taint-checking
symbolic-execution & taint-checking
之前,有西电的大佬K0rz3n详细说过符号执行与污点分析,之后,USTC的一个学长Ch3nYe也学习了一波。无独有偶,最近我对这个也比较感兴趣,所以趁机学习一波。由于两位大佬说的很详细了,所以我就按两位大佬的脉络来叙述。
参考链接如下:https://ch3nye.top/%E6%B1%A1%E7%82%B9%E5%88%86%E6%9E%90%E6%8A%80%E6%9C%AF%E7%AC%94%E8%AE%B0/
0x00 符号执行的定义
通俗的说,如果把一个程序比作DOTA英雄,英雄的最终属性值为程序的输出(包括攻击力、防御力、血槽、蓝槽),英雄的武器出装为程序的输入(出A杖还是BKB)。那么符号执行技术的任务就是,给定了一个英雄的最终属性值,分析出该英雄可以通过哪些出装方式达到这种最终属性值效果。因此,符号执行是一种白盒的静态分析技术。即,分析程序可能的输入需要能够获取到程序的源代码。
0x01 静态符号执行
如果把上述英雄的最终属性值替换成程序形成的bug状态(例如数组越界复制的状态),那么,我们就能够利用此技术挖掘漏洞的输入向量了。
给一个源代码如下:
1 | int m=M, n=N, q=Q; |
其相应程序路径图为:
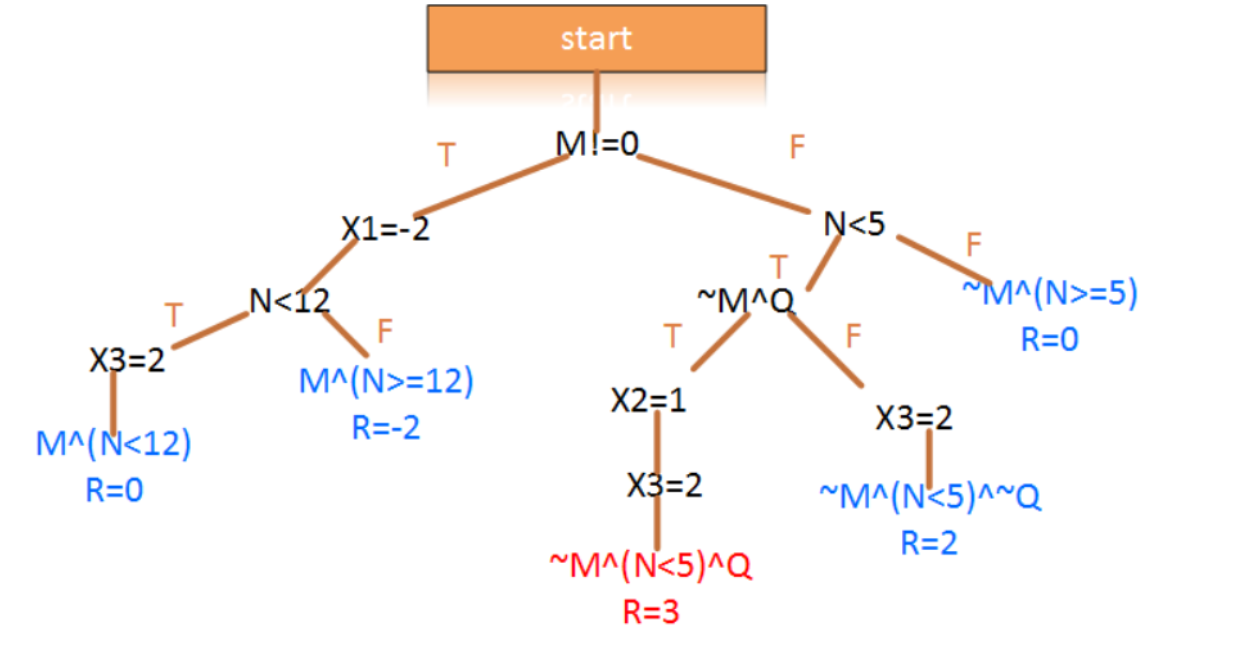
可以看到,当满足~M^(N<5)^Q时,会得到R=3。因此,如果把结果条件更改为漏洞条件,理论上能够进行漏洞挖掘。但是,实际的程序中,可能包含了与外设交互的系统函数,而这些系统函数的输入输出并不会直接赋值到符号中,从而阻断了此类问题的求解。如下代码所示:
1 | int main(int argc, char* argv[]) |
LLVM的KLEE解决了上述问题。它把一系列的与外设有关的系统函数给重写了一下,使得符号数值的传递能够继续下去。例如,上述代码中,fputs("Too many parameters, exit.", fop);可以看成fop="Too many parameters, exit.";而output = fgets(..., fop);可以看成output=fop。这样,就能够把符号数值的传递给续上。
符号执行的关键思想:把输入变为符号值,那么程序计算的输出就是符号输入的函数。简而言之,就是一个程序执行的路径通常是true和false条件的序列,这些条件是在分支语句处产生的。程序的所有执行路径可以表示为树,叫做执行树。如下所示:
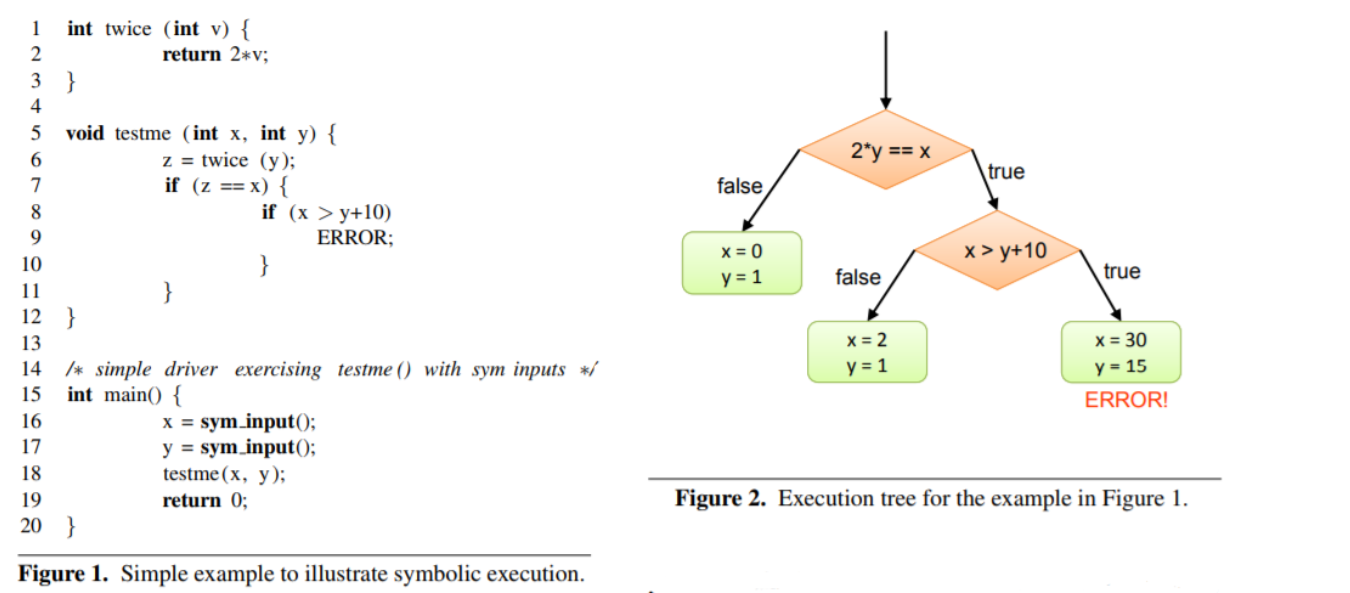
