go-bin-re-study
Go 二进制文件逆向分析
文章链接:https://www.anquanke.com/post/id/214940
最近做到过 Go 的逆向题目,上学期又自学过 Go,所以打算学一下 Go 的逆向分析。
0x00 相关研究
Go 语言靠channel、wait group、select、context 以及 sync 等辅助机制来实现 CSP 并发模型(可以将并发系统分解为独立的进程,从而降低系统的复杂性和耦合性)。
Go 允许为数据类型绑定方法。
Go 语言的编译工具链会全静态链接构建二进制文件,打包标准库函数、runtime(与操作系统底层交互、内存管理)、gc(垃圾回收) 模块等。Go 文件逆向的难点:(1)二进制文件多且复杂;(2)独特的函数调用约定、栈结构和多返回值机制;
Go 内置复杂的数据类型,这些类型在汇编层面比较独特。例如:(1) string 数据不是传统的以 0x00 结尾的 C-String,而是用 (StartAddress, Length)两个元素表示一个 string 数据;(2) slice 数据要由 (StartAddress, Length, Capacity) 三个元素表示。这样在汇编代码中,若一个函数传一个 string 类型的参数,其实要传两个值;若一个函数传一个 slice 类型的参数,其实要传 3 个值。
Go 有独特的栈管理机制。与 C 语言不同,Go 中 callee(被调用函数) 的栈空间由 caller(调用函数) 来维护,callee 的参数、返回值都由 caller 在栈中预留空间,就难以直观看出哪个是参数、哪个是返回值。
恶意软件大都是被 strip 处理过(去除调试信息和函数符号),所以 Go 二进制文件的逆向分析技术的前期主要围绕着函数符号的恢复来展开。方法:(1)为函数符号做 Signature ,然后把 Signature 导入到反汇编工具里;(2)Go 文件中 pclntab 结构中的函数名信息(除 pclntab 之外还有很多),并没有被 strip ,可以通过辅助脚本在反汇编工具里恢复。
1 | 补充:pclntab |
1 | 补充:buildmode=pie |
当前go逆向的插件:IDAGolangHelper、jeb-golang-analyzer、redress。
