OLLVM-study
OLLVM 原理、破解思路&hook
参考链接:https://www.cnblogs.com/theseventhson/p/14861940.html
OLLVM是安卓中常用的一种混淆方法。
0x00 LLVM原理
传统编译器流程:

1 | Fronted前端:做词法分析、语法分析、语义分析、生成中间代码(简单讲就是检查语法是不是正确的,并生成中间代码); |
上述编译流程最大的问题:Frontend、Optimizer、backend之间是紧耦合的,互相拆不开。
LLVM架构:
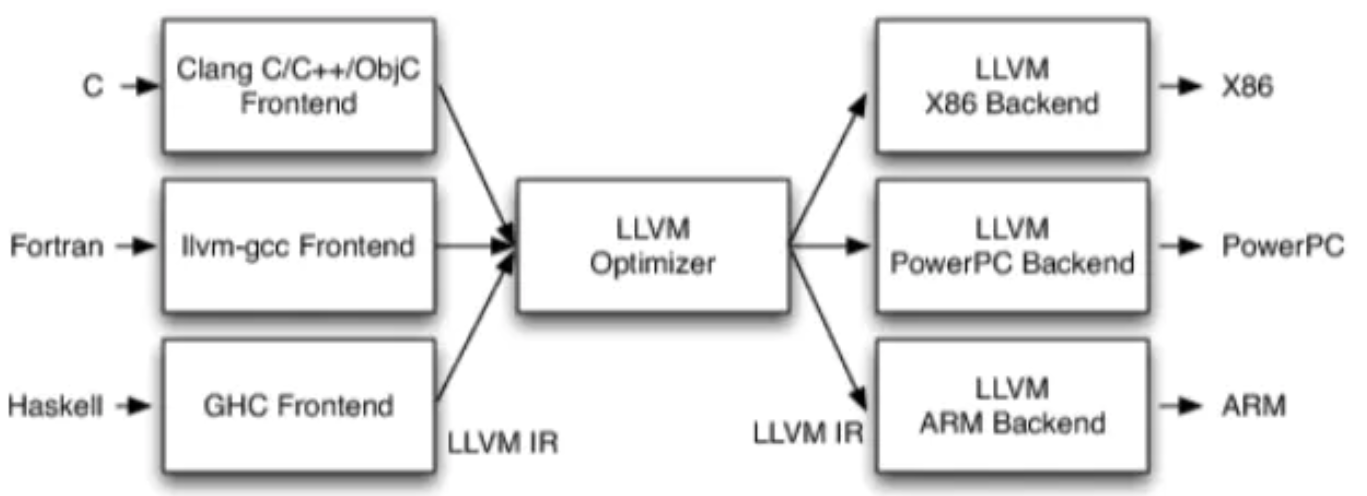
注意:
- 优化阶段 Optimizer 是一个通用的阶段,它针对的是统一的LLVM IR,不论是支持新的编程语言,还是支持新的硬件设备,都不需要对优化阶段做修改,前后端都遵从统一的IR标准。
- 相比之下,GCC(一种开源编译器)的前端和后端没分得太开,前端后端耦合在了一起。所以GCC为了支持一门新的语言,或者为了支持一个新的目标平台,就变得特别困难。
- LLVM现在被作为实现各种静态和运行时编译语言的通用基础结构(GCC家族、Java、.NET、Python、Ruby等)。
0x01 OLLVM原理
OLLVM就是在LLVM的基础上增加了obfuscator(混淆)。
