advance-network-review
高级计算机网络复习笔记
0x00 FatTree
重点概览
(1)拓扑结构和编址方案
(2)路由算法,任意两个主机之间的路径和路由表项
详细内容
拓扑结构和编址方案
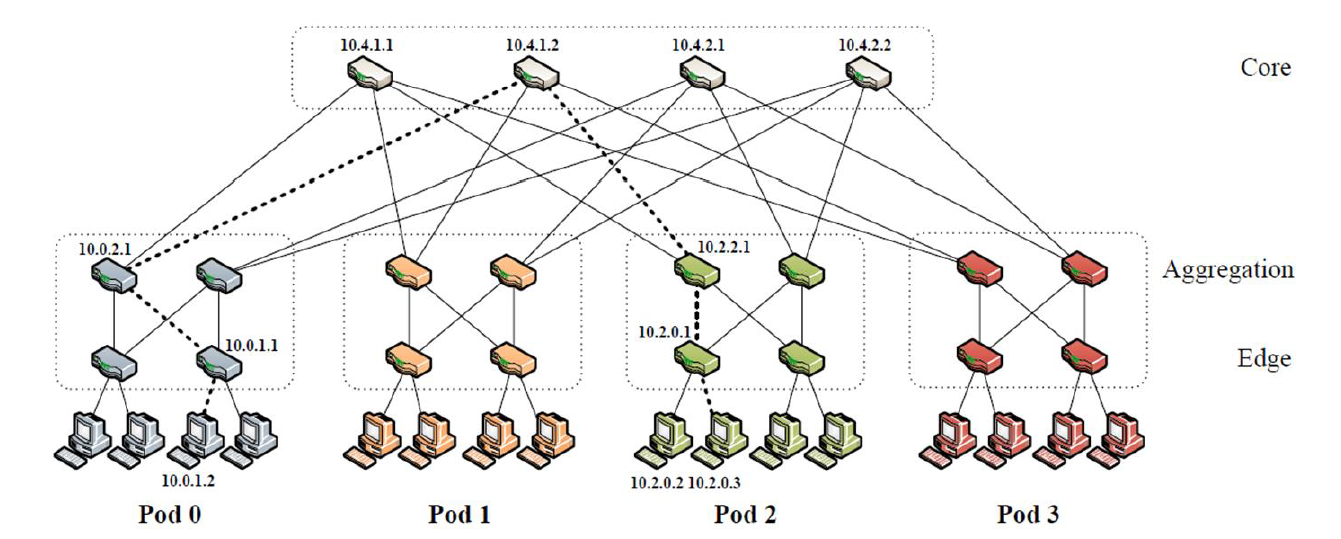
Aggregation和Edge 层:
(1)k pods,每一个 pod 包含 2 层,每一层有 k/2 个 switches
(2)最底层的 pod switch 每一个连接 k/2 个 hosts
(3)剩下的 k/2 个接口连接 aggregation 层的 pod 交换机
Core层:
(1)$(k/2)^2$ k port core switches。k 个接口连接 k 个 pod。
(2)任意 core switch 的第 i 个接口连接 pod i
(3)任意 2 个 host 直接有 $(k/2)^2$ 个 最短路径,只有一条会被选择 (与核心交换机的数量相对应)
特点:
(1)k-port 交换机 支持 $(k^3)/4$ 的 hosts
(2)一个pod 支持的 host 数量 : $(k/2)^2$
(3)all pods(k 个 pod ):$ (k/2)^2*k=(k^3)/4$
编址方案:
块中所有的IP 地址均取自私有地址空间 10.0.0.0/8 中
(1)pod 中的交换机编码格式10.pod.switch.1
4 个路由的时候的编号左下 0、右下 1、左上 2、右上 3,从左到右,从下到上。
pod 的取值范围为
[0,k-1]switch 的范围
[0,k-1]
(2)核心交换机编码格式10.k.j.i
k 表示 port 数,是常量,不变。
j and i denote that switch’s coordinates in the $(k/2)^2$ core switch grid (each in [1, (k/2)], starting from top left);到时候看图就好。
(3)host 编码格式 10.pod.switch.id
- 前 3 个字段和 host 连接的交换机一样,由于 id=1 ,被交换机占用了,因此 id 从 2 开始取,一个 switch 一共 $k/2$ 个 host
路由算法
两级路由表
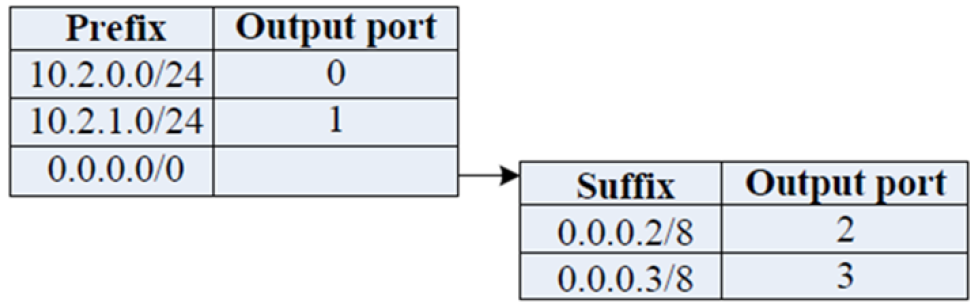
路由表解释:
- 展示的是Pod2 左上角的交换机( 10.2.2.1 )的两级路由表,显然这种表格设计是用来划分目标 IP 属于 Pod 内部还是外部的。
- 前缀表:Pod 内部 IP ,直接转发给 Prefix 第 3 个字节对应的 switch ,转发的端口号和该端口连接的 switch id 保持一致;
- 后缀表:其他Pod 的 IP ,按照 IP 的第 4 个字节,均匀地分散到对应的上层的交换机上(对于接入层Edge的上层就是汇聚层Aggregation,对于汇聚层Aggregation的上层就是核心层core,但它们其实原理都是一样的,都是均匀地转发给其上层的 k/2 个交换机)。
- 结论:对于Pod 内每个交换机,其前 $k/2$ 的端口负责向下转发,后 $k/2$ 个端口负责向上转发。同时,每个pod 交换机的路由表的前缀表和后缀表大小,都不超过其转发的端口的数量,即$k/2$。
路由算法
Pod交换机
(1)如果某主机将数据包发送到同一 pod 中但位于不同子网中的另一台主机,则该 pod 中的所有上层交换机都将具有指向目标子网交换机的终止前缀。
(2)对于所有从 Pod 中传出的流量,Pod 交换机有一个默认的 /0 前缀和一个匹配主机 ID 的辅助表。 使用主机 ID 作为确定性熵的来源; 它们将使流量在到核心交换机的出站链路之间均匀地向上传播。
Aggregation交换机
(1)一旦一个数据包到达它的目的pod ,接收的上层 pod 交换机也将包括一个(10.pod.switch.0/24,port)来将该数据包指向它的目的子网交换机,在那里它最终被转发到它的目标主机。
Core交换机
(1)一旦数据包到达core交换机,就只有一个链接到其目标pod ,并且该交换机将包含该数据包的pod 的条目(10.pod.0.0/16,port)。
例子
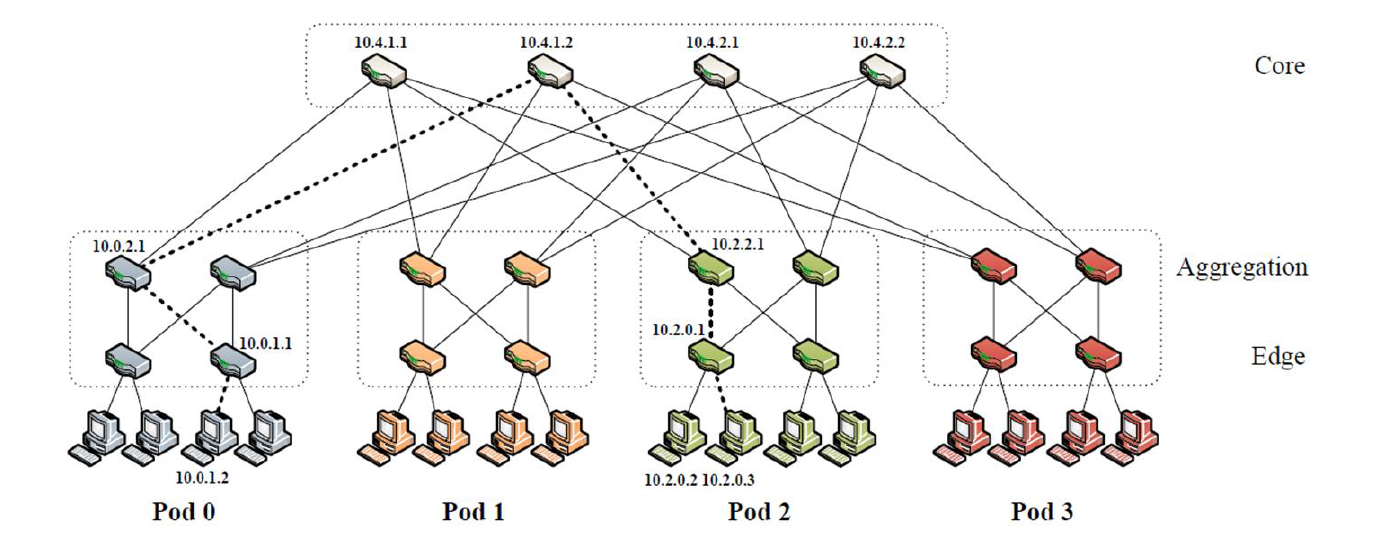
源地址:10.0.1.2,目的地址:10.2.0.3
(1)在网关交换机(10.0.1.1)匹配前缀表中的 /0,再匹配后缀表中的0.0.0.3/8,然后转发到端口2,路由到pod交换机(10.0.2.1)。
(2)在网关交换机(10.0.2.1)匹配前缀表中的/0,再匹配后缀表0.0.0.3/8,转发到端口3,路由到核心交换机10.4.1.2。
(3)在10.4.1.2,匹配前缀表中的10.2.0.0/16,指向端口 2 上的 pod 2 中的交换机10.2.2.1。
(4)在10.2.2.1,匹配前缀表中的10.2.0.0/24,它指向负责该子网的交换机,端口 0 上的10.2.0.1。
(5)最后一步当包到达10.2.0.1的时候,标准的交换技术会将其分发到相应的 host
相关的两个算法如下:
(1)算法1:生成aggregation交换机路由表

对于任一处于pod x,在 pod 内编号为 z 的aggregation交换机 (10.x.z.1) 而言, addPrefix(10.x.z.1,10.x.i.0/24, i) 含义是:对于aggregation交换机10.x.z.1来说,目的 IP 的前缀为10.x.i.0/24,表示其为 pod 内第 i 个子网的主机,转发端口是 i ,下一跳是交换机 10.x.i.1。
对于下层交换机,z 在 [0,(k/2)-1] 中,并省略行3、5。
(2)算法2:生成core交换机路由表

0x01 Portland
重点概览
(1)理解PMAC地址,为什么需要?怎么设计的?有什么好处?
(2)LDP协议
详细内容
PMAC:伪MAC地址。
为什么需要PMAC地址?
(1)任何 VM (虚拟机)都可以迁移到任何物理机器。不应该改变他们的 IP 地址,因为这样做会破坏现有的 TCP 连接和应用程序级状态。
(2)在部署之前,管理员不需要配置任何交换机。需要配置DHCP/子网。
(3)任何终端主机都应该能够沿着任何可用的物理通信路径与数据中心中的任何其他终端主机有效地通信。
(4)不应该有转发循环(forwarding loops)。
(5)故障在网络中是常见的,所以故障检测应该是快速和有效的。
现有协议的不足:
(1)(2)可以满足单个第二层网络结构 ,但第二层网络结构不能扩容,需要支持广播。第三层网络结构不支持虚拟机迁移。
(3)第二层需要大量的 MAC 转发表项(不可行的)。
(4)(5)第二层和第三层协议( 例如IS IS 、 OSPF) 是基于广播的,效率不够高。
补充:fabric
Layer 2 fabric(第二层网络结构)是一种网络架构,用于在数据中心或企业中提供高性能、低延迟、可伸缩性和可靠性的数据中心互连。它通常使用以太网技术,并提供交换、路由和负载均衡等功能。在这种架构中,交换机被配置为一个分布式的、高度可用的交换机集群。这些交换机之间通过高速链路相互连接,以提供高性能和可靠性。同时,它们通过各种协议实现负载均衡和快速故障转移,从而提高网络的可靠性和可用性。与传统的三层网络架构相比,第二层网络结构具有更低的延迟和更高的吞吐量。它还可以更好地支持虚拟化和容器化应用程序,从而提高数据中心的灵活性和效率。
Layer 3 fabric(第三层网络结构)是一种网络架构,用于在数据中心或企业中提供高性能、低延迟、可伸缩性和可靠性的数据中心互连。它通常使用IP协议,并提供路由、交换和负载均衡等功能。
总结一下不足的点:
(1)当前的网络协议带来了巨大的管理开销。例如,终端主机的 IP 地址可能由其直接相连的物理交换机确定,并与复制的 DHCP 服务器进行适当的同步。 VLANs 可以跨交换机边界提供一些命名灵活性,但引入自己的配置和资源分配开销。理想情况下,数据中心网络架构师和管理员应该对交换机进行即插即用部署。
(2)任何终端主机都应该能够沿着任何可用的物理通信路径与数据中心中的任何其他终端主机有效地通信。
(3)为了满足以上的第 2 点需求,第二层的网络协议要求 MAC 转发表可能有数十万甚至数百万的条目,在今天的交换机硬件上是不切实际的。
设计的好处:在最小的物理占用空间上打包虚拟机;改变通信模式;节约资源。
协议如何设计?
