re-core-principle
逆向工程核心原理笔记-1
需要:目标、激情、Google
不需要:贪心(要浅尝辄止)、急躁(要平心静气)
0x01 逆向helloworld
PC的Intel x86、移动产品中的ARM系列,两者具有不同形态的汇编指令。
EP(EntryPoint)是windows可执行文件的入口点。
x32dbg相关指令:

1 | CTRL+E // 转储位置-更改转储位置的值 |
每次重新运行调试器时,调试都会返回到EP处,并从此处开始新的调试,使用起来相当不方便。经验丰富的代码逆向分析专家需要在调试代码时设置某个重要的点(地址),使调试能快速转到设置点上。一般是打断点来解决上述问题,或者通过注释来快速跳跃到设置点。
如何快速查找指定代码?(1)代码执行,例如helloworld.exe程序执行到显示message box的阶段。(2)字符串搜索(程序使用的字符串)。(3)API搜索(x32dbg的自我分析机制)。(4)使用加壳等工具后,方法3就没有用处了,这种情况下,DLL代码库被加载到进程内存后,我们可以直接向DLL代码库的API添加断点。
如何修改字符串?(1)直接修改字符串缓冲区(buffer)。优缺点:优点是使用简单,缺点是它对新字符串的长度有限制,新字符串的长度不应比原字符串长。(2)在其他内存区域生成新字符串并传递给消息函数。若把修改后的代码重新保存为程序文件,可能发现程序无法正常运行。这是因为:可执行文件被加载到内存并以进程形式运行时,文件并非原封不动地被载入内存,而是要遵循一定规则进行。这一过程中,通常进程的内存是存在的,但是相应的文件偏移(offset)并不存在,如果不能正常运行,说明字符串内存对应的文件偏移不存在,所以修改后的程序无法正常运行。
什么是启动函数?启动函数 (Stub code)不是用户编写的代码,而是编译器任意添加的代码。编译A程序时,不同编译器会根据自身特点添加不同启动函数。
0x02 小端序
小端序先放低位(内存地址低位存放数据低位),大端序先放高位(内存地址低位存放数据高位)。但是对于字符串而言,小端序与大端序的存储顺序相同。UNIX的RISC系列的CPU使用大端序,而Intel x86 CPU使用小端序。
0x03 IA-32寄存器讲解
IA-32是英特尔推出的32位元架构,属于复杂的指令集架构。寄存器结构如下:

1 | EAX:(针对操作数和结果数据的)累加器 |
以上4个寄存器常用来保存常量与变量的值。循环命令(LOOP)中,ECX用来循环计数 (loop count),每执行一次循环,ECX都会减1。EAX一般用在函数返回值中,所有WIN32 API函数都会先把返回值保存到EAX再返回。
1 | EBP:(SS段中栈内数据指针)扩展基址指针寄存器 |
以上4个寄存器主要用作保存内存地址的指针。ESP指示栈区域的栈顶地址。EBP表示栈区域的基地址,函数被调用时保存ESP的值,函数返回时再把值返回ESP,保证栈不会崩溃(栈帧技术)。
段是一种内存保护技术,它把内存划分为多个区段,并为每个区段赋予起始地址、范围、访问权限等,以保护内存。段内存记录在SDT (Segment Descriptor Table,段描述符表)中,而段寄存器就持有这些SDT的索引(index)。段寄存器的寄存器大小为16位(针对32位系统)。
1 | CS:Code Segment,代码段寄存器 |
程序调试中会经常用到FS寄存器,它用于计算SEH(Structured Exception Handler,结构化异常处理机制)、TEB(Thread Environment Block,线程环境块)、PEB(Process Environment Block,进程环境块)等。
EIP是32位寄存器(不是16位),程序运行时,CPU会读取EIP中一条指令的地址(CS与IP不结合了),传送指令到指令缓冲区后,EIP寄存器的值自动增加,增加的大小即是读取指令的字节大小。这样,CPU每次执行完一条指令,就会通过EIP寄存器读取并执行下一条指令。
0x04 栈
.png)
0x05 分析abex’crackme#1
跟着书做实验即可。
补充:HDD:Hard Disk Drive(硬盘驱动)。
函数参数入栈的时候是按参数顺序从右向左入栈。为什么是逆序呢?栈的结构先进后出,所以把参数压入栈时,只有按照逆序的方式压入,函数才能以正确的顺序(正序)接收到这些参数。
0x06 栈帧
栈帧就是利用EBP(不是ESP)寄存器访问内局部变量、参数函数返回地址等的手段。栈帧结构很简单,如下所示:

- 最新的编译器中都带有一个
优化(Optimization)选项,使用该选项编译简单的函数将不会生成栈帧。 - 在栈中保存函数返回地址是系统安全隐患,攻击者使用缓冲区溢出技术能够把保存在栈内存的返回地址更改为其他地址。
被调函数执行完毕后,函数的调用者(Caller)负责清理存储在栈中的参数,这种方式称为cdecl方式。反之,被调用者(Callee)负责清理保存在栈中的参数,这种方式称为stdcall方式。这些函数调用规则统称为调用约定(Calling Convention)。
0x07 分析abex’crackme#2
跟着书做实验即可。
此程序使用Visual Basic编写,而不是Visual C++ or 汇编。VB文件使用名为MSVBVM60.dIl( Microsoft VisualBasic VirtualMachine 6.0)的VB专用引擎来运行。例如,显示消息框时,VB代码中要调用MsgBox函数。其实,VB编辑器真正调用的是MSVBVM60.dll里的rtcMsgBox函数,在该函数内部通过调用user32.dll里的MessageBoxW函数 (Win32API)来工作。
根据使用的编译选项的不同,VB文件可以编译为本地代码(N code)与伪代码(P code),类似于汇编的伪指令(供编译器使用)与正常指令。本地代码使用IA-32指令,而伪代码是一种解释器(Interpreter)语言,它使用由VB引擎实现虚拟机并可自解析的指令(字节码)。伪代码类似于Java虚拟机、Python虚拟机等,其好处是方便代码移植。
VB主要用来编写GUI程序。VB使用Unicode字符串,VB文件的函数之间由Nop分隔。VB在main中并不存在用户代码,用户代码存在于各个事件处理程序(event handler)之中。
间接调用
call指令并不直接转入要调用的函数,而是通过jmp来中转一下。例如:
1 | 00401232 JMP DWORD PTR DS:[401A0] |
其中,401A0是IAT(导入地址表)区域,里面有被调用函数的实际地址。abex'crackme#2程序中,ThunRTMain是VB程序的主函数,并在DS:[401A0]中存储,而401E14是RT_MainStruct结构体的地址,这是主函数的参数。
程序分析
此程序是一个用VB写的用于测试名字与序列号是否正确的程序。调试之前可以预测一下代码的实现。具体看P65及以后,这里只跟随书籍进行调试。
0x08 Process Explorer 进程管理工具
Process Explorer是Windows操作系统下优秀的进程管理工具。
0x09 函数调用约定(Calling Convention)
栈就是定义在进程中的一段内存空间,向低地址方向扩展,且其大小被记录在PE头中,也就是说进程运行时确定栈内存的大小(与malloc/new动态分配内存不同,此时分配的是堆)。
函数执行完成后,栈中的参数如何处理?不用管。由于只是临时使用存储在栈中的值,即使不再使用,清除工作也会浪费CPU资源。下一次再向栈存人其他值时,原有值会被自然覆盖掉,并且栈内存是固定的,所以既不能也没必要释放内存。
函数执行完毕后,ESP值如何变化?ESP值要恢复到函数调用之前,这样可引用的栈大小才不会缩减。栈内存是固定的,ESP用来指示栈的当前位置。函数调用后如何处理ESP,这就是函数调用约定要解决的问题。主要的函数调用约定如下:
cdecl方式,主要在C语言中使用,函数调用者负责处理栈,就是把函数调用时push进去的参数给消除。好处:就像printf函数一样,可以向函数传递长度可变的参数,这种功能在其他调用方式中很难实现(为什么?)。stdcall方式,常用于win32 API,若想使用stdcall方式编译源码,只要在函数前面加_stdcall关键字即可。栈的清理工作由被调用者完成,书中例子的add函数最后是ret 0x08,其含义是ret; pop 8字节。其好处是:代码尺寸小,兼容性高,使用VB等其他语言也能调用API。fastcall方式使用寄存器传递前两个参数,而不是使用栈。其调用速度快。
0x10 Part10Tut逆向
补充:msvbvm50.dll是一个动态链接库文件,它是微软Microsoft Visual Basic虚拟机相关的文件。
我们要逆向的程序是关于序列号逆向的,与0x07类似。跟着书籍进行操作。P79
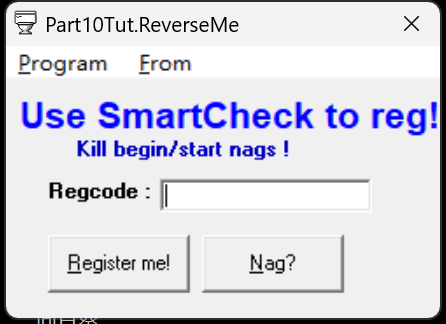
- 首先,我们要去除程序刚开始进入时讨厌的确定框,打开后发现此程序也是用VB写的,其中调用消息框的函数为
MSVBVM50.rtcMsgBox。发现这个确定框在程序中有两次调用(第1次是程序刚开始运行,第2次是点击上图的Nag?按钮),通过将调用MSVBVM50.rtcMsgBox的函数直接ret即可,注意由于是stdcall方式,所以需要确定函数的参数列表,最后是ret 0x4。 - 注册码直接是一个cmp函数,很容易发现是:
I'mlena151。
0x11 如何学习逆向
感受乐趣,懂得检索,实践,保持平和心态(不要急躁)。
0x12 PE文件格式
PE文件是Windows操作系统下使用的可执行文件格式。它是微软在UNIX平台的(COFFCommon Obiect File Format,通用对象文件格式)基础上制作而成的。PE文件是指32位的可执行文件,也称为PE32。64位的可执行文件称为PE+或PE32+(不是PE64)。PE文件种类有:

严格来说,除了OBJ文件,其他类型的文件都可以执行(在shell或者调试器中)。
如何加载到内存、从何处开始运行、运行中需要的DLL有哪些、需要多大的栈/堆内存等,大量信息以结构体形式存储在PE头中,因此学习PE文件格式就是学习PE头中的结构体。
从DOS头(DOS header)到节区头(Section header)是PE头部分,其下的节区合称PE体。文件中使用偏移(offset)表示位置,内存中使用VA(VirtualAddress,虚拟地址)来表示位置。文件的内容一般可分为代码(.text)、数据.data)、资源(.rsrc)节。根据所用的不同开发工具(VB/VC++)与编译选项,节区的名称、大小、个数、存储的内容等都是不同的。
各节区头定义了各节区在文件或内存中的大小、位置等。PE头与各节区的尾部存在一个区域,称为NULL padding。内存中节区的起始位置应该在各文件单位的倍数位置上,空白区域将用NULL填充。如下图所示,DOS头+DOS存根+NT头+节区头=PE头:
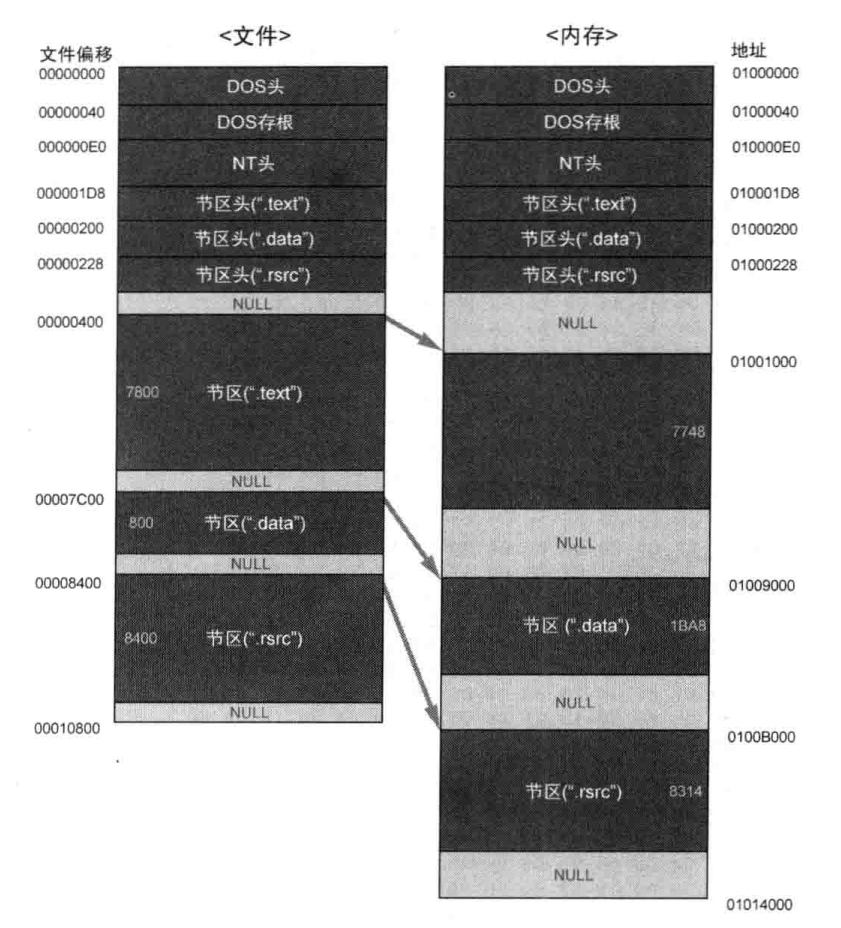
VA:进程虚拟内存的绝对地址,RVA:从某个基准位置开始的相对地址。其转换关系为:VA=ImageBase+RVA,方便文件加载到内存时的重定位。对于32位的OS,每一个进程有4G虚存,VA范围为:00000000-FFFFFFFF。
DOS头
DOS文件是指在DOS操作系统下创建或使用的文件。DOS操作系统是一种基于磁盘管理的操作系统,它直接操纵管理硬盘的文件,一般都是黑底白色文字的界面。DOS文件的扩展名通常有三个字母,例如.exe、.com、.bat等。为了考虑PE文件对DOS文件的兼容性,微软在PE头的最前面添加了一个IMAGE_DOS_HEADER结构体(40字节)。如下所示:
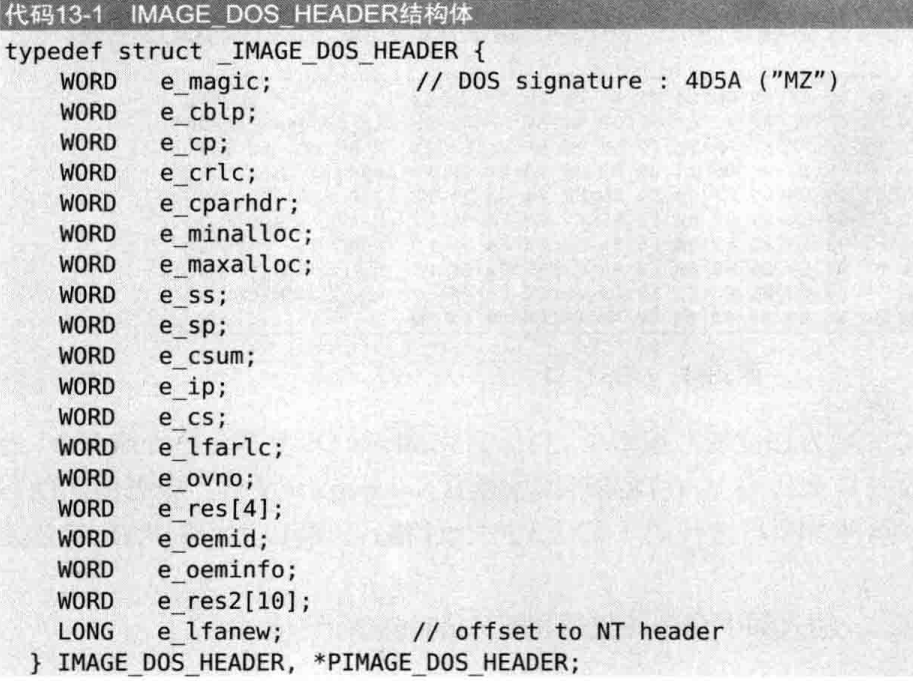
其中最重要的两项是:
1 | e_magic //DOS签名(signature,4D5A=>ASCII值"MZ",MZ是一个开发人员的名字首字母,好帅) |

DOS存根(stub)
在DOS头下方,是可选项,且大小不固定,由代码与数据混合而成。其中的代码,在32位的Windows OS中不会运行该命令(由于被识别为PE文件,所以忽视该代码)。在DOS环境中运行Notepad.exe文件,或者使用DOS调试器(debug.exe)运行它,可使其执行该代码(不认识PE文件格式,所以被识别为DOS EXE文件)。灵活使用该特性可以在一个可执行文件(EXE)中创建出另一个文件,它在DOS环境中运行16位DOS代码,在Windows环境中运行32位Windows代码,这种特性叫做MS-DOS兼容。
NT头
IMAGE_NT_HEADERS结构体如下:

IMAGE_NT_HEADERS结构体大小为0xF8字节,由3个成员组成,第一个成员为签名(Signature)结构体(4字节),其值为50450000h(“PE”)。另外两个成员分别为文件头(File Header)结构体与可选头(Optional Header)结构体。
NT头中的文件头
文件头的IMAGE_FILE_HEADER结构体(20个字节)如下:
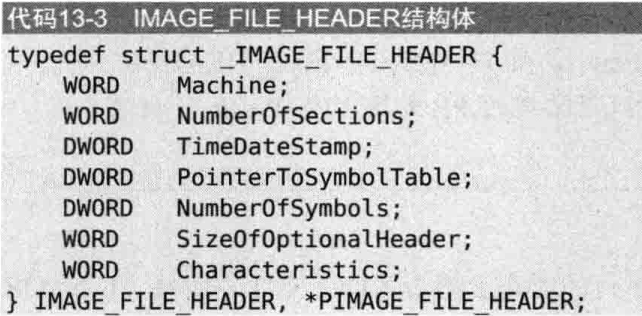
IMAGE_FILE_HEADER结构体有四个重要的项:
1 | Machine // 每种CPU都有自己唯一的mechine码 |
注:借助IMAGE_DOS_HEADER的elfanew(NT头偏移)与IMAGE_FILE_HEADER的SizeOfOptionalHeader(可选头大小) ,可以创建出一种脱离常规的 PE文件(“麻花”PE文件,不连续)。
NT头中的可选头
可选头的IMAGE_OPTIONAL_HEADER32结构体是最大的,如下图所示:


重点关注下列选项:
1 | Magic // IMAGE_OPTIONAL_HEADER32时为10B,IMAGE_OPTIONAL_HEADER64时为20B |
注:driver文件(系统驱动,例如sys),GUI文件(窗口应用程序,例如nodepad.exe),CUI文件(控制台应用程序,例如cmd.exe)。
DataDirectory结构体数组详细结构如下:
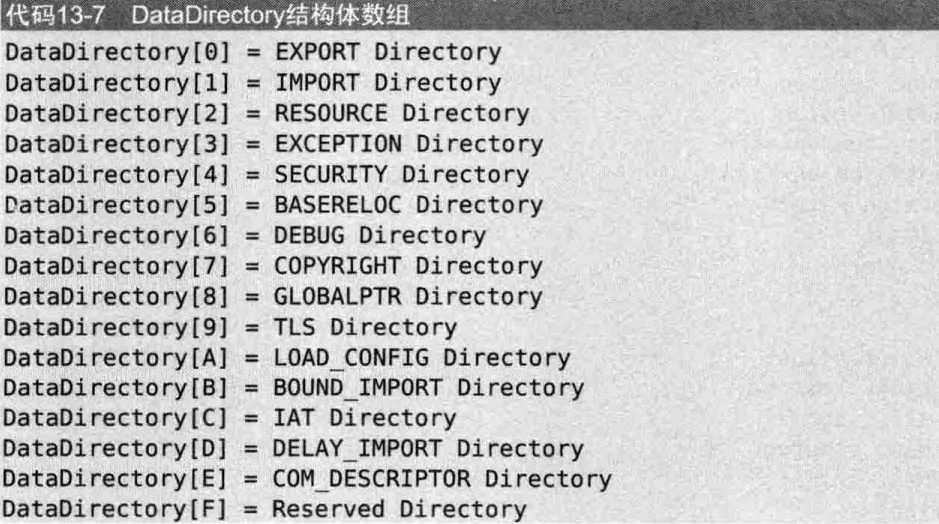
Time:2023-03-14
节区头
PE文件格式的设计者把具有相似属性的数据统一保存节区中,然后需要把各节区的属性记录在节区头中(例如起始位置、大小、访问权限等)。节区头是由IMAGE_SECTION_HEADER结构体组成的数组,每个结构体对应一个节区,其结构如下所示:
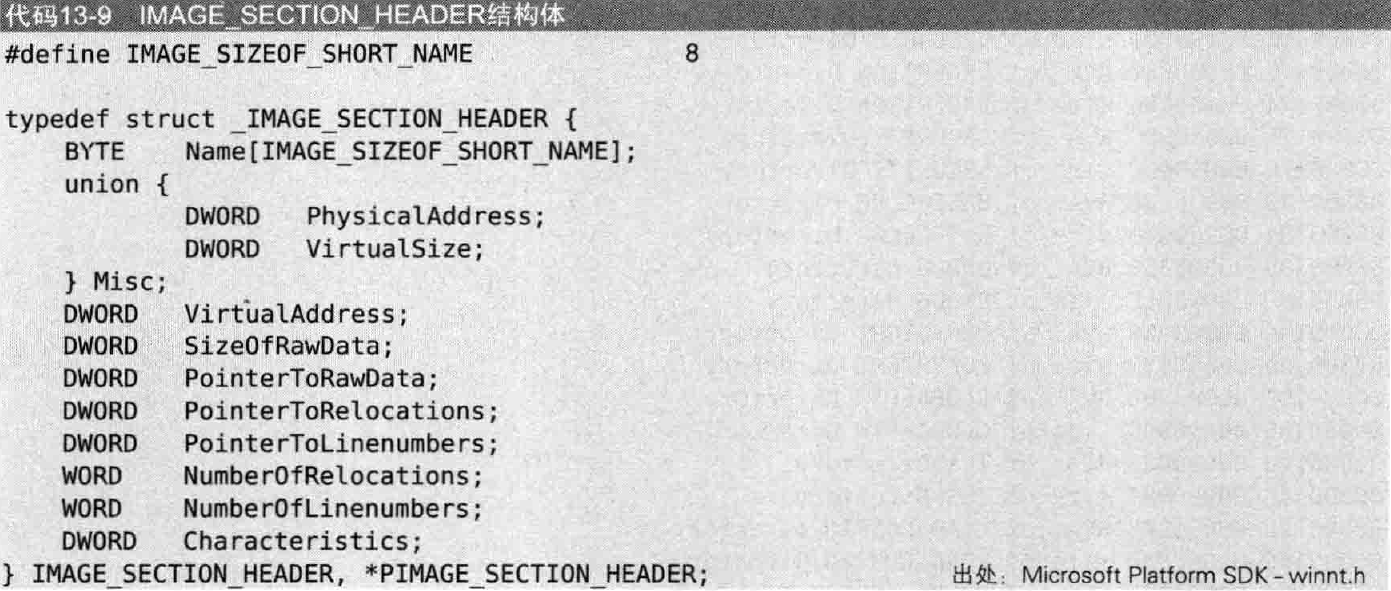
其重要字段解释如下:
1 | VirtualSize // 内存中节区大小 |
RVA to RAW
PE文件从磁盘映射到内存,这种映射叫做RVA to RAW。RVA是内存中数据的实际地址相对内存中PE文件基址间的距离。RAW指磁盘中数据的实际地址相对磁盘中PE文件基址间的距离。比较重要,主要是PointerToRawData与VirtualAddress都保存在节区头中。
1 | RVA = VA - ImageBase // 不考虑节区,纯PE文件从磁盘到内存的映射 |
练习题如下:
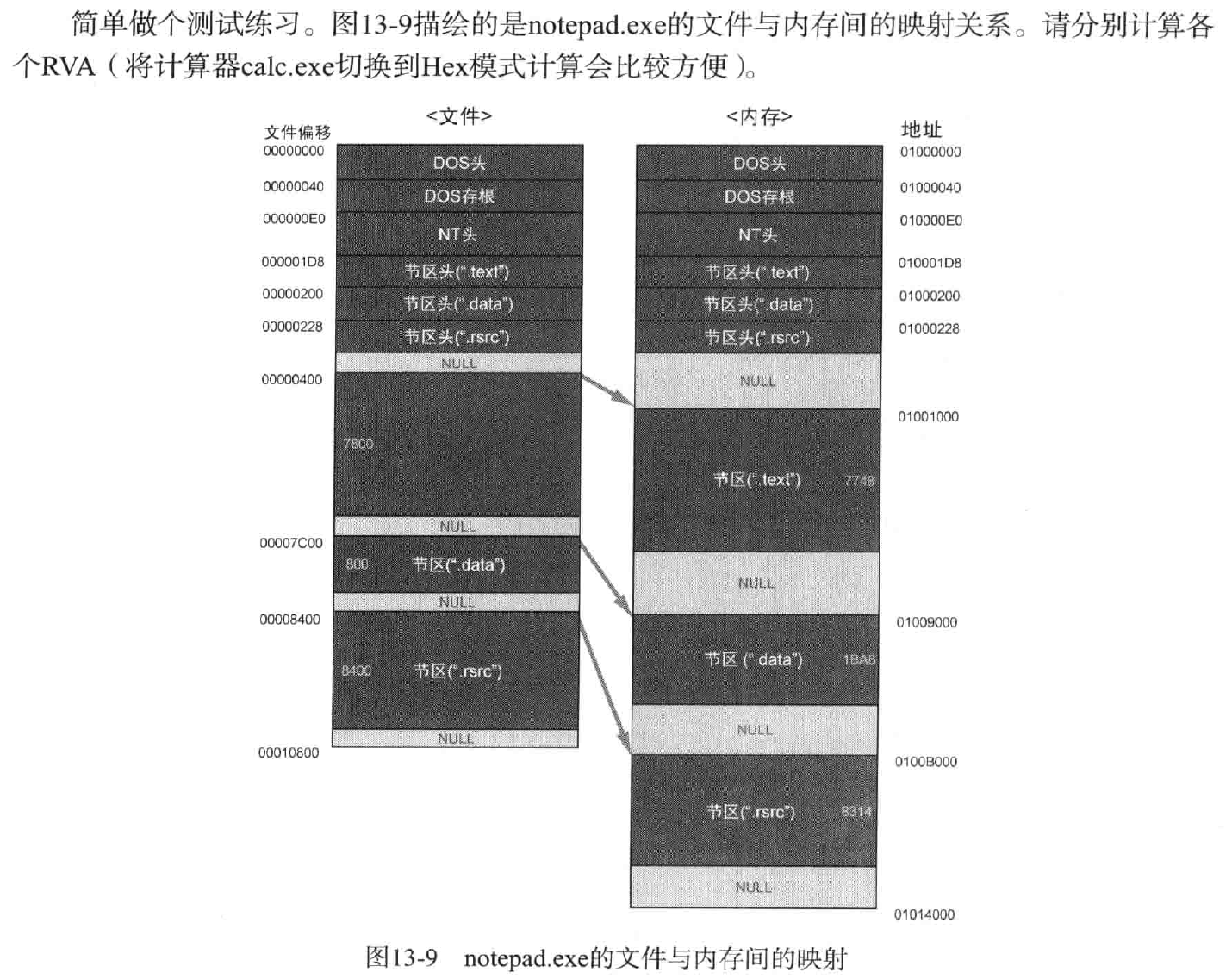
1 | `.text`的RVA:1000H |
IAT(导入地址表)
IAT属于NT可选头的DataDirectory,IAT是一个表格,记录程序正在使用哪些库中的哪些函数。
DLL动态链接库引入原因:同时运行多个程序时,若像DOS一样运行时都包含相同的代码,则会造成严重的内存浪费,而DLL使用内存映射技术,使加载后的DLL代码、资源在多个进程中实现共享。
加载DLL的方式有两种:(1)显式链接(Explicit Linking)程序使用DLL时加载,使用完毕后释放内存。(2)隐式链接(Implicit Linking)程序开始时加载DLL,程序终止时再释放占用的内存。即隐式链接的DLL生命周期更长。
在程序运行时,如果要调用某一个DLL中的函数,指令一般会写call [固定地址],然后这个固定地址里写了此函数在内存中的具体位置。(我猜测,这个固定地址就是IAT表的位置)
IMAGE_IMPORT_DESCRIPTOR
是IAT对应的结构体,位置在NT可选头的DataDirectory的第2项所指向的位置。其结构体示意图如下:
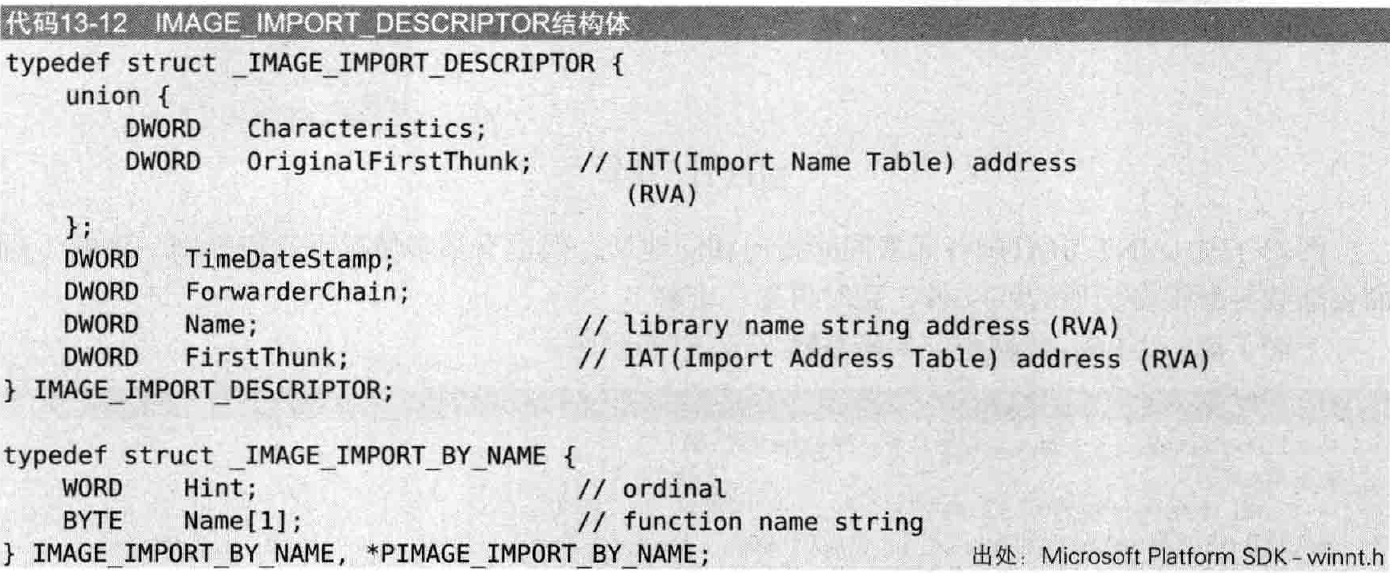
执行一个程序时需要导入多个库,导入多少库就存在多少个IMAGE_IMPORT_DESCRIPTOR结构体,这些结构体形成了数组。上图的重要项解释如下:
1 | OriginalFirstThunk // INT(Import Name Table),指向不同库的IMAGE_IMPORT_DESCRIPTOR指针,RVA |
例如,kernel32.dll的IMAGE_IMPORT_DESCRIPTOR如下所示(都是RVA地址,且这是加载到内存后的示意图,加载到内存之前,FirstThunk与OriginalFirstThunk的指向相同。加载到内存时,PE装载器会重载FirstThunk的值):
.png)
下面说一下PE装载器把导入函数输入到IAT的顺序:
1 | 1. 读取IMAGE_IMPORT_DESCRIPTOR的Name,获得库名称字符串"kernel32.dll" |
书中给了一个notepad.exe的例子,挺重要的,书中写的很全了,所以不再赘述。要注意的是,如果是直接用010editor来追踪,给的地址基本全是RVA,要转换成RAW才能进行寻找。
EAT(导出地址表)
- 一般是DLL中有的,用来方便其他PE文件求得自己提供的函数的地址。
- EAT对应的结构体叫:IMAGE_EXPORT_DIRECTORY。
- IMAGE_IMPORT_DESCRIPTOR(也就是IAT)可以有多个,因为一个PE文件可以导入多个库,但是IMAGE_EXPORT_DIRECTORY只有一个。
- 分析路线与EAT差不多,书中也给了例子。
IMAGE_EXPORT_DIRECTORY的结构如下:
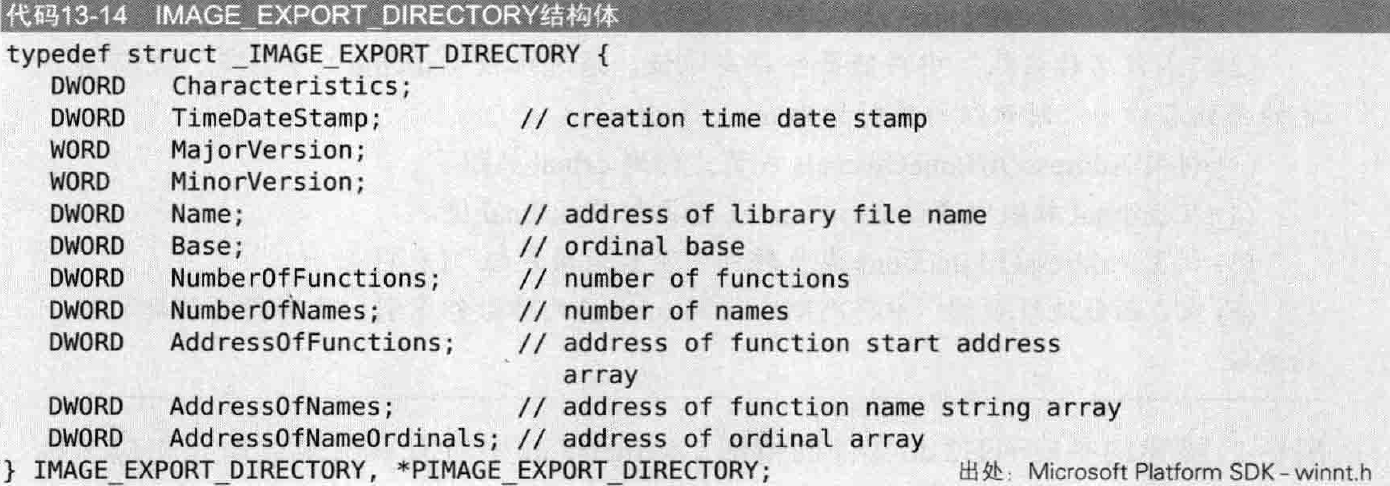
重要字段如下:
1 | NumberOfFunctions // 导出的函数个数 |
下图描述了EAT结构:
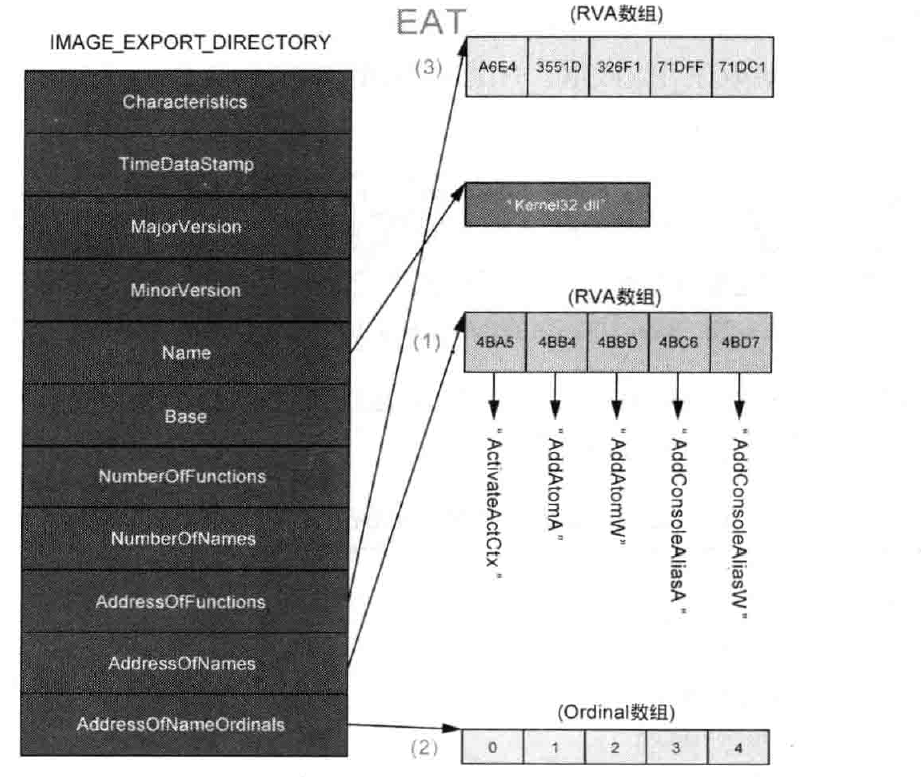
从库中获得函数地址的API是GetProcAddress()函数,该API使用EAT来定位函数的地址,下面讲解它如何获得函数地址:
1 | 1. 在AddressOfNames中找到函数名对应索引,记录此索引。 |
有的导出函数没有函数名,仅通过Ordinals导出。
patched PE
指的是PE文件虽然符合PE规范,但是附带的PE头非常具有创意(PE头纠缠放置到各处),典型的就是tinyPE(97字节)。
0x13 运行时压缩
无损压缩与有损压缩
无损压缩:ZIP、RAR
有损压缩:jpg、mp3、mp4
运行时压缩器
针对PE文件,PE文件内部有解压缩代码,PE文件在运行瞬间在内存中解压缩后运行。程序的EP代码(入口代码)中执行解码程序。把普通PE文件创建成运行时压缩文件的实用程序称为压缩器(Packer),经反逆向(Anti-Reversing)技术特别处理的压缩器称为保护器(Protector)。
普通的压缩器有:UPX、ASPack。针对病毒等恶意文件的压缩器:UPack、PESpin、NSAnti,其会对源文件进行较大变形,严重破坏PE头。
PE保护器是保护PE文件免受代码逆向分析的程序,其应用了多种防逆向的技术(反调试、反模拟、代码混乱、多态代码、垃圾代码、调试器监视等)。这类保护器使压缩后的PE文件尺寸反而比源文件要大一些。常用保护器为:ASProtect、Themida、SVKP、ultraProtect、Morphine等。
下面给出了notepad.exe经upx压缩前后的示意图:
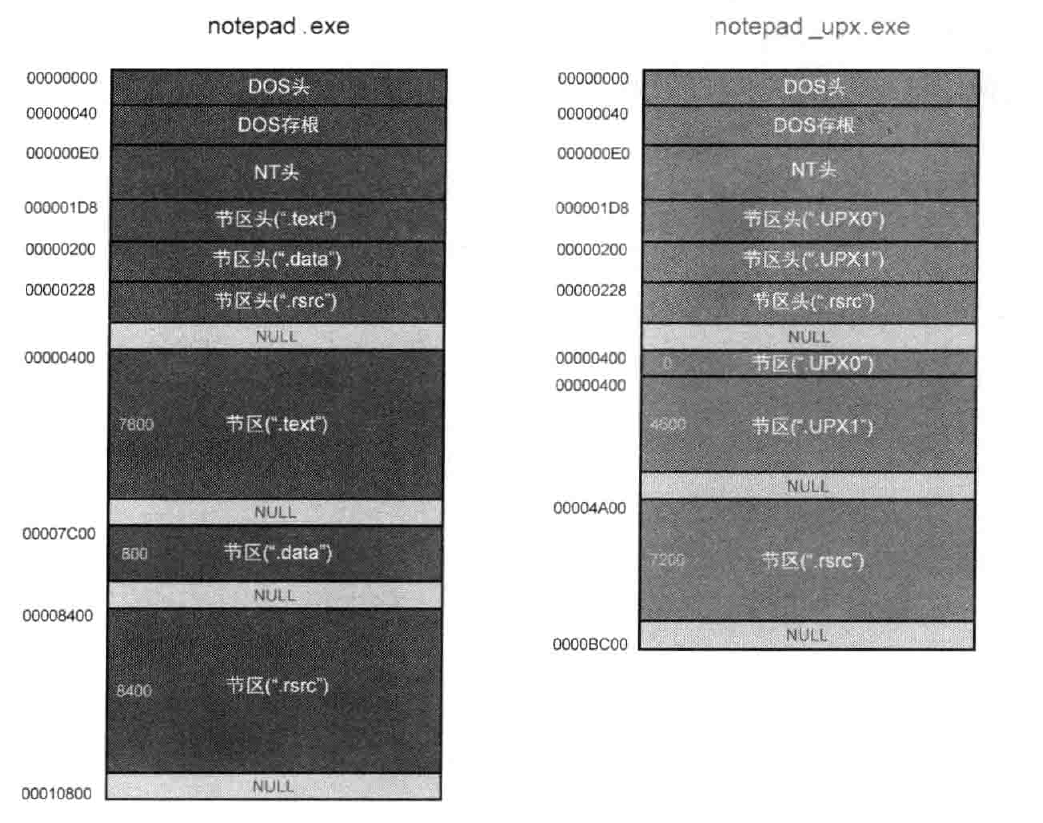
可以看到,压缩后第一个节区UPX0的空间为0,在此文件运行时,经压缩的PE文件在运行瞬间将压缩的代码解压到第一个节区。一开始,解压缩代码与压缩的源代码都在第二个节区。文件运行时首先执行解压缩代码,把处于压缩状态的源代码解压到第一个节区。
0x14 调试UPX压缩的notepad程序
跟踪数量庞大的代码时,遵循:遇到循环(Loop)时,先了解作用再跳出。
命令补充:

跟着书进行实验,最后总结UPX解压缩的流程:
1 | 1. 短循环,对数据进行平移。 |
如何快速找到OEP:UPX压缩器的EP代码被包含在PUSHAD/POPAD指令之间,并且,跳转到OEP代码的JMP指令紧接着出现在POPAD指令之后,只要在JMP指令附近设置好断点,运行后就能直接找到OEP。
注:硬件断点是CPU支持的断点,最多可以设置4个。与普通断点不同的是,设置断点的指令执行完成后才暂停调试。所以要在栈上打硬件断点,popad执行完之后返回,如果打的是普通断点,那么执行到popad一半时就会中止,就会出现问题。
解压缩并转储时需要重新设置IAT,如果不重新设置,转储后成为exe,再点击打开就会出现初始化错误。这是因为:UPX解压缩只拷贝了IAT,并在第3步就把要跳转的地址改了,而INT(导入名称表)却没改(因为都加载到内存了,不需要改了),所以如果保存再打开的话,会出现初始化错误。这里说的不对,不重新设置IAT,程序根本找不到入口啊。
0x15 基址重定位表(Base Relocation Table)
向进程的虚拟内存加载PE文件时,文件会被加载到PE头的ImageBase所指的地址处。若加载的是DLL文件,且在ImageBase位置处已经加载了其他DLL文件,那么PE装载器就会将其加载到其他未被占用的空间。PE重定位是指PE文件无法加载到ImageBase所指位置,而是被加载到其他地址时发生的行为。重定位示意图如下:
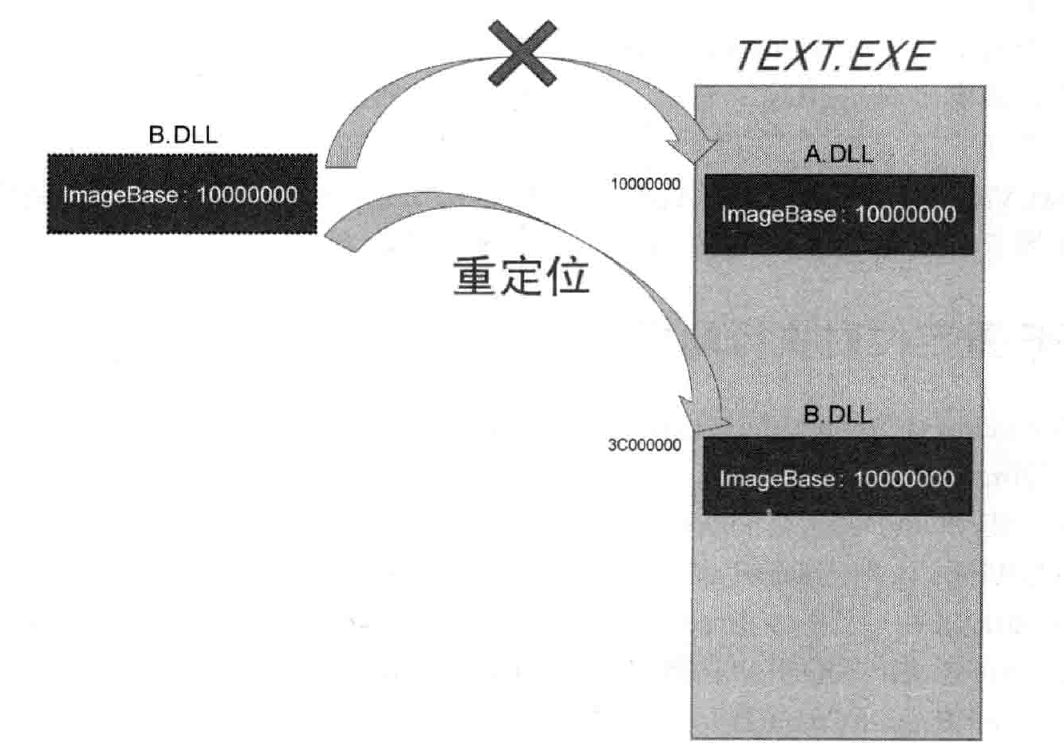
使用ASLR机制,每次运行的PE文件都会被加载到随机地址。重定位操作原理如下:
1 | 1. 在应用程序中查找硬编码(call 后面的地址)的地址位置。 |
那么咋知道程序的哪一部分是硬编码呢?这就需要重定位表(Relocation Table),它是记录硬编码位置的列表(重定位表是在PE文件构建过程,即编译链接中提供的,也就是与DLL连接时提供的)。通过重定位表查找,其实就是指根据PE头的”基址重定位表”项进行的查找。基址重定位表地址位于PE头的DataDirectory数组的第6个元素(数组索引为5),其对应结构体为IMAGE_BASE_RELOCATION,结构体如下:
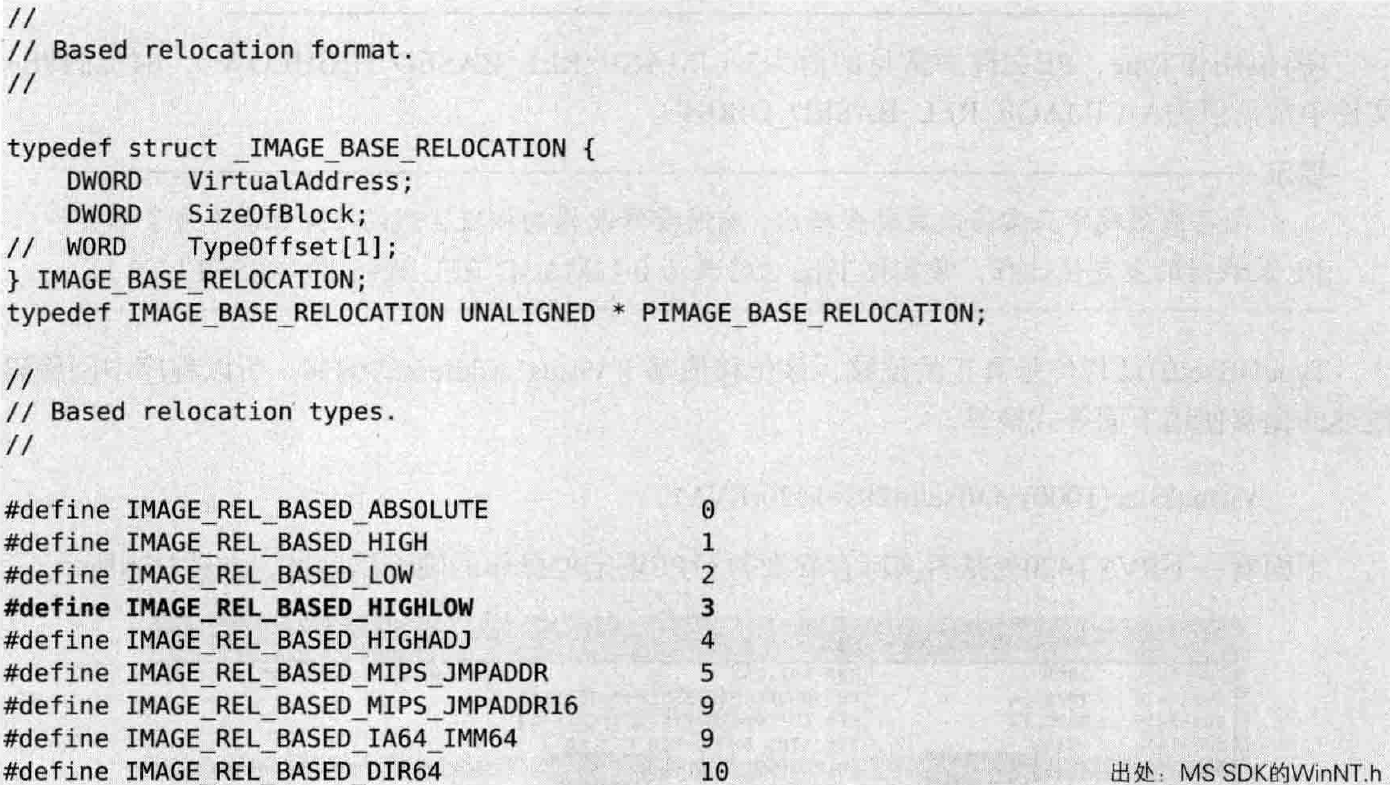
IMAGE_BASE_RELOCATION结构体的第一个成员为VirtualAddress,它是一个基准地址(BaseAddress),实际是RVA值。第二个成员为SizeOfBlock,指重定位块的大小。最后一项TypeOffset数组不是结构体成员,而是以注释形式存在的,表示在该结构体之下会出现WORD类型的数组,并且该数组元素的值就是硬编码在程序中的地址偏移。这段是书上的原话,不太懂,但是后面会详细解释。
下图展示了基址重定位表的内容:
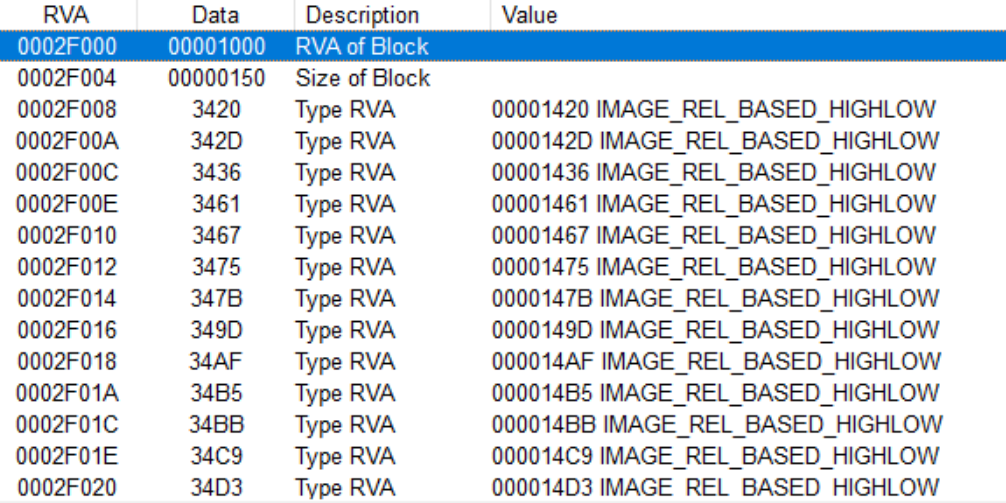
由IMAGE_BASE_RELOCATION结构体的定义可知:VirtualAddress(基准地址)的值为1000,SizeOfBlock的值为150。即,上图中的TypeOffest数组的基准地址为RVA1000,总大小为150。TypeOffset中的每个值为2个字节,是由4位的Type与12位的Offset组成的。例如,值为3420H,就如下所示:

那么此硬编码的RVA=1000+420=1420H。书中P141页写的例子非常好。
0x016 从可执行文件中删除.reloc节区
EXE形式的PE文件中,基址重定位表项对运行没什么影响,这是因为:EXE有自己的虚拟内存空间,因此总是会加载到PE文件中规定的ImageBase中,因此不需要重定位。但基址重定位表对DLL/SYS形式的文件来说几乎是必需的。
VC++中,EXE生成的PE文件的重定位表对应的节区名为.reloc(一般是最后一个节区),删除该节区后文件照常运行,所以我们想删掉。删除的步骤在书中详细说了,跟着做,不再赘述,大体步骤如下:
1 | 1. 整理.reloc节区头 |
0x017 UPack PE文件头详细分析
UPack可以对病毒进行压缩,其对PE文件头作了较大改变。其特点是用一种非常独特的方式对PE头进行变形。UPack会引起诸多现有PE分析程序错误。也就是说,UPack使用了一些划时代的技术方法。
Time:2023-03-20
UPack的重叠文件头
MZ文件头(IMAGE_DOS_HEADER)与PE文件头(IMAGE_NT_HEADERS)巧妙重叠在一起,并可有效节约文件头空间,也给分析带来很大困难。UPack中,PE文件头的起始位置为0x10。
IMAGE_FILE_HEADER.SizeOfOptionalHeader
PE32的IMAGE_OPTIONAL_HEADER固定是0xE0大小,那为什么还要有SizeOfOptionalHeader这样一个选项呢?因为IMAGE_OPTIONAL_HEADER的种类有很多,例如PE32+的IMAGE_OPTIONAL_HEADER大小为0xF0,而且IMAGE_OPTIONAL_HEADER能够确定OPTIONAL_HEADER的下一项,即节区头的位置。
在UPack压缩的文件中,IMAGE_OPTIONAL_HEADER的偏移为0x28,且SizeOfOptionalHeader为0x148(比0xF0与0xE0都要大),因此节区头的偏移为0x170。为啥呢?这是因为,UPack的基本特征就是把PE文件头变形,像扭曲的麻花一样,向文件头适当插人解码需要的代码。增大SizeOfOptionalHeader的值后,就在IMAGE_OPTIONAL_HEADER与节区头之间添加了额外空间,UPack就可以向这个区域添加解码代码。
IMAGE_OPTIONAL_HEADER结束的位置为D7(因为有两个双字节的Null),IMAGE_SECTION_HEADER的起始位置为170,中间就是汇编代码。
IMAGE_OPTIONAL_HEADER.NumberOfRvaAndSizes
这个用来指定datadirectory的数组长度。原来是0x10个,Upack改成了0xA个,后面6个数组不再使用,UPack在这6个数组的位置写自己的代码。和上节中的复写代码区域是重合的。
IMAGE_SECTION_HEADER
节区数为3个,且节区头的起始地址为0x170。
重叠节区
在Stud_PE下看nodepad_upack.exe的节区头,发现磁盘文件中第1节区与第3节区的RawOffset与RawSize是重合的,如下图所示:

且RawOffset与PE文件头起始位置相同。因此可知,UPack会对PE文件头、第1节区、第3节区进行重叠。具体示意图如下所示:
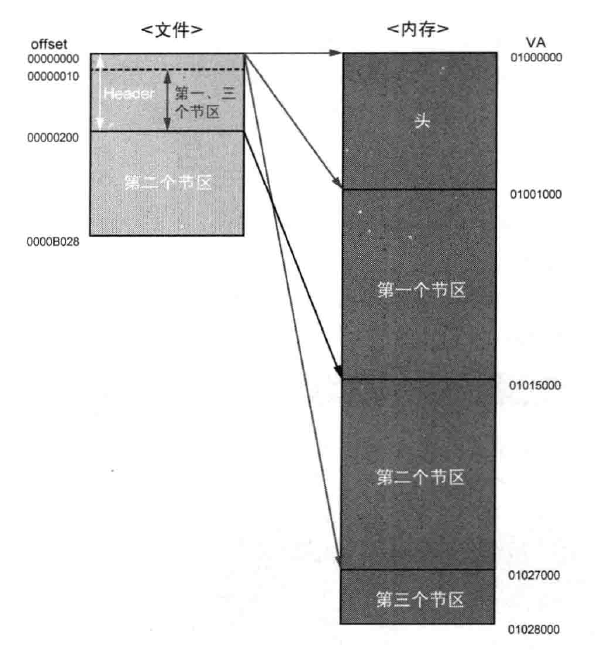
可以看到,PE装载器会将文件0-1FF的区域分别映射到3个不同的内存位置(文件头、第1个节区、第3个节区)。也就是说,用相同的文件映像可以分别创建出处于不同位置的、大小不同的内存映像。第2节区比较大,占了磁盘文件的大部分,这就是被压缩文件所在的地方。文件解压缩后,会放入到第1个节区中。
RVA to RAW
各种PE分析程序对Upack束手无策的原因是:无法正确进行RVA到RAW的变换。由RVA到RAW的计算公式为:RAW-PointerToRawData=RVA-VirtualAddress,使用此公式无法得到正确的RAW地址。为什么呢?