Obfuscator是在中间optimizer这个环节做的。简单理解:OLLVM有一个框架,这个框架提供了很多API,调用这些API可以对IR中间代码做各种操作,比如下面的API:
1 | ConstantDataSequential *CDS =dyn_cast<ConstantDataSequential>(GV->getInitializer()); |
上述API的意思是:逐行扫描IR代码的字符串,并异或,达到混淆的目的。
0x02 OLLVM的4种混淆方式
Instructions Substitution(加减法、逻辑运算)
1 | 例1: |
可以混淆多次。
Bogus Control Flow(虚假控制流:BCF)
简单的代码:
1 |
|
BCF处理后:

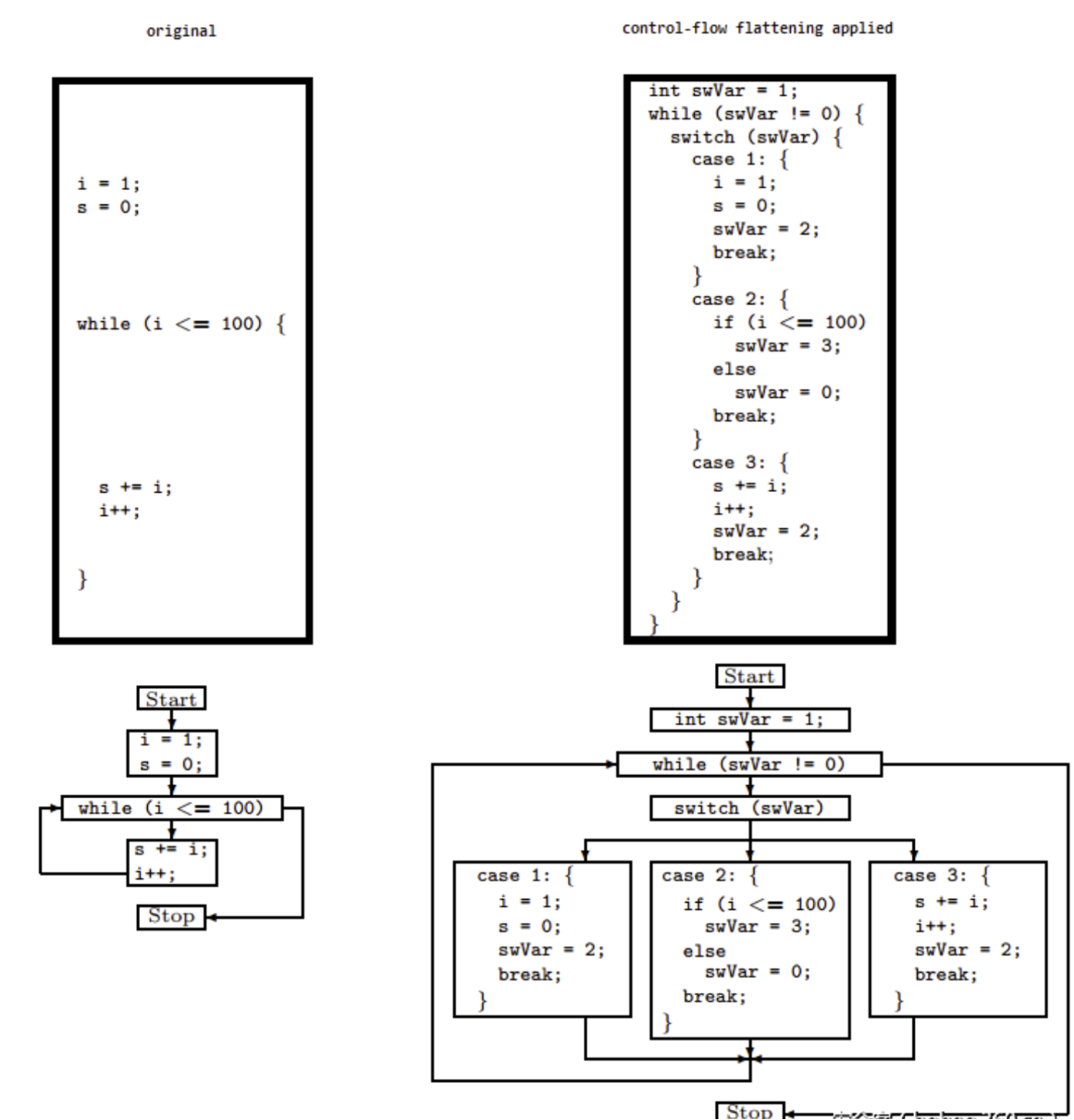
Control Flow Flattening(控制流平坦化:CFF)
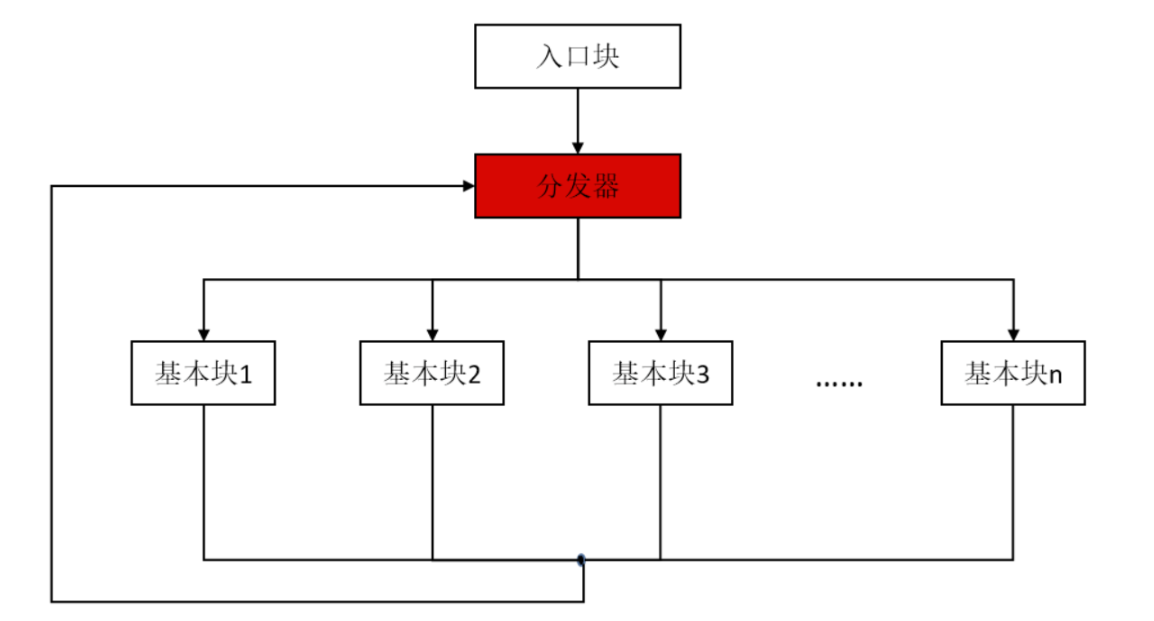
最常见的混淆。原理:将if、while、for、do等控制语句转换成switch分支语句,可以模糊switch中case代码块之间的关系,从而增加分析难度。