可以看到,只要分别输入x,y=0,1、x,y=2,1、x,y=30,15,就可以遍历这三个路径。符号执行的目标就是:生成这样的输入集合,在给定的时间内探索所有的路径。
符号执行会在全局维护两个变量:(1)符号状态 $\sigma$,表示变量到符号表达式的映射。(2)符号化路径约束PC,用来表示路径条件。
初始时,$\sigma$为空,PC为true。结束时,PC就会用约束求解器进行求解,以生成实际的输入值。这个实际的输入值如果用程序执行,就会走符号执行过程中探索的那条路径,即此时PC的公式所表示的路径。
以上图为例,当读16-17行后,此时$\sigma={x \rightarrow x_0, y \rightarrow y_0}$,其中 $x_0$ 与 $y_0$ 是两个初始的未约束的符号化值。之后执行第6行,执行完后,此时$\sigma={x \rightarrow x_0, y \rightarrow y_0, z \rightarrow 2*y_0}$。之后,运行到第7行,此时PC会同时有两个不同的更新:$PC \cap (x_0 = 2y_0)$与$PC \cap (x_0 != 2y_0)$。在第8行,又更新了不同的PC(如果不等于,程序直接结束,到不了第8行),分别为:
那如果遇到循环与递归呢?如下所示:
1 | void testme_inf() { |
上述代码,有无数条执行路径,每条路径的可能性有两种:要么是任意数量的true加上一个false结尾,要么是无穷多数量的true。其符号化约束PC如下:
其中,每一个$N_i$都是一个新的符号化值,执行结尾的符号状态是:
这就是符号执行面临的问题之一:如何处理循环中的无限多路径。但是,我们可以通过限制搜索时间的长短,限制路径数量等方式来解决。
符号执行还面临一个问题:符号路径约束包含不能由求解器高效求解的公式。如下代码所示:
1 | int twice(int v) { |
将twice函数的代码变成,如上所示。那么路径约束就变为:
这样的话,约束求解器是不能求解这样的约束的,所以符号执行不能产生输入。
上述内容是纯粹的静态符号执行,还有一种动态符号执行(concolic execution)。
0x02 动态符号执行(concolic execution)
有两篇相关论文,分别为DART:Directed Automated Random Testing、CUTE:A concolic unit testing engine for C。