(1)有效转发、路由以及虚拟机迁移的基础是分层伪MAC (PMAC) 地址。
(2)Portland为每台终端主机分配一个唯一的 PMAC 地址。
(3)PMAC对终端主机在拓扑中的位置进行编码。例如,同一pod中的所有端点将在其分配的PMAC 中具有相同的前缀。终端主机保持不变,认为它们保持着自己的实际 MAC (AMAC) 地址。
(4)执行ARP 请求的主机会收到目的主机的 PMAC 。
(5)所有的报文转发都根据PMAC 地址进行,使很小的转发表功能得以实现。
(6)出口交换机执行PMAC 到 AMAC 头重写,以保持目标主机上未修改的 MAC 地址的假象。
PMAC地址如何设计?
PortLand edge交换机在每个 pod 中学习:唯一的 pod 编号、唯一的位置编号。
48bit PMAC 格式: pod:position:port:vmid
- pod(16bit):edge交换机的pod 编号。
- position(8bit):edge交换机的位置编号。
- port(8bit):主机连接的端口号的交换机本地视图。
- vmid(16bit):在同一台物理机上多路复用多个虚拟机。当没用任何流量使用vmid时,portland重用它们。
在每个pod 中,每个edge交换机学习到一个唯一的 pod 号和一个唯一的 position(是学习获得的,而不是配置获得的),并采用位置发现协议 (Location Discovery Protocol )来分配这些值。为所有直联的主机和edge交换机分配一个 48 位的 PMAC 地址。如下所示:
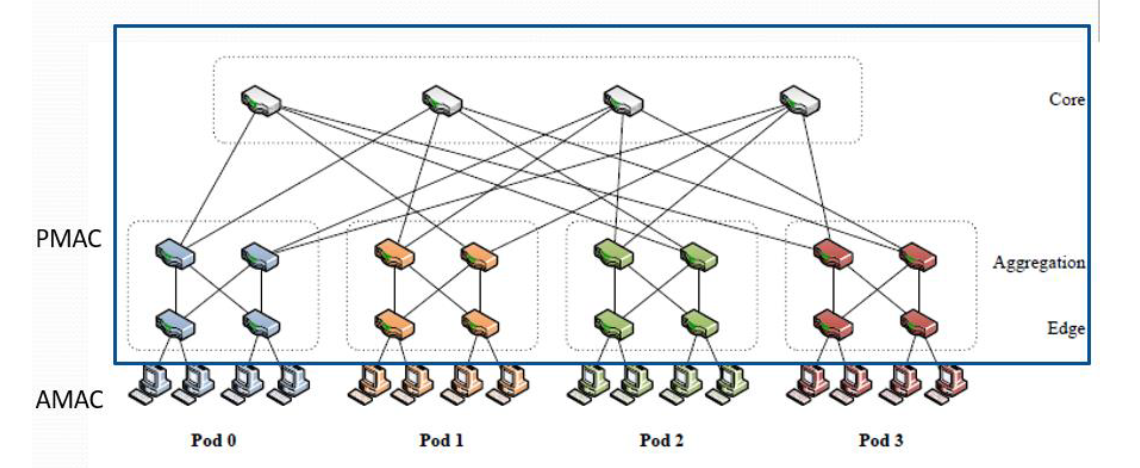
AMAC到PMAC的映射过程(用openflow实现)
(1)当入站交换机看到一个源 MAC 地址,这个源 MAC 地址是之前没有观察到的,这个数据包就会被向量化到交换机软件。
(2)(a)软件在本地 PMAC 表中创建一个条目,将主机的 AMAC 和 IP 地址映射到它的 PMAC 。edge交换机决定PMAC地址。
(2)(b)交换机将此映射信息传达给 fabric 管理器。
(3)fabric 管理器使用此状态响应 ARP 请求。交换机还创建适当的流表条目,为任何指向主机的流量重写 PMAC 目的地址。
如下图所示:
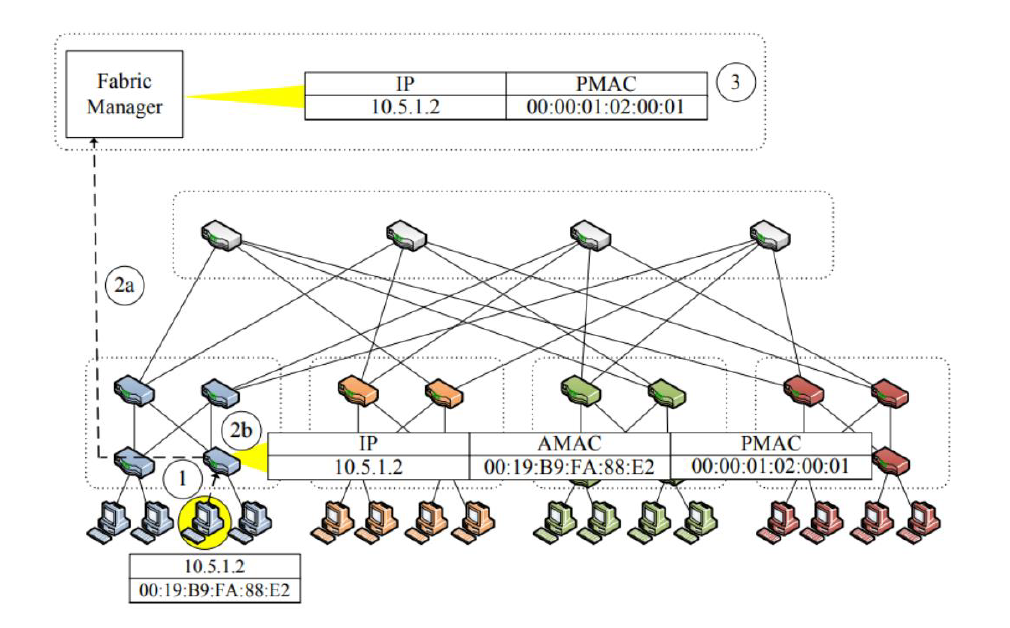
代理ARP协议(根据ip获得物理地址)
(1)源主机发送 IP 到 PMAC 的请求。
(2)接入交换机将这一请求转向 Fabric 管理器,Fabric 管理器查 IP-PMAC 映射表,如果查到转向(3),如果没有就进行广播。
(3)Fabric 管理器将 PMAC 返回给此接入交换机。
(4)接入交换机响应 ARP 请求,将 PMAC 地址交给源主机。
(5)下图显示了源主机与目的主机进行通信, 1 号核心交换机进行转发数据包的过程。
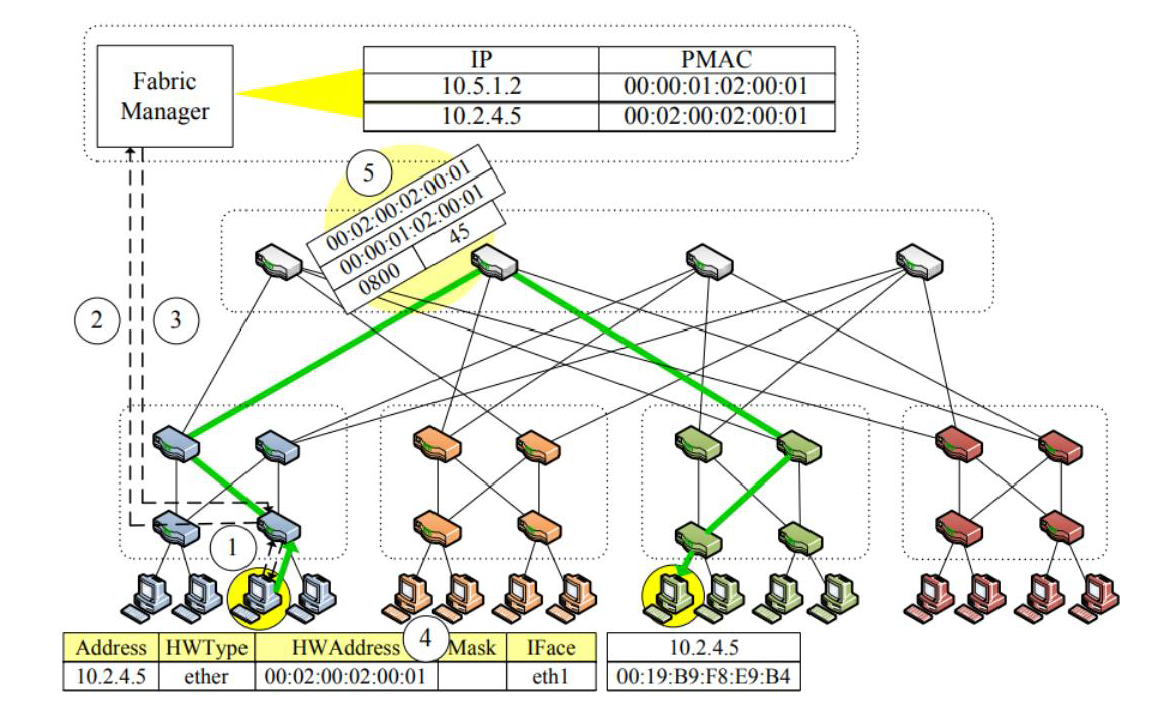
LDP(位置发现)协议
PortLand 交换机定期向其所有端口发送一个位置发现消息(LDM),以设置它们的位置、在稳定状态下监视是否存活等。
(1)地址发现协议是用来自动获得 PMAC 的前提。
(2)交换机及 Fabric 管理器间交换的是 LDM(位置发现消息)。
(3)只在相邻的交换机间进行交换。
(4)LDMs 包含以下表项:

交换机启动时,除了switch_id 与端口号,其他值均未知。我们假设所有交换机端口都处于以下三种状态之一:断开连接、连接到终端主机、连接到另一个交换机。LDP核心思想是:edge交换机只接收aggregation交换机的 LDM(终端主机不产生 LDM)。
(5)Tree Level的获取:
- edge交换机通过确定它们的部分端口是主机连接,来知晓它们的级别。
- aggregation交换机一旦知道它们的一些端口连接到edge交换机,就会知道它们的级别。
- core交换机确认所有端口都连接到aggregation交换机,就会知道它们的级别。
(6)pos值的获取:
交换机在[0,k/2-1](k 是端口数)中随机取一个值,并向所有aggregation交换机(其上行端口) 进行发送,当有一半 (>=k/4+1) 的aggregation交换机承认这个值,那么可获得该值,否则在可选的值除去该值,重新尝试。
(7)pod值的获取:
只由pos=0的交换机去请求,向 Fabric 管理器请求以获得一个唯一的 pod 号,除core交换外,其直联的交换机的 pod 号相同。
每个交换机响应LDM所执行的处理

上述算法给出了每个交换机响应 LDM 所执行的处理。第 2-4 行与pos分配有关,将在下面进行描述。在第 6 行,交换机更新它从交换机邻居那里听到的集合。在第 7-8 行中,如果一个交换机没有与超过 k/2 个相邻交换机连接足够长的时间,它就可以断定它是一个edge交换机。这个结论的前提是edge交换机至少有一半的端口连接到终端主机。一旦交换机得出这个结论,在它接收到的任何后续 LDM 上,它就推断相应的传入端口是向上的。虽然为了简单起见没有显示,但是交换机可以通过在所有端口上发送 ping 来进一步确认它的位置概念。主机将响应此类ping ,但不会传输 LDM 。其他 PortLand 交换机既响应 ping 信号,又传输 LDM 。第12-13 行处理这样的情况:core/aggregation交换机在向下的端口上将 LDM 传输到aggregation/edge交换机,且这些交换机还没有设置其某些端口的方向。
确定core交换机的级别有点复杂,在 14-20 行进行处理。一个交换机还没有建立它的级别,首先验证它的所有活动端口都连接到其他 PortLand 交换机(第 14 行)。然后,它在第 15-18 行验证所有邻居都是尚未设置其链路方向的aggregation交换机,连接到edge交换机的aggregation交换机端口已经被确定为向下 。如果这些条件保持不变,交换机可以断定它是一个core交换机,并将其所有端口设置为向下(第 20 行)。
每个edge交换机在适当的范围内为同一pod 中的所有aggregation交换机提出一个随机选择的数字。如果建议被这些交换机中的大多数验证为未使用,则建议将被最终确定,该值将从边缘交换机包含在未来的 LDM 中。如下所示:

在第 24 行和第 29 行中,当多个建议同时出现在同一个位置号时,aggregation交换机将保持一个建议的位置号一段时间,然后计时结束。 LDP 利用 fabric 管理器为同一pod 中的所有交换机分配唯一的 pod 号。在算法 2(上图)的第 8-9 行中,位置为 0 的edge交换机向 fabric 管理器请求 pod 号。在算法 1 (上上图)的第 21-22 行中,这个 pod 编号扩展到 pod 的其他部分。
0x02 VL2
重点概览
(1)拓扑结构
(2)编址方案,什么是LA?什么是AA?