做法:将要实现平坦化的方法分成多个基本块(就是case代码块)和一个入口块,为每个基本块编号,并让这些基本块都有共同的前驱模块和后继模块。前驱模块主要是进行基本块的分发,分发通过改变switch变量来实现。后继模块也可用于更新switch变量的值,并跳转到switch开始处。如下图所示:
字符串加密
调用OLLVM的API进行加密。
0x03 代码优化 LLVM IR pass
代码优化的实质是分析+转换。
LLVM IR (Intermediate Representation) 是 LLVM 的一种中间表示,中间表示的生成是便于更好的代码优化。LLVM Pass 是 LLVM 代码优化中的一个重要组成部分。我们可以将 Pass 看作一个又一个的模块,各个 Pass 可以通过 IR 获取信息,直接对中间代码进行优化,或者为下一个 Pass 做好准备。
常见的代码优化方法有:
1 | 1. 删除公共子表达式。例如,x+y 以前被计算过,且一段时间内 x 与 y 中的变量值没有改变,则 x+y 就可以在这段时间内替换成一个常量。 |
LLVM 中 Pass 架构有很高的可重用性与可控制性,这使得用户可以自己开发 Pass 模块,或关闭默认开启的 Pass。Pass 分为两类:
1 | 1. 分析,提供信息。 |
To be continued…
0x04 静态分析除 FLA
