PoisoningAttack-in-Recommender-Systems
Triple Adversarial Learning for Influence based PoisoningAttack in Recommender Systems
最近NLP要进行论文汇报,打算汇报这篇论文。
推荐系统,想必大家都知道,例如我们刷B站时,B站会推送给我们某些令我们感兴趣的内容(养号)。但是推荐系统容易受到中毒攻击,即,在推荐系统中注入一组精心设计的用户档案会严重影响推荐质量。中毒攻击的类型有:Adversarial Attack、Optimization-based Attack、Influence-based Poisoning Attack等。
1 | 1. Adversarial Attack。攻击者改变输入数据,从而使推荐系统的输出结果发生变化(基于统计信息)。例如,攻击者可以修改一些评分或者行为数据,或者添加虚假评分或行为数据,以此来影响推荐系统的结果。 |
本文中的攻击属于Influence-based Poisoning Attack。本文贡献:
1 | 1. 考虑到输入噪声的情况下,通过对生成器、鉴别器和影响模块的三重对抗性学习,生成恶意用户。 |
0x00 背景介绍
推荐系统容易遭受攻击。现有攻击都集中在优化定义的攻击对象(如何更好的攻击推荐系统,达到自己的目的),但是生成的攻击文件(用户行为应该是什么样子的,用户个人资料应该如何定义)很单调,容易被检测到。(虽然Adversarial Attack利用统计信息生成的攻击文件更接近真实用户,但是不知道该咋优化具体模型。)
基于此问题,有很多研究。有研究者利用GAN来生成恶意用户(例如Christakopoulou用DCGAN先生成”真实”用户,然后针对攻击意图对”真实”用户进行改变,此模型最差情况下是传统的基于模型的优化攻击),Lin将Adversarial Attack的损失纳入generator(生成攻击文件的模块),但本质上仍是Adversarial Attack,难以保证攻击性。
本文提出了triple adversarial learning,将jointly attack optimization和GAN联合到一块,来生成有效的攻击文件,且攻击文件的分布近似于真实分布(意味着生成的恶意用户更难检测)。(贡献点1)
1 | 补充:Jointly Attack Optimization。攻击者会优化一个目标函数,该函数同时考虑多个目标,包括推荐系统的准确性和攻击者的目标。攻击者的目标可以是影响特定用户的推荐结果,或者使推荐系统更倾向于推荐某些特定的物品。 |