(3)转发机制:几层包头?字段?路由/任播
详细内容
常规数据中心网络架构:
(1)ToR 连接到两个汇聚交换机以实现冗余。
(2)每对接入路由器下的所有交换机形成一个第 2 层域。
(3)服务器被划分为虚拟局域网 (VLAN)。如下图所示:
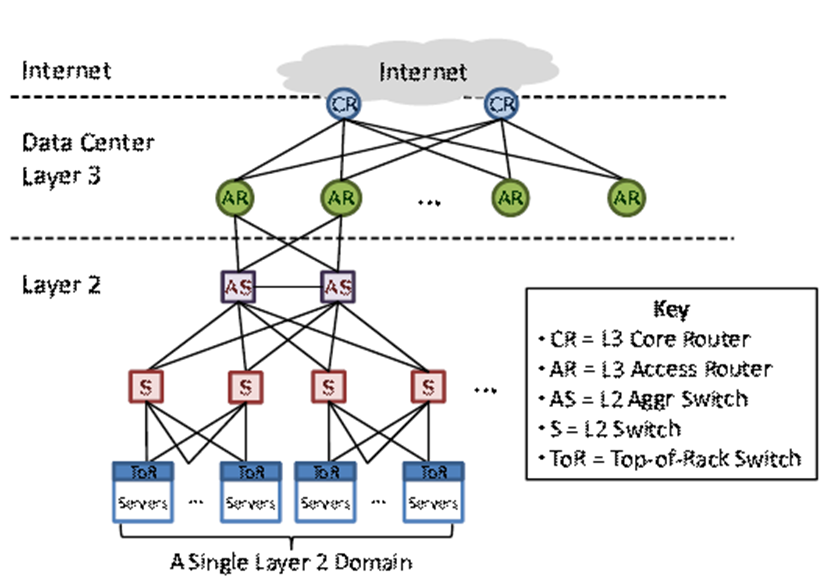
VL2拓扑结构
设计原则:
(1)随机化以应对波动性(易变性)。流量随机分布,分布比例均匀
(2)基于成熟的网络技术。链路状态路由 (OSPF)、等价多路径 (ECMP) 转发、IP 任播和 IP 多播
(3)将名称(name)与定位器(locator)分开。将服务器的特定于应用程序的地址 (AA) 与其特定于位置的地址 (LA) 分开。
(4)拥抱终端系统。在主机上使用 VL2 代理实现,而不是在交换机上。
拓扑结构:
中间交换机和聚合交换机之间的完整二分图:
(1)$D_A/2$个中间交换机,每一个都有$D_I$个端口。
(2)$D_I$个聚合交换机,每一个都有$D_A$个端口($D_A/2$个向上端口,$D_A/2$个向下端口)
(3)$(D_AD_I)/4$个ToR,每个连接到 2 个汇聚交换机。
(4)总共有$20(D_AD_I)/4$个服务器。如下所示:
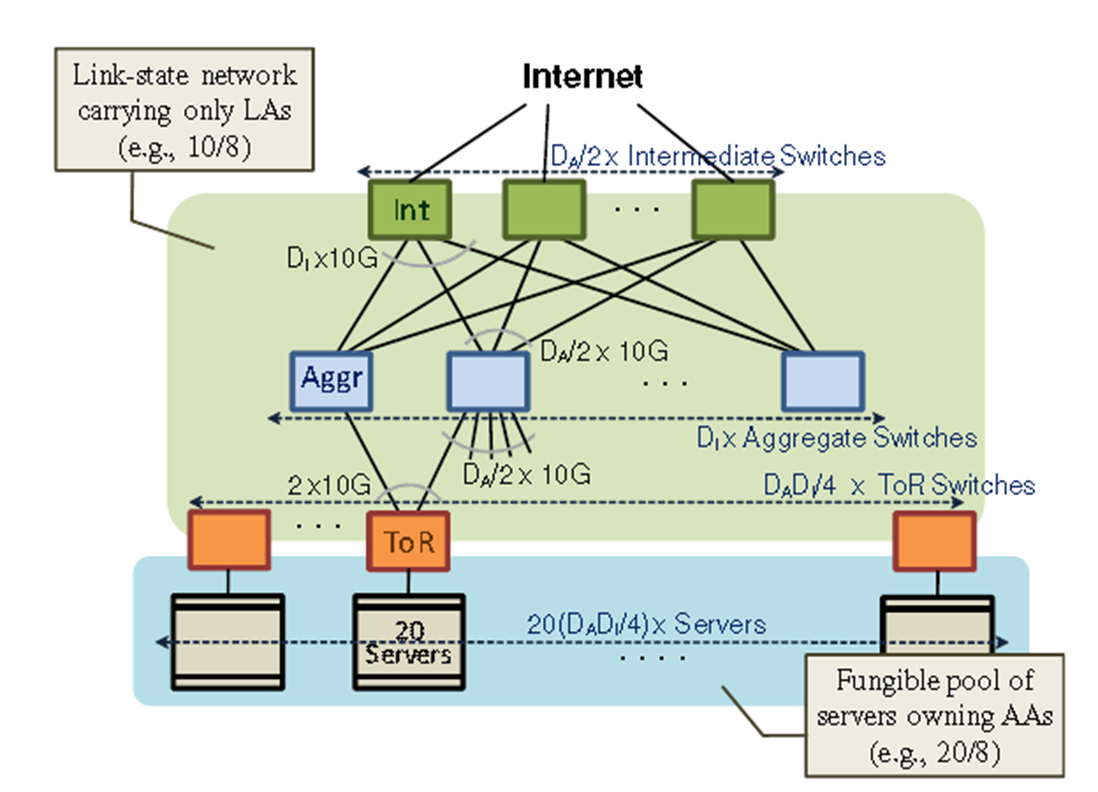
VL2编址方案:LA与AA
(1)位置特定地址 (LA),分配给中间和汇聚交换机,以及ToR 交换机的向上接口。交换机运行链路状态路由协议(例如 OSPF),仅传播这些 LA。
(2)应用程序服务器使用的应用程序特定地址 (AA)。
(3)VL2 目录系统存储 AA 和 LA 之间的映射。将 ToR 的 AA 映射到它的 LA。
如下图所示:
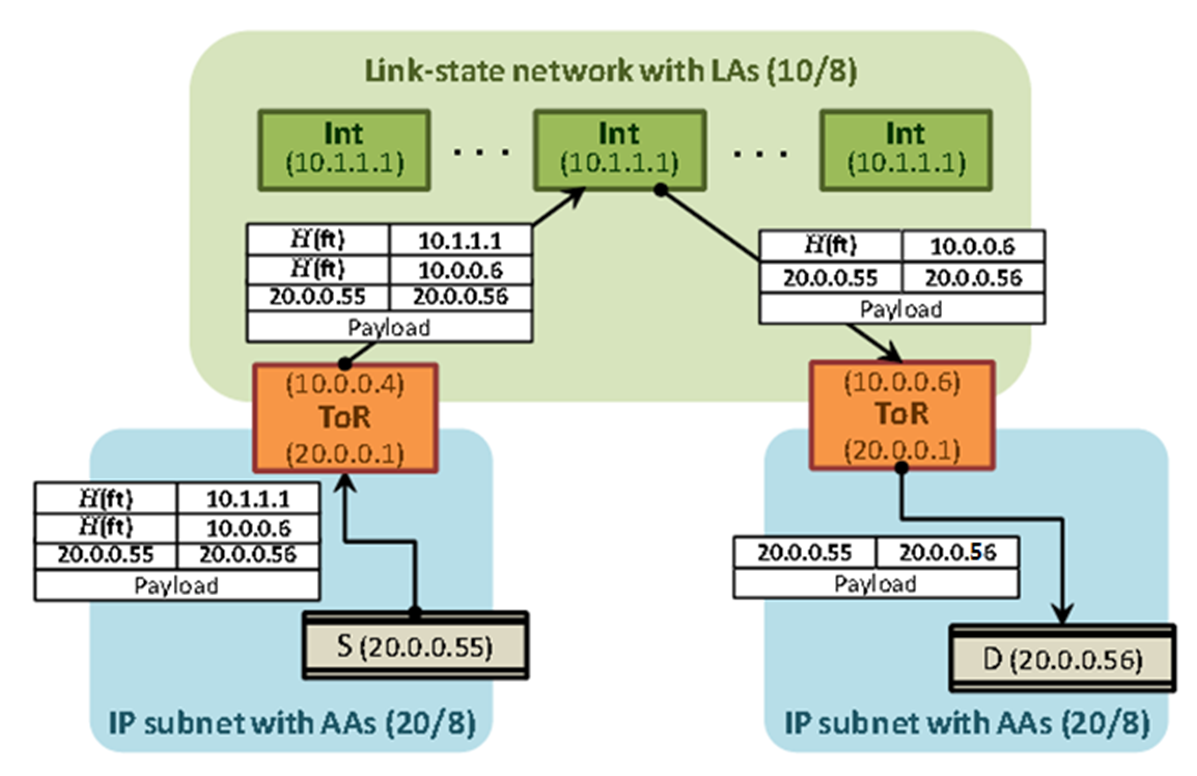
数据包传播:每台主机上的 VL2 代理使用目标 ToR 的 LA 地址封装数据包。例如上图中的10.0.0.6。目的 ToR 解封装数据包并将其传送到目标 AA。
地址解析:每个服务中的服务器都认为它们在同一个 IP 子网中。在发送给 AA 之前查询 AA 的 MAC。主机上的 VL2 代理拦截广播 ARP 请求并将其转换为对 VL2 目录系统的单播查询。目录系统用 ToR 的 LA 回答查询。如上图所示,查询为20.0.0.56的MAC 地址,返回10.0.0.6。VL2 代理缓存映射。
访问控制:如果目录服务拒绝向服务器提供 LA,则服务器无法将数据包发送到 AA。示例:只有属于同一服务的服务器才能相互通信。
Traffic Spreading(流量均衡分布):VL2 代理使用封装通过随机选择的中间交换机发送流量来实现 VLB。数据包首先传送到其中一个中间交换机,由交换机解封装,传送到 ToR 的 LA,再次解封装,最后发送到目的地。为所有中间交换机分配相同的 LA 地址,例如Anycast(任播)地址,因此,VL2 代理不需要记住许多中间交换机的 LA。
ToR 和聚合交换机上的 ECMP:16 至 256 路 ECMP。当交换机或链路故障时,OSFP+ECMP通过移除路径作出反应,代理不需要处理故障。(ECMP(Equal-Cost Multi-Path)协议是一种用于实现负载均衡的协议,可以将网络流量均匀地分配到多个路径上,从而提高网络性能和可靠性。)
ECMP 将封装有任播地址的数据包传送到任何一个活动的中间交换机,源主机上的 VL2 代理计算五元组值的哈希值并将该值写入源 IP 地址字段。
(1)ECMP 使用源 IP(也就是H(ft))在等成本的中间交换机之间做出转发决策。ft: <src IP, dst IP, src MAC, dst MAC, proto>
(2)相同五元组的报文在同一路径上转发。
(3)产生统一的基于流的流量传播(VLB)。
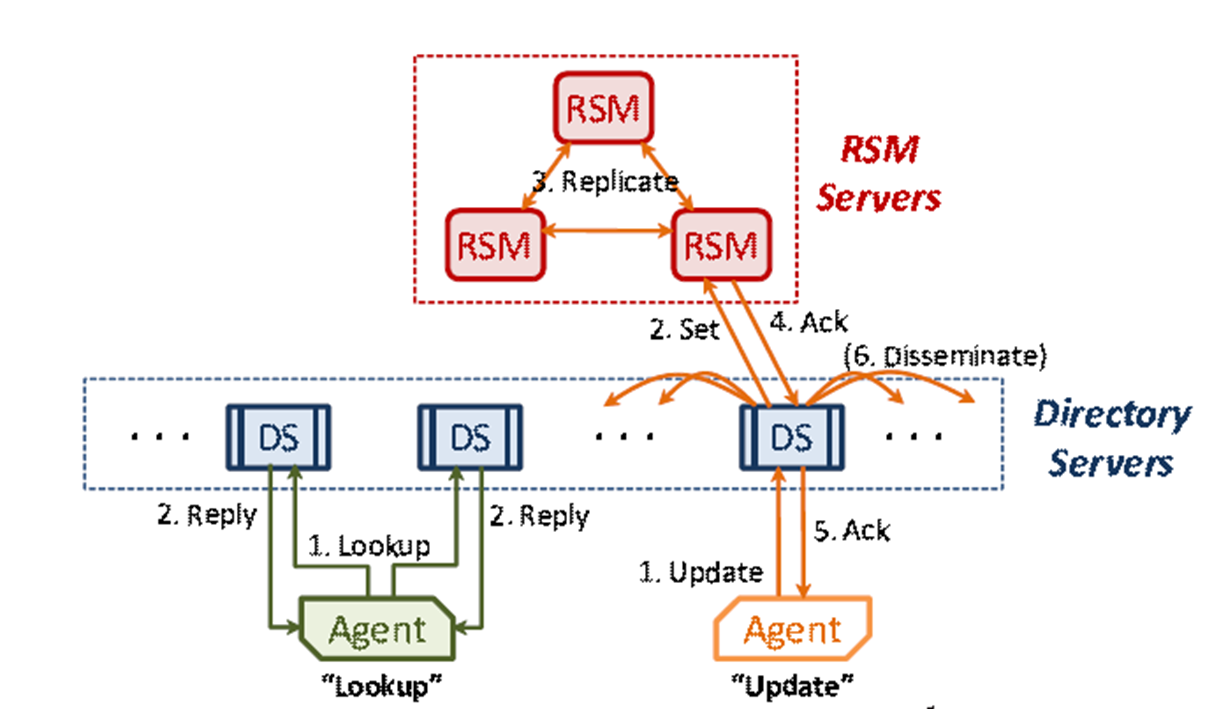
(4)两层目录系统体系结构。少量(5-10 个服务器)写入优化的异步复制状态机 (RSM) 服务器提供高度一致、可靠的 AA 到 LA 映射存储。少量读取优化的复制目录服务器缓存 AA 到 LA 映射并处理来自 VL2 代理的查询。
0x03 Helios
重点概览
(1)拓扑结构
(2)Circuit switching和packet switching特点、优劣
详细内容
模块化数据中心。希望能够根据动态变化的通信模式,在需要的时间和地点分配可用带宽池,而不是为最坏情况下的通信要求做准备。Helios,一种混合电/光数据中心交换机架构,能够有效结合这两种技术的优势。识别从一个pod到另一个pod的稳定通信需求,用电路切换进行切换。其余的突发通信由分组交换处理。
Layer-0 交换机:直接对光束进行操作,无需解码任何数据包。转发不是基于地址,而是基于交换机端口
拓扑结构
(1)分组交换机和电路交换机形成一个核心交换机层来互连pod。
(2)每个 pod 的一半上行链路连接到分组交换机。
(3)每个 pod 交换机的另一半上行链路在连接到单个光电路交换机之前通过无源光多路复用器。w:超链路的大小,受 WDM 技术限制。(WDM(Wavelength Division Multiplexing)是一种传输技术,用于在光纤通信系统中实现多路复用。)
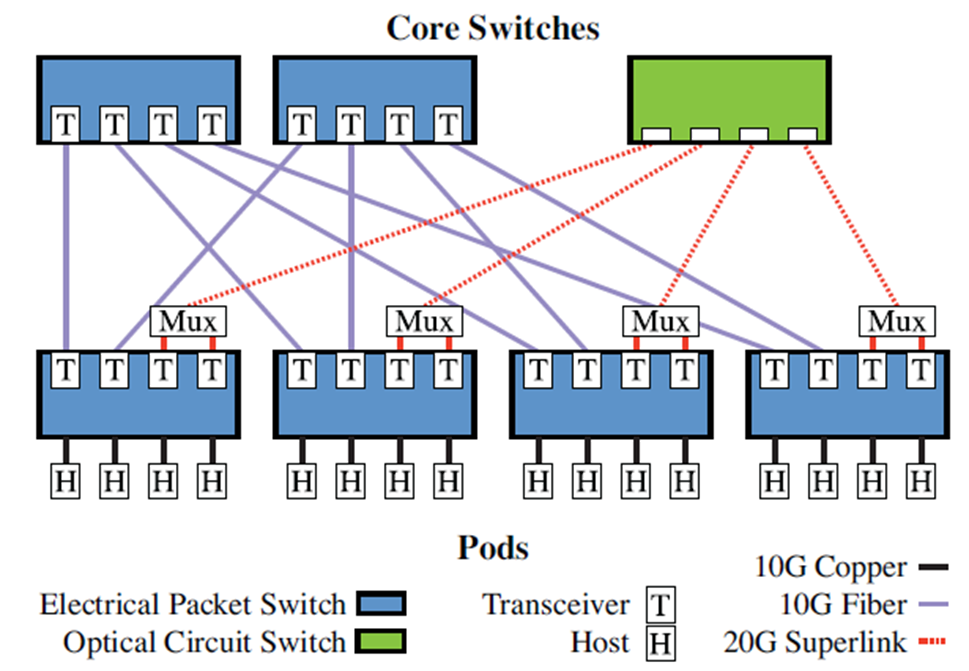
(4)在数据包时间尺度上,50% 的二等分带宽在 pod 之间共享。例如,任意到任意分组交换。50% 分配给特定的源-目标 pod 对,并且可以在毫秒时间尺度上重新分配。例如,一对一电路交换。
(5)问题:给定 pod 间流量模式,找到分组交换机(packet)和电路交换机(Circuit)的最佳分配。
Circuit switching和packet switching特点、优劣
使用分组交换的好处和问题是什么?