0x01 相关原理
Q:为什么 Go 二进制文件中会有这么多无法被 strip 掉的符号和类型信息?
A:Go 二进制文件里打包进去了 runtime 和 GC 模块,信息太多了,无法全 strip 完。
Q:Go 文件中有哪些可以辅助逆向分析的信息?
A:如下图所示
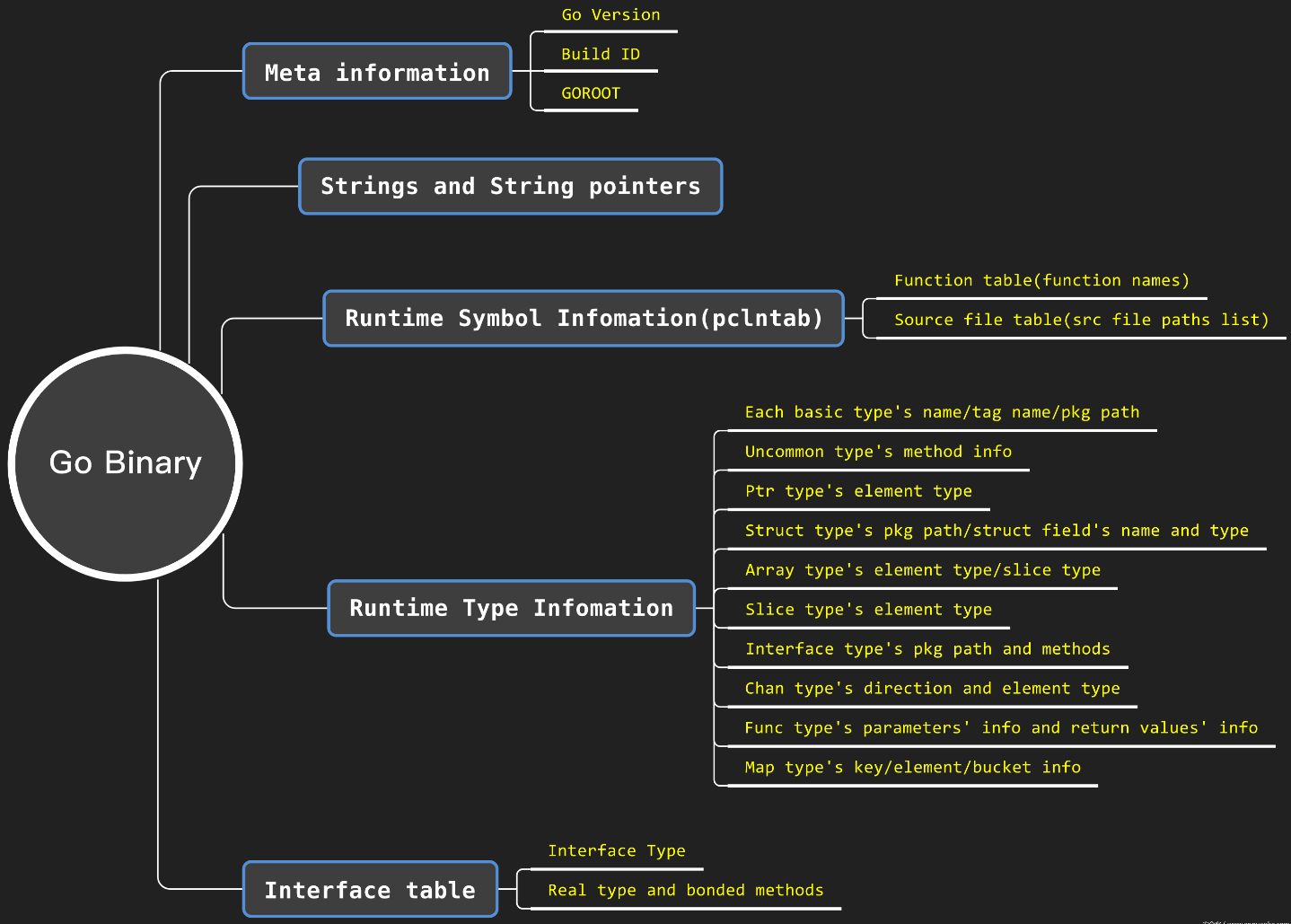
0x02 MetaInfo、函数符号与源码文件路径列表
Go 二进制文件中的元信息:build ID、Go Version、GOROOT、pclntab。
1 | 补充:build ID |
GOROOT存在runtime.GOROOT()函数中。go_parser提取GOROOT的方式为:先在 IDAPro 中先把函数名符号恢复出来,然后根据函数名找到 runtime.GOROOT() 这个函数,最后解析该函数的 FlowChart,找到最后带 return 的 FlowChart(在源码中GOROOT存在 return sys.DefaultGoroot这个语句中),然后再找出该值的地址。
pclntab全名是Program Counter Line Table(程序计数器行数映射表),最初引入该表的动机是Stack Trace。pclntab包括stack trace、栈的动态管理用到的栈帧信息、垃圾回收用到的栈变量的生命周期信息、所有源码文件路径信息。其中,我们重点关注pclntab的函数表(func table) 和源码文件路径列表(source file table)。下面是一个pclntab的例子:
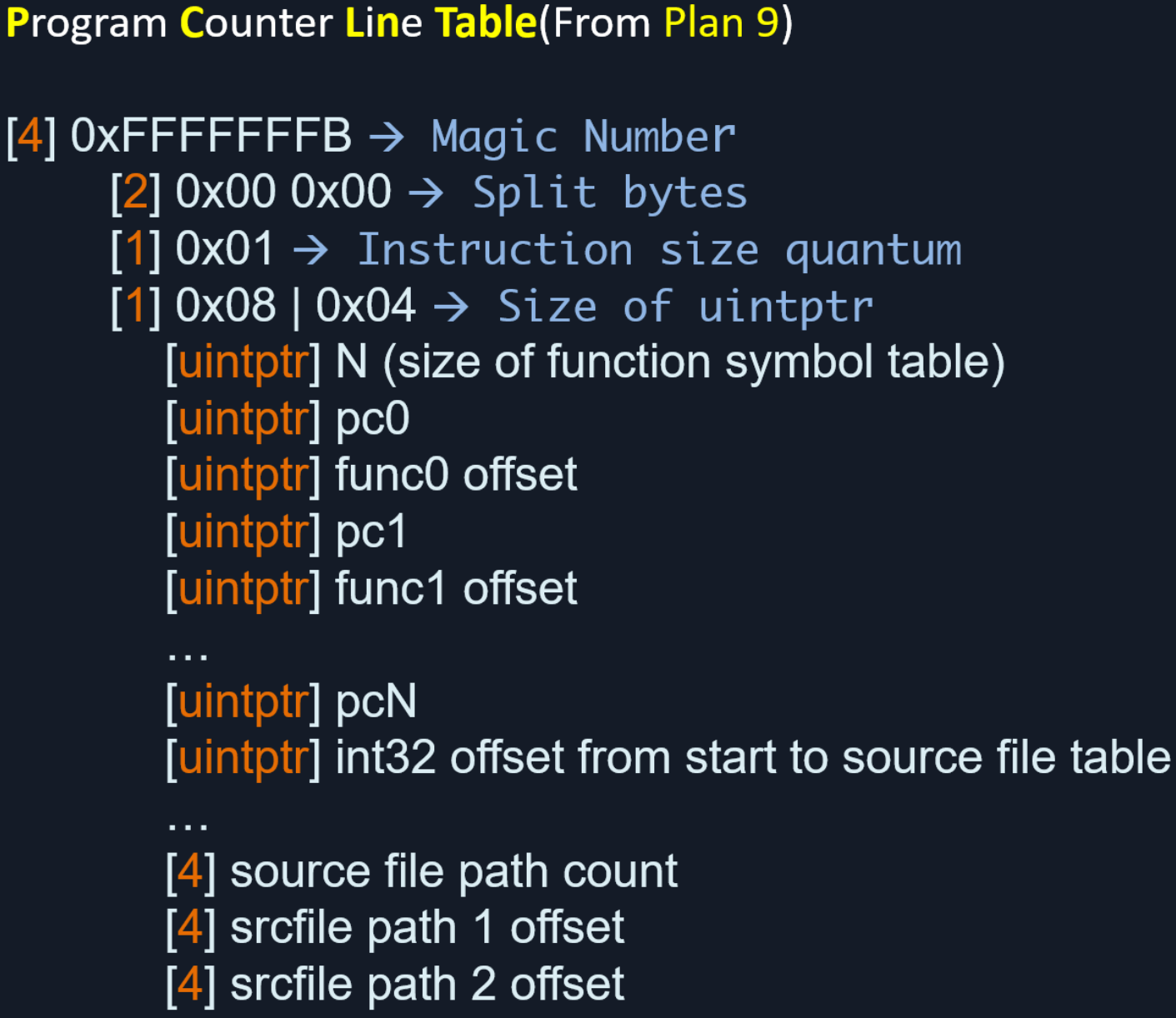
上表的解释如下:
1 | Header: |
Function table
我们可以通过Function table中记录的函数偏移地址+pclntab地址来找到Go文件中的每一个函数。需要说明的是,Function table中记录的函数偏移地址+pclntab地址指向某个函数的Function Struct,其定义如下:
1 | struct Func |
函数名字符串地址=pclntab地址+name中存的偏移地址。理论上讲,遍历Function table,就可以获得所有函数的函数名。但是对于一些特殊函数,上述方法是无法解析的。例如编译器对循环做编译时,会对一些循环进行展开(即不使用cmp;jmp之类的),如下图所示:
