Assembly_1
汇编语言学习笔记-1
0x00 存储器的存储结构
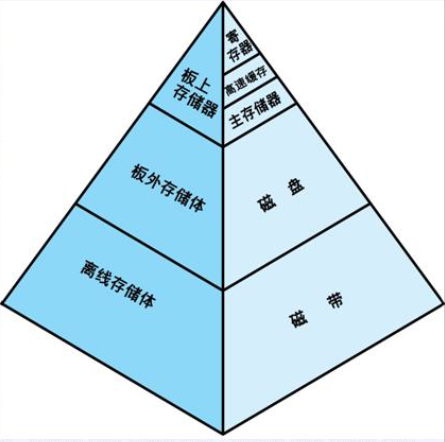
1TB=1024GB,1GB=1024MB,1MB=1024KB,1KB=1024B,1B=1字节(8位)。
CPU想要对存储介质上的数据进行操作,就必须通过总线,总线分为地址总线、控制总线、数据总线。例如,CPU在内存中读数据,图示如下:
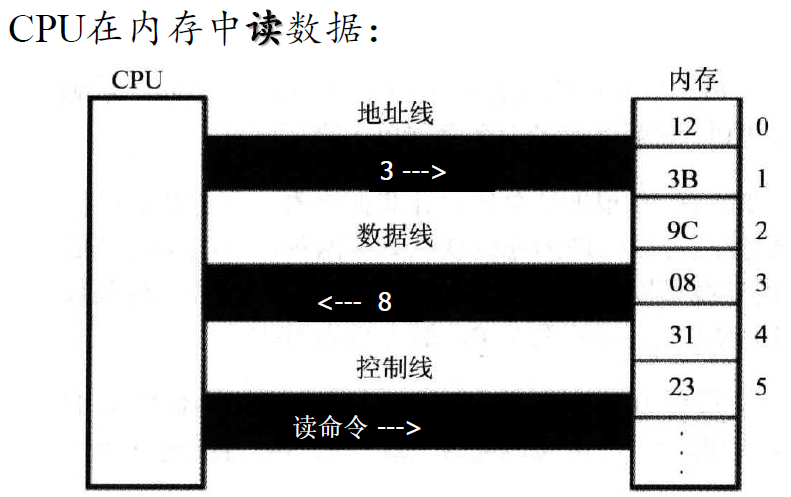
可以看到,CPU是通过地址总线来指定存储单元的。地址总线上能传送多少个不同的信息, CPU 就可以对多少个存储单元进行寻址。如果一个 CPU 有 N 根地址总线,即地址总线宽度为 N,那么就可以寻址2^N个内存单元。
数据总线宽度关系到了 CPU 和外界的数据传送速度。下面展示了8位和16位数据总线在传输0x89D8时候的不同:
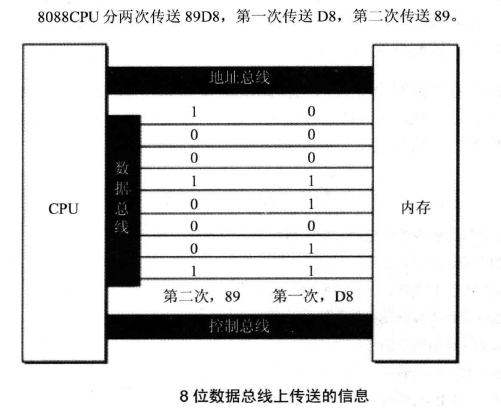
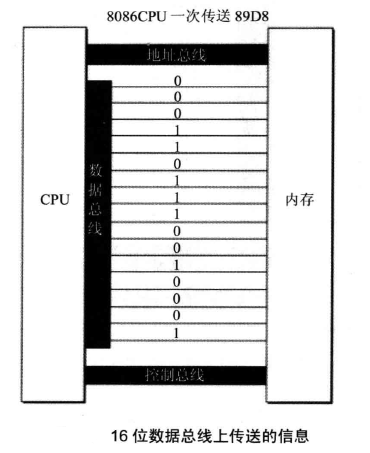
可以看到,8位需要传两次,16位传一次即可。
小结:
- 每一种 CPU 都有自己的汇编指令集。
- 一个存储单元可以存储 8 个 bits,即 8 位二进制数。
0x01 内存地址空间
什么是内存地址空间?一个 CPU 的地址线宽度为 10 ,那么可以寻址 1024 个内存单元,这 1024 个可寻到的内存单元就构成这个CPU 的内存地址空间。
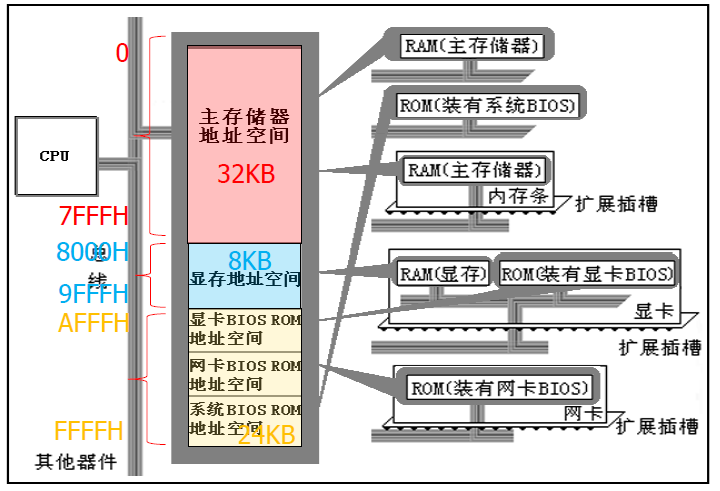
存储器包括随机存储器(RAM)与只读存储器(ROM)。随机存储器可读可写,但是关机后储存内容就会消失。只读存储器只能读取,关机后储存内容不会消失。例如,BIOS就储存在ROM中。这和磁盘什么的没啥关系哈,RAM与ROM都是主板上的。
可以将各类存储器看作一个逻辑存储器。如下图所示:
0x02 寄存器
CPU由运算器 、 控制器 、 寄存器组成,内部总线实现 CPU 内部各个器件之间的联系,外部总线实现 CPU 和主板上其它器件的联系。
8086CPU 所有寄存器都是 16 位 ,可存放两个字节,AX、BX、CX、DX被称为通用寄存器。8086 上一代 CPU 中的寄存器都是 8 位的,为保证兼容性,AX可以分为AH与AL。BX、CX、DX也可以这样分。
字节为8位,字为16位(2个字节)。
以下是简单的汇编指令举例:(注:汇编指令不区分大小写)