(1)无block交换。
(2)成本低、功耗低、复杂性低、Oversubscription
(3)用于铜缆,电缆长度和带宽之间的权衡;光纤没有长度限制,使用激光,价格昂贵;
(4)电路交换的转发不是基于地址,而是基于交换机端口。同价值情况下,电路交换的功耗更低。
Oversubscription
(1)pod内服务器互联问题基本解决。
(2)为任意的 all-to-all pod 间通信模式提供全带宽是昂贵且没有必要的
(3)很少有应用程序以如此规模运行或具有如此持续的通信要求。
(4)希望能够根据动态变化的通信模式,在需要的时间和地点分配可用带宽池,而不是为最坏情况下的通信要求做准备。
0x04 BBR
重点概览
(1)基于loss的拥塞控制存在什么问题?
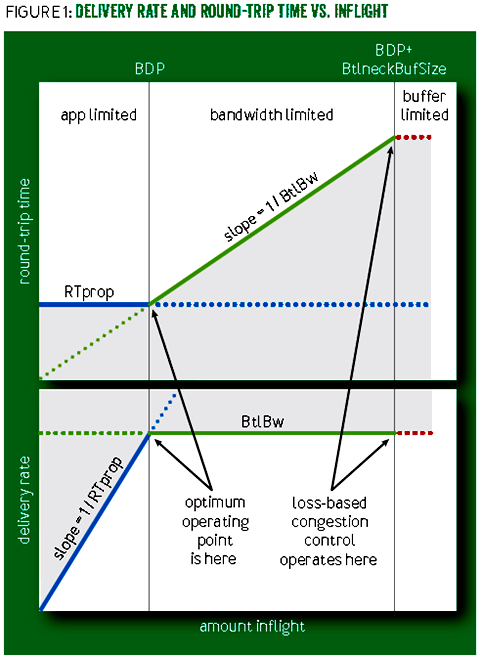
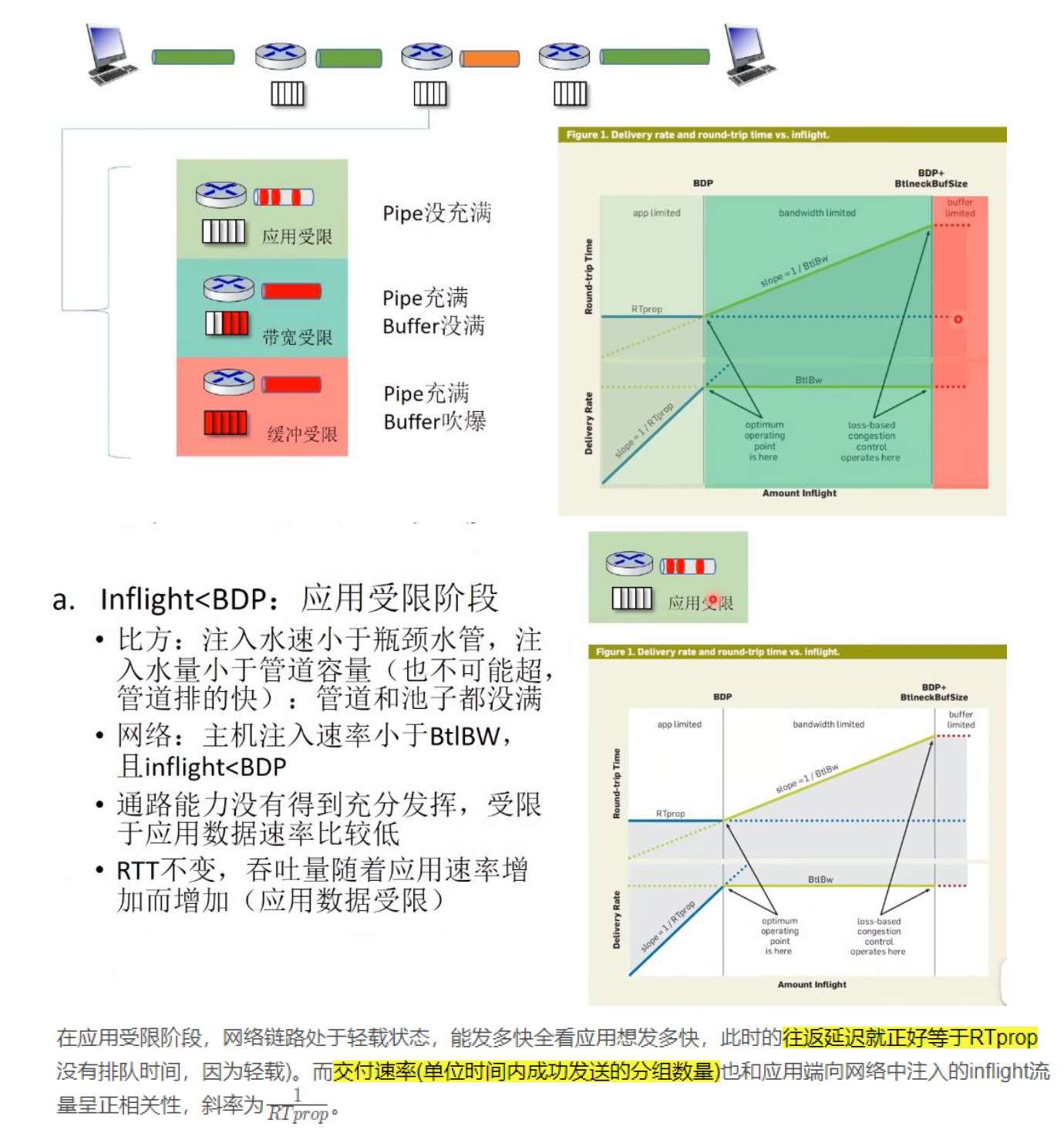
(2)理解下图
a.两个关键点,BBR工作在哪个点,基于loss的拥塞控制工作在哪个点?
b.左侧和右侧分别有什么行为?观察到什么现象?原则上怎样调整?
详细内容
基于loss的拥塞控制存在什么问题?为什么?
(1)带宽剧烈震荡,吞吐量低(链路利用率不高)。首先是随着网络链路带宽的不断变大和无线链路的广泛使用,链路上出现丢包的可能性大大增加了。因出错而丢包、因无线链路不稳定而丢包、 链路瓶颈处的 buffer 很小而丢包等 。如果此时仍简单的认为丢包=拥塞,就会导致传输带宽的剧烈振荡的情况发生。剧烈振荡的原因是传统 TCP 拥塞控制中 AIMD 的特性(加性增、乘性减),协议实体本身在不拥塞时试探性地一点点增大自己的发送窗口大小,一旦遇到拥塞就会将发送窗口骤降至原先的一半等行为会造成带宽的剧烈振荡,而实际的吞吐量并不高。
(2)端到端的延迟大。链路瓶颈处的 buffer 很大时,这类算法会持续占满整个缓冲区,导致 bufferbloat(延迟高的本质是随着网络设备的发展,链路中的各个设备的 buffer 大小也在不断增加,因为链路繁忙而临时缓存下来的数据也变得更多了。注意,一旦设备上的 buffer开始缓存数据,这时候本质上已经出现了链路拥塞,理想化的拥塞控制协议应该立即开始进行调整动作。但是对于基于 loss 的拥塞控制协议而言,它必须等到丢包出现时才开始进行拥塞控制动作。丢包开始时说明途径链路上的设备缓冲区也已经爆了,距离拥塞发生的时间更是已经过去很久很久了,这时再开始进行拥塞控制已经很迟了)
(3)算法侵略性强。所有的基于 loss 的拥塞控制协议总是倾向于挤爆缓冲区之后再回退,这种侵略性极强的行为会将某些不是基于 loss 的拥塞控制协议完全逐出网络,使其不能得到有效的带宽保障,极大地损害了网络的公平性。
例如,对于基于loss的TCP 拥塞控制(New Reno,CUBIC):
(1)巨大的 RTT (发送数据和被 ack 数据之间的时间差)路径上有足够的缓冲区。大量的动态数据 (data in flight),称为 bufferloat。
(2)低吞吐量与频繁的包丢失,重传和 cwnd(拥塞窗口) 减少。
图的理解
蓝线展示 RTprop 限制,绿线展示 BtlBw 限制,红线是瓶颈缓冲区 (bottleneck buffer)。
横轴表示 inflight(动态数据)数据量,关键的点有三个,依次为0 -> BDP -> BDP+BtIneckBuffsize,将整个空间分为了三个部分:
(1)(0,BDP):这个区间内,客户端发送的数据并未占满瓶颈带宽(容量),因此称为应用受限 (app limited) 区域。
(2)(BDP,BDP+BtlneckBuffsize):已经达到链路瓶颈容量,但还未超过瓶颈容量+缓冲区容量,此时应用能发送的数据量主要受带宽限制,因此称为带宽受限 (bandwidth limited) 区域。
(3)(BDP+BtlneckBuffsize,infinity) :这个区间内,实际发送速率已经超过瓶颈容量+缓冲区容量,多出来的数据会被丢弃,缓冲区大小决定了丢包多少,因此称为缓冲区受限 (buffer limited) 区域。
灰色区域是不可达的,因为它违反了至少其中一个限制。限制条件的不同导致了三个可行区域(应用受限、带宽受限、缓冲区受限)各自有不同的行为。
BDP(带宽延迟乘积:Bandwidth delay product)= RTprop×BtlBw
RTprop(往返时延:roundtrip propagation time):是网络完全轻载(没有排队时间)时的往返传播延迟之和。
BtlBw(瓶颈链路带宽:bottleneck bandwidth):指的是在整个通信链路上分得带宽最小的那一截链路,它是整条通信链路中源目标吞吐量的决定性因素,如果发生拥塞,在瓶颈链路这里将最先发生数据包的缓存。
两个关键点
(1)BDP:optimum operating point (最优的工作点)。1979 年 Kleinrock 证明了这个点是最优的,能最大化传输速率、最小化延迟和丢包,无论是对单个连接还是整个网络都是如此。但是几乎在同一时间被证明不存在能收敛到这个点的分布式算法, 于是研究方向从哪个寻找达到最佳工作点的分布式算法转向了对不同拥塞控制方法的研究。
(2)BDP+BltneckBufSize :基于 loss 的拥塞控制算法在这里运行。
左侧和右侧分别有什么行为?观察到什么现象?原则上怎样调整?