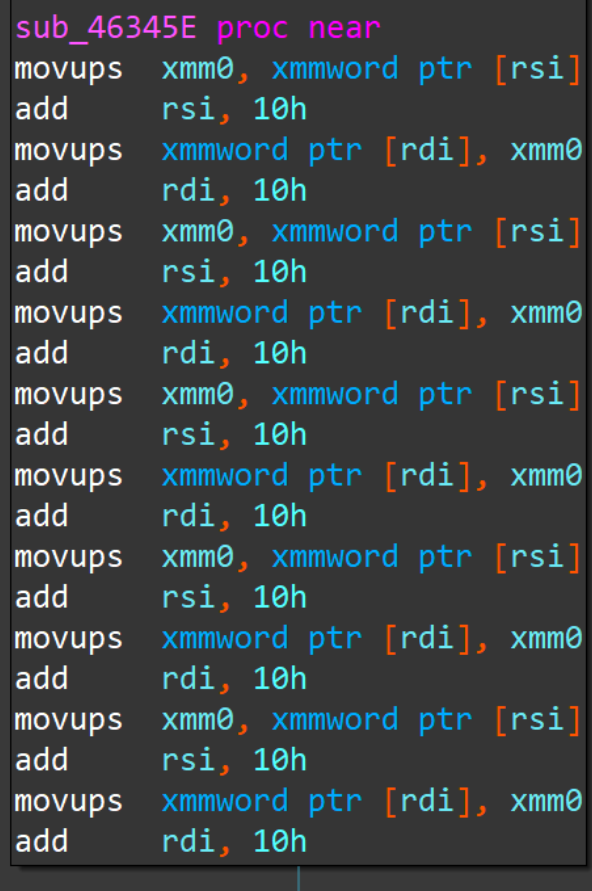
这是一个连续操作内存(拷贝、清零等)的操作。
Source File Table(源码文件表)
在Function table下方,隔着一个uintptr,就是Source File Table的偏移(相对于pclntab起始地址)。
Source File Table 中的元素全都以 4-Bytes(uint32) 为单位,第一个元素是本二进制文件涉及的所有源码文件的个数,包括标准库的源码文件、第三方 Pacakge 的源码文件以及当前项目的源码文件。后续每个 uint32 元素代表一个相对于 pclntab 的偏移量,该偏移量加上 pclntab 的起始地址,即为相应源码文件路径字符串的起始地址。每个源码文件路径名都是以 0x00 结尾的 C-String。
Moduledata
Go 语言中,Module 是比 Package 更高层次的概念,一个 Module 中可以包含多个不同的 Package,而每个 Package 中可以包含多个目录和很多的源码文件。
相应地,Moduledata 在 Go 二进制文件中也是一个更高层次的数据结构,它包含很多其他结构的索引信息,可以看作是 Go 二进制文件中 RTSI(Runtime Symbol Information) 和 RTTI(Runtime Type Information) 的 map。Moduledata 定义如下:
1 | type moduledata struct { |
根据 Moduledata 的定义,Moduledata 是可以串成链表的形式的,而一个完整的可执行 Go 二进制文件中,只有一个 firstmoduledata 包含如上完整的字段。简单介绍一下关键字段:
1 | 第 1 个字段为 pclntab 的地址 |
定位 firstmoduledata
找到 pclntab,由于firstmoduledata第一个字段就是pclntab的地址,因此如果知道pclntab的位置,就可以找到firstmoduledata。
那我们如何定位pclntab呢?