那我们如何评估攻击文件攻击推荐系统的有效性呢?把攻击文件(也可以理解为恶意的用户数据)和正常文件放一块,然后重新训练推荐系统,然后就可以评估(需要在每个GAN训练时期多次训练推荐系统,计算太麻烦)。受[19]的启发,本文提出了一种近似方法,来来评估攻击对于推荐系统的影响,来避免重复训练。(贡献点2)
最后,此文将影响力建模成影响力模块,并集成GAN,从而生成了基于影响力的三重对抗性学习(与TripleGAN类似)。(贡献点3)
1 | 补充:TripleGAN 是一种推荐系统模型。 |
中毒攻击的相关工作
攻击
1 | 1. Average attack。攻击者向多个物品添加相同的虚假评分。 |
1 | 补充:强化学习。 |
检测/防御
1 | 1. 从评分矩阵中提取特征来检测是否是恶意用户。 |
0x01 问题定义
1 | 补充:升级攻击,降级攻击,可用性攻击。 |
1 | 补充:全知识,部分知识 |
本文基于升级攻击(promotion attacks)、部分知识,并限制攻击者在推荐系统中注入$n$个恶意用户。
1 | 补充:Bi-level Optimization Problem(双层优化问题) |
Bi-level Optimization Problem:
其中,$X$是当前观察到的评级矩阵,$X’$是当前观察到的评级矩阵,$\thetaR$是推荐系统模型的参数,$\mathcal{L}{a t k}\left(X, \theta_R\right)$是目标函数。第二个式子表示假用户和真用户分别计算损失,并调整模型参数使损失最小。此式子可以表示,攻击者要在推荐系统的响应中选择最优的攻击策略(最小的损失),使得推荐结果最大程度地符合自己的目的。
本文基于升级攻击,因此我们希望目标条目出现在尽可能多的用户的top-k推荐列表中,因此可以定义目标函数为:
其中,$\sigma(x)=1 /\left(1+e^{-x}\right)$,$V{i, k}$代表用户$i$的top-k列表,$\hat{r}{i, j}$代表用户$i$对物品$j$的实时评分。若$j$在top-k列表中,且位置很高,那么$\sum{j \in \mathcal{V}{i, k}}-\ln \sigma\left(\hat{r}{i, j}-\hat{r}{i, t}\right)$就很大,最后$\mathcal{L}_{a t k}\left(X, \theta_R\right)$也很大。