0x05 MPTCP
重点概览
(1)MPTCP拥塞控制的目标
(2)理解EWTCP和Coupled
(3)能判断EWTCP和Coupled各自获取的带宽
详细内容
MPTCP拥塞控制的目标
(1)能够对单个连接使用多个网络路径。
(2)能够使用可用的网络路径,至少与常规 TCP 一样,但不会使 TCP 匮乏。
(3)与现有应用程序的常规 TCP 一样可用(无需更改最终主机)。
MPTCP协议本质是作为一个传输层的中间件出现的,它的主要目的是将一个数据流划分到多个路径上传输。一个TCP连接管理多个subflow,每个subflow可以在网络中进行自由选路,并且每一个subflow都维护着属于自己的一个私有的发送窗口$W_r$,而MPTCP的发送者则在任何一subflow发送窗口有余量时将数据分发给它们去传输,以上是对MPTCP的一个简要概括。其特征如下:
(1)每个子流r维护自己的拥塞窗口$W_r$。
(2)与TCP是并行的。
(3)子流之间是互相独立的。当一个子流拥塞时,其他子流不会变得繁忙。
原始TCP拥塞控制算法:

如果直接应用原始的TCP拥塞控制算法,那么会造成不公平(拥有 n 个 subflow 的 MPTCP 获得的带宽将是单路径 TCP 的 n 倍)。
理解EWTCP和Coupled
EWTCP(Equally Weighted TCP)如下:

但是EWTCP算法不能合理的选择有效路径。表现如下:
(1)三个链接每个都有 12Mbps
(2)链路带宽被三个相同的子流平均分割,尽管它们来自不同的连接
(3)如果在两条路径上平均分配流量,则每个子流的流量为 4Mbps ,总共为 8Mbps
(4)应该会把所有流量转移到最不拥挤的路径,获得 12Mbps 。已有理论上的证据表明:对于多路径传输的情形, 最优解总是将其所有流量迁移至拥塞程度最低的路径 。而且有一种算法在理论上被证实,不需要进行拥塞程度侦测也可以自适应地找到最优解,这就是COUPLED 算法。如下所示:

COUPLED 算法有两种情况:
(1)各个链路拥塞程度相等。在 COUPLED 算法中,一个 MPTCP 的各个 subflow 获得的总带宽之和只与链路丢包率有关,这证明了 COUPLED 拥有天然的带宽竞争公平性,这是各个链路丢包率相同时的情况。
(2)各个链路拥塞程度不相等。首先对 COUPLED 算法中的每一条 subflow 而言,每次增加或减少的窗口值对所有 subflow 是统一的,只与那个时刻的 $W_{total}$ 有关。那么拥塞程度高的链路势必在指定的一段时间内会遇到更多的丢包,长远来看最终算法会慢慢将其流量逐渐向低拥塞链路汇集,从而实现了 EWTCP 没有实现自适应功能。
将流量从高拥塞链路向低拥塞链路迁移的动作会带来全网络的丢包率逐渐收敛到均衡。 这意味着如果执行 COUPLED 算法,(2)状态会最终向(1)过渡 ,最终达到收敛时,各个 MPTCP 实体都会获得相等的全局链路带宽。
能判断EWTCP和Coupled各自获取的带宽
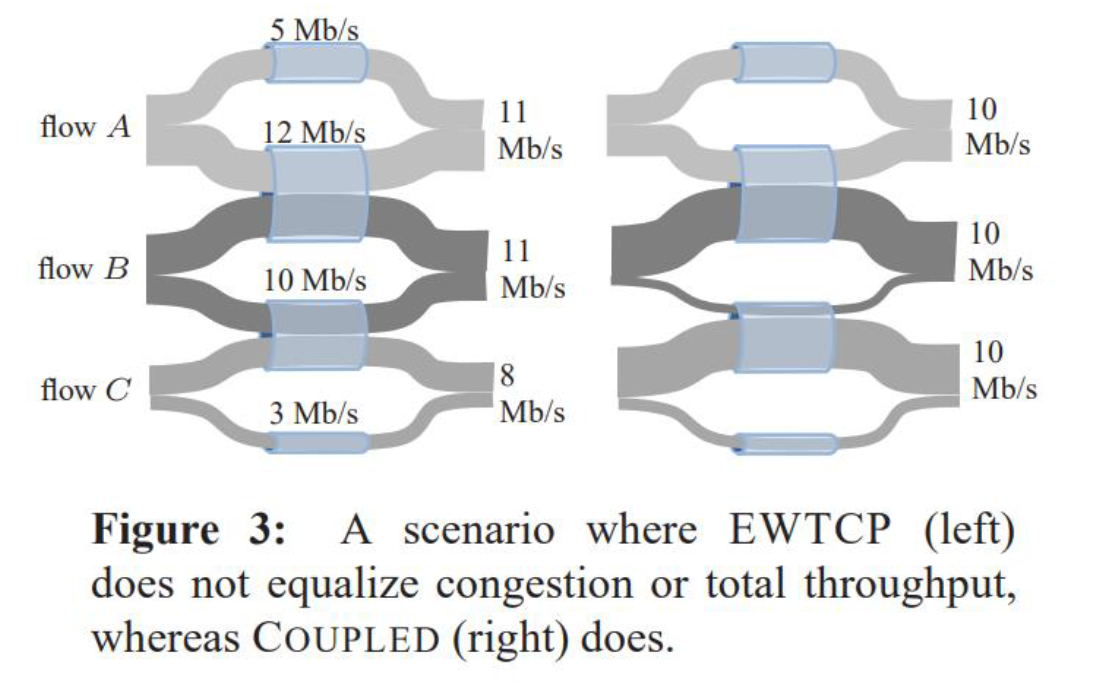
EWTCP:管道内按$a^2$的大小比例分; coupled:每个流总体量是一样的。
左图(EWTCP):Flow A(5+6); flow B(6+5);flow C(5+3)
右图(coupled):Flow A(10); flow B(10);flow C(10)
0x06 Etalon
重点概览
(1)拥塞控制分几类?有哪些代表?为什么它们都不能在RDCN上很好工作?
详细内容
RDCN是什么?
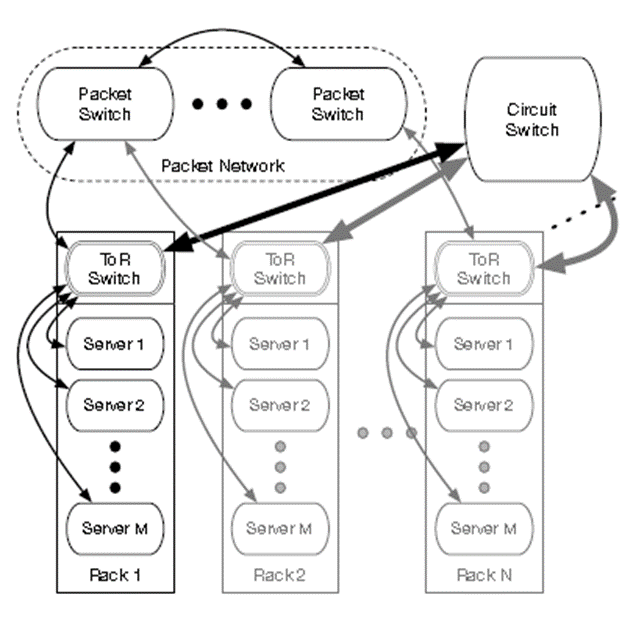
一个 RDCN:M 个服务器的 N 个机架。
ToRs连接器:
复杂分组网络:
(1)一个或多个分组交换机
(2)低带宽 (10Gbps)
(3)每个数据包转发决策
电路网络:
(1)1个集中式电路开关
(2)高带宽(80-100 Gbps)
(3)转发具有重新配置惩罚的数据包
(4)重新配置间隔过去以毫秒为单位,但现在以微秒为单位。
其组成结构如下:
拥塞控制分几类?有哪些代表?
(1)基于loss的拥塞控制
a. Cubic, Reno
b. 使用loss作为拥塞信号
c. 在没有loss的情况下探测更多带宽
d. RDCN 中的性能不佳,因为发送方不能足够快地提升以利用高带宽电路。
(2)基于delay的拥塞控制
a. BBR, Vegas
b. 电路和分组网络通常具有不同的传播延迟(30 μs 与 10 μs)
(3)基于Feedback的拥塞控制
a. DCTCP
b. 监控队列深度
为什么它们都不能在RDCN上很好工作?
RDCN通常具有高带宽、低延迟和大规模等特点,而这些特点使得传统的拥塞控制算法在RDCN上面临一些挑战。
(1)难以准确测量网络状态:在RDCN中,由于网络规模较大,网络拓扑结构复杂,网络延迟和带宽变化非常快,因此准确测量网络状态变得非常困难。这使得传统的拥塞控制算法难以快速地适应网络变化,从而导致网络拥塞和延迟增加。
(2)公平性问题:在RDCN中,由于网络规模较大,会存在大量的短流量和长流量,而传统的拥塞控制算法无法很好地处理这些不同类型的流量。如果某些流量过于集中,可能会导致网络拥塞和流量不公平问题。
