_flag (): plain = "flag{this_is_fake_flag}" cipher = [24 , 0xF8 , 37 , 0x86 , 70 , 16 , 0x92 , 0xDA , 0xD3 , 0x89 , 0xF4 , 4 , 0x7E , 0xB3 , 0xF7 , 92 , 206 , 77 , 0xAF , 34 , 0x7A , 14 , 0x9E ] v6 = [i for i in range (0x100 )] for k0 in tqdm(range (32 ,128 )): for k1 in range (32 ,128 ): for k2 in range (32 ,128 ): for k3 in range (32 ,128 ): k = [k0, k1, k2, k3] tmp = 0 v3 = [k[i%4 ] for i in range (0x100 )] for i in range (256 ): tmp = (v6[i] + tmp + v3[i]) & 0xff v6[i], v6[tmp] = change(v6[i], v6[tmp]) i = 0 out = [0 for i in range (23 )] tmp = 0 for j in range (23 ): i = (i + 1 ) & 0xff tmp = (tmp + v6[i]) & 0xff v6[i], v6[tmp] = change(v6[i], v6[tmp]) out[j] = ord (plain[j])^v6[(v6[i]+v6[tmp])&0xff ]^18 eq = 1 for i in range (23 ): if out[i] != cipher[i]: eq = 0 break if eq == 1 : print (chr (k), end = "" ) v6 = [i for i in range (0x100 )] print ("challenge0_flag:" , end = "" ) get_flag() print ("" ) def challenge1 (): print ("challenge2_flag:" , end = "" ) print ("userv" ) DELTA = 0x9E3779B9 def encrypt (v, n, k ): rounds = 6 + int (52 / n) sum = c_uint32(0 ) z = v[n - 1 ].value while rounds > 0 : sum .value += DELTA e = (sum .value >> 2 ) & 3 p = 0 while p < n - 1 : y = v[p + 1 ].value v[p].value += (((z >> 5 ^ y << 2 ) + (y >> 3 ^ z << 4 )) ^ ((sum .value ^ y) + (k[(p & 3 ) ^ e] ^ z))) z = v[p].value p += 1 y = v[0 ].value v[n - 1 ].value += (((z >> 