由于是双层优化,因此模型需要在中毒后重新训练,因此得到的$\thetaR$只是最优解的近似值。若想得到更精确的值,目前的优化方法主要使用可微目标的梯度或搜索离散数据的邻域。由于$r{i, j}$是离散的,这样就很难找到精确的值,因此我们将$r{i, j} \in\left{0,1, \ldots, r{\max }\right}$变为$r{i, j} \in \left[0, r{\max }\right]$。
0x02 三重对抗性学习
本文提出了三重对抗性学习(TrialAttack),其框架如下图所示:
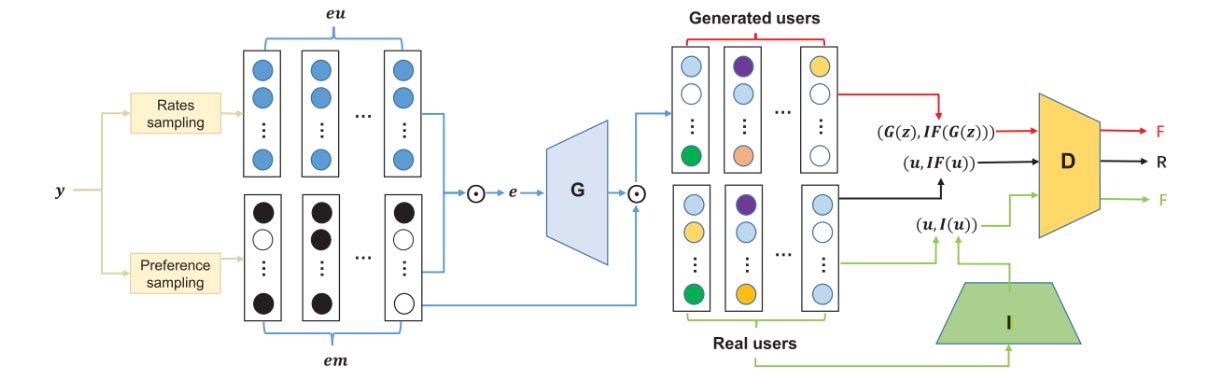
上图中,有生成器$G$,鉴别器$D$,影响模块$I$。
- 生成器。输入噪声$e$,输出攻击文件$u$(此文件很接近真实用户的行为,且对推荐系统造成足够大的影响。),其中$u_i$代表用户对商品$i$的评分。
- 鉴别器。鉴别攻击文件(恶意用户)与正常文件(正常用户)。仅当文件与影响力都是正常时,才会输出
True。计算出的影响为正常,影响模块预测出的影响不正常。 - 影响模块。(1)对产生的用户的破坏力进行评估,引导生成器产生影响尽可能大的用户。(2)影响力可以被视为用户的潜在特征,并用作鉴别器的输入。因此,它旨在使预测的影响显得更正常而不被鉴别器检测到。
上图中,$IF()$代表计算出的影响,而$I()$代表预测出的影响。
影响模块
把攻击文件(也可以理解为恶意的用户数据)和正常文件放一块,然后重新训练推荐系统,然后就可以评估攻击文件对系统的影响。但是数据太多,重新训练是不切实际的,而且我们也不知道正常文件。
对于训练集中的样本$z$,使用$\epsilon$进行加权,那么就会得到:
根据[19],$\epsilon$加权后对测试样本$z_{test}$的影响函数可定义为:
其中,$H{\hat{\theta}}:=\frac{1}{n} \sum{i=1}^n \nabla\theta^2 \mathcal{L}\left(z_i, \hat{\theta}\right)$,这是一个Hessian矩阵。
1 | 补充:Hessian矩阵。二阶偏导数矩阵,它描述了一个多元函数的局部曲率。 |
此外,考虑将小扰动$\delta$添加到样本$z$的场景,对样本$z_{test}$的影响函数可以定义为:
上述式子表示:对样本$z$(训练)进行改变,如何影响测试样本$z_{test}$的预测结果。通过影响函数估计模型振荡可以用作评估攻击效果的有效工具。
对于本文来说,我们想要估计一个从未出现过的恶意用户$z$的影响,因此简单的增加或干扰用户是不可行的。因此我们将毒害用户的操作分解为两个阶段:(1) 选择正常用户$z$并将其添加到数据集中; (2) 干扰添加的用户$z$,使其与假用户$z’$相同。如下图所示:
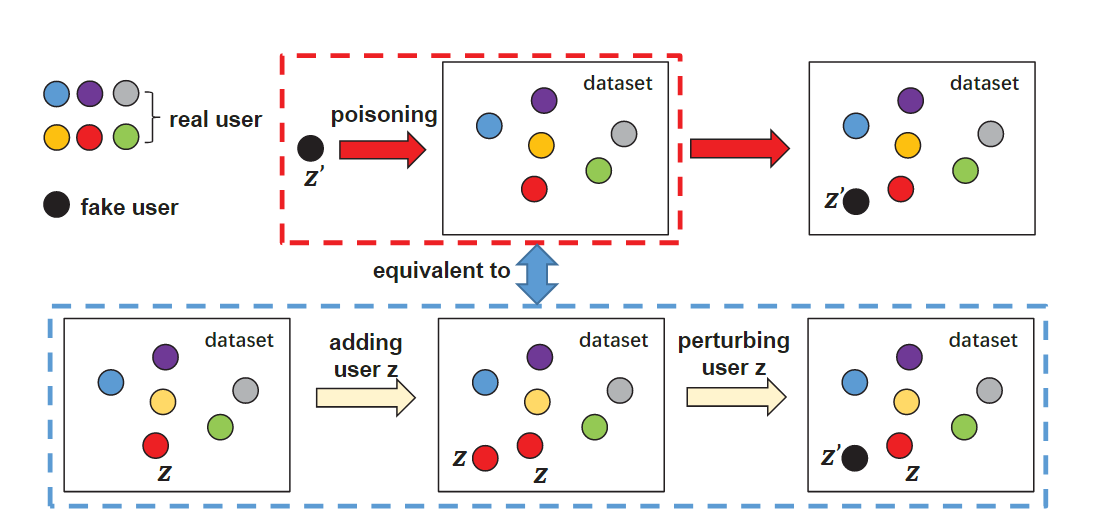
上图表示:将恶意用户 $z’$(黑色节点)中毒到推荐系统相当于首先添加现有的正常用户 $z$(红色节点),然后扰动添加的 $z$,直到它与 $z’$ 相同。因此,添加恶意用户对推荐系统的影响可以看作:
对于一个由$n$用户组成的系统,每个训练用户的权重为$\frac{1}{n}$,因此添加一个现有用户相当于将这个用户的权重提高了$\epsilon \approx \frac{1}{n}$,可以计算影响为:
将新加入的用户$z$变为恶意用户$z’$,相当于进行扰动,扰动大小为:$\delta=z^{\prime}-z$,因此可以计算影响为:
因此,在数据集中添加恶意用户$z’$的总影响为:
但是,[19]中说明了用户$z$与$z’$必须足够相似。因此,对于恶意用户$z’$,要遍历数据集找到一个最相似的$z$,之后计算$\mathcal{I}{\text {poison }}\left(z^{\prime}\right)$。上述式子中,$H{\hat{\theta}_R}^{-1}$是比较难计算的,虽然利用Hessian-vector products (IHVP) 可以进行有效计算,但是复杂度为$O(n m+t p)$。其中,$t$为IHVP的迭代次数,$p=n d+m d$是模型参数的总维度。
1 | 补充:Hessian-vector products (IHVP) |
为了方便计算,我们假设用户$z_{min}$是最接近所有恶意用户的正常用户。
两个命题
在目标为$t$的升级攻击中,设$p(z’)$是恶意用户的分布;有$m$维向量$\mu$,$\mui$代表对物品$i$的评分模式;$e_t$是一个$m$维的向量,$t$维的值为$r{max}$,其他值为0;那么有:
其中,$\Pi(z)$指将$zi$映射到合理的评分。因此,可以计算出$z{min}$,然后我们可以直接训练推荐系统。
为什么进行上述操作?避免计算$\mathcal{L}_{a d d, \operatorname{loss}}(z)$,将时间复杂度变为$O(p)$。最终,恶意用户$z’$的影响为:
设$p(z’)$是恶意用户的分布;$\operatorname{Err}I\left(z^{\prime}, z\right)$是选择$u$时对$z’$的影响误差,那么当$\delta=z^{\prime}-z \rightarrow 0$时,有:$E{z^{\prime} \sim p\left(z^{\prime}\right)}\left(\operatorname{Err}I\left(z^{\prime}, z{\text {min }}\right)\right) \leq E{z^{\prime} \sim p\left(z^{\prime}\right)}\left(\operatorname{Err}_I\left(z^{\prime}, z\right)\right)$。这说明,当扰动最小时,选择$z{min}$的影响估计误差并不比从原始数据集中选择的用户差。
影响模型
基于影响越大,攻击收益越高。利用上述影响公式可以准确衡量用户的影响力,从而为生成器训练提供可靠的保证。在每一轮中,随机选取真实用户$u_I$,并最小化真实影响$IF_I$(利用上述公式计算)与预测影响力$I\left(u_I\right)$之间的差距,公式如下:
并尽力让鉴别器以为输入的影响是真实的,即:
生成器
用户生成不明显且恶意的用户。但有以下挑战:(1)对于大量的项目,要具体了解每个项目的偏好并不容易 [5];(2)因模式崩溃而产生的用户多样性不足[8]。即使假用户具有攻击性,也很容易被发现,因为多样性低 [7,26]。
针对上述挑战,本文提供了一种多样化的噪声采样,生成器的输入噪声$e$,其中$e_i$是给予物品$i$的评分。多样化的噪声采样主要包括评分采样和偏好采样。具体过程如下:
1.使用K-means算法将所有真实用户聚类为不同的组。
2.使用评分采样来生成初始噪声$eu$,其中$eu_i$是从物品$i$的评分分布中采样的。
3.由于用户对不太可能对所有项目进行评分,因此使用偏好采样来选择用户可能对其进行评分的项目。我们生成选择向量$em$,$emi=1$表示选择这个物品并进行评分。具体来说:随机选择组$j$,然后将$\sum_i e m_i$设置为组$j$对物品$i$的评分,那么选择物品$i$的概率为:$p\left(e m_i=1\right)=\frac{\mu{j, i}}{\sumk \mu{j, k}}$,其中$\mu{j, i}$为组$j$中对物品$i$的评分。对于目标$t$而言,$em{t}=1$。
4.我们只关注偏好采样选择的物品,因此最终噪声为$e=e u \odot e m$,$\odot$指的是按元素进行乘法(因此生成的用户也只关心这些偏好物品)。
这种噪声生成的好处:(1)多样化的噪声采样使生成器可以专注于可能被评分的低维物品,从而减轻了学习压力。(没看懂)(2)以通过这样的一系列操作 (例如,聚类) 来保证多样性。