动态符号执行维护一个实际状态(concrete state)和一个符号化状态(symbolic state):实际状态将所有变量映射到实际值,符号状态只映射那些有非实际值的变量。动态符号执行首先用一些给定的或者随机的输入来执行程序,收集执行过程中条件语句对输入的符号化约束,然后使用约束求解器去推理输入的变化,从而将下一次程序的执行导向另一条执行路径。简单地说来,就是在已有实际输入得到的路径上,对分支路径条件进行取反,就可以让执行走向另外一条路径。这个过程会不断地重复,加上系统化或启发式的路径选择算法,直到所有的路径都被探索。以上述例子为例,直接引用ch3nye师傅的原话:

Cristian Cadar对上述动态符号执行做进一步优化,其创新点主要是在实际状态和符号状态之间进行区分,称之为执行生成的测试(Execution-Generated Testing),简称EGT。这个方法在每次运算前检查值是不是实际的,如果是实际的,那么运算就原样执行,否则,如果至少有一个值是符号化的,运算就会通过更新当前路径的条件符号化地进行。
例如,对于我们的例子程序,第17行把y=sym_input()改变成y=10,那么第6行就会用实际参数10去调用函数twice,并实际执行。然后第7行变成if(20==x),符号执行若走then路径,则加入约束x=20;对条件进行取反就可以走else路径,约束是x≠20。在then路径上,第8行变成if(x>20),那么该if的then路径就不能走了,因为此时有约束x=20。可以看到,这种方式减少了路径遍历。
动态符号执行可以解决静态符号执行的很多问题。求解器无法求解的部分,用实际值替换就好了。但是,有丢失路径的缺陷。举一个例子来说明:假设执行从随机输入{x=22, y=7}开始,if(x==z)条件取反生成路径约束$x_0 \neq\left(y_0 y_0\right)~ \bmod ~50$。因为约束求解器无法求解非线性约束,所以动态符号执行的应对方法是,把符号值用实际值替换,此处会把$y_0$的值替换为7,这就将程序约束简化为$x_0 \neq 49$ 。通过求解这个约束,可以得到输入{x=49, y=7},走到一个此前没有走到的路径。传统静态符号执行是无法做到这一步的。但是,在这个例子中,我们无法生成路径true-false的输入,即约束
又因为$y_0$的值已经实际化了,这就造成了丢失路径的问题,造成不完全性。
0x03 问题&解决方案
路径爆炸
问题定义:每一个条件分支都会产生两个不同约束,符号执行要探索的执行路径依分支数指数增长。
解决方法:通过路径选择的方法缓解指数爆炸问题。(1)启发式搜索,目的是先探索最值得探索的路径,最简单的启发式就是随机搜索;(2)可靠的程序分析技术减少路径探索的复杂性,例如剪枝冗余路径,如果程序路径与此前探索过的路径在同样符号约束的情况下到达相同的程序点,那么这条路径就会从该点继续执行,所以可以被丢弃。
约束求解
问题定义:符号执行所需的约束求解能力超出了当前约束求解器的能力。
解决方法:
(1)不相关约束消除。例如当前路径条件是:
我们想对$z>0$探索新路径,于是有:
由于$\wedge(y<12)$与z没关系,所以约束可以直接写成:
(2)增量求解。本质上是重用的思想。缓存在经历过一个路径后,会将路径与相应的输入保存起来,例如:
表示输入${x=6, y=3} $,其程序执行路径为$ (x+y<10) \wedge(x>5) $。那么,如果程序又遇到一个路径约束,如下:
那么求解器就会迅速检查${x=6, y=3} $,发现这是一个正确的答案。
内存建模
程序语句转换为符号约束的精度对符号执行能实现的覆盖率以及约束求解的可伸缩性有很大影响。例如,使用数学整数(actual mathematical integers)去近似去代替固定宽度的整数变量,这样的内存模型可能会更有效率,但另一方面,根据诸如算术溢出之类的极端情况,可能导致代码分析不精确,这可能会导致符号执行遗漏路径或探索不可行的路径。
0x04 总结
符号执行技术可以用于测试例的自动生成,也可以用于源代码安全性的检测。前几天学习的Angr,就是其中的一种工具。
0x05 污点分析原理
污点分析可以抽象成一个三元组<sources,sinks,sanitizers>的形式。
1 | 1. source:污点源,代表不受信任的数据(恶意代码)进入到系统中 |
污点分析:分析程序中由污点源引入的数据是否能够不经无害处理,直接传播到汇聚点。如果不能,则系统是安全的,否则系统不安全。
在漏洞分析中,使用污点分析将外部数据标记为污点数据,并分析它们是否会影响关键的程序操作,进而挖掘程序漏洞,即将程序是否存在某种漏洞的问题转化为污点信息是否会被 Sink 点上的操作所使用的问题。
污点分析的过程如下:
1 | 1. 定位source与sink |

定位source与sink与要检测的系统、关注的漏洞类型等有关系。大体的定位方法有3类:(1)启发式策略,例如来自程序外部输入的数据统称为污点数据;(2)手工标记,根据程序调用的API或数据类型;(3)统计或机器学习的方法。
对于污点传播而言,分为显示流分析与隐式流分析。
显示流分析就是分析标记的污点数据如何跟随程序中变量之间的数据依赖关系传播。如下图所示:

隐式流分析就是分析标记的污点数据如何跟随程序中变量之间的控制依赖关系传播,如下图的虚线所示:

欠污染:由于对隐式流污点传播处理不当,导致本应被标记的变量没有被标记。相应的还有过污染。
无害处理:将污点数据清洁化,例如加密、输入验证(ScriptGard,CSAS,XSS Auditor,Bek)。
使用污点分析检测程序漏洞的工作原理:(基于数据流的污点分析可以看作显式分析,基于依赖关系的污点分析可以看作隐式分析)
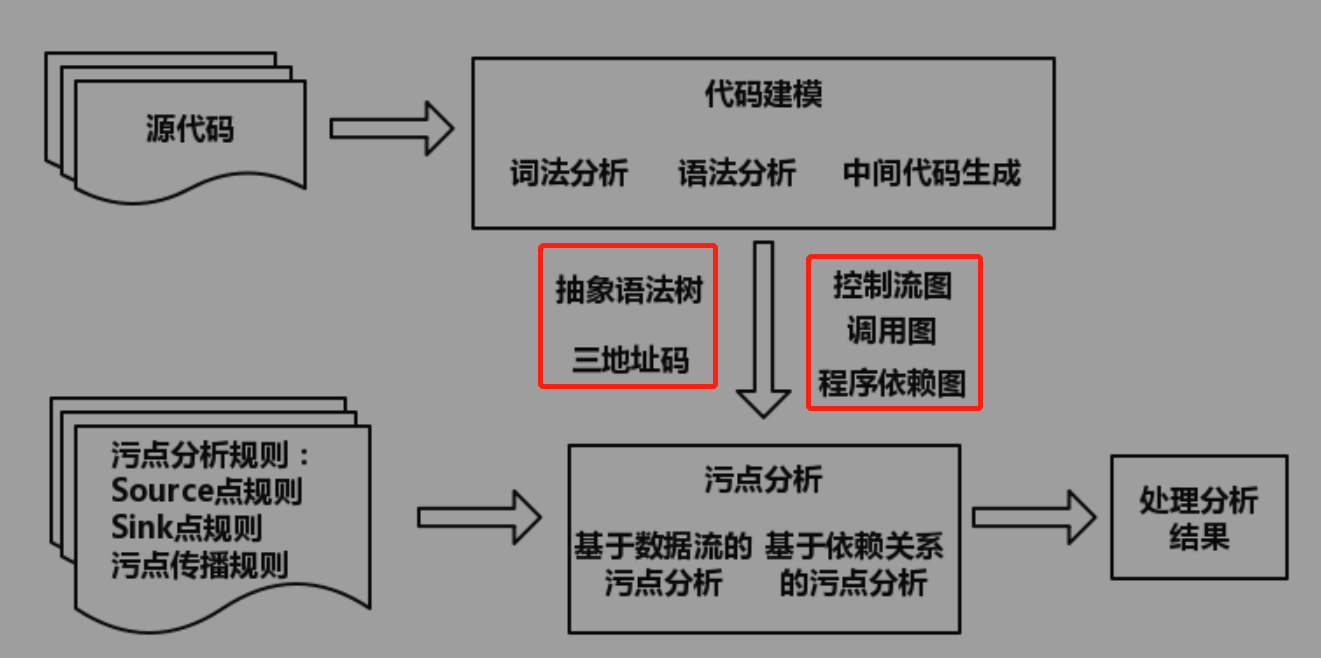
0x06 如何利用动/静态分析来解决污点传播中的显示流/隐式流传播问题
显示流分析
静态污点分析:不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从污点源传播到污点汇聚点。步骤:(1)创建函数调用关系图(CG);(2)进行传播分析(直接赋值、函数/过程调用传播、别名/指针传播);如下图所示:

上述静态分析已经非常成熟,现今研究的重点是如何为别名传播的分析提供更精确、高效的解决方案。
动态污点分析:为污点数据扩展一个污点标记(tainted tag)的标签并将其存储在存储单元中,然后根据指令类型和指令操作数设计相应的传播逻辑,传播污点标记。种类有:(1)基于硬件。需要在寄存器上扩展标记位,用来存储污点标记。(2)基于软件。使用插桩等,会带来巨大开销。(3)混合。
隐式流分析
静态污点分析:精度与效率不可兼得。
动态污点分析面临的问题:
(1)如何确定污点控制条件下需要标记的语句范围,现在的研究大多采用离线的静态分析辅助判断动态污点传播中的隐式流标记范围。例如下图,当document.cookie == "abc"被确定为污点源时,第4行与第6行都会被标记。

(2)如何选择合适的污点标记分支进行污点传播?例如(1)中都标记的话,可能会出现过污染的情况。
0x07 污点分析方法的实现
静态污点分析示例:
下面是一个存在SQL注入漏洞ASP程序的例子:
1 | <% |
上述ASP的解释:
- 定义了三个变量pwd、sql1、sql2,分别用于存储密码、查询语句1和查询语句2。
- 调用MySqlStuff函数,该函数接收三个参数password、cmd1和cmd2,分别表示数据库密码、查询语句1和查询语句2。
- 在MySqlStuff函数中,首先创建了一个ADODB.Connection对象conn,并设置了其提供程序为”Microsoft.Jet.OLEDB.4.0”。
- 使用conn.Open方法打开了一个名为”c:/webdata/foo.mdb”的Access数据库,其中用户名为”foo”,密码为password。
- 调用conn.Execute方法执行了查询语句2,并将结果存储到rs对象中。
- 创建了一个ADODB.Recordset对象rs,并使用rs.Open方法执行查询语句1,并将结果存储到rs对象中。
将上述代码表示为一种三地址码的形式,例如第 3 行可以表示为:
1 | a = "SELECT companyname FROM " |