(3)开销问题:在RDCN中,大量的数据包和流量需要通过网络传输,这会带来很大的网络开销和带宽消耗。而传统的拥塞控制算法通常需要发送大量的控制信息来调整网络状态,这会进一步增加网络开销和延迟。
0x07 FlowRadar
重点概览
(1)掌握Bloom filter,理解false positive错误的来源和概率
详细内容
Bloom filter
用于大致确定一个元素是否属于一个集合,当判断为否时一定不属于,召回率为100%。给定长为m 初始为全 0 的数组,用 k 个独立的哈希函数进行运算,集合中元素的数量记为 n。
插入元素x时,计算k个$h_i(x),i=1,…,k$ ,并将数组中所有对应的位置置 1。数列中的同一位置可能被不同元素多次置1。
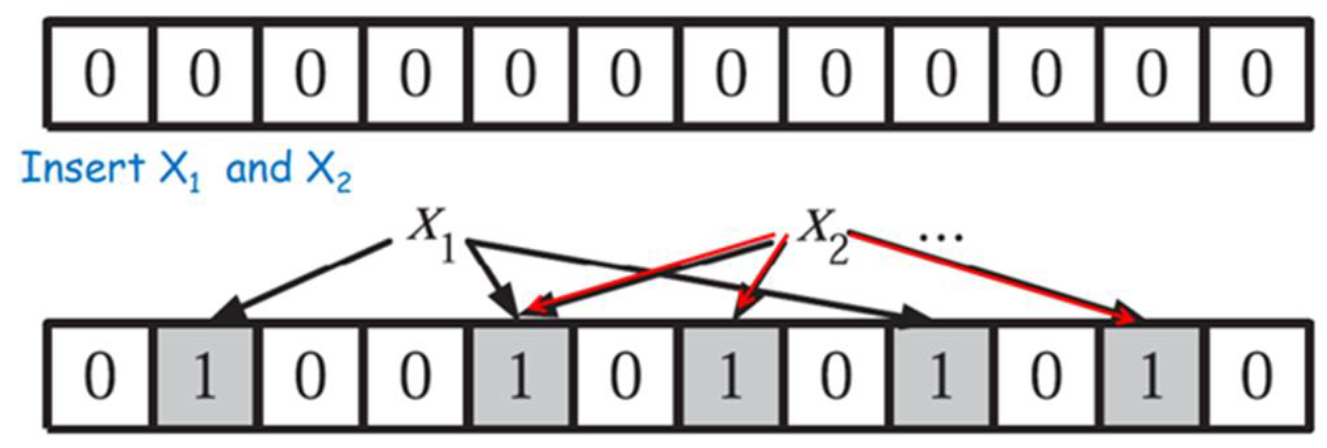
查询元素y时,计算 k 个 $h_i (y),i=1,…,k$ ,若对应位置为 0 ,则 y 必定不在集合中,若对应位置全为 1 ,则可能在集合中(也有可能假阳性,实际不在)。错误来源:刚好那几个位被标志成了1 ,导致了错误判断。
误差的概率:当插入了n 个元素以后,特定位置仍为 0 的概率为 p:
对于不在集合中的元素,判断它是集合中的元素(其对应的位置均为1 )的概率(误报概率)为:
当m 和 n 确定时,为使错误率最小, k 的最优取值为$k=(m/n)ln2$。
0x08 Elastic Sketch
重点概览
(1)掌握哈希表和CM
(2)理解Elastic Sketch的工作方式:a. heavy part和light part。b. P12示例
详细内容
哈希表与CM
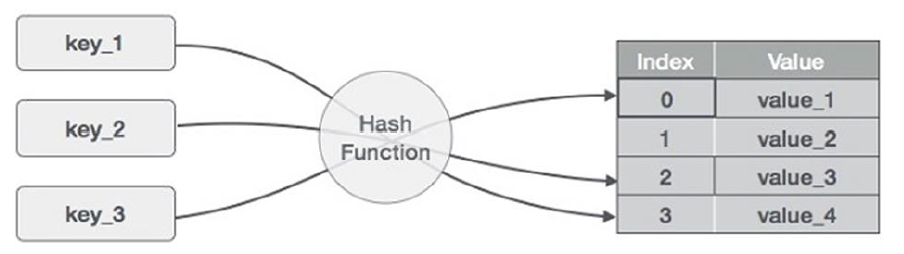
上图中,0=H(key_1)。
对于有 B 个 存储桶的表,存储桶的索引值范围为${0,…,B-1}$,存储桶包含:
(1)flowID :例如 5 元组
(2)计数器:流的数据包数或字节数
(3)其他信息
当以 h(f)%B 为索引的桶跟踪的流量 f 到达时,更新存储桶 H[h(f)%B]。查询 f 时,返回 H[h(f)%B]。当$\mathrm{f} 1 \neq \mathrm{f} 2$,$h(\mathrm{f} 1) \% \mathrm{~B}=\mathrm{h}(\mathrm{f} 2) \% \mathrm{~B}$时发生哈希冲突。
CM(count-min)表
可以用来计数的算法,在数据大小非常大时,一种高效的计数算法,通过牺牲准确性提高的效率。
d行计数器阵列,$L_1, L_2, \ldots, L_d$,每行都有w个计数器,且有d个哈希函数。如下所示:
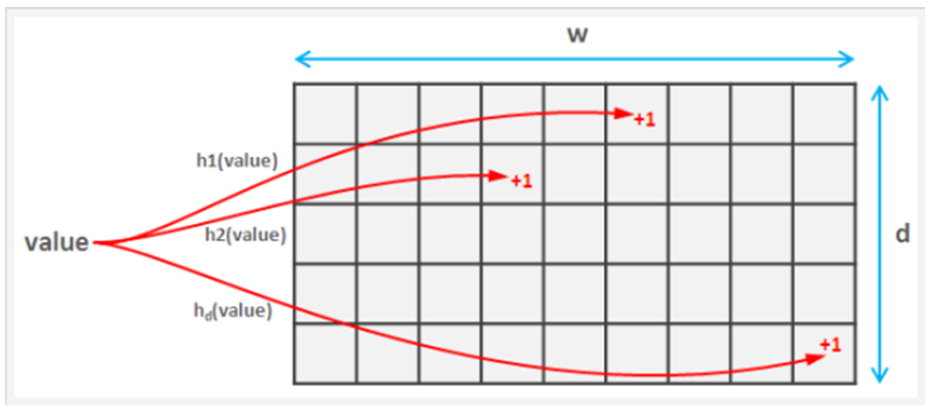
当接收到流f的数据包时,对于每个数组$L_i$,更新为$L_i(H_d(f))+1$。
估计流量f时,对于$0<=i<d$,返回$min(L_i(H_d(f)))$。CM在插入和查询的时候都先对 f 用不同哈希函数进行哈希,得到多个不同值,插入时将 f 对应 CM 表的位置都加上 f 的数量(正票数),查询时返回 f 对应位置中值最小的一个作为 f 的数量(其实返回的是 f 数量的上限)。
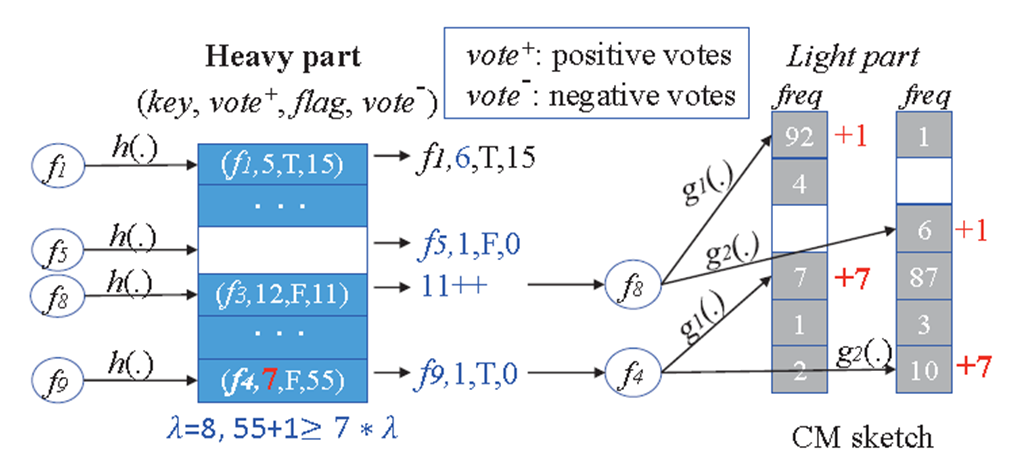
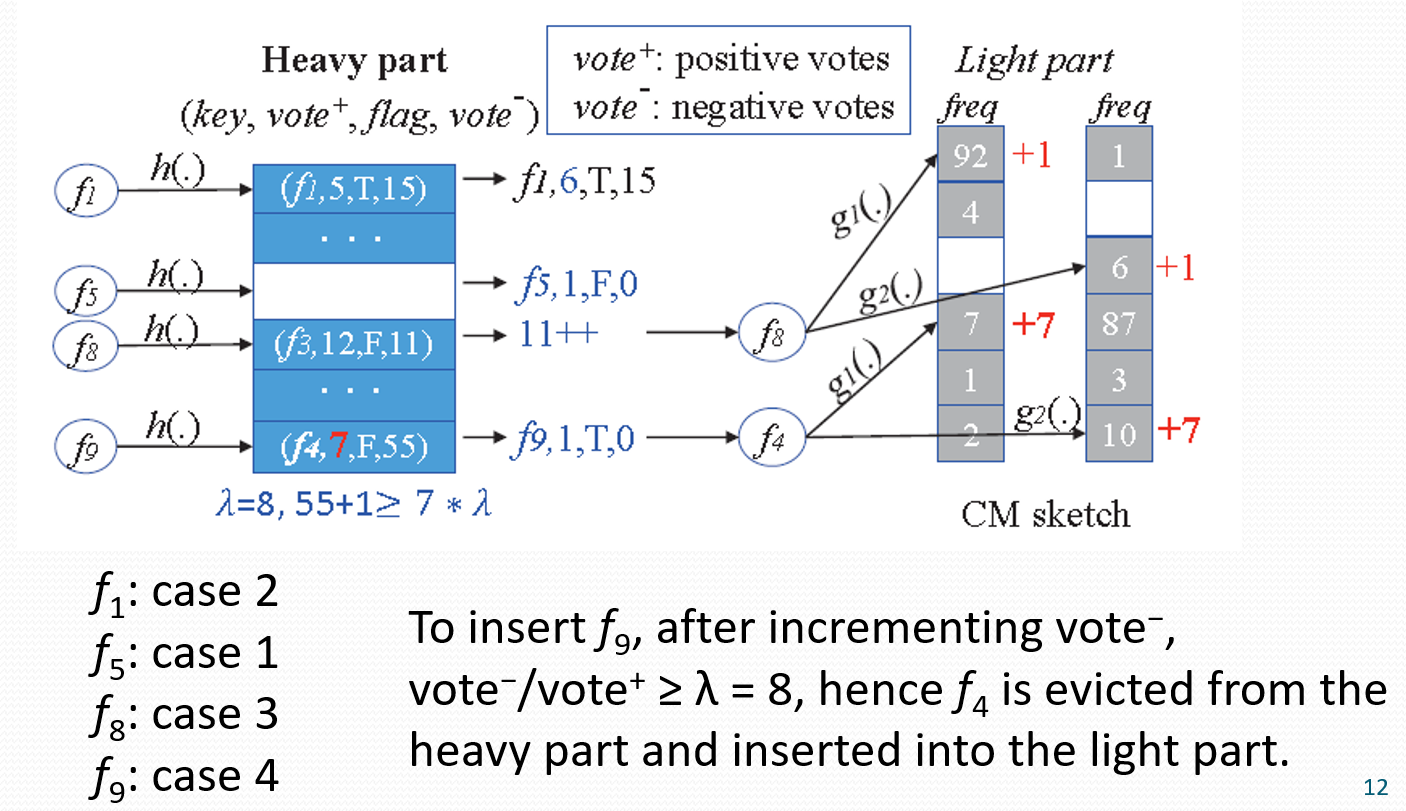
Elastic Sketch的工作方式
Heavy:有哈希表H;每一个哈希桶包括:flowID,正向vote(属于流的数据包数),负向vote(其他数据包数),flag(light 部分是否包含对该流的正向vote)。
Light:CM。
插入操作
(1)收到流f后,计算$H[h(f) \% B]$,假设桶此时的状态为$\left(f_1\right.$, vote $^{+}$, flag $_1$, vote $\left.^{-}\right)$。
(2)如果桶是空的,那么插入$(f, 1, F, 0)$。
(3)如果$f=f_1$,那么vote $^{+}$加1。
(4)如果$f \neq f_1$,且有vote $/$ vote $e^{+}<\lambda$,那么vote $^{-}$加1,并且向CM中插入f。
(5)如果$f \neq f_1$,且当vote $^{-}$加1时,满足 vote $/$ vote $^{+} \geq \lambda$,那么将此桶设置为$(f, 1, T, 1)$。$f_1$被放到 Light part ,使$f_1$对应的 CM 加上$f_1$的正向vote。
如下图所示:
查询操作
(1)流f 不在 heavy part 中,用 CM 估计
(2)对于heavy部分的流量f:标志是F :返回 $vote^+$。标志为T :返回 $vote+$ 和 $CM$中的查询结果之和。
0x09 PIFO
重点概览
(1)PIFO队列如何工作?enqueue、dequeue
(2)STFQ算法和PIFO实现
详细内容
PIFO队列如何工作?