最近做的一个 WMCTF 的题目中涉及到 OLLVM,但是脚本处理一直出问题,所以想更新一下这个脚本,但是这又需要 OLLVM 混淆与反混淆的知识。由于距上次接触到 OLLVM 已经过去了较长时间,这次接着这篇文章,完善丰富一下 OLLVM 的细节。
LLVM 主要有 3 种混淆方式,就是 0x02 中说的,包括 Instructions Substitution,Bogus Control Flow,Control Flow Flattening。需要注意的点是,这些混淆操作是在 LLVM IR 上做的,它基本上支持所有的架构。
重新介绍一下 Control Flow Flattening。其混淆步骤为:
1 | 1. 收集 CFG 种所有的原始基本块。 |
下图是一个 CFF 前后的函数流图(左边为混淆前,右边为混淆后)。
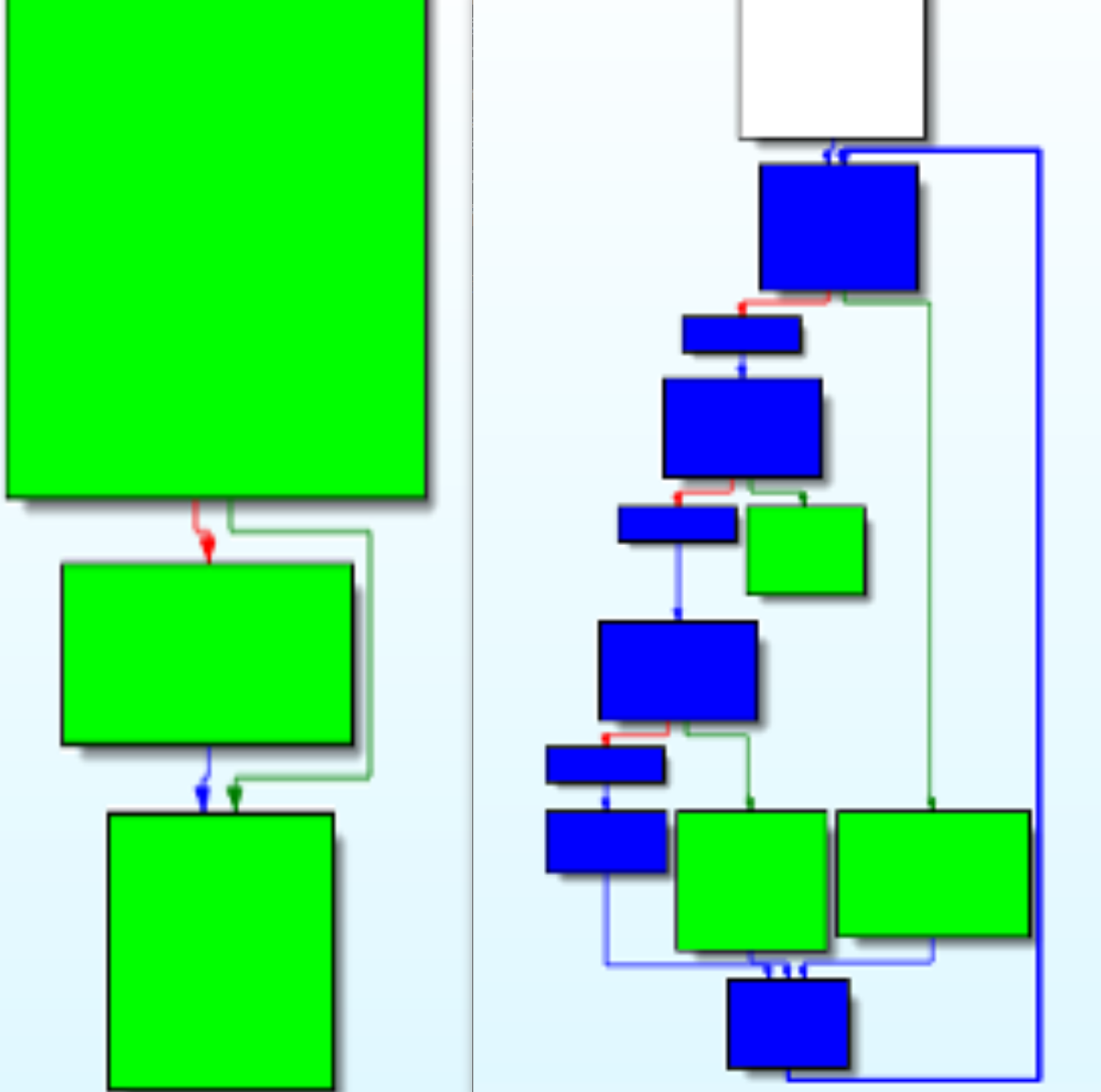
混淆后出现的蓝色块就是 machiery,这些 machiery 组成了 backbone。我们可以想象这些代码形成了一个状态机,每一个原始基本块的末尾都设置了状态变量以指向下一个基本块。Binary ninja 的特性使其天生就便于分析 LLVM 程序,而这些特性是 IDA 没有的,这些特性包括 Medium-level IL、SSA form、Value-set analysis。
下面介绍 CCF 的反混淆算法。
(1)确定 backbone(主干块)(上图蓝色块)。下图给出了一个主干块的示例:
