汇编语言学习笔记-2 0x00 包含多个段的程序 问几个问题:
计算0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H的和,并保存在ax中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 assume cs:code code segment ; dw表示一个字,这些数据存储在CS:0, CS:2, CS:4,..., CS:E中 dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H mov cx, 8 mov bx, 0 mov ax, 0 loop1: add ax, cs:[bx] add bx, 2 loop loop1 mov ax, 4c00H int 21H code ends end
但是这样编译运行会出现问题,因为程序一开始的CS:IP指向了数据,但是程序却认为这是汇编指令。 因此这样改:
1 2 3 4 5 6 7 8 9 assume cs:code code segment ... start: ... loop1: ... code ends end start ; end的作用:(1)通知编译器程序结束。(2)通知编译器程序的入口位置
利用栈,将上述8个数据进行逆序存放(以字为单位)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 assume cs:code code segment dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H dw 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 start: mov ax, cs mov ss, ax mov sp, 22H mov bx, 0 ; 变量i mov cx, 8 ; 循环次数 ext: push cs:[bx] add bx, 2 loop ext mov bx, 0 mov cx, 8 put: pop cs:[bx] add bx, 2 loop put mov ax, 4c00H int 21H code ends end start
将数据、栈、代码放到不同的段 如上所示,放到同一个段显得混乱。那么我们就放到不同的段,如下所示(就是将上一节的程序改了改 ):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 assume cs:code, ds:data, ss:stack ; 数据段 data segment dw 0123H,0456H,0789H,0abcH,0defH,0fedH,0cbaH,0987H data ends ; 栈段 stack segment dw 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 stack ends ; 代码段 code segment start: mov ax, stack ; 不是mov ax, cs了。段地址都要有中间变量来承接。 mov ss, ax mov sp, 22H mov ax, data mov ds, ax mov bx, 0 mov cx, 8 ext: push [bx] add bx, 2 loop ext mov bx, 0 mov cx, 8 put: pop [bx] add bx, 2 loop put mov ax, 4c00H int 21H code ends end start
CPU到底如何处理我们定义的段中的内容,当作指令执行,当作数据访问,还是当作栈空间,完全是靠程序中具体的汇编指令,和汇编指令对CS:IP、SS:SP、DS等寄存器的设置来决定的 。
0x01 更灵活的定位内存的方法 and与or指令不再多说。
也可以用字符来代替16进制数,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 assume cs:code, ds:data data segment db 'unIX' db 'foRK' data ends code segment start: mov al, 'a' mov bl, 'b' mov ax, 4c00H int 21H code ends end start
题目:将第一个字符串(BaSiC)转化为大写,将第二个字符串(iNfOrMaTiOn)转化为小写。其中,大写字母+20H=小写字母,但是,我们还不知道如何区分大写字母与小写字母,下面给出一种方法,观察A=01000001H,a=01100001H,可以看到只有第5位不同。第5位为1,那么为小写,第5位为0,那么为大写。 代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 assume cs:code, ds:data data segment db 'BaSiC' db 'iNfOrMaTiOn' data ends code segment start: mov ax, data mov ds, ax mov cx, 5 mov bx, 0 s: mov al, [bx] and al, 11011111B mov [bx], al inc bx loop s mov cx, 11 mov bx, 5 s0: mov al, [bx] or al, 00100000B mov [bx], al inc bx loop s0 mov ax, 4c00H int 21H code ends end start
[bx+idata] 前面我们用[bx]的方式来指明内存单元,还可以用[bx+idata]表示一个内存单元,其中idata为常数。例如,mov ax, [bx+200]代表(ax)=((ds)*16+(bx)+200)。