push-in first-out(PIFO) 队列:一种优先级队列,允许根据元素的等级将元素排入任意位置,但从头部出队元素。 排名较低的元素首先出队。在将元素排入 PIFO 之前,计算元素的等级。例如Scheduling transaction,scheduling tree等。
enqueue:根据数据包的等级插入到任意位置
dequeue:从头中移除。
STFQ算法和PIFO实现
STFQ算法:
(1)包入队之前,计算:

last_finish[f]:流 f 的前一个数据包的结束时间。
(2)包出队时,virtual_time += p.length。
举例说明:
两个流,A 和 B,$w_A=0.8$ 和 $w_B=0.2$,两个流都有很多数据包到达交换机,对队列长度没有限制,假设没有出队且数据包大小为1。对于流A,a1.rank=1.25, a2.rank=2.5, a3.rank=3.75, a4.rank=5, a5.rank=6.25, ...;对于流B,b1.rank=5, b2.rank=10, ...,最后出队序列为a, a, a, a, b, a, a, a, a, b, ...。
某些算法需要更改缓冲数据包的相对顺序,例如HPFQ(分层数据包公平队列)算法,其思想为:
(1)先在类之间划分链路容量,然后在每个类中的子类之间递归,一直向下到叶子节点。
(2)HPFQ 不能使用单个调度事务和 PIFO 来实现,因为已经缓冲的数据包的相对调度顺序可能会随着未来数据包的到达而改变。如下所示:
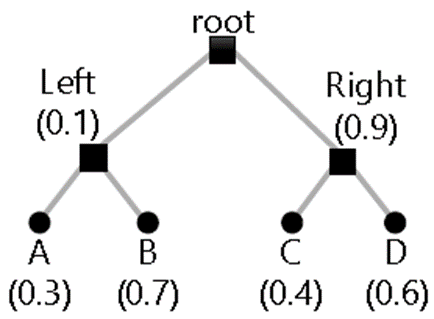
HPFQ的例子:
(1)根节点有两个子节点 A 和 B,份额分别为 0.8 和 0.2。 A 有两个子叶节点 A1 和 A2,份额分别为 0.5 和 0.3。
(2)在时间 0,A1 有一个空队列,A2 和 B 有很多数据包在排队。 A2 和 B 将分别拥有 80% 和 20% 的链路带宽。 A2 数据包的finish时间为 1.25,2.5,3.75 ...,B 数据包的finish时间为 5,10,15,..。最后出队序列为a2, a2, a2, a2, b, a2, a2, a2, a2, b, ...。
(3)假设,A1 数据包某一时间到达,A1、A2、B 的带宽份额将分别为 50%、30% 和 20%。 对于 A1 数据包,finish时间为2, 4, 6, ...。对于 A2 数据包,finish时间为3.33,6.66,9.99,...。此时,相对调度顺序发生变化。
PIFO实现:调度树
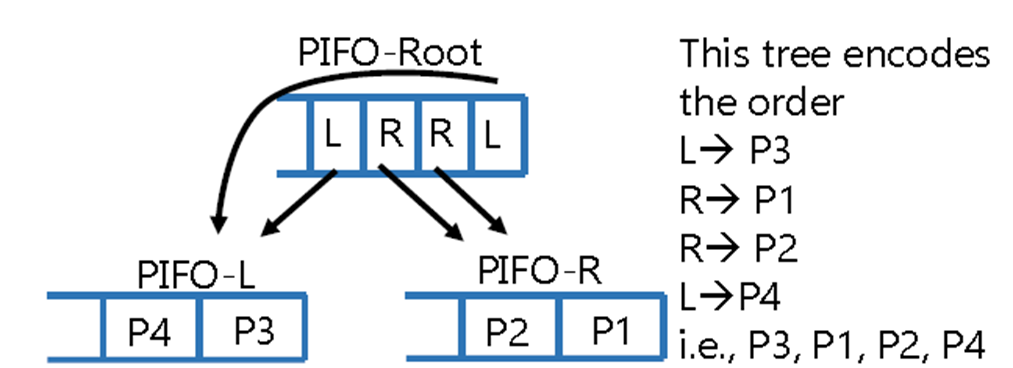
举例:
(1)根节点有两个子节点 A 和 B,份额分别为 0.8 和 0.2。 A 有两个子叶节点 A1 和 A2,份额分别为 0.5 和 0.3。
(2)时间 1。4 个 A2 和 1 个 B 到达:
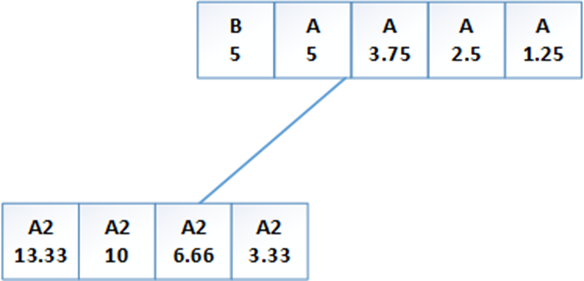
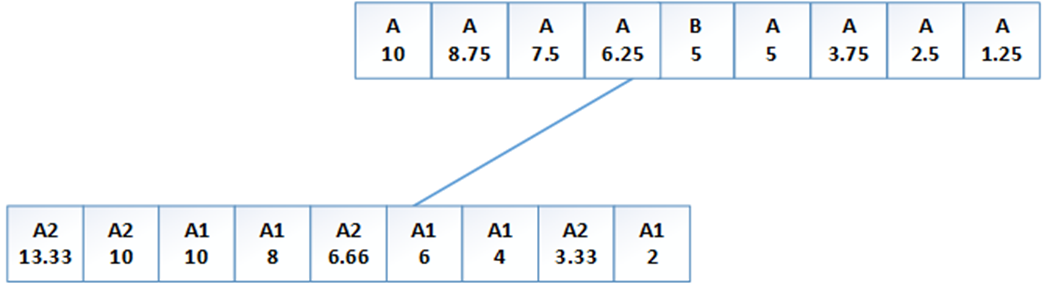
(2)时间 2。5个 A1 :
0x10 SP-PIFO(严格优先级SP)
重点概览
(1)SP-FIFO如何工作?Push-up、push-down
(2)结合例子理解
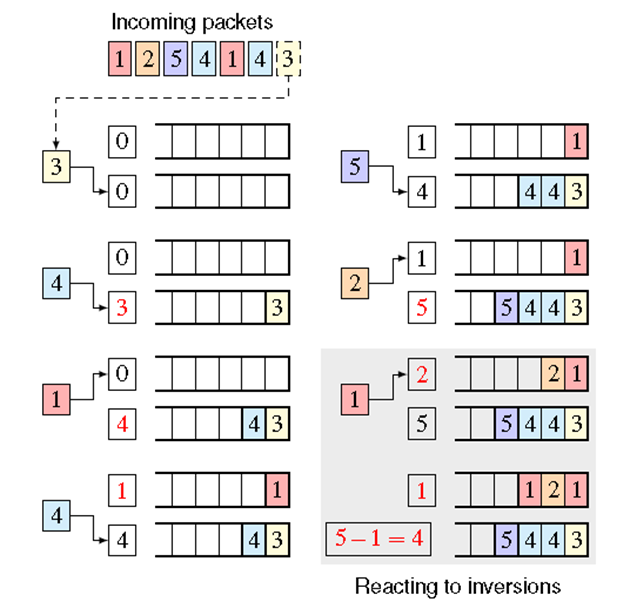
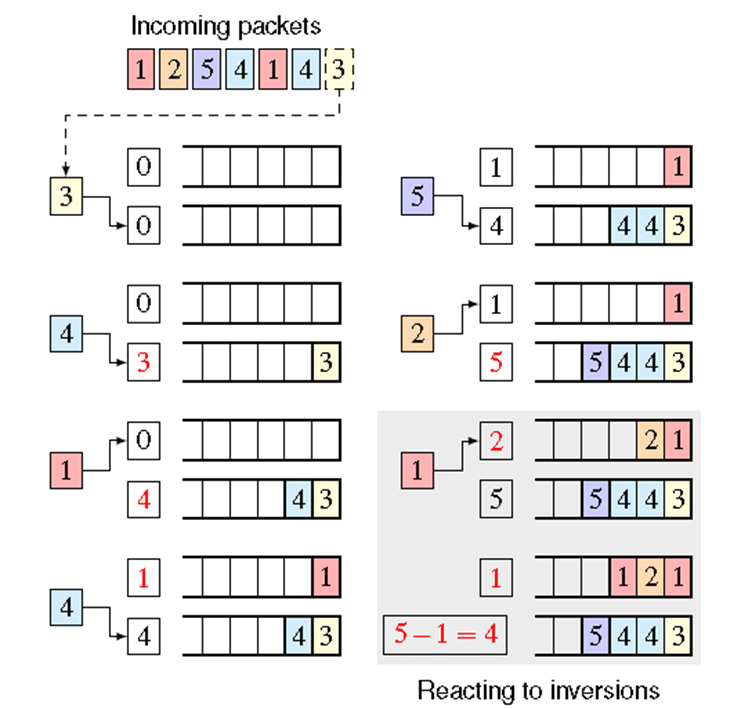
详细内容
SP-FIFO如何工作?
如下图所示:
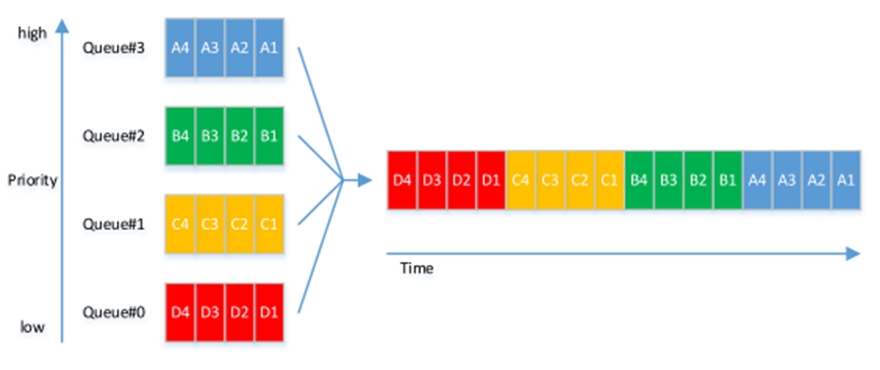
一个端口有多个FIFO队列,每个队列关联一个优先级。只有当所有优先级高的队列都为空时,队列才开始发送数据包。
图示:
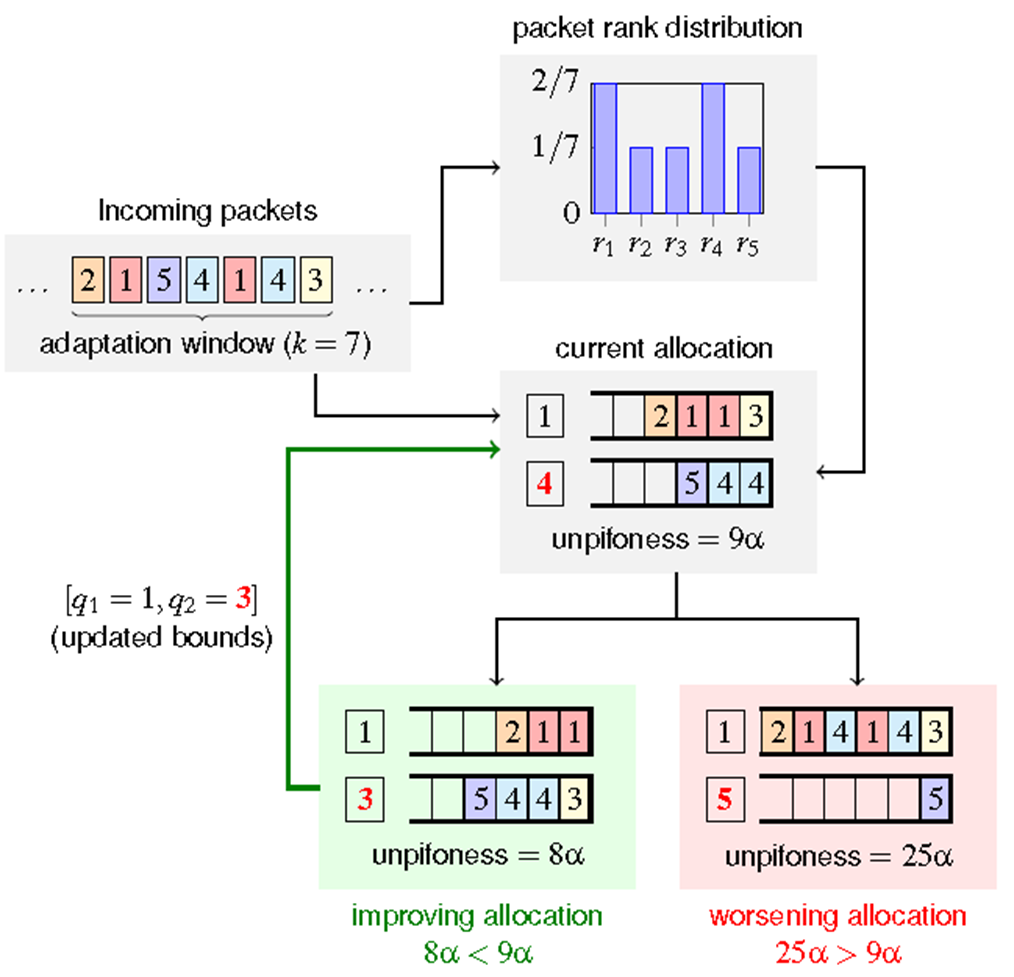
push-up:映射过程自底向上扫描队列,将数据包入队到第一个满足$r(p)≥q_i$的队列中。 然后它将 $q_i$ 增加到排队数据包的等级,即 $q_i=r(p)$。
push-down: 当检测到反转时,将所有队列边界减少$q_1-r(p)$。如下图所示:
0x11 Odin
重点概览
(1)理解LVAP,per-client、构成、迁移
详细内容
无线局域网的室内定位技术。
协议介绍
(1)LVAP全称 light virtual access points(轻量级虚拟访问点),在 odin 中,每一个客户端拥有一个 per-client LVAP。
(2)每个客户端都由具有唯一 BSSID 的控制器分配一个 LVAP。
(3)物理AP拥有多个 LVAP。
(4)BSSID:AP的唯一标识,通常是 ap wifi 接口的 mac 地址。
(5)ESSID:是 BSSID 的集合。
(6)SSID:指的是 WLAN 的名称,类似于 ustcnet 这样的名称。
补充:OpenFlow
OpenFlow是一种网络协议,用于实现软件定义网络(SDN)中的网络控制。OpenFlow协议定义了网络设备(如交换机、路由器等)和控制器之间的通信接口,使得网络管理员可以通过集中的控制器来管理和控制网络中的所有设备。
LVAP的结构
(1)一个唯一的虚拟 BSSID
(2)一个或多个 SSID
(3)client 的 ip 地址
(4)openflow 的规则集合