5 ^ y << 2 ) + (y >> 3 ^ z << 4 )) ^ ((sum .value ^ y) + (k[(p & 3 ) ^ e] ^ z))) z = v[n - 1 ].value rounds -= 1 def decrypt (v, n, k ): rounds = 6 + int (52 / n) sum = c_uint32(rounds * DELTA) y = v[0 ].value while rounds > 0 : e = (sum .value >> 2 ) & 3 p = n - 1 while p > 0 : z = v[p - 1 ].value v[p].value -= (((z >> 5 ^ y << 2 ) + (y >> 3 ^ z << 4 )) ^ ((sum .value ^ y) + (k[(p & 3 ) ^ e] ^ z))) y = v[p].value p -= 1 z = v[n - 1 ].value v[0 ].value -= (((z >> 5 ^ y << 2 ) + (y >> 3 ^ z << 4 )) ^ ((sum .value ^ y) + (k[(p & 3 ) ^ e] ^ z))) y = v[0 ].value sum .value -= DELTA rounds -= 1 def challenge2 (): def get_level2jar (): with open ("C:\\Users\\23957\\Desktop\\Syclock\\liblevel2.so" , "rb" ) as f: d = f.read() size_tuple = (hex (d[-4 ]), hex (d[-3 ]), hex (d[-2 ]), hex (d[-1 ])) size = "" for s in size_tuple[::-1 ]: size += s[2 :] size = int (size, 16 ) st = -20 md5 = [] for i in range (16 ): md5.append(d[st+i]) md5_to_arr4 = [] for i in range (4 ): tmp = md5[i*4 :i*4 +4 ] tmp = tmp[::-1 ] tmp = "" .join(hex (t)[2 :] for t in tmp) md5_to_arr4.append(int (tmp, 16 )) st = -52 key = [] for i in range (0x20 ): key.append(d[st+i]) st = -52 - size filedata = [] for i in range (size): filedata.append(d[st+i]) cipher = [] for i in range (0 , len (filedata), 4 ): dd = [hex (filedata[i+j])[2 :].zfill(2 ) for j in range (4 )] dd = dd[::-1 ] n = "" .join(dd) n = int (n, 16 ) cipher.append(c_uint32(n)) decrypt(cipher, len (cipher), md5_to_arr4) out = [] for i in range (len (cipher)): dd = hex (cipher[i].value)[2 :].zfill(8 ) dd = [int (dd[j*2 :j*2 +2 ], 16 ) for j in range (4 )] dd = dd[::-1 ] out += dd with open ("C:\\Users\\23957\\Desktop\\Syclock\\level2.jar" , "wb" ) as f: for dd in out: f.write(dd.to_bytes(1 , 'little' )) def get_flag (): target = [90 , 80 , 70 , 91 , 93 , 80 , 93 , 71 , 82 , 65 , 90 , 110 ] for i in range (11 , 0 , -1 ): target[i] = target[i-1 ] ^ target[i] for i in range (11 , -1 , -1 ): target[i] = target[(i+1 )%12 ] ^ target[i] for t in target: print (chr (t), end = "" ) get_level2jar() print ("challenge2_flag:" , end = "" ) get_flag() print ("" ) challenge0() challenge1() challenge2()
SycGson 1 2 Find the correct route 找到正确的路由
Go-64。
可以总结出如下3种数据结构:
1 2 3 4 5 6 7 8 9 10 11 12 main_city(0x28): name int 0x00 neighbours []main.neighbour_city 0x08 delta uint8 0x20 main.neighbour_city(): name int 0x00 distance int 0x08 cost main.cost 0x10 main.cost(0x18): transportation int 0x00 time int 0x08 expense int 0x10
程序逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 valid_city_delta = 0 valid_city_delta_1 = 0 valid_city_index = 2 tmp1 = 0 tmp2 = 1 tmp5 = 0 target2 = 0x186A0 target2_add_8 = 0 str1 = "“fedcba9876543210" while True: if flag_len < valid_city_delta_1: break now_flag_char = flag[valid_city_delta_1] valid_city_delta_add_1 = valid_city_delta_1 + 1 rax = tmp5&0xF if rax%2 == 1: rcx = 1 else: rcx = 0 newstr = str1[rcx:0x10-rax]+str1[:rax] rax = newstr.index(now_flag_str) # rax < 4 tmp1 ^= valid_city_index邻居列表的第rax个邻居的time tmp2 = (tmp2*valid_city_index邻居列表的第rax个邻居的expense)&0xFFFFFFFF target2 -= valid_city_index邻居列表的第rax个邻居的transportation target2_add_8 += valid_city_index邻居列表的第rax个邻居的distance valid_city_delta += valid_city_index的delta if valid_city_index的邻居列表的第rax个邻居的name == 0x7C2: target1 = valid_city_delta*tmp1 if valid_city_delta==0x83 and target1==0x1F370 and tmp2==0x0AA00000 and target2==0xC4E0 and target2_add_8==0xD898 and flag_len==0x1F: print("good") else: tmp5 += valid_city_index的邻居数量 valid_city_index = valid_city_index邻居列表的第rax个邻居在main_citys中的索引 valid_city_delta_1 = valid_city_delta_add_1
总结以下程序逻辑:找出城市2到城市0x7c2-1800之间长度为32的路径,且expense、transportation、distance、delta都要满足一定条件。
由于路径遍历复杂度太高,因此进行一些约束,从而可以对路径树进行剪枝。
(1)路径点数为32。
(2)路径无环。
(3)由于transportation单调递减,distance与delta单调递增,因此路径的transportation少于某个值则不再考虑,distance与delta大于某个值则不再考虑。
(4)最重要的点:由于计算出平均每条边的transportation为1600,且图中transportation最小为1600,因此路径每条边应为transportation。
脚本如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 ''' # @Time : 2023/07/18 10:31:52 # @Author: wd-2711 ''' import timeclass citys (): def __init__ (self, data ): self.data = data def get_neighbours_info_by_index (self, index ): info = self.data[index] neighbours = info[1 ] neighbours_ind = [] neighbours_distance = [] neighbours_cost = [] for n in neighbours: neighbours_ind.append(n[0 ]-1800 ) neighbours_distance.append(n[1 ]) neighbours_cost.append({ "transportation" : n[2 ][0 ], "time" : n[2 ][1 ], "expense" : n[2 ][2 ], }) return neighbours_ind, neighbours_distance, neighbours_cost def get_delta_by_index (self, index ): info = self.data[index] delta = info[2 ] return delta def __len__ (self ): return len (self.data) def parse_data (): path = "./gson/gson.json" with open (path, 'r' ) as f: lines = f.read().strip().replace(" " , "," ).replace("{" , "[" ).replace("}" , "]" ) lines = eval (lines) return citys(lines) expense_gate = 0x0AA000000 target2_gate = 0xC4E0 target2_add_8_gate = 0xD898 valid_city_delta_gate = 0x83 st_index = 2 ed_index = 0x7C2 - 1800 arr = "fedcba9876543210" citys_info = parse_data() def find_path (): ret = {} path_seq = [[st_index]] expense_seq = [1 ] target2_seq = [0x186A0 ] target2_add_8_seq = [0 ] valid_city_delta_seq = [0 ] st = time.time() i = 0 while True : i += 1 if i % 10000 == 0 : print ("path_seq:{:<10}|time:{:<10}|max_path_len:{:<10}" .format (len (path_seq), int (time.time()-st), len (path_seq[-1 ]))) head_path = path_seq[0 ] head_expense = expense_seq[0 ] head_target2 = target2_seq[0 ] head_target2_add_8 = target2_add_8_seq[0 ] head_valid_city_delta = valid_city_delta_seq[0 ] if len (head_path) == 32 : break now_index = head_path[-1 ] neighbours_ind, neighbours_distance, neighbours_cost = citys_info.get_neighbours_info_by_index(now_index) delta = citys_info.get_delta_by_index(now_index) neighbours_len = len (neighbours_ind) for j in range (neighbours_len): new_path = head_path + [neighbours_ind[j]] new_expense = (head_expense * neighbours_cost[j]['expense' ]) & 0xFFFFFFFF new_target2 = head_target2 - neighbours_cost[j]['transportation' ] new_target2_add_8 = head_target2_add_8 + neighbours_distance[j] new_valid_city_delta = head_valid_city_delta + delta if neighbours_cost[j]['transportation' ] != 1600 : continue if new_target2 < target2_gate or new_target2_add_8 > target2_add_8_gate or new_valid_city_delta > valid_city_delta_gate: continue if new_path[-1 ] in new_path[:-1 ]: continue if new_path[-1 ] == ed_index and len (new_path) < 32 : continue if len (new_path) > 32 : continue if new_path[-1 ] == ed_index and len (new_path) == 32 and new_target2 == target2_gate and new_target2_add_8 == target2_add_8_gate and new_valid_city_delta == valid_city_delta_gate: if new_expense == expense_gate: ret['path' ] = new_path return ret continue path_seq.append(new_path) expense_seq.append(new_expense) target2_seq.append(new_target2) target2_add_8_seq.append(new_target2_add_8) valid_city_delta_seq.append(new_valid_city_delta) path_seq = path_seq[1 :] expense_seq = expense_seq[1 :] target2_seq = target2_seq[1 :] target2_add_8_seq = target2_add_8_seq[1 :] valid_city_delta_seq = valid_city_delta_seq[1 :] def get_flag (): p = find_path() path = p['path' ] tmp5 = 0 print ("SCTF{" , end = "" ) for i in range (len (path)-1 ): node_index = path[i] next_node_index = path[i+1 ] rax = tmp5 & 0xF new_arr = arr[:0x10 -rax] + arr[:rax] neighbours, _, _ = citys_info.get_neighbours_info_by_index(node_index) tmp = neighbours.index(next_node_index) flag_c = new_arr[tmp] print (flag_c, end = "" ) tmp5 += 4 print ("}" ) if __name__ == "__main__" : get_flag()
做出来才发现,Nu1L和W&M都没做出来,嘿嘿嘿,官方题解也没给答案,我得出的flag=SCTF{dfedfcdefdecdefdccffeddceddecdf}。
SycTee 1 2 3 4 study OP tee 附件:链接:https://pan.baidu.com/s/1rPLyDrhzZJGilYgFQP6qoA?pwd=SCTF 提取码:SCTF Google Drive:https://drive.google.com/file/d/1568TtX2DRrTg7jtIv3IaNd1MhVcEmhDS/view?usp=sharing
0x00 思路 今天看了一天OP-TEE,搭建好了OP-TEE的环境,也能运行hello_world等示例程序。但是还是看不出来,只能运行bl1.bin,其余的bl2.bin/bl31.bin/bl32.bin/bl33.bin无法运行。
发现这是realworld的题目 ,直接打算看wp,复现一下,这样的话以后遇到了也可以解决(主要是浪费了3天时间了)。
0x01 My middle WP 找到了某链接 ,可能是出题人学习optee的笔记。rootfs.cpio.gz是题目的文件系统,首先解压:
1 2 gzip -d root.cpio.gz sudo cpio -id -D ./rootfs < rootfs.cpio
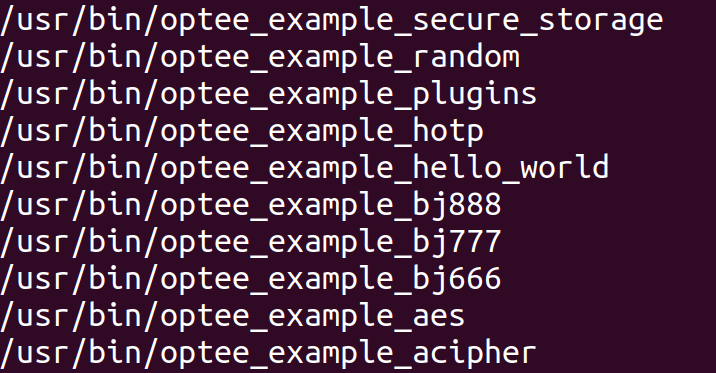
在其中,发现optee的相关示例文件:
重点关注optee_example_bj666-888,因为这是普通示例文件没有的。经过实验,bj888带参数输入会输出wrong,猜测可能flag检验文件。