Q:
A:
AX=00BEH,BX=1000H,CX=0606H
下面使用[bx+idata]的方式改变大写转小写的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 assume cs:code, ds:data data segment db 'Basic' db 'MinIx' data ends code segment start: mov ax, data mov ds, ax mov bx, 0 mov cx, 5 s: mov al, [bx] and al, 11011111B mov [bx], al mov al, [bx+5] or al, 00100000B mov [bx], al inc bx loop s mov ax, 4c00H int 21H code ends end start
SI与DI SI与DI是与BX功能相近的寄存器,SI与DI不能分成两个8位寄存器来使用。
[bx+si]与[bx+di] 例如,mov ax, [bx+si]代表(ax)=((ds)*16+(bx)+(si)),也可以写成mov ax, [bx][si]
总结
Q&A
注:每个字符串16个字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 assume cs:code, ds:data data segment db '1. file ' db '2. edit ' db '3. search ' db '4. view ' db '5. options ' db '6. help ' data ends code segment start: mov ax, data mov ds, ax mov cx, 6 mov bx, 0 s: mov al, ds:[bx+3] or al, 00100000B mov ds:[bx+3], al add bx, 16 loop s code ends end
注:每个字符串16个字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 assume cs:code, ds:data data segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' data ends code segment start: mov ax, data mov ds, ax mov si, 0 mov cx, 4 s0: mov dx, cx ; 外层循环把cx保存起来,保存到dx中 mov bx, 0 mov cx, 3 s: mov al, ds:[bx+si] and al, 11011111B mov ds:[bx+si], al inc bx loop s add si, 16 mov cx, dx ; 恢复cx loop s0 code ends end start
上述程序是用寄存器dx保存cx,为了减少寄存器的占用,下面我们使用栈来进行保存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 assume cs:code, ds:data, ss:stack data segment db 'ibm ' db 'dec ' db 'dos ' db 'vax ' data ends stack segment dw 0,0,0,0,0,0,0,0 stack ends code segment start: mov ax, data mov ds, ax mov si, 0 mov cx, 4 mov ax, stack mov ss, ax mov sp, 16 s0: push cx mov bx, 0 mov cx, 3 s: mov al, ds:[bx+si] or al, 00100000B mov ds:[bx+si], al inc bx loop s add si, 16 pop cx loop s0 code ends end start
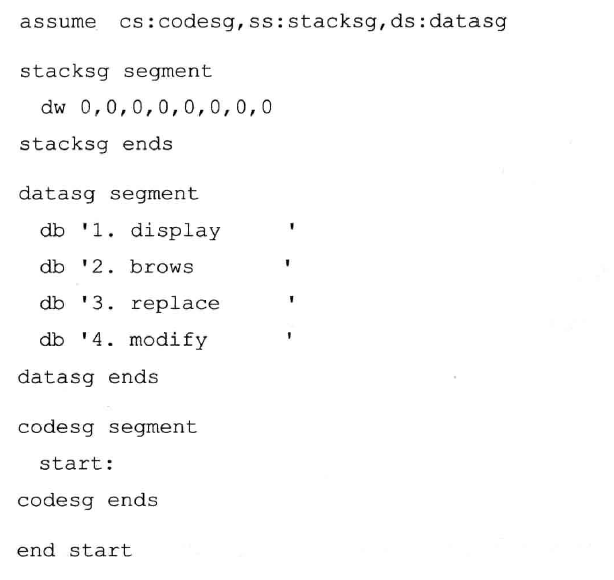
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 assume cs:code, ds:data, ss:stack data segment db '1. display ' db '2. brows ' db '3. replace ' db '4. modify ' data ends stack segment dw 0,0,0,0,0,0,0,0 ;不是16字节会报错 stack ends code segment start: mov ax, stack mov ss, ax mov sp, 16 mov ax, data mov ds, ax mov cx, 4 mov si, 0 s: push cx mov bx, 0 mov cx, 4 s0: mov al, ds:[3+si+bx] and al, 11011111B mov ds:[3+si+bx], al inc bx loop s0 pop cx add si, 16 loop s mov ax, 4c00H int 21H code ends end start
0x02 数据处理的2个基本问题 寄存器reg:ax,bx,cx,dx,sp,bp,si,di,段寄存器sreg:ds,ss,cs,es。
在8086CPU中,只有bx,bp,si,di可以用在[]中来进行内存单元的寻址。(非常重要!!)
在[]中,bx,bp,si,di要么单个出现,要么以bx+si,bx+di,bp+si,bp+di出现:
只要在[]中使用bp,且指令没有显性给出段地址,则段地址默认为ss,而不是ds!