再来看两个特殊情况:
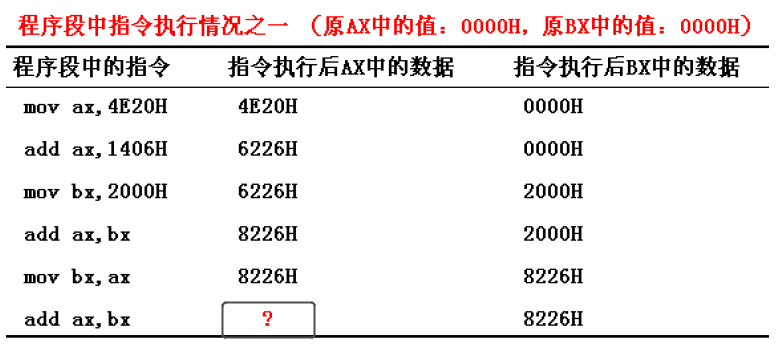
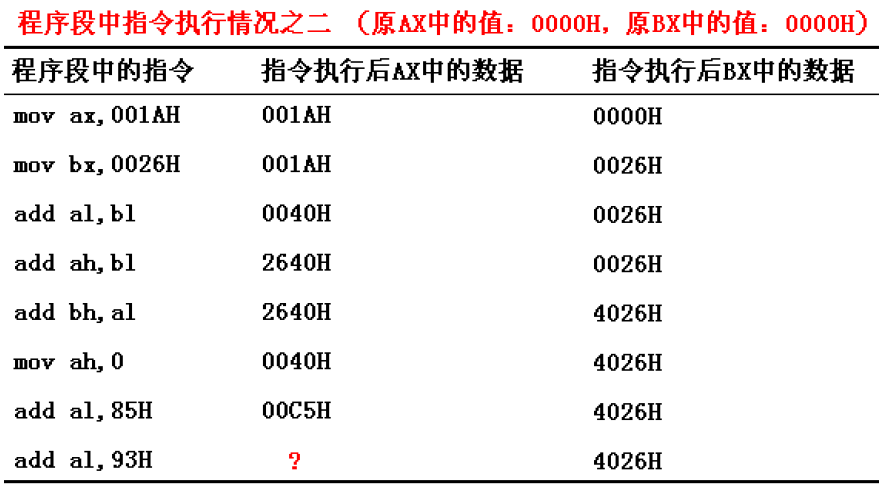
可以看到,上述两个图中的红色问号部分都有进位,不同的是第一个图是AX的进位,第二个图是AL的进位。第二张图中,此时CPU 把 al 和 ah 看作 8 位的寄存器上的独立的寄存器,产生的进位不会存储在 ah 中。第一张图也是类似,因此,第一张图中的问号填044CH,第二张图的问号填58H。
16位结构的CPU体现在哪里?
- 运算器一次最多可以处理 16 位的数据。
- 寄存器的最大宽度为 16 位。
- 寄存器和运算器之间的通路是 16 位的。
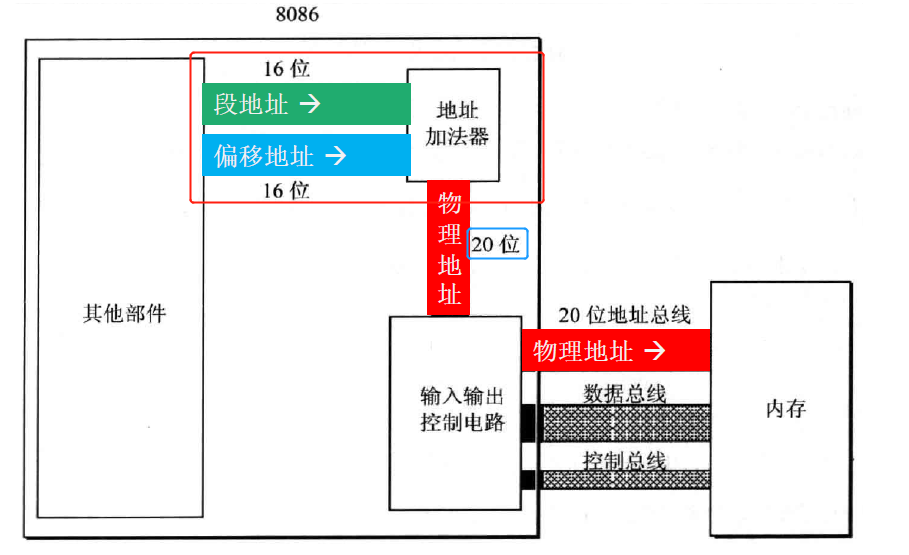
8086CPU是如何找物理地址的?
存在这样一种矛盾,8086 有 20 位地址总线,可传送 20 位地址,寻址能力为 1MB 。而8086 内部为 16 位结构,它只能传送 16 位的地址,表现出的寻址能力却只有 64KB 。为解决这种矛盾,8086CPU 采用一种在内部用两个16 位地址合成的方法来形成一个 20 位的物理地址。具体公式为:
1 | 物理地址 = 段地址 × 16 + 偏移地址 |
图像解释如下:
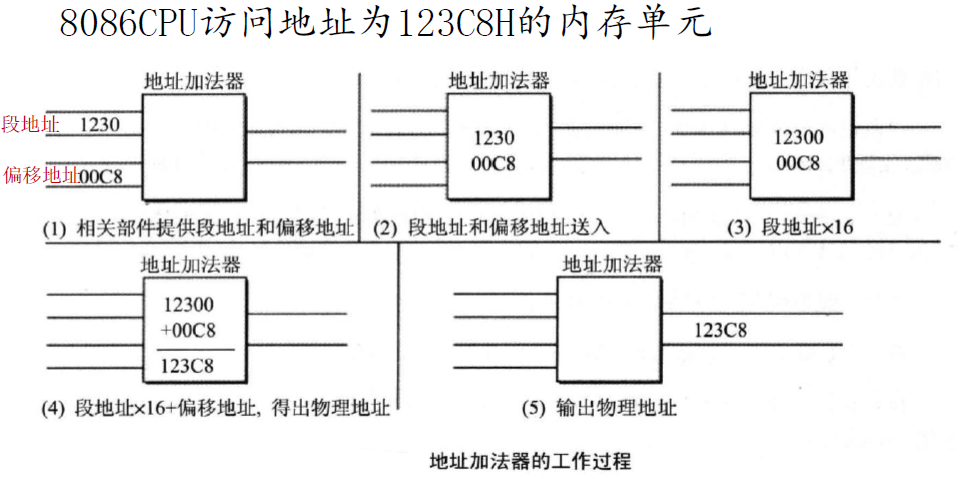
分段
内存并没有分段,段的划分来自于 CPU(就是因为上面的公式)。
- 段地址 × 16 必然是 16 的倍数,所以一个段的起始地址也一定是 16 的倍数。
- 偏移地址为 16 位, 16 位地址的寻址能力为 64K,所以一个段的长度最大为 64K 。
再给出如下结论:
- CPU 可以用不同的段地址和偏移地址形成同一个物理地址 。如下所示:

- 偏移地址 16 位,变化范围为 0-FFFFH ,仅用偏移地址来寻址最多可寻 64K 个内存单元。例如,给定段地址 1000H ,用偏移地址寻址 CPU 的寻址范围为: 10000H-1FFFFH 。
段寄存器
段寄存器就是提供段地址的。8086CPU中有 4 个段寄存器:CS、DS、SS、ES。
CS(代码段寄存器 )和 IP(指令指针寄存器 )是8086CPU 中最关键的寄存器,它们指示了 CPU 当前要读取指令的指令地址。具体可以看《汇编语言第三版》P26-P31。最终,可以总结出8086CPU的工作流程:
- 从 CS:IP 指向内存单元读取指令,读取的指令进入指令缓冲器;
- IP = IP + 所读取指令的长度 ,从而指向下一条指令;
- 执行指令。 转到步骤 1 重复这个过程。
8086CPU刚刚开机时,CS=FFFFH,IP=0000H,所以CPU 从内存 FFFF0H 单元中读取指令执行,这是开机后执行的第一条指令 。内存中指令和数据没有任何区别,都是二进制信息,但是CPU将 CS:IP 指向的内存单元中的内容看作指令。
控制CS:IP跳转到目标地址
在CPU中,程序员能够用指令 读写的部件只有寄存器,程序员可以通过改变寄存器中的内容实现对CPU的控制。
- 同时控制CS与IP。