(1)根据二进制文件中的 Section Name 来定位。因为平常见到的 Go 二进制文件, .gopclntab Section 就对应于 pclntab 结构。但是这个方法不靠谱,原因是如果Go文件开启PIE特性,那么这个方法就会失效(就没有.gopclntabSection)。 PIE 全称为 Position Independent Executable,意思是地址无关的可执行文件,这个类型的二进制文件结合 ASLR 技术可以加强 Go 二进制文件自身安全性。
(2)无论是否 PIE ,ELF 文件中的 firstmoduledata 总在 .noptrdata 这个 Section 里,PE 文件中可能会在 .data 或 .noptrdata Section中。可以根据此特征来找。
0x03 数据类型
Go 中的数据类型如下:
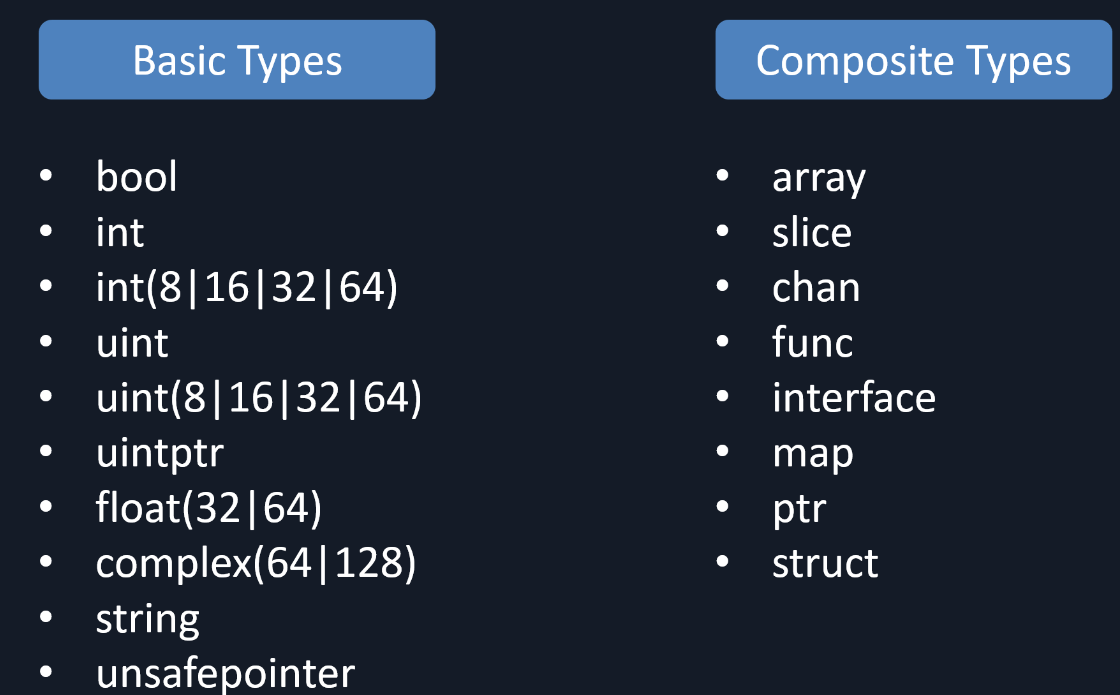
上述类型的具体实现都是基于rtype基本数据类型。如果只是一个没有绑定任何 Method 的 Basic Type ,那么用 rtype 的结构就可以表示。如果一个数据类型绑定了 Methods(这种数据类型也叫 Uncommon Type),或者属于复杂的组合类型(Composite Type),那么就需要用扩展组合的方式来表示了。复杂类型的扩展组合方式可以简单描述为:
1 | rtype + composite type(可选) + uncommon type(可选) |
下面是一个struct结构体数据的例子:
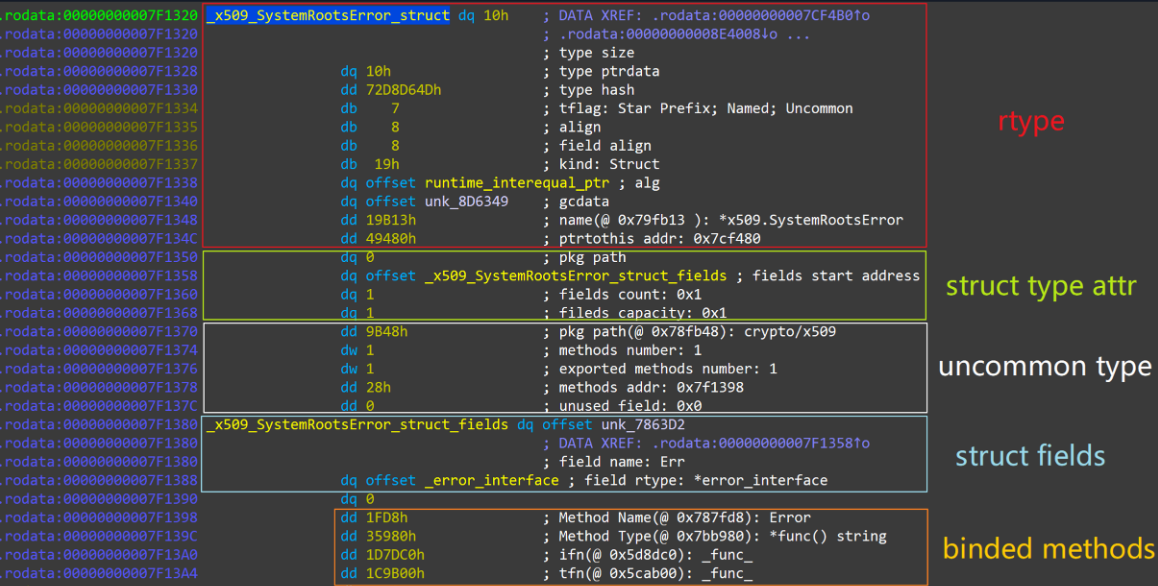
其对应的源码如下所示(反正我是没看出来有什么关系):
1 | // structType represents a struct type. |
rtype解析
之前已经说明了, Go 二进制文件中所有 Type 信息如何组织、存放的。接下来的问题就是,如何解析每一个找到的数据类型定义,从中提取有助于逆向分析的信息。
rtype可以表示最简单的数据类型(Common Basic Types),rtype的定义如下:
1 | type rtype struct { |
tflag可能有3个值:
(1)star prefix:即 name string 以星号 * 开头
(2)named:即该类型是被显示命名的,或者是为标准类型拟了一个别名
(3)Uncommon:该类型有绑定的 Methods
str 是一个 uint32 类型的值,代表一个相对于 firstmoduledata.types 的偏移量,这个偏移量加上 firstmoduledata.types 得出一个地址值,这个地址就是当前 rtype 的 name 信息所在的位置。
composite type解析
Go 中的 Common Basic Types 都可以用上面的 rtype 来表示,如果 rtype.kind 对应于 Composite Types 其中一个,那么完整的类型定义就需要在 rtype 的基础上加上各自独有的字段或者属性才能表示了。
指针类型Ptr
源码定义如下,即在 rtype 后面又附带了一个指向 rtype 的指针(是地址,不是偏移),对这个被指向的 rtype 的解析。
1 | type ptrType struct { |
结构体类型Struct
Go中的结构体可以绑定方法,像类(Class)。源码定义如下:
1 | type structType struct { |
pkgPath 是相对于 firstmoduledata.types 的一个偏移,指向一个 type name 结构。fields 就是 Struct 中的字段定义信息。structField 的定义如下:
1 | type structField struct { |
切片类型Slice
切片可以当作“动态数组”,其源码定义如下。结构类似指针类型,在 rtype 数据后面加上一个指向 element type 的地址
1 | type sliceType struct { |
数组类型Array
源码定义如下:
1 | type arrayType struct { |
接口类型Interface
1 | type interfaceType struct { |
即在 rtype 的数据后面加上了一个 pkgPath 和一组 imethod。pkgPath 是一个指向 type name 结构的地址。imethod就是 Interface 中定义的、必须实现的方法 ,其源码定义如下:
1 | type imethod struct { |