指令要处理的数据有多长? 1. 通过寄存器名指定,例如`mov al, 1`
1. **使用操作符`X ptr`指明内存单元的长度,X可以为word或byte,例如`mov word ptr ds:[0], 1`,`inc byte ptr [bx]`。但是`push [1000H]`只进行字操作!!!**
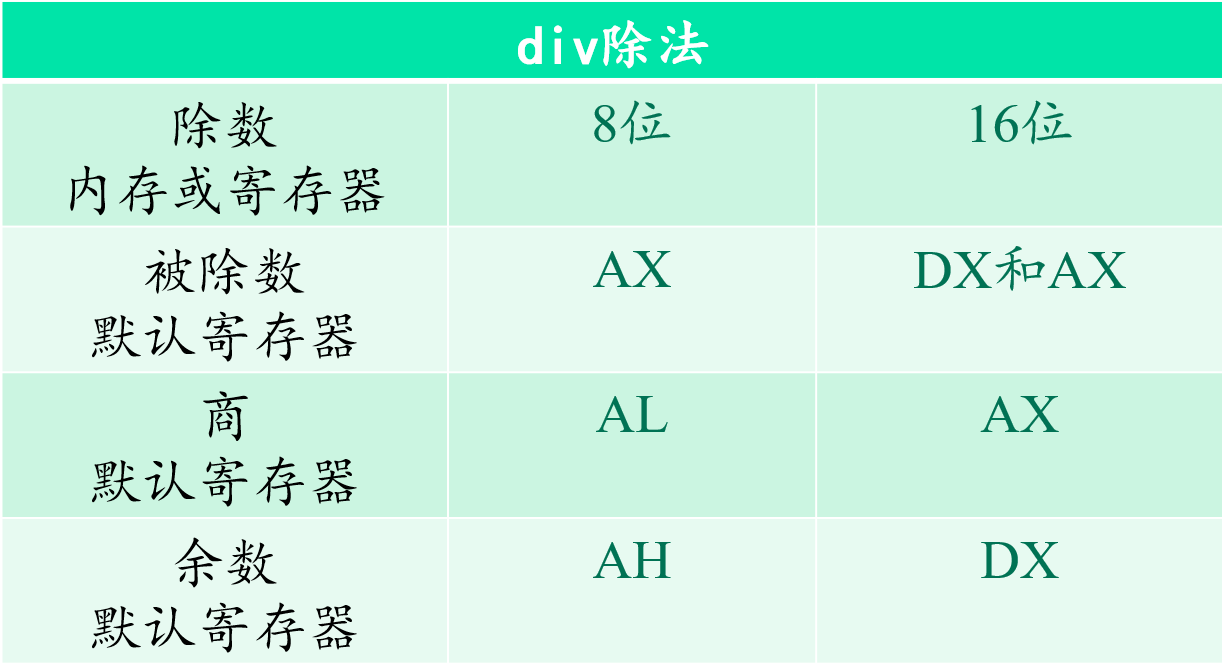
div除法指令
举例说明:
div byte ptr ds:[0]:其中ds:[0]指向的字节为除数,al保存(ax)/((ds)*16+0)的商,al保存(ax)/((ds)*16+0)的余数div word ptr es:[0]:其中es:[0]指向的字为除数,ax保存[(dx)*10000H+(ax)]/((es)*16+0)的商,dx保存[(dx)*10000H+(ax)]/((es)*16+0)的余数。
利用除法指令计算100001/100 1 2 3 4 5 6 7 8 9 10 11 assume cs:code code segment mov dx, 1H mov ax, 86A1H mov cx, 100 div cx mov ax, 4c00H int 21H code ends end
伪指令dd db是字节数据,dw是字型数据,dd是双字型数据。
Q&A
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 assume cs:code, ds:data data segment dd 100001 dw 100 dw 0 data ends code segment start: mov ax, data mov ds, ax mov dx, ds:[0] mov ax, ds:[2] div word ptr ds:[4] mov ds:[6], ax mov ax, 4c00H int 21H code ends end start
dup指令 编译器识别的指令,与db,dw,dd搭配使用,来进行数据重复。例如:
db 3 dup(0)相当于db 0,0,0。db 3 dup(0,1,2)相当于db 0,1,2,0,1,2,0,1,2ndb 3 dup ('abc','ABC')相当于db 'abcABCabcABCabcABC'
Time: 2023-2-21
0x03 转移指令原理 jmp ax只改变ip=ax,而jmp 1000:0改变cs=1000且ip=0。
短转移的ip修改范围为-128~127,近转移的ip修改范围为-32768~32767。
offset操作符 编译器处理的符号,功能是取得标号的偏移地址 。如下举例:
Q&A
1 2 mov ax, cs:[si] mov cs:[di], ax
jmp指令
jmp short 标号,实现段内短转移,IP的修改范围为-128~127。
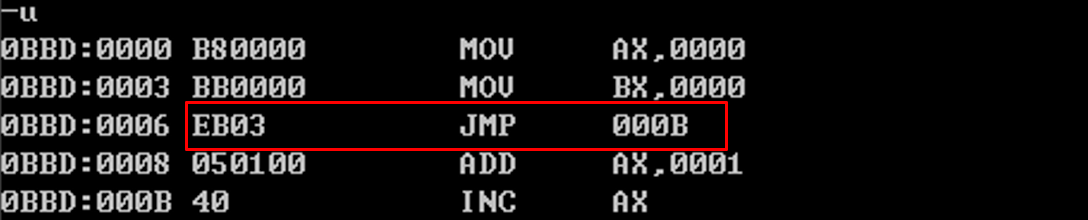
jmp跳转原理 考虑如下问题,给出两个程序,分别如下:
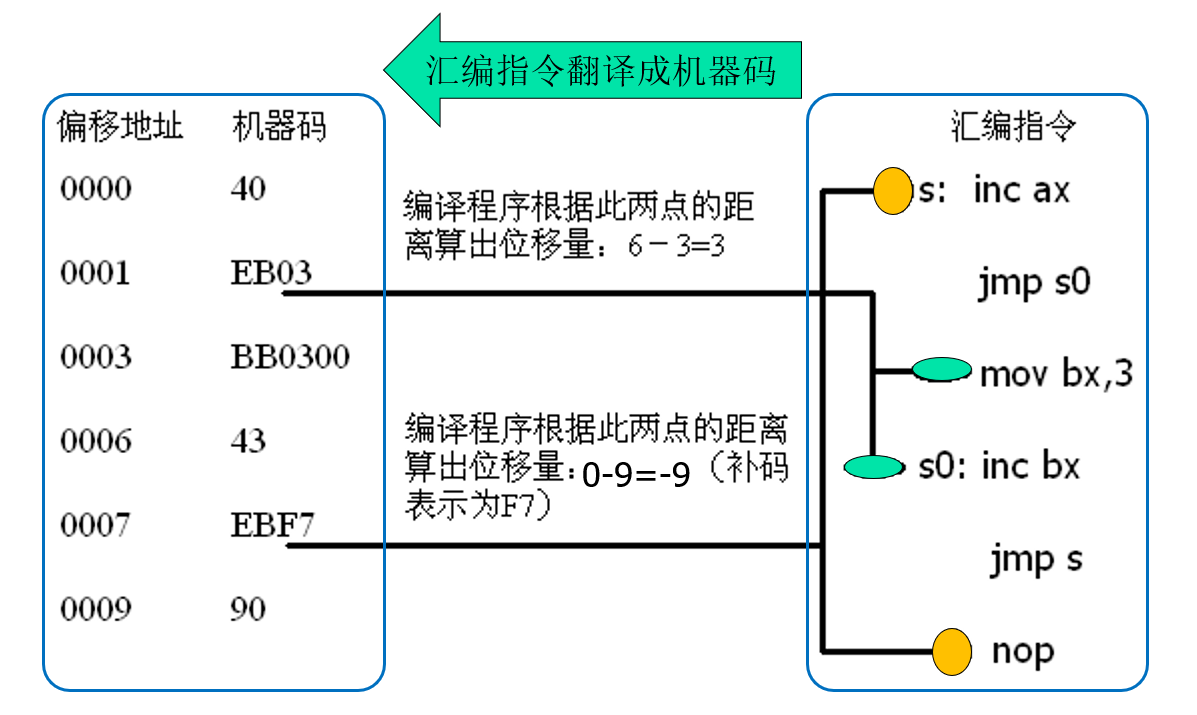
两个程序的不同仅仅是第2个程序加入了mov bx, 0。我们比较两个程序在debug中的汇编与机器码:
可以看到,第一个程序jmp short s编译成了jmp 0008,第二个程序编译成了jmp 000b,但是机器码都是EB03,这是为啥??
我们首先按照第2个程序分析jmp short s的执行流程:
cs=0BBD,ip=0006,将机器码EB03读入指令缓冲器。ip变为0008。
CPU执行EB03。
执行后ip变为000B(因为EB03中03的缘故,所以000B=0008+3=000B)。
那么不用多说,问题得到了解答。如下图所示:
段内近转移 jmp near ptr 标号,实现了段内近位移,范围为-32768~32767。
段间转移(远转移) jmp far ptr 标号,cs是标号所在段的段地址,ip为标号在段中的偏移地址。
转移地址在内存中 jmp word ptr 内存单元地址(段内转移),内存单元开始的一个字,修改ip为这个字。
jmp dword ptr 内存单元地址(段间转移),内存单元开始的2个字,高地址的字为段地址,低地址的字为偏移地址。
Q&A
1 2 mov [bx], bx mov [bx+2], cs
jcxz指令 条件转移指令,所有的条件转移指令都是短转移,也就是-128~127。
jcxz 标号,如果cx=0,则转移到标号处执行。
Q&A
1 2 3 4 mov cx, 0 mov cl, ds:[bx] jcxz ok inc bx
loop指令 loop不详细说,循环指令也是短转移。
Q&A