- 仅仅控制IP。可以看到直接
jmp ax控制的其实是偏移地址。

注意:jmp ax等价于mov IP, ax。jmp 3:01B6等价于mov cs, 3; mov ip, 01B6。你懂得~
Q&A
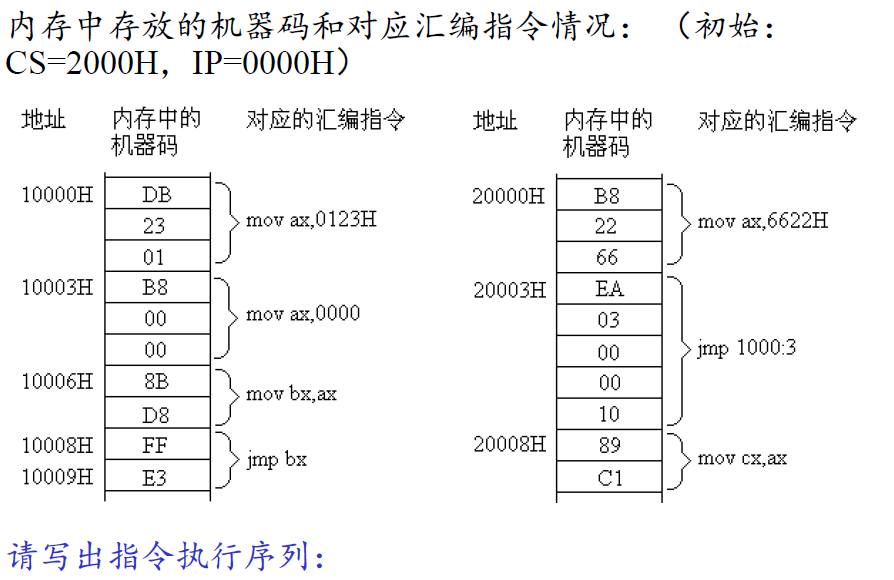
1 | mov ax, 6622H |
代码段
CS:IP指向的内容就是代码段。就类似于上述的Q&A中的示例,就是代码段。代码段举例(123B0H-123B9H):

