emotion-analysis
情感分析-二分类
0x00 背景
任务数据集是
NLPCC14-SC,训练集:测试集=10000:2500。NVIDIA Tesla T4相当于NVIDIA GTX 750。transformers库是一个用于自然语言处理(NLP)的 Python 第三方库,它提供了数千个预训练的模型,可以用于不同模态(如文本、图像、音频等)的任务。transformers库支持PyTorch深度学习框架,并且可以在它们之间无缝切换,transformers库还提供了简单的API和工具,可以快速下载和使用预训练的模型。from google.colab import drive的含义,这段代码的作用是从google.colab模块中导入drive对象,用于在colab虚拟机中挂载Google Drive云盘文件,以便访问云盘中的数据和代码。
0x01 Transformer与BERT
补充:
- 自回归(Auto-regressive,AR)是一种常用于时间序列分析的方法。它通过对变量自身的历史值进行回归来预测未来的值。
- Minibatch是指一种训练方法,它将整个数据集分成若干个较小的批次(minibatch),每次训练时只使用一个批次的数据进行梯度下降。这种方法可以加快训练速度,并且可以通过调整批次大小和学习率来优化模型性能。
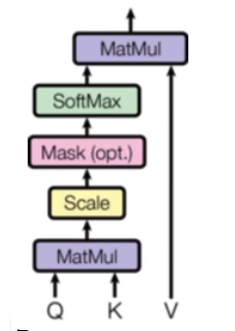
- 注意力机制可以被描述为将一个查询(Query)和一组键-值对(Key-Value)映射到一个输出,其中查询、键、值和输出都是向量。输出计算为值(Value)的加权和,其中分配给每个值的权重由查询与相应键的相似度来计算。
- BatchNorm与LayerNorm。BatchNorm是对一个batch中所有样本的同一维度特征进行归一化。而LayerNorm是对单个样本的所有维度特征进行归一化。BN一般使用在CV中,LN一般使用在NLP中,具体机理也不是特别清楚。
- 预训练。指的是使用大量数据对深度学习模型进行预先训练,以执行特定任务(例如,识别图片中的分类问题)。预训练的目的是从大量数据中提取出尽可能多的共性特征,从而能让模型对特定任务的学习负担变轻。
- 为什么注意力机制的计算开销与输入序列长度的平方成正比?这是因为注意力机制需要计算每个输入元素与其他所有输入元素之间的关系(相当于一个自相关函数),因此计算量与输入序列长度的平方成正比。
语言模型概念
AutoRegressive语言模型:指的是依据前面(或后面)出现的单词来预测当前时刻的单词,代表有 ELMo, GPT等,优点是能够编故事,但只能利用单向语义。
AutoEncoder语言模型:通过上下文信息来预测被mask的单词(让语言模型可以试图去还原其原始输入的系统),代表有 BERT 。
AutoEncoder&Denoising AutoEncoder(DAE)
AutoEncoder不需要标签,本质上是对数据的重构,但是当神经网络的参数复杂到一定程度时,AutoEncoder很容易存在过拟合的风险。为了缓解AutoEncoder过拟合的问题,一个办法是在输入中加入随机噪声,即DAE(Denoising AutoEncoder)。使用破损数据来训练,破损数据一定程度上减轻了训练数据与测试数据的代沟。由于数据的部分被擦掉了,因而这破损数据一定程度上比较接近测试数据。
DAE与BERT模型的关系
- BERT模型是基于Transformer Encoder来构建的一种模型,BERT模型基于DAE(Denoising AutoEncoder)的,这部分在BERT中被称为Masked Language Model (MLM)。
- MLM并不是严格意义上的语言模型,它仅仅是训练语言模型的一种方式。BERT随机把一些单词通过MASK标签来代替,并接着去预测被MASK的这个单词,过程其实就是DAE的过程。
Seq2Seq
Seq2seq模型,通常架构是:Encoder+Attention(建立关联性)+Decoder,可以使用CNN(卷积神经网络)、RNN、Transformer来做。
CNN的特点有:(1)权重共享(平移不变性、可并行计算)。(2)滑动窗口(局部关联性建模)(3)对相对位置敏感,对绝对位置不敏感。每一层卷积只对局部范围建模,使用多层卷积,就可以进行长程建模。
RNN依次有序的进行递归建模,其特点有:(1)对顺序敏感。(2)串行计算耗时(可以通过堆RNN的深度来改善)。(3)长程建模能力弱。(4)对相对位置敏感,对绝对位置也敏感。
Transformer的特点:(1)无局部假设(CNN),即没有局部建模这一说,因此对相对位置不敏感,且可以并行计算。(2)无有序假设(RNN),对绝对位置不敏感,需要增加位置编码来反映位置变化对特征的影响。(3)任意两个字符都可以建模(邻近or离得远),擅长长短程建模,需要自注意力机制(复杂度比较高,为序列的平方)。
Transformer
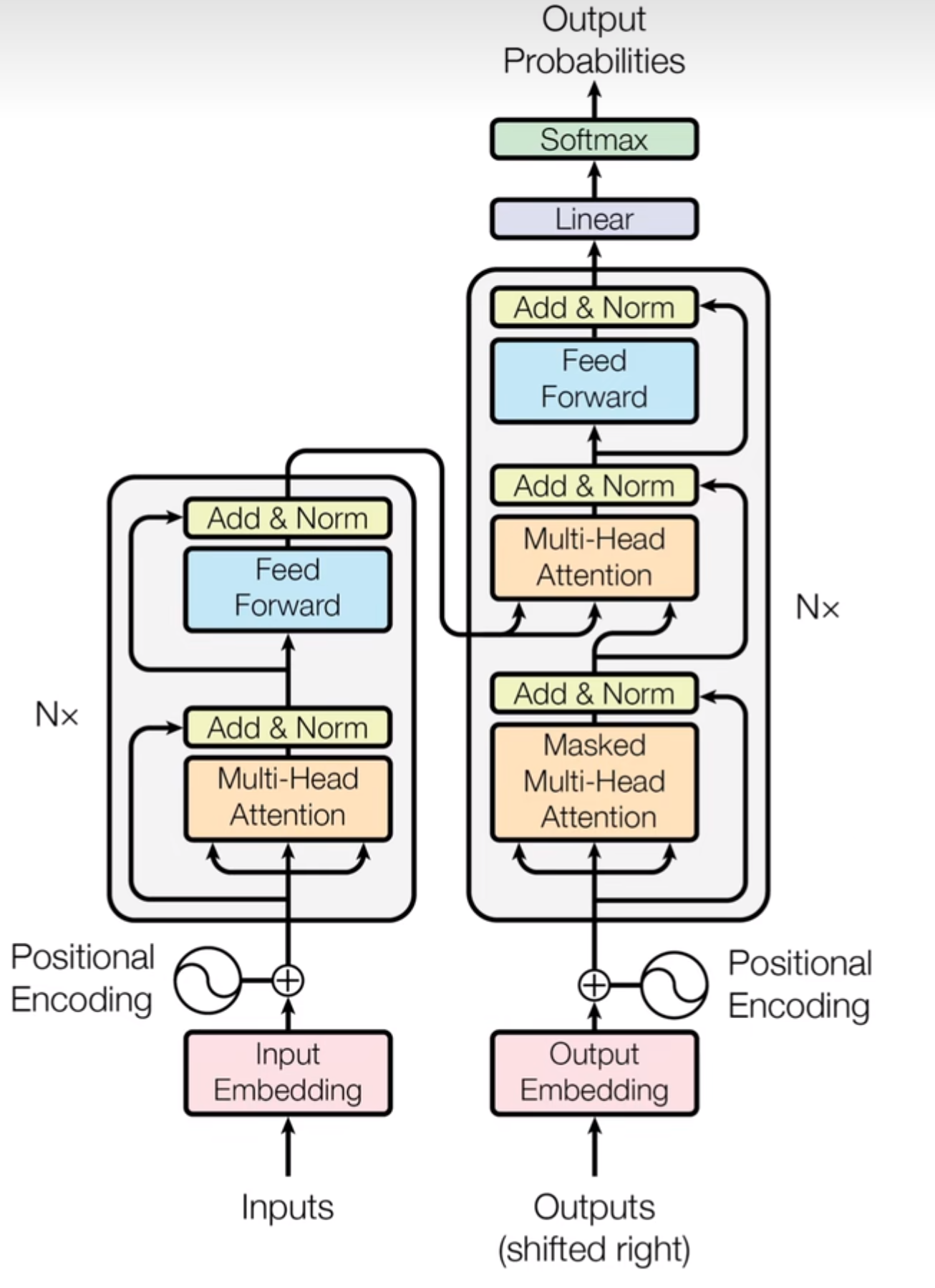
下面详细叙述该Transformer结构图。左边是Encoder部分,右边是Decoder部分。Encoder的输入是某个字符,输出是内部状态向量;Decoder的输入是上一时刻的字符与Encoder的内部状态向量,输出是字符的预测概率。
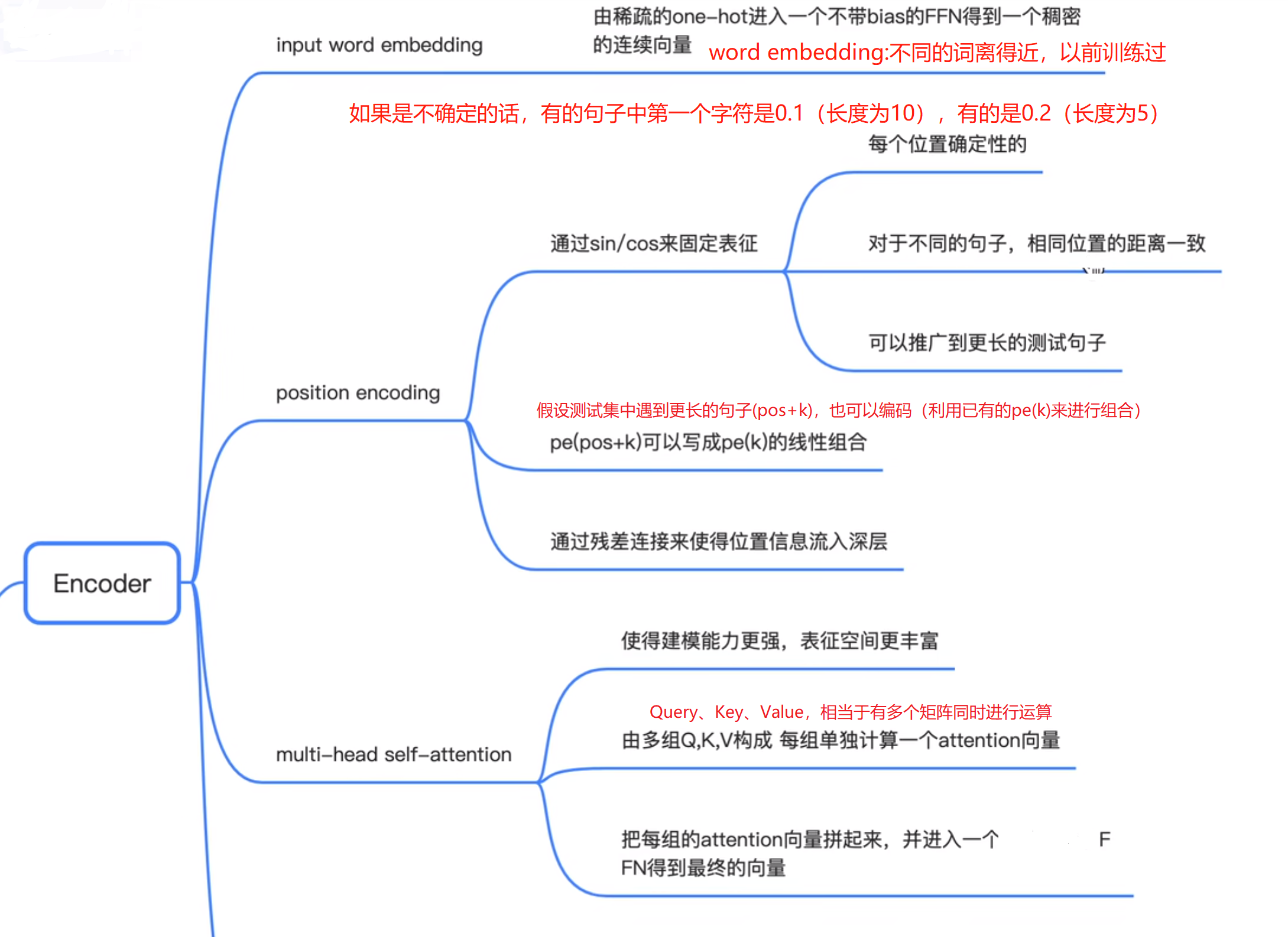
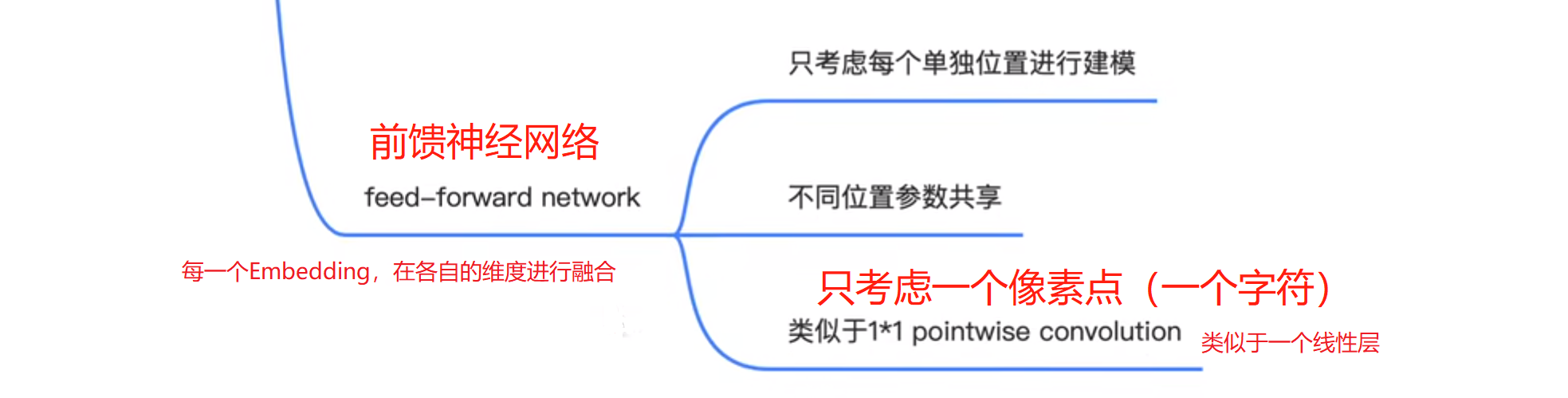

BERT
BERT的全称是Bidirectional Encoder Representation from Transformers,模型是基于Transformer中的Encoder并加上双向的结构。BERT模型的主要创新点都在pre-train方法上,即用了Masked Language Model和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation(表示)。
Masked Language Model指的是训练BERT的时候,随机把语料库中15%的单词做Mask操作。对于这15%的单词做Mask操作分为三种情况:80%的单词直接用[Mask]替换、10%的单词直接替换成另一个新的单词、10%的单词保持不变。
由于BERT可能做Question Answering (QA:问题回答) 和 Natural Language Inference (NLI:翻译)之类的任务,因此增加了Next Sentence Prediction预训练任务,目的是让模型理解两个句子之间的联系。

BERT的作用:(1)情感分类(2)意图识别(3)问答匹配
0x02 基于BERT的文本分类
引用1:https://www.ylkz.life/deeplearning/p10979382/
引用2:https://cloud.tencent.com/developer/article/2136055
PS:月来客栈写的教程是真的好,很注重细节。
已知,BERT是一个强大的预训练模型,它可以基于谷歌发布的预训练参数在各个下游任务中进行微调。因此,在本篇文章中,掌柜将会介绍第一个下游微调场景,即如何在文本分类场景中基于BERT预训练模型进行微调。总的来说,基于BERT的文本分类模型就是在原始的BERT模型后再加上一个分类层即可。数据的分类层处理过程如下:
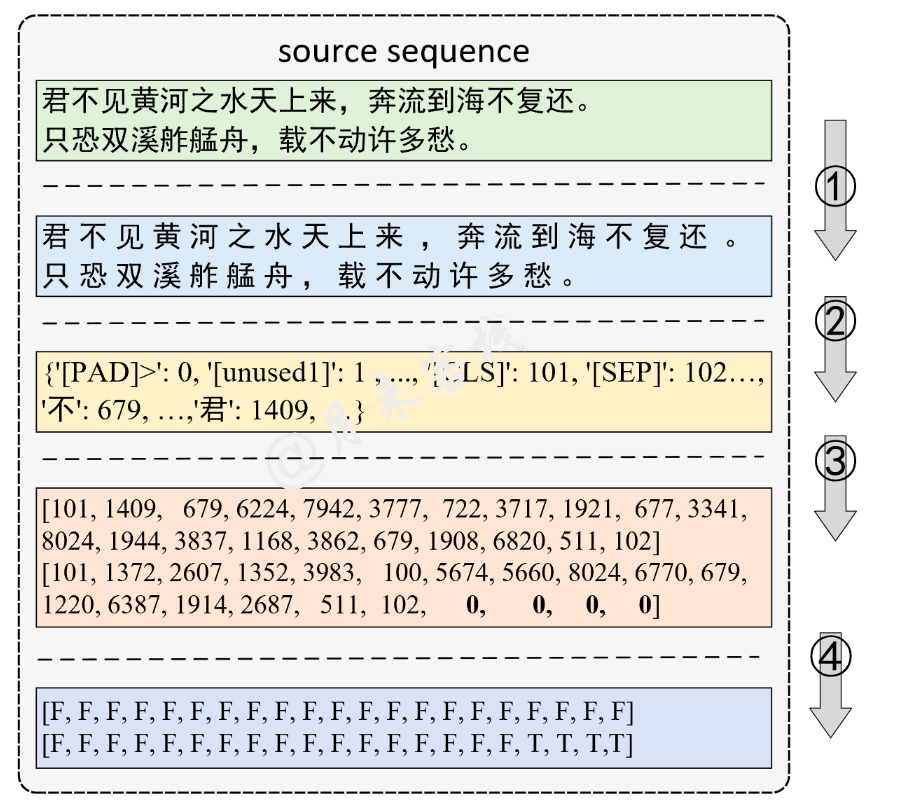
(1)需要将原始的数据样本进行分字(tokenize)处理;
(2)根据tokenize后的结果构造一个字典,不过在使用BERT预训练时并不需要我们自己来构造这个字典,直接载入谷歌开源的vocab.txt文件构造字典即可,因为只有vocab.txt中每个字的索引顺序才与开源模型中每个字的Embedding向量一一对应。
(3)根据字典将tokenize后的文本序列转换为Token序列,同时在Token序列的首尾分别加上[CLS]和[SEP]符号,并进行Padding。
(4)根据第3步处理后的结果生成对应的Padding Mask向量。
(5)最后,在模型训练时只需要将第3步和第4步处理后的结果一起喂给模型即可。
0x03 K折交叉验证
holdout 方法
holdout方法是将原始训练集分为三部分:训练集、验证集和测试集。训练集用于训练不同参数的模型,验证集用于模型选择。而测试集由于在训练模型和模型选择这两步都没有用到,对于模型来说是未知数据,因此可以用于评估模型的泛化能力。下图展示了holdout方法的步骤:
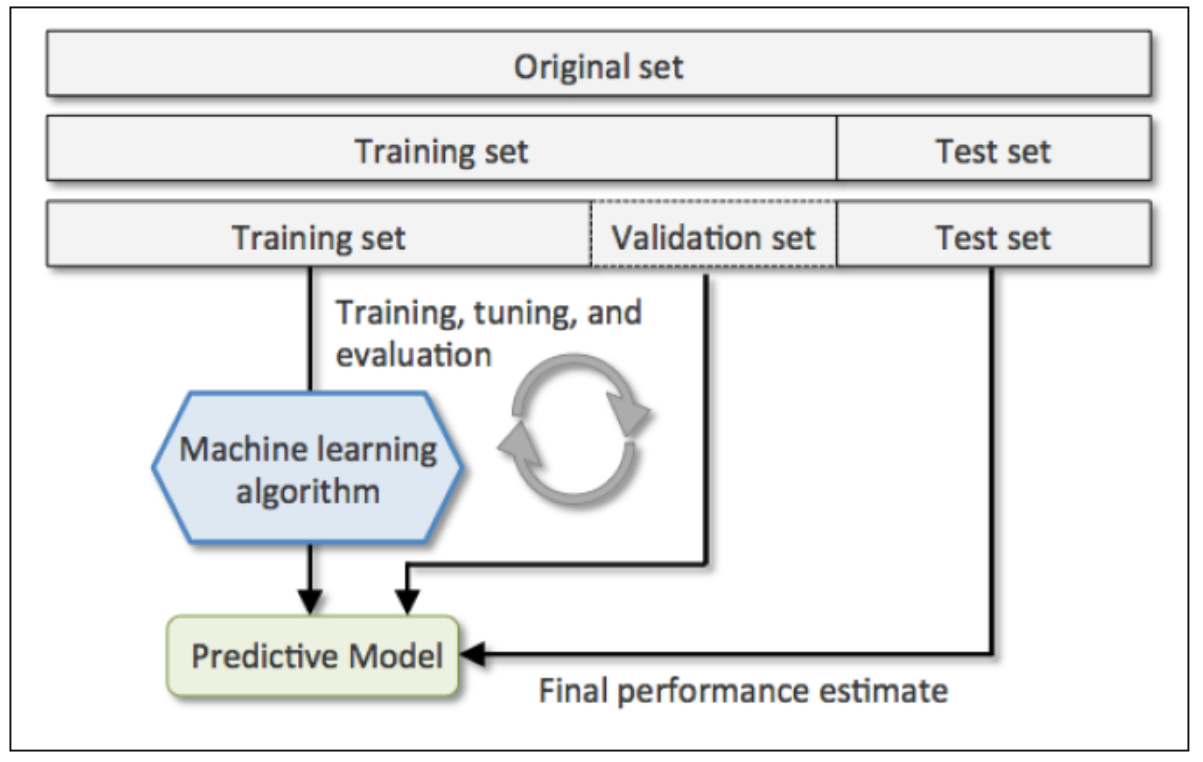
但holdout方法也有明显的缺点,它对数据分割的方式很敏感,如果原始数据集分割不当,这包括训练集、验证集和测试集的样本数比例,以及分割后数据的分布情况是否和原始数据集分布情况相同等等。所以,不同的分割方式可能得到不同的最优模型参数。
k折交叉验证
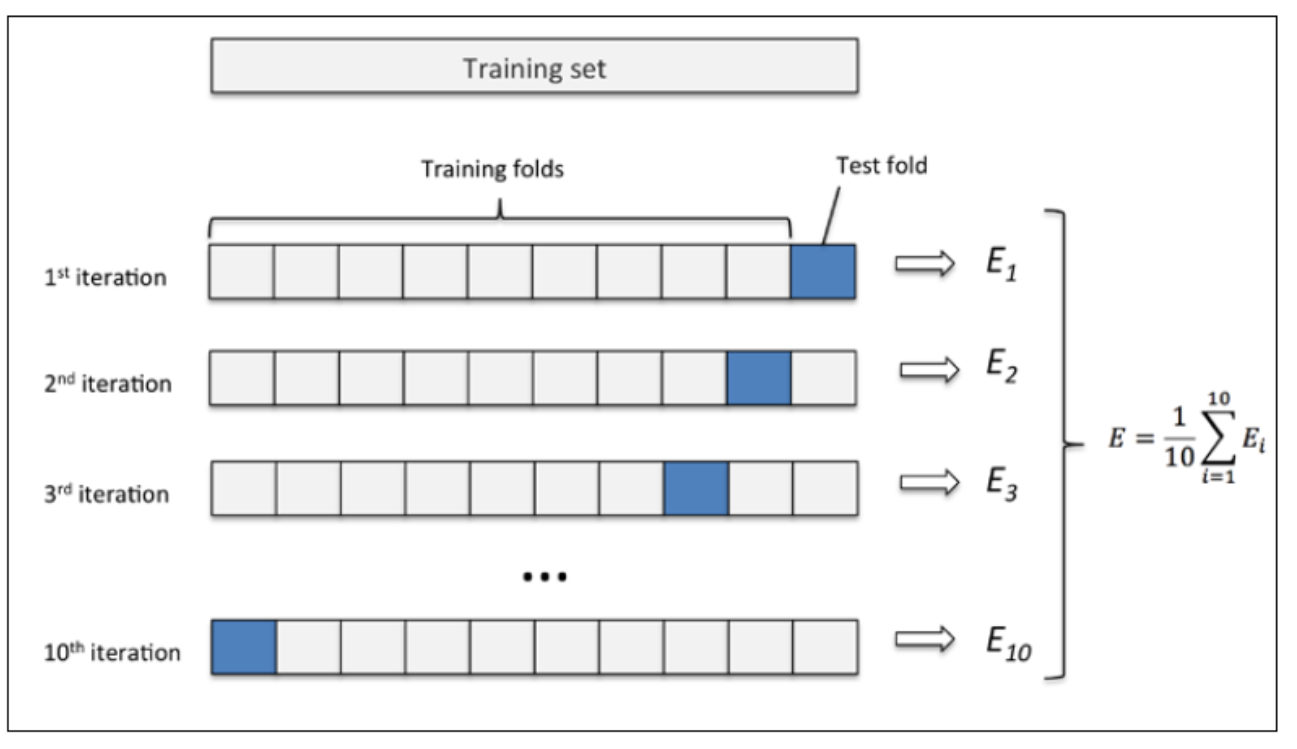
k折交叉验证如下:
(1)使用不重复抽样将原始数据随机分为k份。
(2)k-1份数据用于模型训练,剩下1份数据用于测试模型。
(3)重复第2步k次,我们就得到了k个模型和其评估结果。
(4)将计算k折交叉验证结果的平均值作为参数/模型的性能评估。
(5)一旦找到最优参数,要使用这组参数在原始数据集上训练模型,作为最终的模型。
10折交叉验证如下:
0x04 TextCNN
文本序列中的n-gram信息指的是文本中连续的n个词。在NLP任务中,n-gram可以用来评估或预测一个句子是否合理,或者提供一些自动完成、拼写检查、语法检查等功能。CNN网络可以很有效的捕捉文本序列中的n-gram信息,而分类任务从本质上讲是捕捉n-gram排列组合特征。无论是关键词、内容,还是句子的上层语义,在句子中均是以n-gram特征的形式存在的。
Bert往往可以对一些表述隐晦的句子进行更好的分类,TextCNN往往对关键词更加敏感。
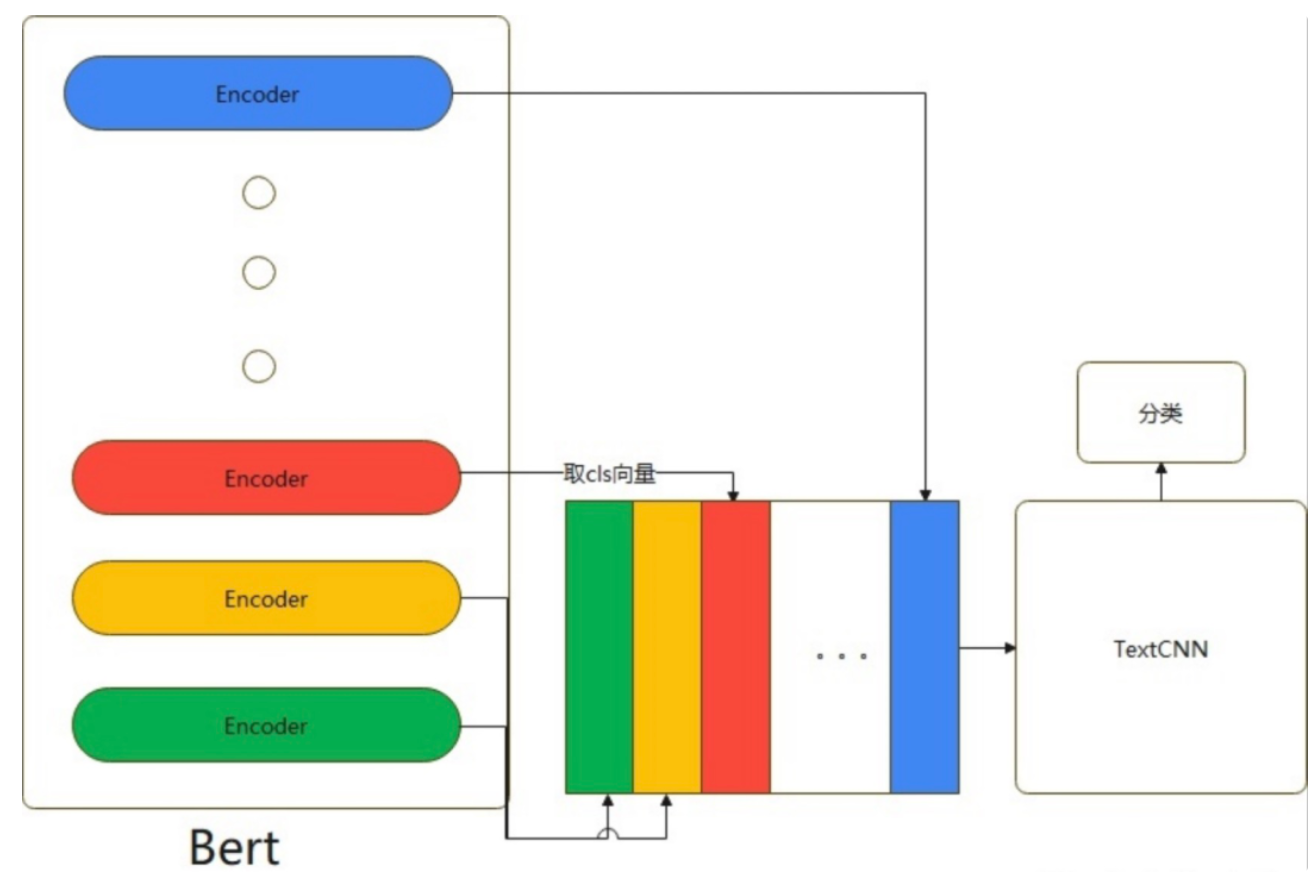
Bert除去第一层输入层,有12个encoder层。每个encoder层的第一个token(CLS)向量都可以当作句子向量。我们可以理解为:encoder层越浅,句子向量越能代表低级别语义信息;越深,代表更高级别语义信息。
如果我们既想得到有关词的特征,又想得到语义特征,模型具体做法是将第1层到第12层的CLS向量,作为CNN的输入然后进行分类。如下图所示:
0x05 结果
最优结果0.66,绝对不是模型问题,应该调一调参会好很多,目前已知的调参可以达到0.79。
0x06 另一种方法
分层抽样:一种数据采样的方法,它根据不同群体的比例在数据里通过比例进行采样,减少采样的误差。分层抽样的目的是保证抽样后的数据集能够反映总体的特征,提高模型的泛化能力。最终结果可以到达0.83。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!