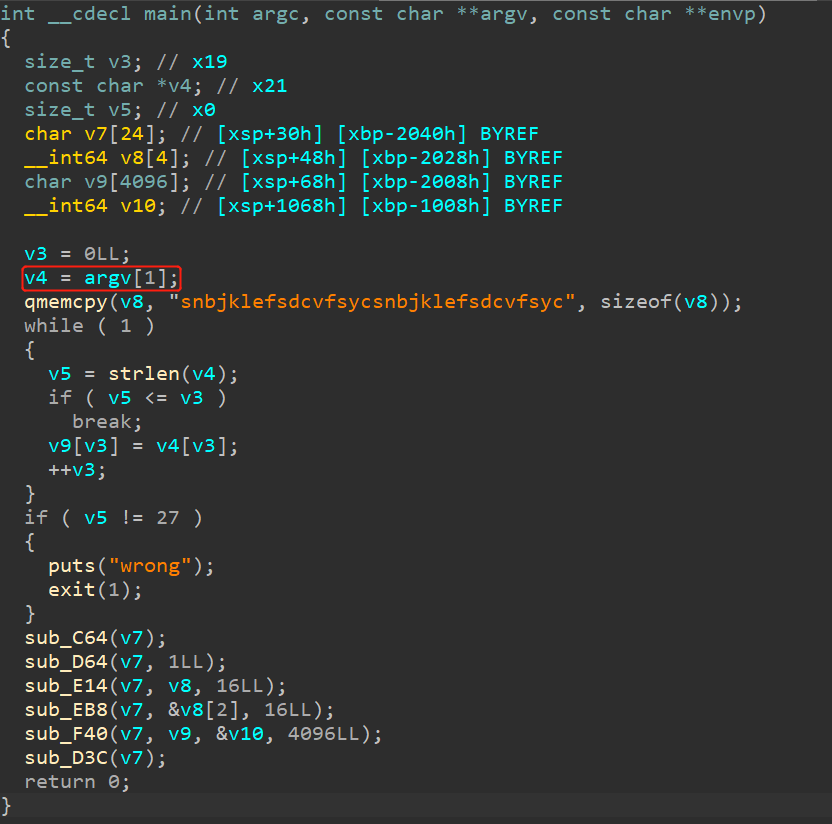
分析bj888文件:
在此需要补充,由于optee是一个可信执行环境,因此,有TEE(可信环境)与REE(不可信环境)两种环境,并且在程序加载时,TEE将根据UUID从内存中取出UUID.ta文件,将其作为TEE系统的镜像文件。从上图可以看出,输入长度为27。
UUID如上图红框所示,我们可以根据它找到此程序对应的UUID.ta文件。在本题中,UUID.ta文件存放在/lib/optee_armtz中,对应的具体文件为:/lib/optee_armtz/045ccc45-ee83-43ec-b69f-121819c1ba6b.ta。
之后,由于045ccc45-ee83-43ec-b69f-121819c1ba6b.ta是加密的,因此,我就不知道该如何做了。
0x02 W&M’s wp 无论是官方的wp,还是Nu1L的wp,他们都没说一件事:xxx.ta文件并不是加密的,绝大部分情况下,将xxx.ta文件的头部字节删掉,即变成以.ELF字节开头,这样就可以直接使用IDA进行分析。因此,045ccc45-ee83-43ec-b69f-121819c1ba6b.ta不是加密的。
补充:.ta文件的开头,也就是.ta_head:0000000000000000,一般是uuid。跟进start进入类似于下图的函数结构后,optee的.ta有一个固定的模式(看了两个文件都是这样的模式),记住下图红框中的函数一般是主函数即可。
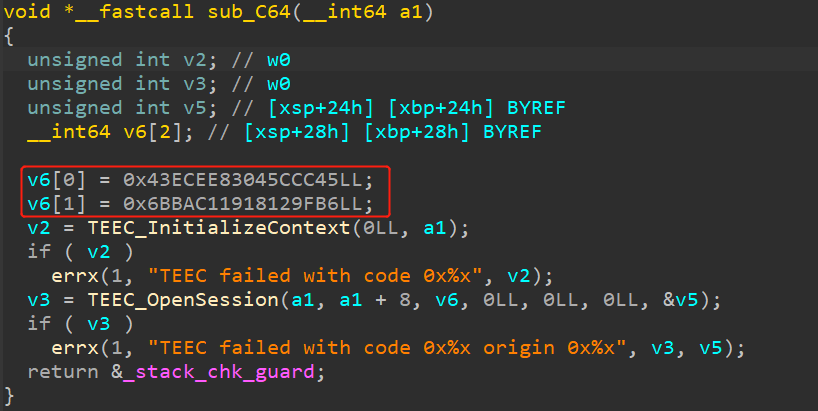
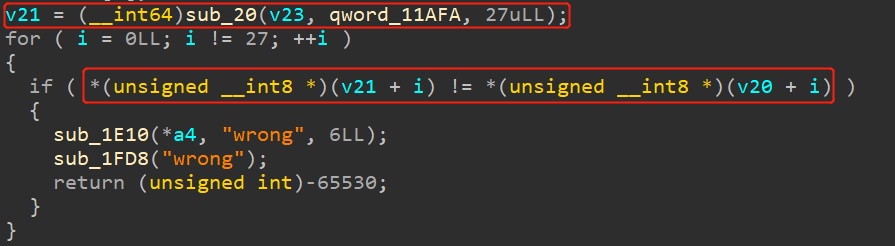
跟进sub_1DC函数后,发现:
其中sub_20可以当作是copy函数,因此有:
1 v21 = [0x25, 3, 0xA, 0x6C, 0xF8, 0xB1, 0xCE, 0x7F, 0xC9, 0x42, 0xC, 0xD, 0x68, 0xB3, 0x1C, 4, 0x64, 0xFA, 0xE5, 0xA4, 0x22, 0xD4, 0x2C, 0xFF, 0x4E, 0x36, 0x2A, 0]
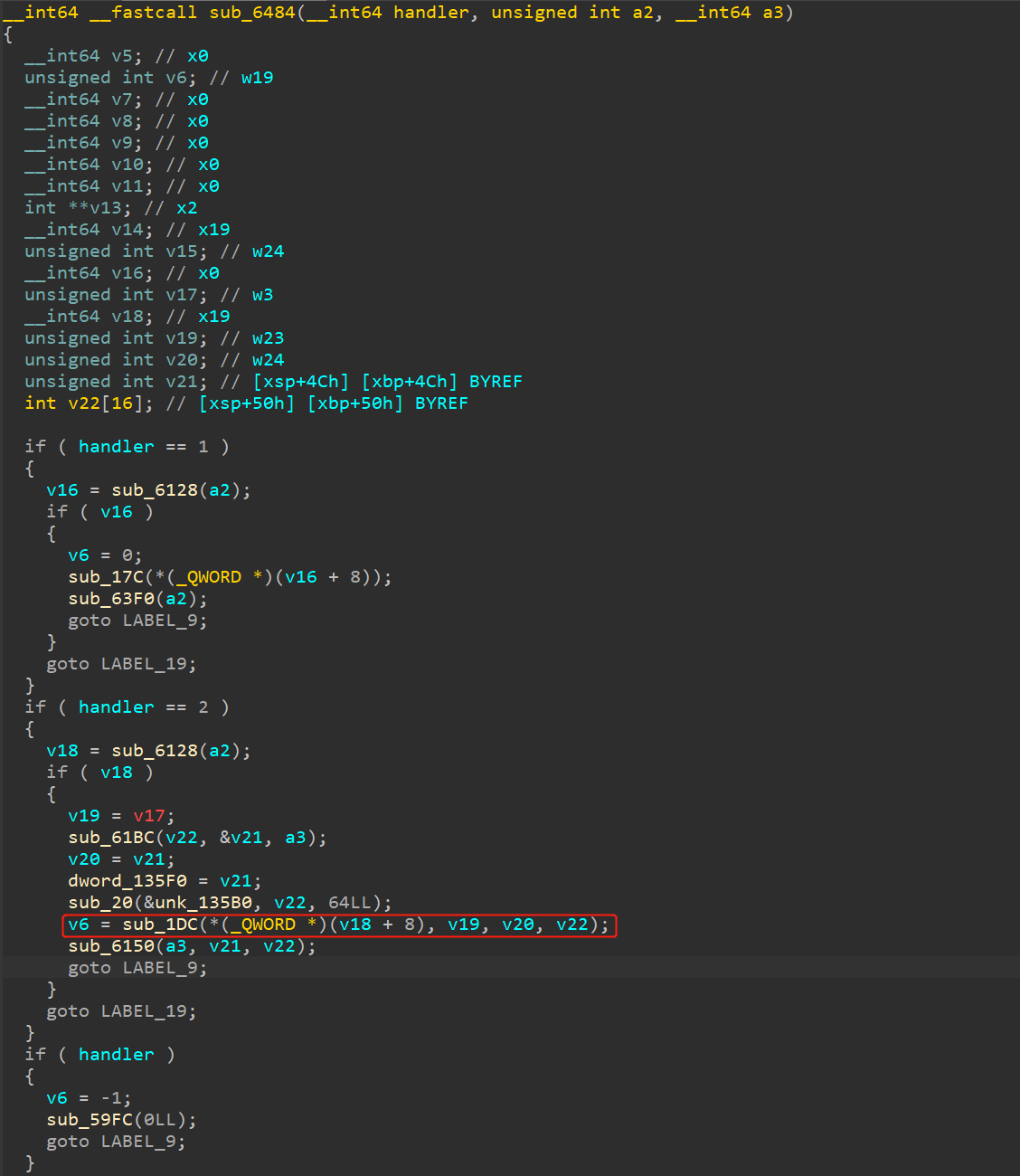
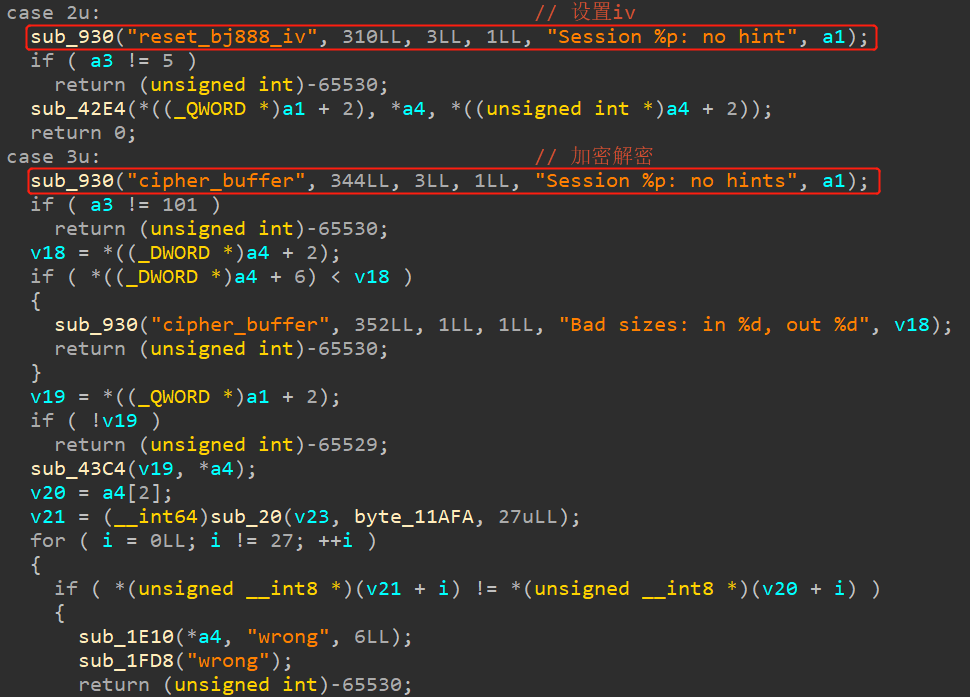
下面跟进v20,在此,说明一下.ta文件的某些函数:
如上图所示,sub_930函数结构出现过多次,此函数的功能是:收取来自CA(不可信环境)中的参数。
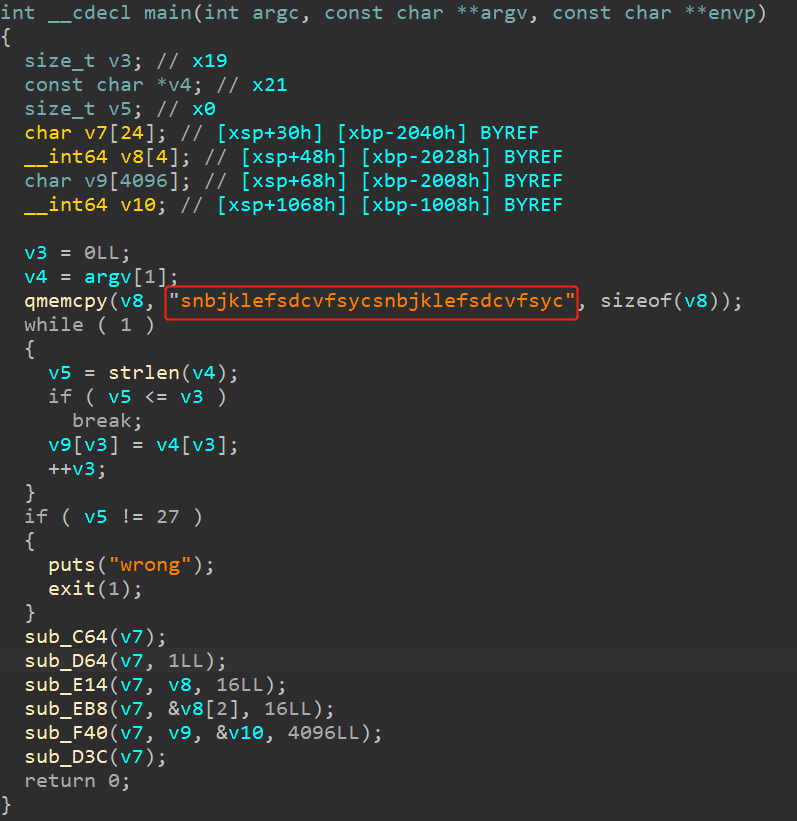
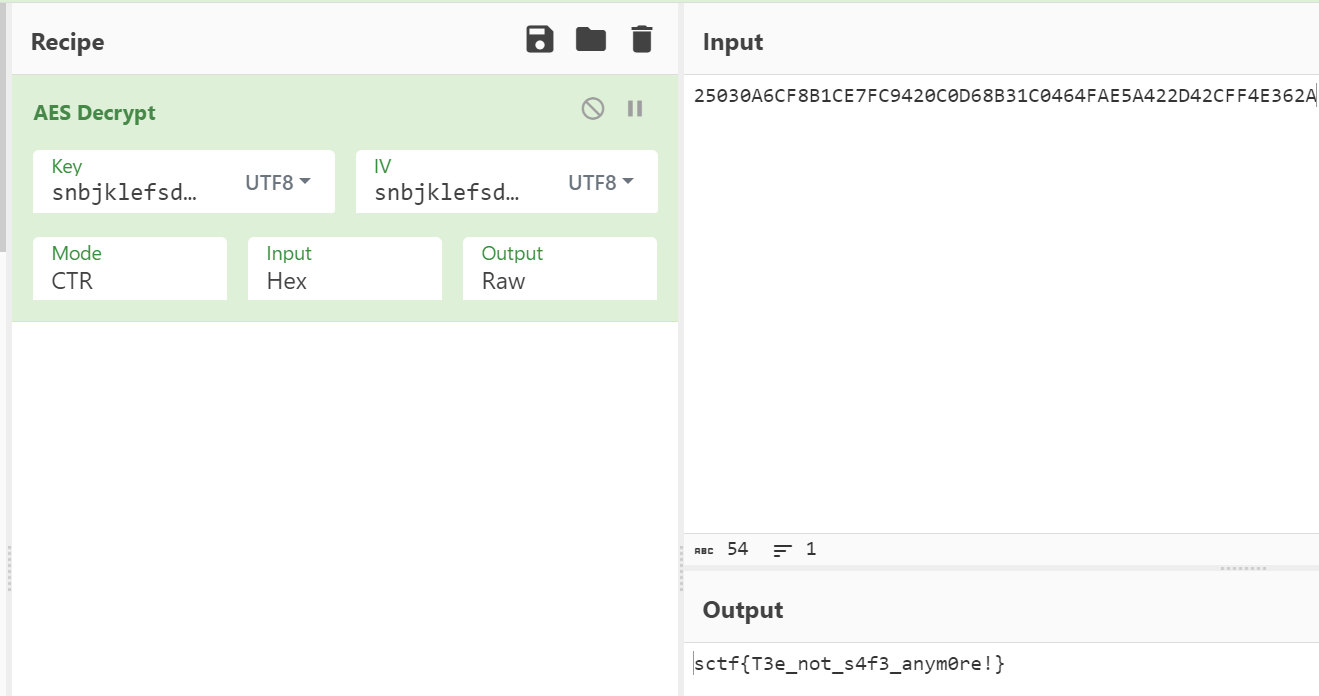
因此,key、iv、密文都是用户输入的。并且,可以发现字符串:Example of TA using an AES sequence,猜测是AES解密。在128位AES的情况下,key与iv都是16字节。再次看bj888,发现:
猜测key=snbjklefsdcvfsyc,iv=snbjklefsdcvfsyc。通过在线网站CyberChief可以获得flag: