chatbot
chatBot
0x00 RNN & LSTM & GRU
标准RNN结构如下图所示:
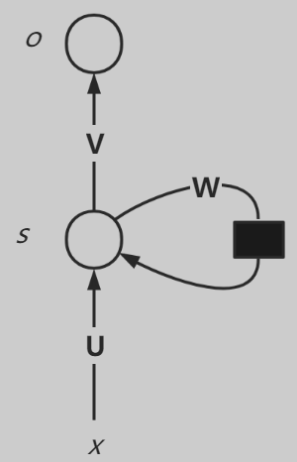
其中输入为x,隐藏层为s,输出层为o,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,还有一个自循环矩阵W。上图展开可得到下图:
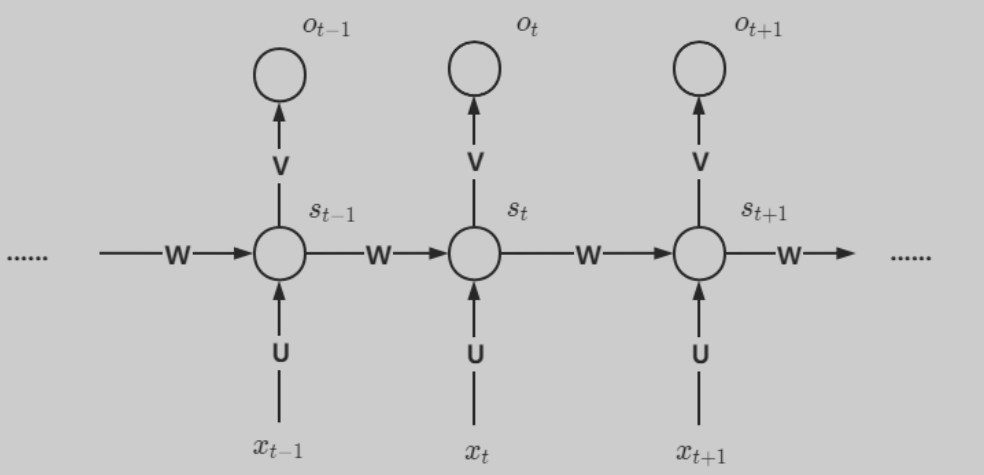
隐藏层s可以细化为:
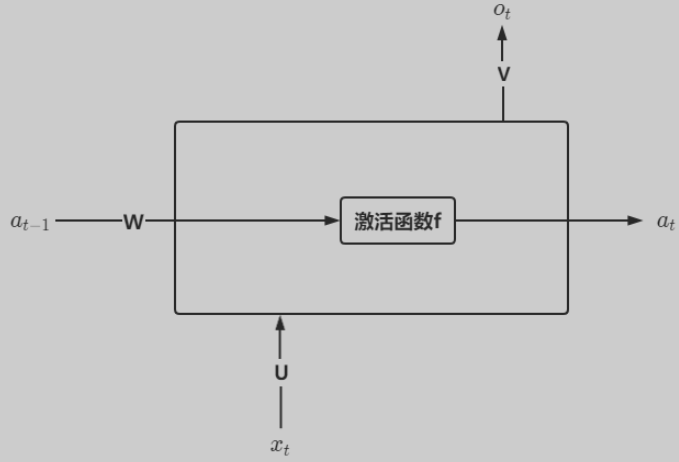
根据上述结构,对RNN进行深度化,就可以得到深层循环神经网络。
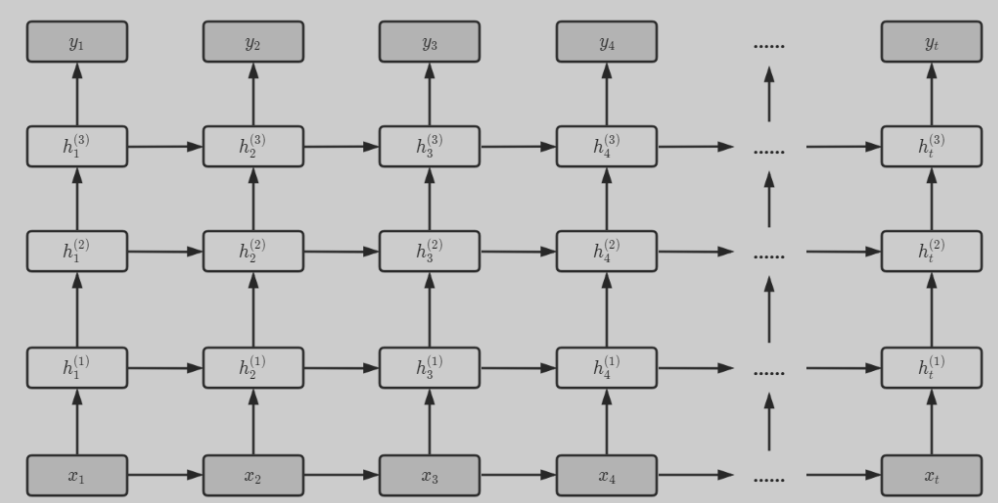
但是RNN有一个问题,即容易造成梯度消失或梯度爆炸问题,这就说明RNN不具备长期记忆,仅仅有短期记忆功能。因此LSTM应运而生。网络结构如下:
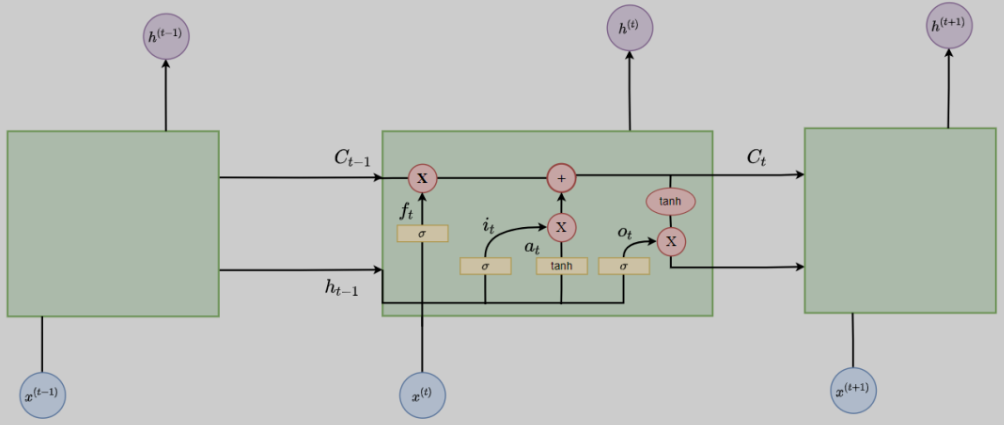
LSTM每一个时刻t都增加一个隐藏状态C(细胞状态),并用两个门来控制它的内容:
- 遗忘门(Forget Gate),决定上一时刻的细胞状态C_{t-1}有多少保留到当前时刻细胞状态C_t。
- 输入门(Input Gate),决定当前时刻网络的输入x有多少保存到细胞状态C_t。然后再用输出门(Output Gate)来控制当前细胞状态C_t有多少输出到当前输出值h。
但是,LSTM复杂度较高,由此又有了GRU,其是LSTM的v2版本。
上述所说的RNN、LSTM与GRU都是处理序列数据,但是利用的一般是前文信息,但是实际上很多场景都需要结合上下文才能综合判断,因此提出了双向循环神经网络。
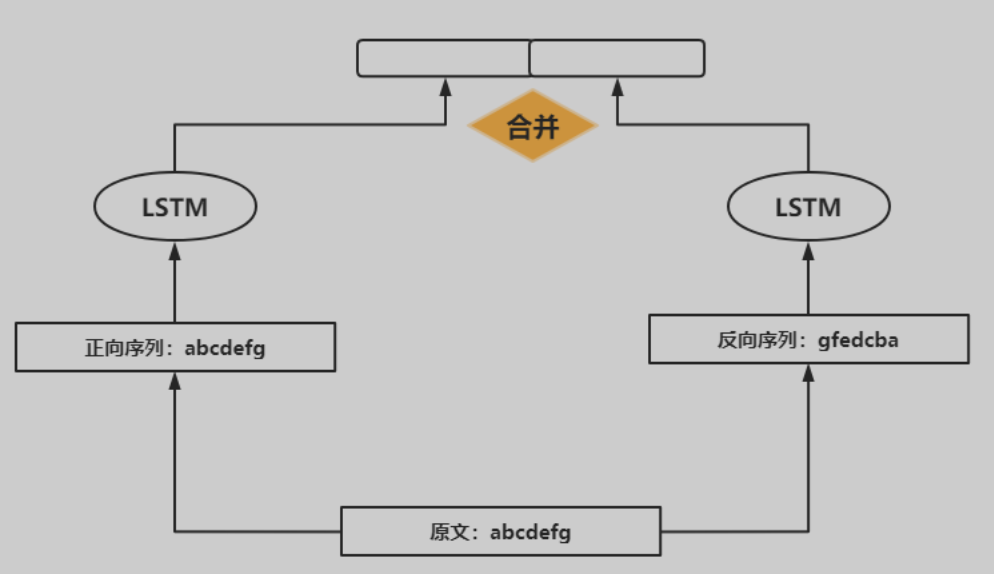