之后,生成用户。生成器需要伪装生成的用户,以便鉴别器将其误认为是真实的:
生成的用户应该是恶意的,因此有:
为了防止由于攻击损失的结合而导致学习分布偏离真实分布,我们将重建损失集成到生成器中。由于输入噪声是从真实分布中采样的,因此重建损失有利于生成近似真实的评分:
鉴别器
鉴别器致力于区分生成的用户和真实用户,以避免被生成器和影响模块欺骗。只有当输入用户和影响力是真实的时,鉴别器才会将其视为真实的。因此,判别器的对抗性损失定义如下:
总结
总结一波,本文的三重对抗性学习可以看作一个3方minimax游戏:
首先,按照如下算法进行训练。之后,采样噪声并生成恶意用户文件,并获取其影响。最后,使用组级别的抽样:(1)根据每个组的用户比例选择一个组;(2)选择该组中最有影响力的用户。重复该过程,直到选择了$n’$个用户。

理论分析
本部分对TrialAttack在非参数假设下的学习能力进行系统的理论分析,证明TrialAttack可以在执行有效攻击的同时近似真实用户。首先,我们考虑一个没有攻击损失的简化试验攻击,即$\beta_1=0$(不知道为啥),然后下面描述生成器和影响模块的学习能力:
引理1
当$\beta_1=0$时,我们可以得到$p(u, I F)=p_G(u, I F)=p_I(u, I F)$,其中$D^*(u, I F)=0.5$。这说明,如果TrialAttack不考虑攻击,则生成器和影响模块都可以学习达到均衡时的真实用户分布。此外,$D^*(u, I F)=0.5$表示判别器很难区分用户影响对是否是真实的。
引理2
对于域$\mathcal{X}$两个分布$P$和$Q$,假设存在一个小的$\epsilon$,使得对于任意$x \in \mathcal{X}$,都有:$|p(x)-q(x)|<\epsilon$,其中$p(x)$是$P$的概率密度,$q(x)$是$Q$的概率密度,那么有:$\left.J S(P \mid Q)\right|_{\epsilon=0}=0$。这说明,对于分布的任何点$x$,如果在另一个分布中总有一个与$x$有小的$\epsilon$邻域的点,则两个分布几乎完全相同。
引理3
略。由引理3可知,当考虑攻击损失时,通过TrialAttack学习的评级分布接近真实的。此外,TrialAttack通过最大化影响力来生成具有特定攻击意图的恶意用户。因此,TrialAttack可以产生恶意但接近现实的中毒配置文件。
0x03 实验
数据集:ML-100K2,ML-1M2和FilmTrust。数据集含有用户、物品以及评分。对于每个数据集,我们从每个用户中随机选择一个正样本,作为测试集;其余的作为训练集和验证集,比例为9:1。
参数设置:将基于MF的推荐系统作为目标模型,潜在因子维度$d$为64,$epoch=1000$,使用Adam优化器,生成器与鉴别器学习率为0.0001,影响模块的学习率为0.001。$\alpha=0.5$,$\beta_2=100$,$\gamma=1$,$T_D=1$,$T_G=2$,$T_I=1$。对于ML-100K2,ML-1M2和FilmTrust,$\beta_1$分别为2000、4000、400,$N$分别为500、2000、500。
攻击之间的比较。TrialAttack,随机攻击 [21],平均攻击 [21],PGA [22],TNA [12],和AUSH [25]。
评价指标。平均命中率($HR@k$)与归一化折扣累积增益($NDCG@k$),$k=10$。
1 | 补充:HR@k与NDCG@k |
全知识攻击
与baseline比较
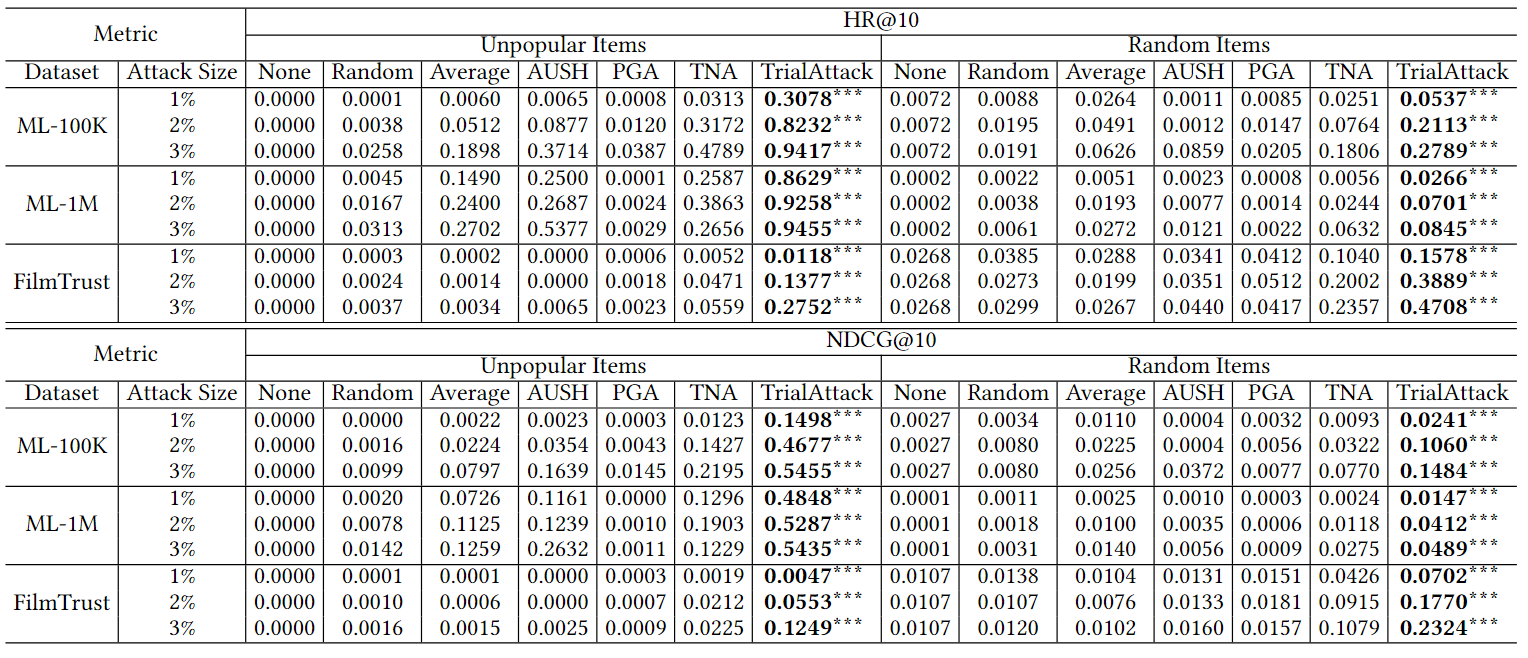
首先,结果表明 TrialAttack 在 HR@10 和 NDCG@10 方面明显优于基线。与TNA 相比,TrialAttack 在攻击随机项目时对 HR@10 的提升超过 33.7%,并且在攻击冷门物品时提升更为显着,提升高达 72.0%。其次,对于同样基于 GAN 的 AUSH,我们观察到其性能与平均攻击和其他先令攻击几乎相同。那是因为它包含了段内损失,这在本质上仍然是一种启发式先令攻击。最后,我们注意到在 ML-1M 和 ML-100K 中,对冷门物品的攻击伤害比随机物品更明显。当攻击规模为 2% 时,超过 80% 的用户被成功攻击。我们怀疑它们比 FilmTrust 更密集且具有相对较少的行为特征,使它们更容易受到攻击。
影响的有效性(影响模块的有效性)
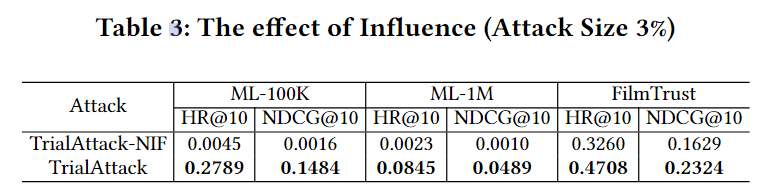
TrialAttack的关键是结合影响力函数来引导生成器产生有影响力的用户。在这一部分中,我们评估了影响函数对攻击性能的影响。设TrialAttack-NIF为无攻击影响损失的攻击,即$\beta_1=0$。下表报告了当攻击大小为3% 时,TrialAttack-NIF与原始TrialAttack攻击随机项目之间的比较。它揭示了利用影响力进行试验攻击的优势是显著的。在ML-100K的最佳情况下,HR@10增加约62倍,而NDCG@10增加92倍。这些结果强调了影响对提高攻击性能的积极影响。
防御模型中的表现
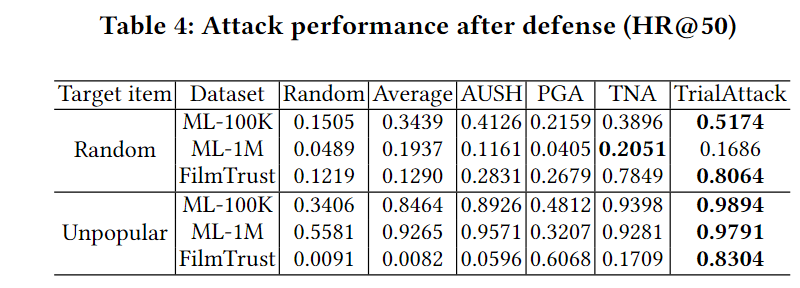