一般而言,指向节区开始的文件偏移的PointerToRawData值应该是FileAlignment的整数倍。UPack的FileAlignment为200,故PointerToRawData值应为0、200、400等值。PE装载器发现第一个节区的PointerToRawData(10)不是FileAlignment(200)的整数倍时,它会强制将其识别为整数倍(即为0)。这使UPack文件能够正常运行,但是PE的相关分析程序都会发生错误。
导入表(IMAGE_IMPORT_DESCRIPTOR)
UPack的导入表组织结构比较特殊。导入表是由一系列IMAGE_IMPORT_DESCRIPTOR结构体组成的数组,最后
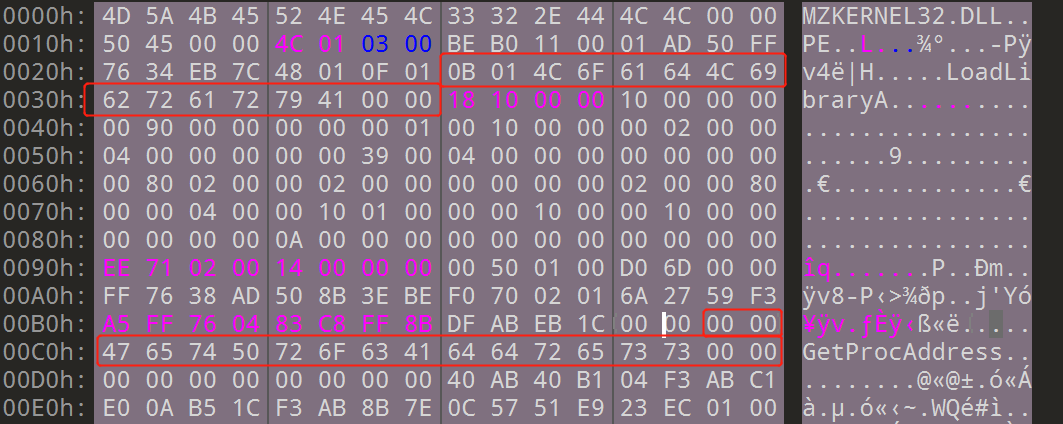
以一个内容为NULL的结构体结束。下图红框表示导入表信息,导入表RVA为000271EE,大小为0x14。
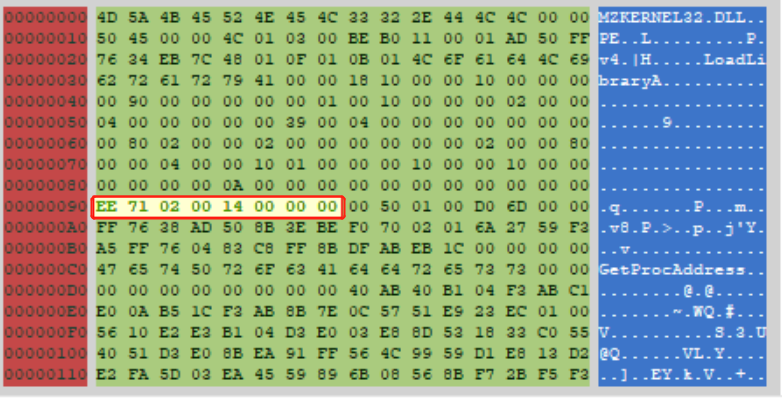
由RVA转RAW后(UPack特殊的转换方式),可以看到导入表数组(第一个IMAGE_IMPORT_DESCRIPTOR):

后面既不是另一个IMAGE_IMPORT_DESCRIPTOR结构体,也不是全NULL,但是在内存中,IAT映射到第3个节区,就保证了之后的字节全是NULL。
下面详细看IMAGE_IMPORT_DESCRIPTOR结构体的内容,对上图进行分析,可以得到:

Name部分找到为KERNEL32.DLL,一般而言,跟踪OriginalFirstThunk(INT)能够发现API名称字符串,但是像UPack这样OriginalFirstThunk(INT)为0时,跟踪FirstThunk(IAT)也无妨(只要INT、IAT其中一个有API名称字符串即可)。跟踪FirstThunk的RAW=1E8,如下图所示(结束为NULL):

可以看到,其导入了2个API,地址分别在RVA=0x28与0xBE,此位置上存着[ordinal(序号)+名称字符串]。
0x18 UPack调试-查找OEP
UPack的前两条指令就是把OEP放到EAX中,但是我们还是接着调试,假设我们不知道这一点。
大体步骤如下:
1 | 1. 将第2个节区中的数据解压缩后放到第1个节区 |
汇编补充:
1 | 1. lodsd //从指针 DS:SI 所指向的内存单元开始,取一个双字进入 EAX 中,并根据标志位 DF 对寄存器 SI 增减1 |
函数补充:
1 | 1. GetProcAddress是一个Windows函数,它的作用是从指定的动态链接库(DLL)中检索导出的函数或变量的地址。GetProcAddress需要两个参数:一个是DLL模块的句柄,一个是函数或变量的名称或序数。GetProcAddress可以用于实现运行时动态链接,即在程序运行时加载和调用DLL中的函数。 |
0x19 “内嵌补丁(Inline Patch)”练习
当难以修改指定代码时,插入并运行Code Cave,从而对程序打补丁,常用于对象程序经过运行时压缩(或加密)而难以直接修改的情况,示意图如下:
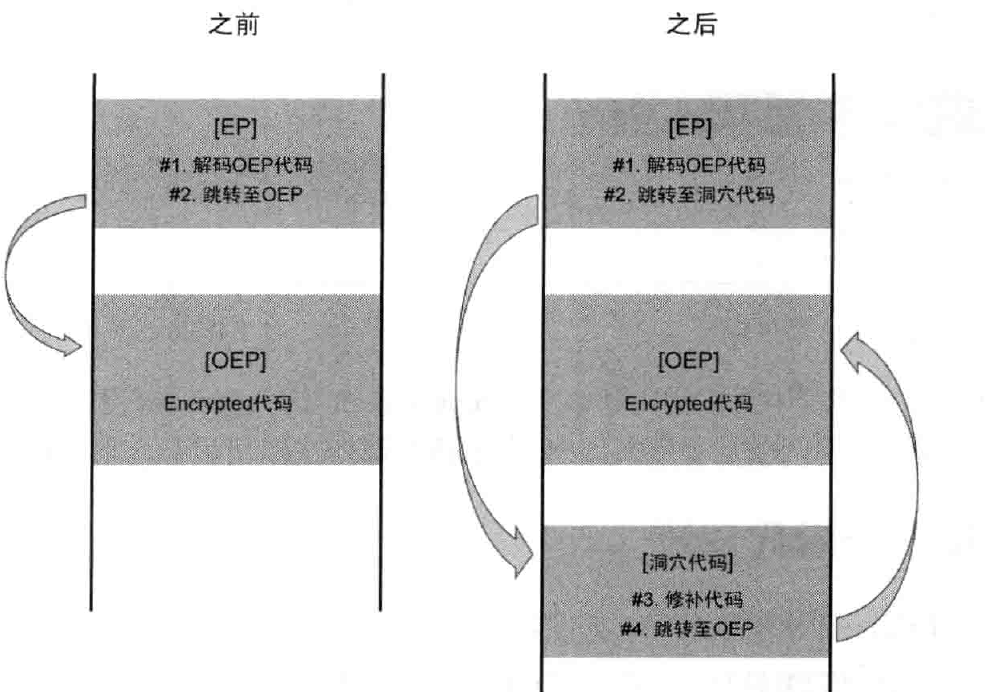
即,先将加密代码解密(先找到OEP),然后再打补丁。之后练习了一道题:Patchme,练习了如何对加密的程序打补丁,在P168页,写的非常详细,不再赘述。细节非常多,忘记了再回过头看。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!