odin的系统构造
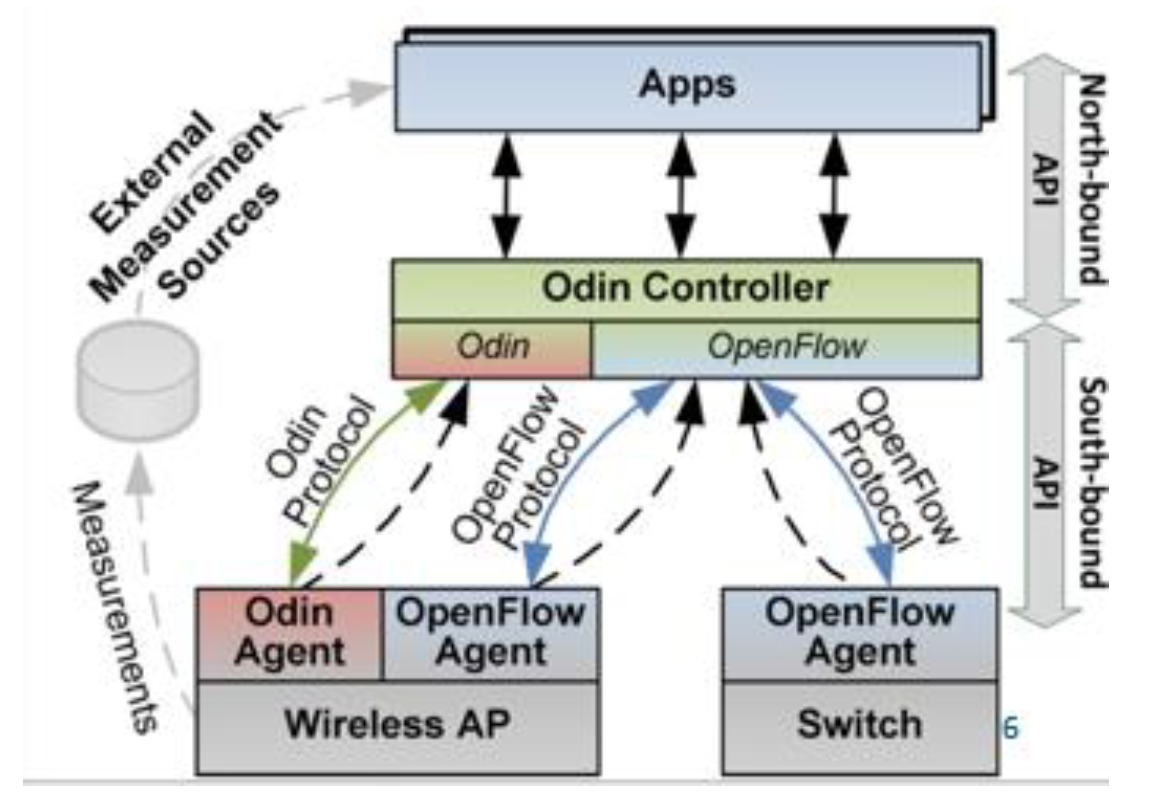
(1)有线和无线网络编程的独立协议
(2)odin controller (作用:提供接口给 apps、维护网络视图)
(3)odin agents(odin agent 工作在 wireless ap 上面,处理 802.11 协议的帧)
(4)applications
处理流程
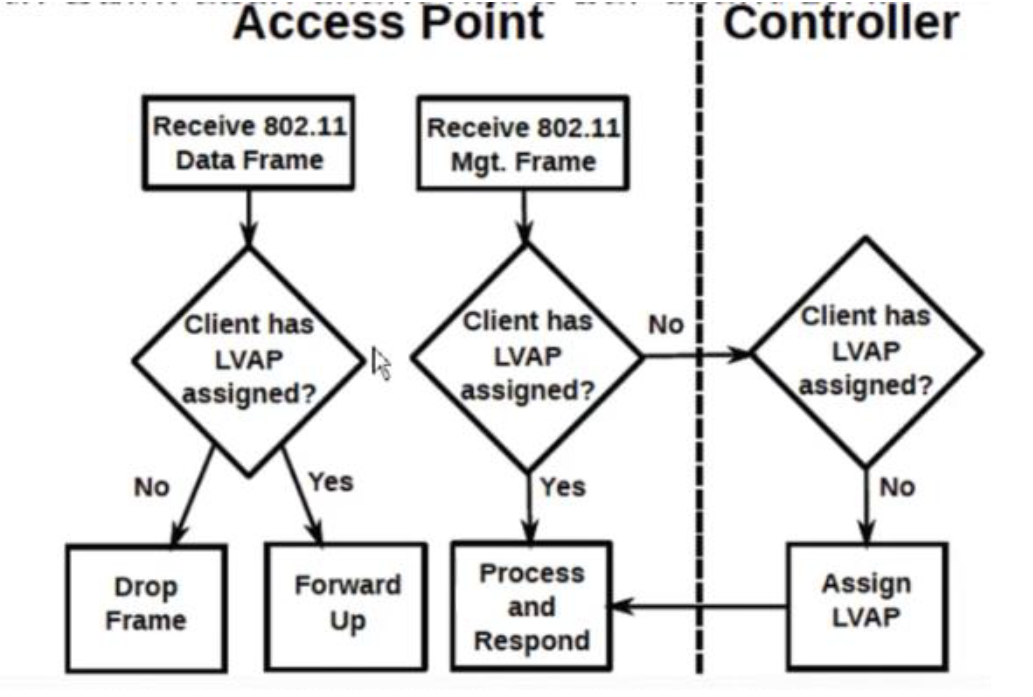
odin的新服务:移动管理、负载均衡、网络信道质量监控、自动信道选择。
odin提出的动机: 随着无线技术在最后一跳变得流行,今天的网络运营商需要与有线网络运营商协调管理 WiFi 接入网络。然而,现有解决方案中功能集的不一致性以及缺乏可编程性使这成为一项具有挑战性的任务。
本文提出了一种基于 SDN 的解决方案 Odin 来弥补这一差距:
(1)轻型虚拟接入点( LVAP ),一种用于解决 IEEE 802.11 协议栈复杂性的新型编程抽象。
(2)基于 LVAP 的软件定义 WiFi 网络架构的设计和实现。
(3)在商品接入点硬件上的原型实现,无需修改 IEEE 802.11 客户端,使其适用于当今的部署。为了强调该方法的有效性,我们在 Odin 上演示了六种 WiFi 网络服务,包括负载平衡、移动性管理、干扰检测、自动信道选择、能量管理和来宾策略实施。为了进一步促进我们框架的开发, Odin 原型已公开。
0x12 B4
重点概览
(1)TE算法
详细内容
B4广域网:提供数据中心之间的连接,第一个也是最大的 SDN/OpenFlow 部署。
TE算法(Traffic Engineering)
TE 服务器运行于:
(1)网络拓扑:图形将站点表示为顶点,将站点到站点的连接表示为边。
(2)流组(FG):{源站点,目标站点,QoS} 元组。
(3)隧道(T)表示站点级路径。
(4)隧道组(TG) 将 FG 映射到一组隧道和相应的权重。
将隧道组TG输出到SDN网关,网关将隧道T和流组FG转发到OFC(OpenFlow Control),并使用Open Flow安装在交换机上。
应用程序带宽函数:给定流的相对优先级,给相应的流上的应用程序分配带宽。
FG带宽函数:每个应用程序带宽函数的分段线性加法组合。例如,App1 需要15Gbps(站点A到B),App2 需要5Gbps(站点A到B),App3 需要10Gbps(站点A到C),那么FG1=App1+App2,FG2=App3。
根据 FG 的带宽函数在 FG 之间分配边的容量,使得边上的所有竞争 FG 要么获得平等的公平份额,要么完全满足他们的需求。
通过增加它们在首选隧道上的公平份额来将所有 FG 填充在一起时,通过找到瓶颈(bottleneck)边进行迭代。冻结所有隧道穿过瓶颈边,移动到下一个首选隧道。算法步骤如下:
(1)用他们的首选隧道初始化每个 FG。
(2)通过为每个首选隧道提供平等的公平份额来分配带宽。
(3)冻结包含任何瓶颈链路的隧道。
(4)如果每个隧道都被冻结,或者每个 FG 都完全满足,则完成。
(5)为每个不满意的 FG 选择最喜欢的非冻结隧道,转到(2)。
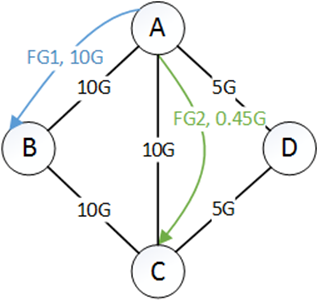
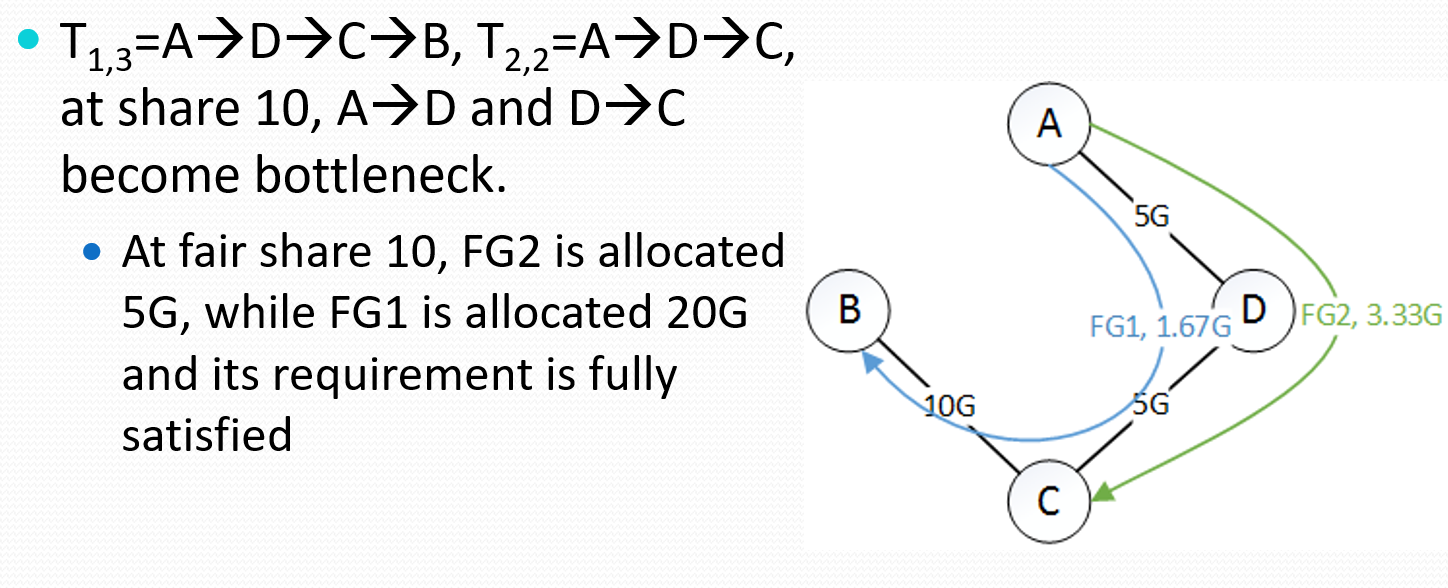
如何理解?举个例子,其中$T_{x,y}$:$FG_x$ 的第 y 个首选隧道(preferred tunnel)。有图:
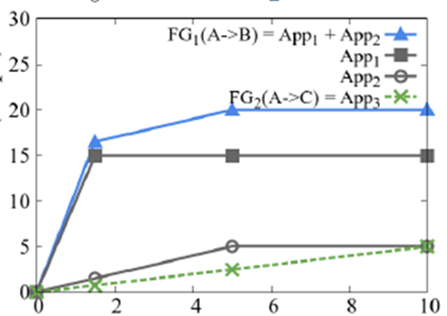
其横坐标是share,纵坐标为Gbps。最终要达到:$FG_1=20G$,$FG_2=5G$。
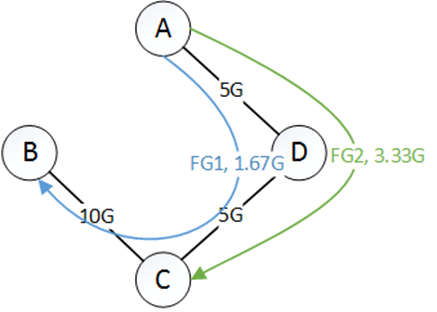
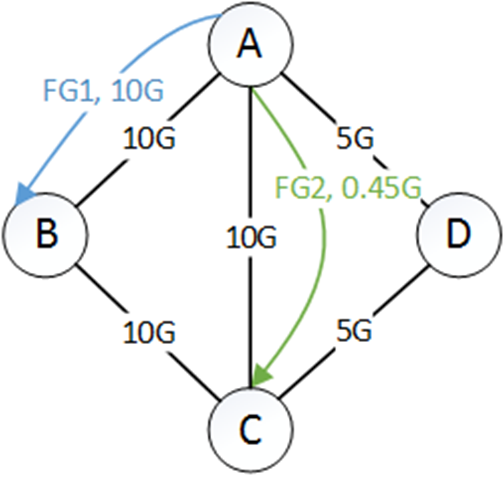
第一步,首选隧道是$\mathrm{T}{1,1}=\mathrm{A} \rightarrow \mathrm{B}, \mathrm{T}{2,1}=A \rightarrow C$,当share为0.9时,FG1 为10G,FG2为0.45G。因此,$A \rightarrow B$是瓶颈,所以去掉。剩下的$FG1$流量为10G,$FG_2$流量为4.55G。$\mathrm{T}{2,1}=A \rightarrow C$的剩余为9.55G。如下所示:
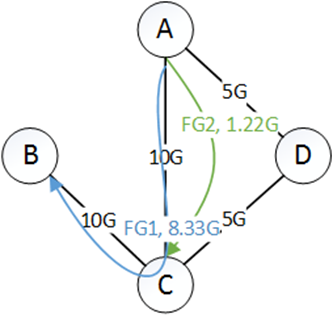
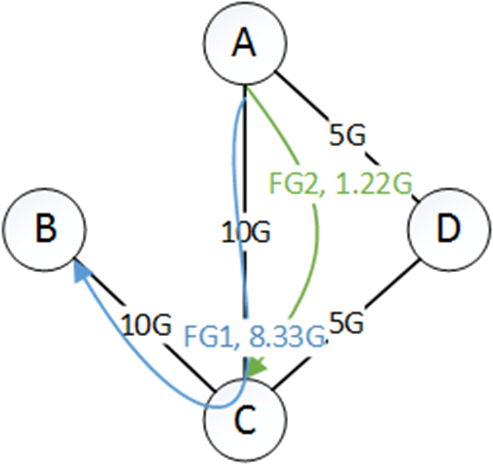
第二步,第二首选隧道是$\mathrm{T}_{1,2}=\mathrm{A} \rightarrow \mathrm{C} \rightarrow \mathrm{B}$(为什么另一个隧道没有,因为那个隧道的流量还没用完。),当share为3.33时,FG1 为18.3G,FG2为1.67G。因此,$A \rightarrow C$是瓶颈,所以去掉。剩下的$FG_1$流量为1.67G,$FG_2$流量为1.22G。$C \rightarrow A$的剩余为1.67G。给如下所示:
第三步,直接如下:
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!