可以认为上述代码是段地址是123BH,长度为10字节的代码段。
0x03 实验 1
见《汇编语言第三版》P35。
补充:
- Debug是DOS、Windows提供的调试工具,可以查看CPU寄存器中的内容。
- Debug常用命令。
1 | R // 查看、改变寄存器中的内容 |
查看并修改寄存器中的内容:
查看内存0AD40H及其之后的内容:

改写内存10000H的内容:
一块修改

逐位修改

写入字符串

写入机器码并展示

执行刚刚写入的机器码(需要预先修改CS与IP)

直接写入汇编指令
0x04 寄存器(内存访问)
小端序与大端序,如下图所示:

之前我们知道:物理地址 = 段地址 × 16 + 偏移地址。代码段的短地址保存在CS寄存器中,数据段的段地址保存在DS寄存器中。
使用mov指令可以读取内存,其格式为mov 寄存器名 [address],其中address为偏移地址,执行此命令时,8086CPU会自动取DS作为段地址。
内存到寄存器。使用mov指令从10000H中读取1个字节放到AL中:
1 | mov bx, 1000H |
注:8086CPU不支持将数据直接送入段寄存器的操作,而物理地址10000H可以看作段地址:偏移地址=1000H:0H。
寄存器到内存差不多,举一个例子:

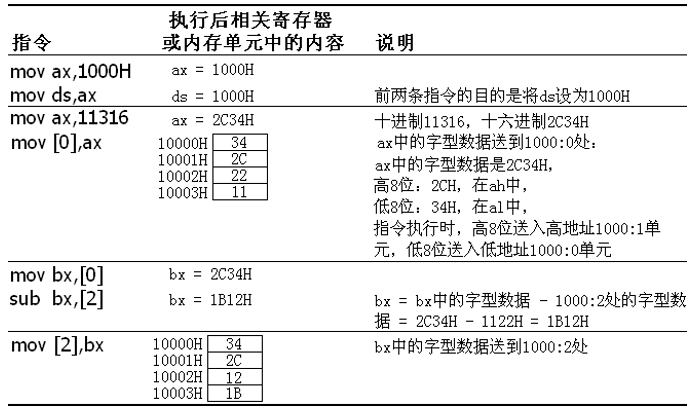
对于8086CPU来说,累加123B0H的前三个单元的数据:
1 | // 累加字节数据 |
0x05 栈
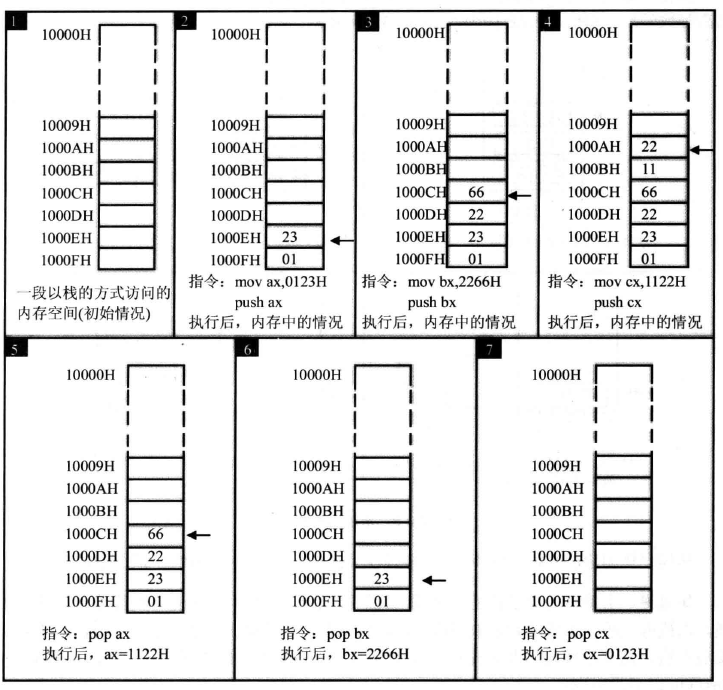
8086CPU的入/出栈操作都是以字(两个字节)为单位进行的。栈的增长方向是由高地址往低地址。栈操作举例:
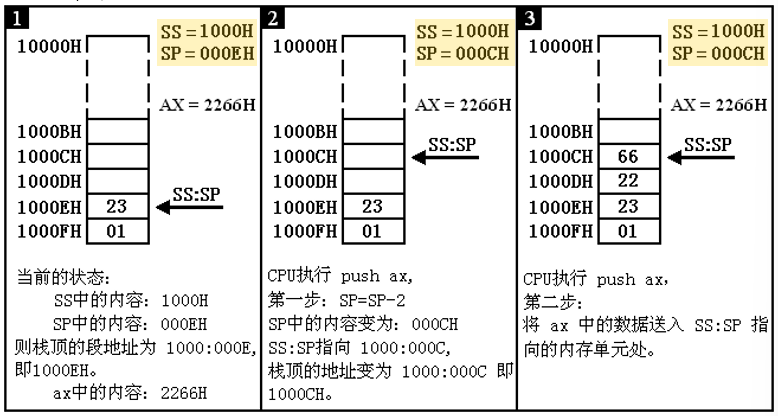
类似于CS:IP,存放着指令的段地址与偏移地址,SS:SP存放着栈顶的段地址与偏移地址。SS:Stack Segment、SP:Stack Pointer。
push指令的执行过程,以push ax为例:
SP=SP–2。
将ax中的内容送入SS:SP指向的内存单元处,SS:SP此时指向新栈顶。
pop指令的执行过程,以pop ax为例:
- 将SS:SP指向的内存单元处的数据送入ax中。
- SP = SP+2,SS:SP指向当前栈顶下面的单元,以当前栈顶下面的单元为新的栈顶。
Q&A
Q1:将10000H-1000FH 这段空间当作栈,初始状态是空的,将 AX、BX、DS中的数据入栈。
A1:
1 | mov cx, 1000H |
Q2:将10000H-1000FH 这段空间当作栈,初始状态是空的;设置AX=001AH,BX=001BH;将AX、BX中的数据入栈;然后将AX、BX清零;从栈中恢复AX、BX原来的内容。
A2:
1 | mov cx, 1000H |
Q3:将10000H-1000FH 这段空间当作栈,初始状态是空的;设置AX=002AH,BX=002BH;利用栈 ,交换 AX 和 BX 中的数据。
A3:
1 | mov cx, 1000H |
Q4:我们如果要在10000H处写入字型数据2266H,可以用以下的代码完成:
1 | mov ax, 1000H |
补全下列代码,完成同样功能。(不能使用mov [内存单元],寄存器)
1 | ________ |
1 | mov ax, 1000H |
push、pop 实质上就是一种内存传送指令,可以在寄存器和内存之间传送数据,与mov指令不同的是,push和pop指令访问的内存单元的地址不是在指令中给出的,而是由SS:SP指出的。同时,push和pop指令还要改变 SP 中的内容。
0x06 实验2
Debug的使用技巧:


注:Debug的T命令(运行一条汇编语句)在执行修改寄存器SS的指令时,下一条指令也紧接着被执行。
0x07 第一个程序
流程:
- 编写汇编源程序。
- 对源程序进行编译连接。使用汇编语言编译程序对第一步的源程序进行编译,产生目标文件。再用连接程序对目标文件进行连接,生成可执行文件。
- 运行可执行文件。
示例程序分析
给出如下程序:
1 | assume cs:codesg |
汇编语言程序中包括汇编指令与伪指令。伪指令不被CPU执行,是由编译器来执行,编译器根据伪指令来进行相关的编译工作。
上述程序的伪指令有:
段名 segment ... 段名 ends。代表一个段,这个段用来存放代码。end。汇编程序的结束标记,不要与ends搞混。assume将有特定用途的段和相关的段寄存器关联起来,例如assume cs:codesg就是将codesg段与cs段寄存器关联起来,以说明codesg内存放的是代码。
计算2^3的示例程序:
1 | assume cs:abc |
在汇编后加入mov ax, 4c00H; int 21H就可以实现程序返回。在DOS中edit并保存为1.asm。接下来使用masm.exe对文件进行编译,生成1.obj。之后使用1.obj进行连接,使用link.exe生成1.exe。
连接的作用:
源程序很大时,将其分为多个源程序来编译,将源程序编译成目标文件后,再用连接程序将其连接到一起,生成一个exe。
将库文件与目标文件连接起来。