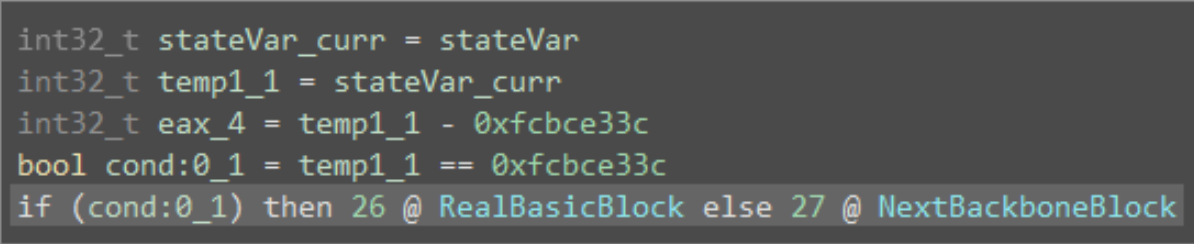
每一个主干块都很相似。即,读取当前的状态变量 stateVar,并与某个 case 值作比较,如果为真,则执行一个原始基本块,否则执行下一个主干块。那么,我们可以得出结论:给定一个 stateVar,每一个主干块至少用一次 stateVar。我们可以利用每个主干块至少使用一次 stateVar 的事实,遍历 Binary Ninja 的 medium-level IL 提供的变量的所有用法来收集每个主干块。
对于程序开头,在第一个基本块直接进入状态机之前,通常都会定义 stateVar,如下图所示:
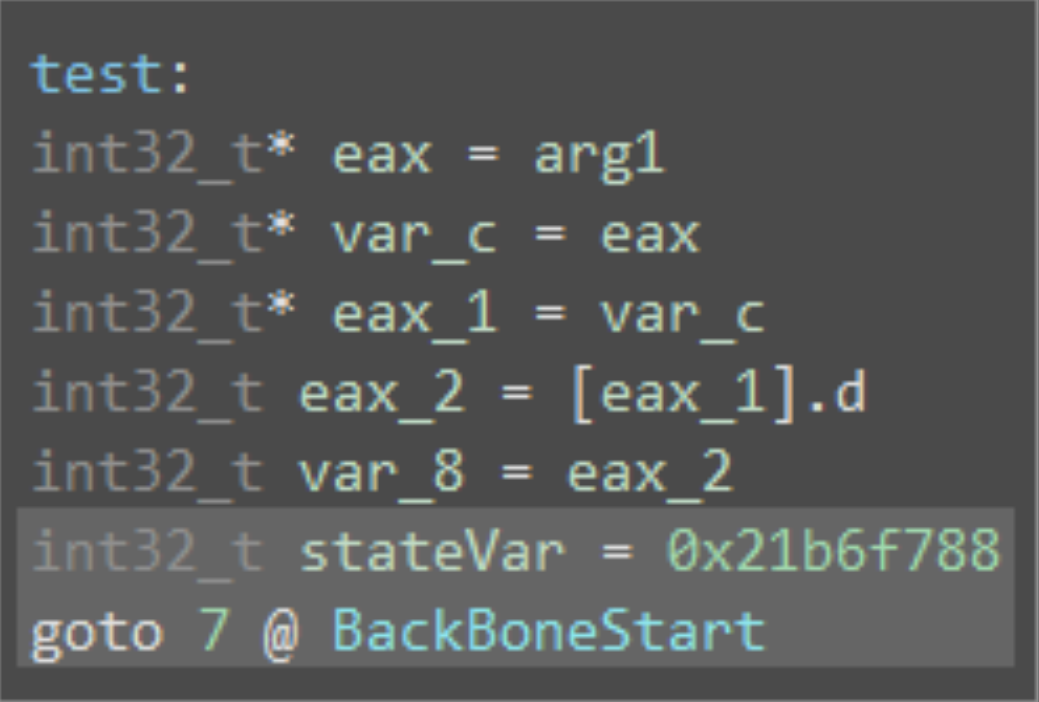
因此,我们以 stateVar 的定义为目标,且相关的主干块(backbone)都可以使用 use-def 与 def-use 的链图找到(如何找?可能需要看代码)。
1 | 注: |
(2)确定程序基本块(绿色块)。类似的,我们通过查看程序基本块的例子,识别出基本块的特征。下面看一个无条件跳转的程序基本块:
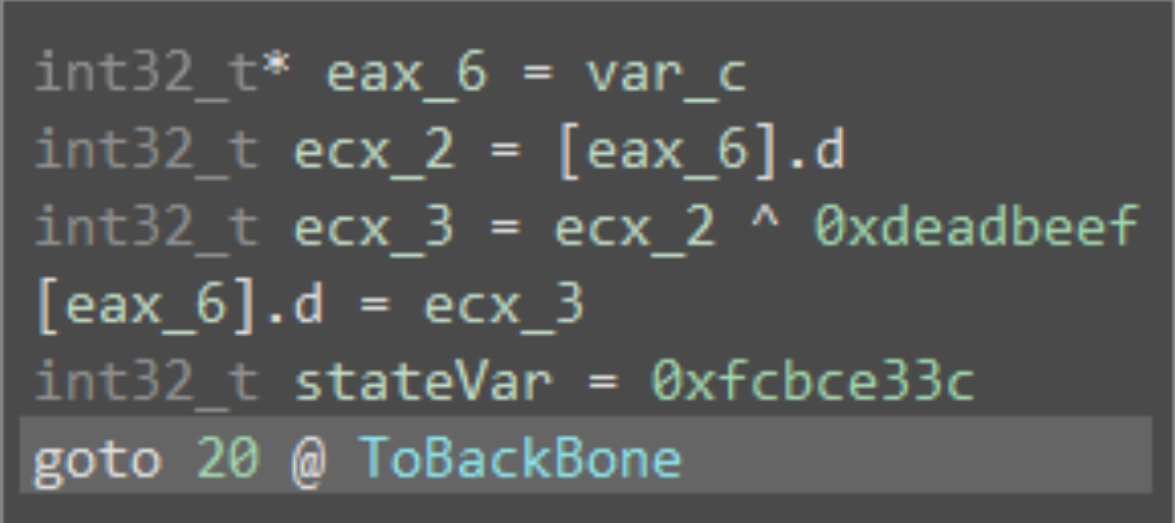
可以看出,在程序基本块的最后,将常量写入状态变量,然后返回主干块。如果这个基本块有多个后继的话,那么如下图所示:
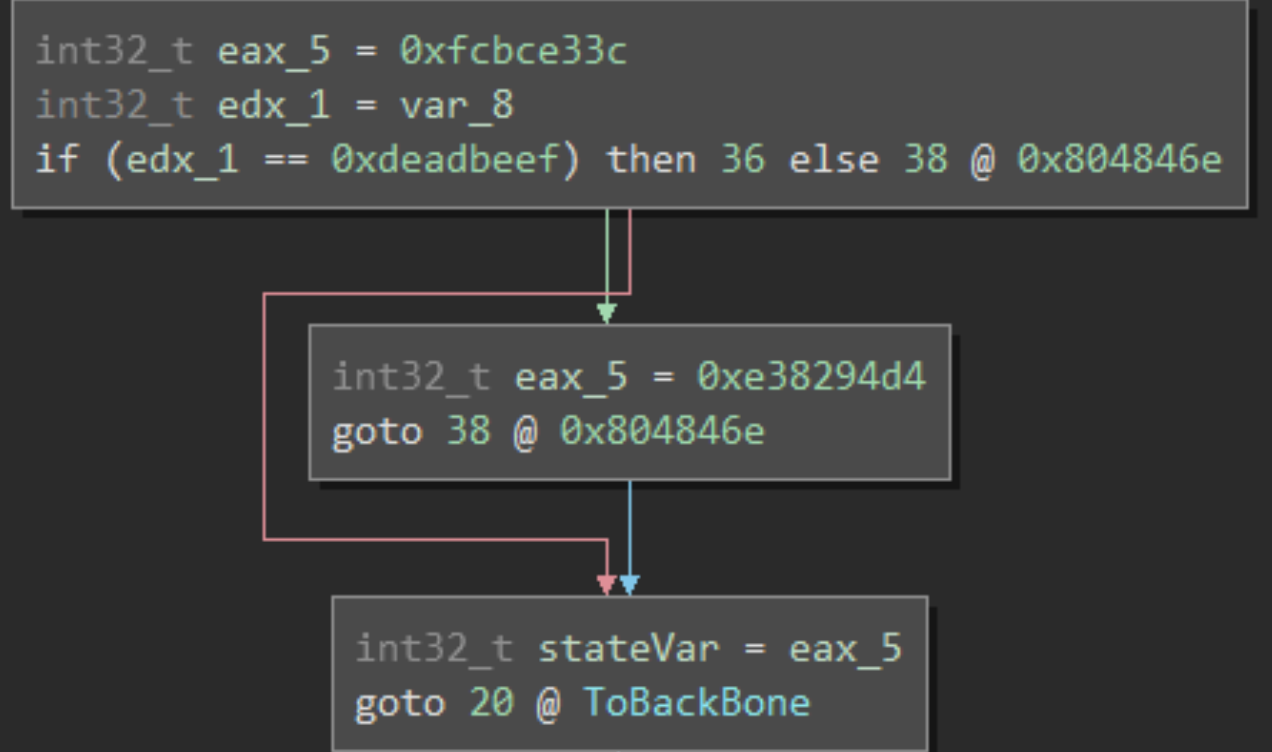
1 | stateVar = var == 0xdeadbeef ? 0xe38294d4 : 0xfcbce33c |
因此,我们可以总结:每个基本块都包含至少一个 stateVar 的定义,类似于程序入口的主干块。乍一看,我们似乎需要在 def-use 图(获取 stateVar 的所有定义)上执行递归的深度优先搜索,但是我们只需获得 stateVar 的最初定义。stateVar 的最初定义来自入口主干块。
(3)恢复 CFG。目前,我们已经有:
1 | 1. 所有的程序基本块。 |
我们还缺少:程序基本块结束时的 stateVar。为了解决这一点,我们可以使用 binart ninja 的 Value-Set Analysis,它可以计算保存在寄存器中的值。
当程序基本块是无条件跳转时,stateVar 是常数。当程序基本块是条件转移时,我们需要确定两个可能的 stateVar 哪个是真分支,哪个是假分支。Binary ninja 的 Value-Set Analysis 能够计算寄存器中的值。如果程序基本块中的 stateVar 是无条件跳转的,那么很容易获得 stateVar 的值。而对于条件跳转来说,我们需要确定 stateVar 的值,就需要 medium-level IL 的 SSA 形式。SSA 形式如下所示:
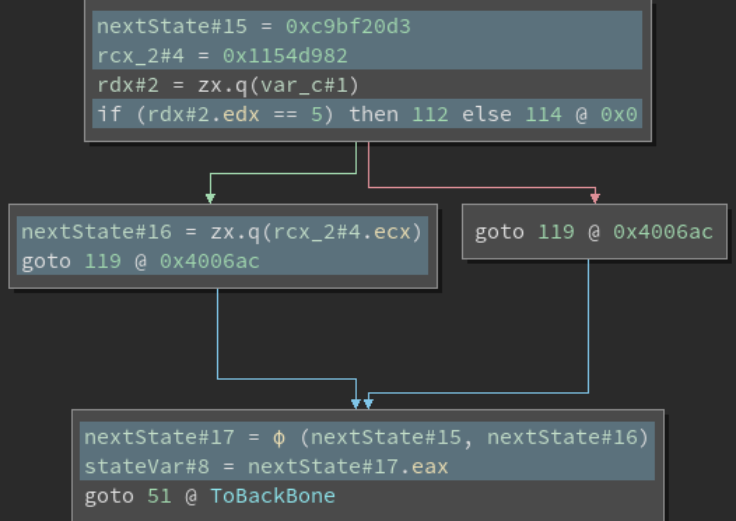
可以看到,最下面的 nextState#17 表示 nextState#17 有两种可能,这就很好的解决了条件跳转的问题。转化成 LLVM IR 的形式,就是:
1 | %next_state = select i1 %original_condition, i32 %true_branch, i32 %false_branch |
我们可以这样构造我们的算法:
1 | 1. 将 nextState 置为 %false_branch。 |
(4)重建 Binaries。我们已经得到了原始的 CFG,之后就是修复这些程序基本块,让他们能够跳转到 CFG 中的下一个正确的程序基本块。
(4)- Step1: 由于在最开始 OLLVM 混淆过的程序中,插入了用于更新 stateVar 的指令,所以我们要移除这些没用的指令,这些没用的指令包括:
1 | 1. 当前 Block 的最后一条指令(跳转到主干块的指令)。 |
如下所示,红色部分是可以删除的指令,也就是加 nop(其中没有 def-use 链中确认 next state 的指令):
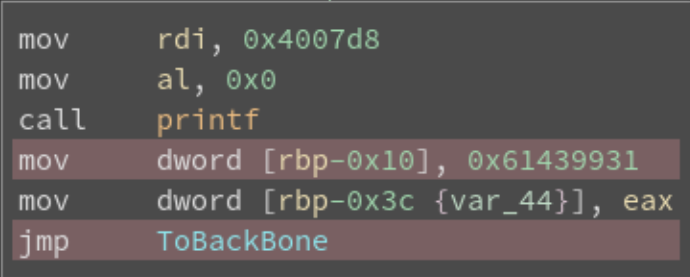