控制流分析如下:
- 调用 Request.Cookies(“hello”) 的返回结果是污染的,所以变量 sql1 也是污染的(外部输入的)
- 调用 Request.QueryString(“foo”) 的返回结果 sql2 是污染的(外部输入的)
- 函数 MySqlStuff 被调用,它的参数 sql1,sql2 都是污染的。分析函数的处理过程,根据第 6 行函数的声明,标记其参数 cmd1、cmd2 是污染的
- 第 10 行是程序的 Sink 点,函数 conn.Execute 执行 SQL 操作,其参数 cmd2 是污染的,进而发现污染数据从 Source 点传播到 Sink 点。因此,认为程序存在 SQL 注入漏洞
动态污点分析示例:
1.污点数据标记:网络输入、文件输入、输入设备输入
2.污点动态跟踪:一般基于以下 2 种机制,(1)动态代码插桩:通过在被分析程序中插入分析代码,跟踪污点信息流在进程中的流动方向。(2)虚拟机:在虚拟机中增加分析污点信息流的功能,跟踪污点数据的流动。
污点动态跟踪需要影子内存(shadow memory)来映射实际内存的污染情况,从而记录内存区域和寄存器是否是被污染的。影子内存是一个与程序内存大小相同的二进制位数组。每个二进制位对应程序内存中的一个字节,如果该字节被污染,则对应的二进制位被标记为1,否则标记为0。
3.污点误用检查:检测污点数据是否有非法使用的情况
1 | void fun(char *str) |
程序接受外部字符串并调用fun的 2 进制代码如下:
1 | 0x08048609 <+51>: lea eax,[ebp-0x2a] |
程序调用strncpy的 2 进制代码如下:
1 | 0x080485a1 <+59>: push DWORD PTR [ebp-0x2c] |
在扫描该程序的二进制代码时,能够扫描到 call <gets@plt>,该函数会读入外部输入,即程序的攻击面。确定了攻击面后,我们将分析污染源数据并进行标记,即将 [ebp-0x2a] 数组(即源程序中的source)标记为污点数据。程序继续执行,该污染标记会随着该值的传播而一直传递。在进入 fun() 函数时,该污染标记通过形参实参的映射传递到参数 str 上。然后运行到 Sink 点函数 strncpy()。该函数的第2个参数即 str 和 第3个参数 strlen(str) 都是污点数据。最后在执行 strncpy() 函数时,若设定了相应的漏洞规则(目标数组小于源数组),将检测出缓冲区溢出漏洞.
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!