下图展示了DOS系统在.EXE文件中的程序加载过程:
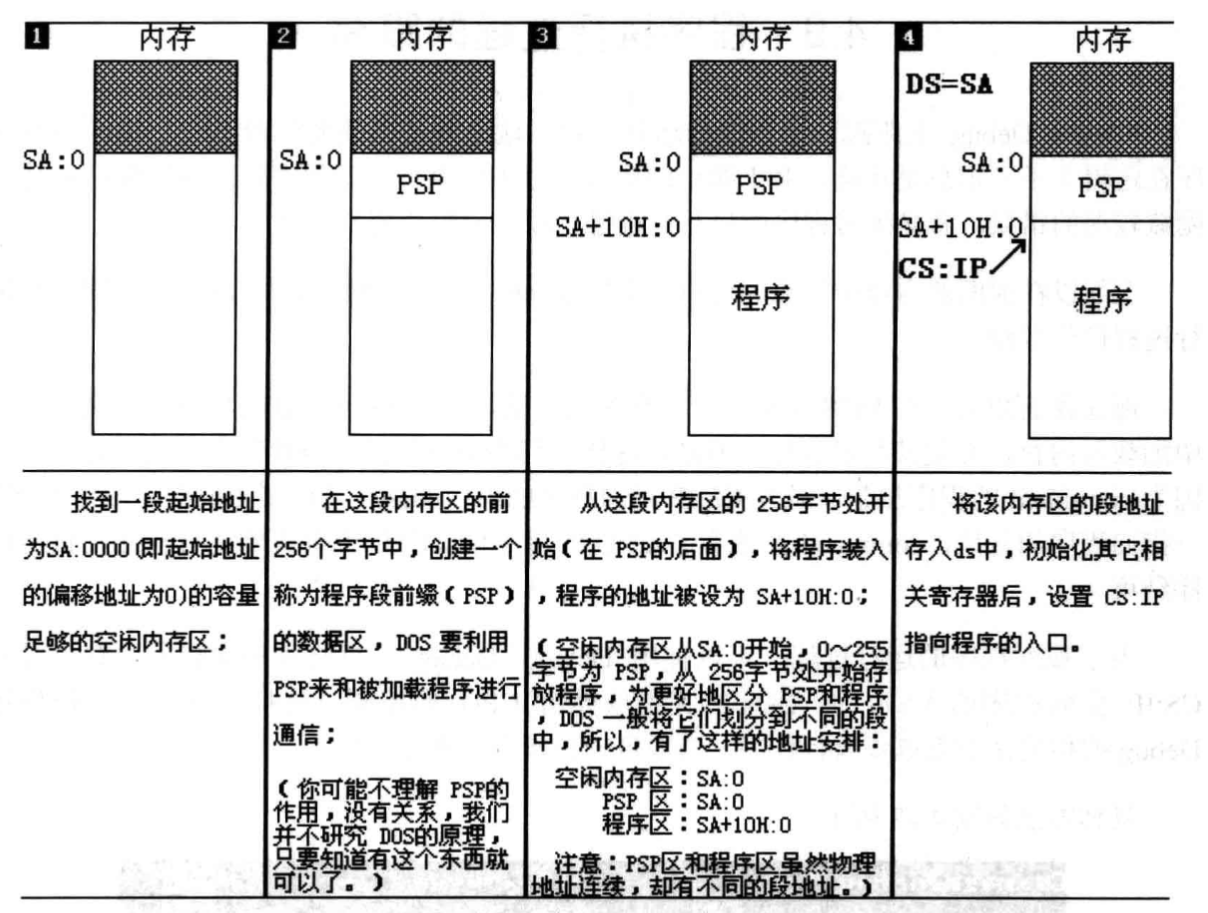
- 程序加载后,ds存放程序内存区的段地址,内存区偏移地址为0,程序所在内存区的地址为
ds:0。 - 内存区的前256字节存放PSP(DOS用来和程序来进行通信),从256字节处向后的空间存放的是程序。
调试显示:

DS=0B14可以看到PSP的段地址SA=0B14,PSP的偏移地址为0,因此PSP的物理地址为SA*16+0,程序的物理地址为SA*16+0+256=SA+10H:0=0B24H,这也是CS指向的地址。
再用u查看一下汇编代码,如下:
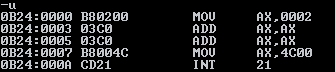
再p单步执行,执行到INT 21,结束。
0x07 [BX]和内存单元的描述
[BX]是什么?
[0]表示一个内存单元时,0表示单元的偏移地址,段地址默认在DS中,而取出数据的长度由具体指令中的接收值的寄存器指出。[BX]也是同理,BX代表单元的偏移地址,其他与[0]类似。
举例题目如下:

答案:
1 | | BE | 21000H |
一些补充
- 我们用
()来表示一个寄存器中的内容,举例mov ax [2]代表(ax)=((ds)*16+2),add ax, bx代表(ax)=(ax)+(bx),push ax代表(sp)=(sp)-2;((ss)*16+(sp))=(ax)。 - 用
idata表示常量。(不能向DS写常量,例如mov DS, 1)
Loop指令
1. `(cx)=(cx)-1`
1. 判断cx中的值是否为0,如果不为0则跳转到标号处执行,否则继续下个下执行。(**cx为循环次数**)
程序示例:

1 | ; 任务1 |
1 | ; 任务2 |
1 | ; 任务3(loop的使用) |
Q&A
- 加法计算123*256,并将结果保存在A X中。
1 | assume cs:addFunc |
- 计算
ffff:0006单元中的数乘3,结果保存在DX中。
1 | assume cs:func |
Debug与Masm的不同处理
Debug中直接用a写入汇编命令:
1 | mov ax, 2000 |
然后在debug中用u命令查看(debug的解释):
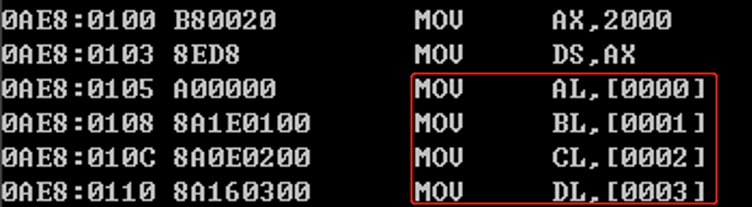
和正常一样,但是如果用edit来写汇编程序的话(编译器的解释),代码如下:
1 | assume cs:code |
结果如下图所示(怎么与程序写的不一样???):
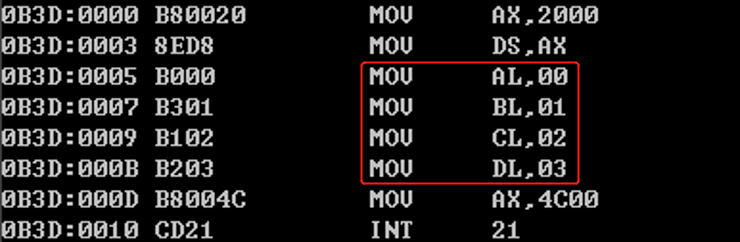
那我们如何避免呢?那就需要这么写:
1 | assume cs:code |
或者这么写:
1 | assume cs:code |
Q:计算ffff:0-ffff:b单元中的数据的和,结果存储在dx中
A:
1 | assume cs:func |
安全空间
- DOS方式下,
0:200-0:2FF空间中没有系统或其他程序的程序,可以放心使用,其他的不确定,有可能存放重要代码。 - 将内存
ffff:0-ffff:b单元中的数据拷贝到0:200-0:20b单元中:
1 | assume cs:code |
改进如下:
1 | assume cs:code |
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!