(4)- Step2:修复 Control Flow。对于无条件跳转的块,我们只需要在块最后加入 jmp xxx 即可。对于条件跳转,由于 LLVM 混淆过后的程序中,在 state 附近总有 CMOVXX,我们假设 LLVM 的 flatten 过程总是使用 true branch 覆盖 false branch,如下所示:
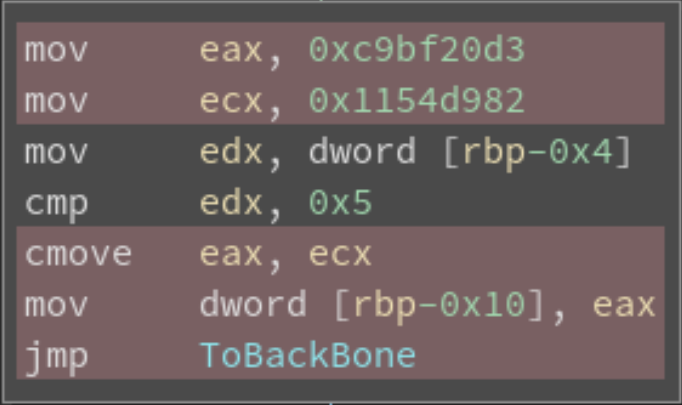
我们可以将指令改为:
1 | cmp edx, 0x5 |
具体算法可以总结为:
1 | 1. 删除所有无用指令。 |
(3)- Step3:在进行完前两步之后,CFG 中的代码无法访问主干块(backbone),我们当然可以使用 nop 来进行替换,但反编译器可以自动帮我们进行线性扫描,不会在流程图中显示。
0x05 符号执行去除 FLA
https://kiprey.github.io/2020/06/LLVM-IR-pass/#%E7%AE%80%E4%BB%8B
符号执行会将程序中变量的值表示为符号值和常量组成的计算表达式,程序输出被表示为输入符号值的函数,其在软件测试和程序验证中发挥着重要作用,并可以应用于程序漏洞的检测。
To be continued…
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!