使用了最近研究中最广泛的对抗训练[6,16,31,35]。下表列出了攻击规模为 3% 时对抗性训练后的性能。为了强调防御效果,我们这里使用 HR@50。结果表明,即使配置了防御程序,TrialAttack仍然有效并处于领先地位,显示出TrialAttack强大的破坏性。
部分知识攻击
我们构建了一个本地模拟器,将部分知识攻击转化为全知识攻击,并在本地模拟器上执行TrialAttack和baseline。对于观察到的用户的采样,我们采用操作[12],根据到目标项目的距离选择最近的用户。本地模拟器的维度设置为 128,与目标模型不同。下图将HR@10与仅使用部分用户进行训练时不受欢迎的项目进行了比较。
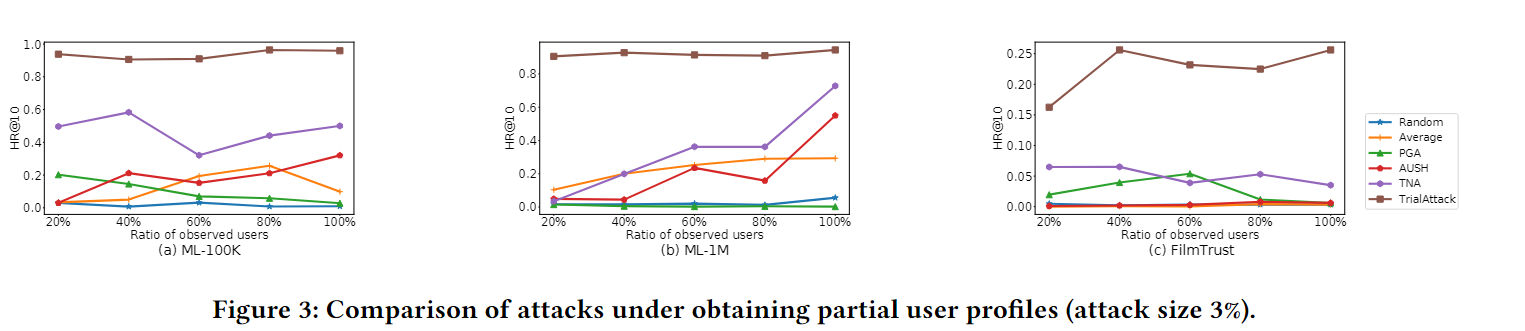
注意到 TrialAttack 仍然有效,知识的缺乏并没有显着降低攻击性能。相比之下,我们发现获得的知识越多,攻击不一定越好(例如,当观察到 60% 的用户评分时,FilmTrust 中的 PGA 实现了最佳性能)。我们怀疑它可以在获得足够知识的前提下,针对部分用户进行高质量的攻击。
还研究了推荐系统维度$d$的攻击敏感性。我们将本地模拟器的维度$d$设置为64,而目标系统使用不同的维度。在不受欢迎的项目下的结果如下图所示,它表明该维度具有最小的影响,并且TrialAttack仍然可以在不同维度上产生高质量的假冒用户。攻击总是有效的优良特性给我们一个警钟,即解决推荐系统的安全问题势在必行。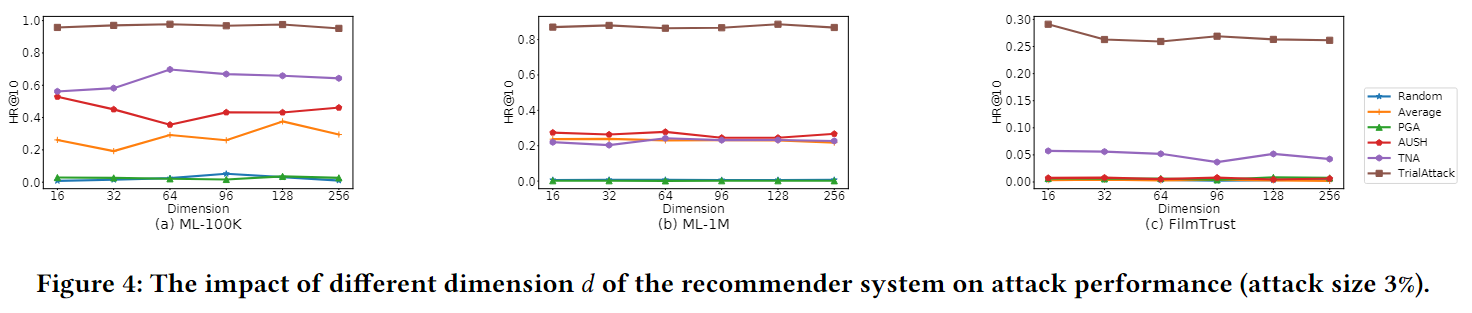
虚假用户检测
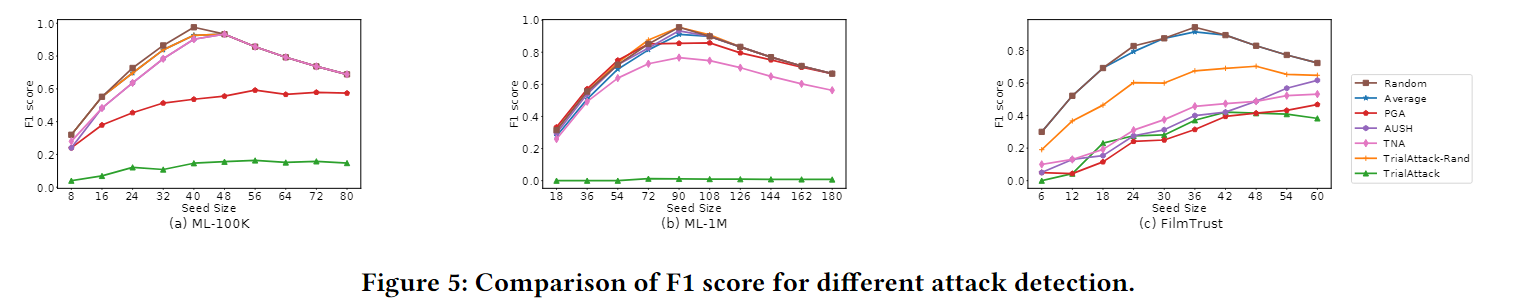
下图展示了在不同参数下检测虚假用户的F1得分。分数越大,检测性能越好。首先,由TrialAttack-Rand生成的大部分用户很容易被检测到,这表明不同的噪声采样在学习真实轮廓方面是有效的。其次,可以看出,在这些数据集中,TrialAttack不容易被察觉。特别是在ML-100K和ML-1M上,假冒用户几乎完全欺骗了检测器,这清楚地验证了TrialAttack在生成不可察觉用户方面的优越性。最后,我们发现对FilmTrust的大多数攻击的检测性能显著下降。
0x04 结论
略。
- 参考链接:
1.https://blog.csdn.net/qq_43532928/article/details/126517165?spm=1001.2014.3001.5501
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!