两个成员都是相对于 firstmoduledata.types 的 偏移量,第一个成员 name 即当前 Method 的名字,计算得出的地址,指向一个 type name 结构;第二个 typ 即当前 Method 的类型,其实就是方法的声明信息,计算得出的地址,指向一个 func type 的结构。
方法类型Func
1 | type funcType struct { |
inCount 其实就是参数的个数;outCount 是返回值个数。紧随其后的就是每个参数类型定义的地址、每个返回值类型定义的地址。
Map类型
1 | type mapType struct { |
Map比较复杂,在 rtype 数据后附加了比较多的字段,而其中重要的有 2 个:key 和 elem,就是 key 指向的类型定义数据和 element(value) 的数据类型定义数据。
Chan类型
Chan类型主要是用来在Go协程之间传递消息、同步数据,Chan只能传输一种类型的数据,且有方向(发送or接收)。定义如下:
1 | type chanType struct { |
在 rtype 数据后附加了两个字段:指向一个可发送的数据类型的定义的地址 elem,和一个代表 Channel 方向(单向接收为 1;单向发送为 2,双向收发为 3)。
Uncommon类型
可绑定方法的Uncommon类型,定义如下:
1 | type uncommonType struct { |
任何一个 Type,无论是 Basic Type 还是 Composite Type,都可以是 Uncommon Type。如果一个 Type 的 tflag 字段标记该 Type 是Uncommon Type,那么在该 Type 的所有的字段之后,就是 Uncommon Type 的信息了。 pkgPath的用法与 Interface Type 中的 pkgPath 相同。 mcount是所有绑定的 Methods 的数量。 xcount 是可导出的 Methods 的数量,即 Method name 首字母大写。moff是 Methods 列表到 Uncommon Type 信息起始地址的 偏移。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!