左边的是正向序列信息,LSTM模型利用上文信息;右边的是反向序列信息,LSTM模型利用下文信息。接着将两个模型输出合并,得到整个模型的输出。
循环神经网络可以实现语言翻译、问答系统等,基于此网络构建的典型模型是Encoder-Decoder模型。
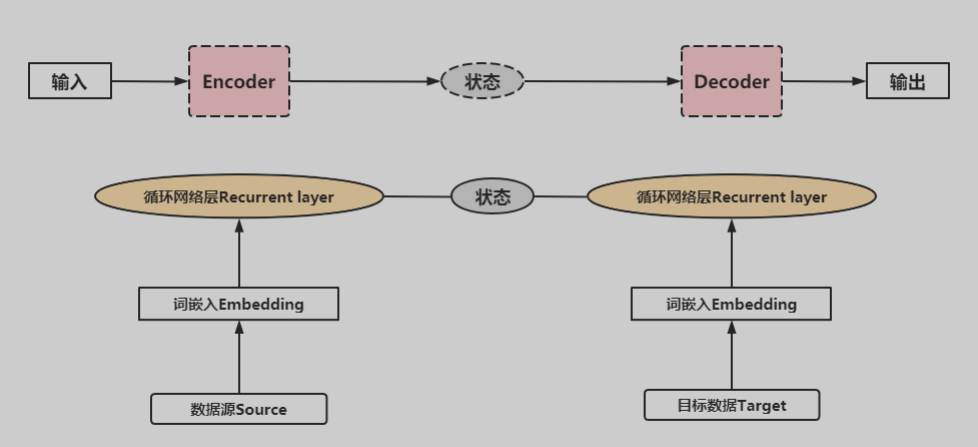
对于自编码模型可以理解为:从左到右,看作由一个句子(文章,段落等)生成另外一个句子(文章或段落)的通用处理模型。对于输入与输出都是序列的自编码模型,称之为Seq2Seq模型。
0x01 注意力机制(AM)
引用:https://blog.csdn.net/qq_27388259/article/details/120878477
0x00所说的Seq2Seq模型,无法应对句子很长的情况,于是注意力机制模型应运而生。注意力机制本质就是:输出句子中某个单词和输入句子中每个单词的相关性。如下图所示:
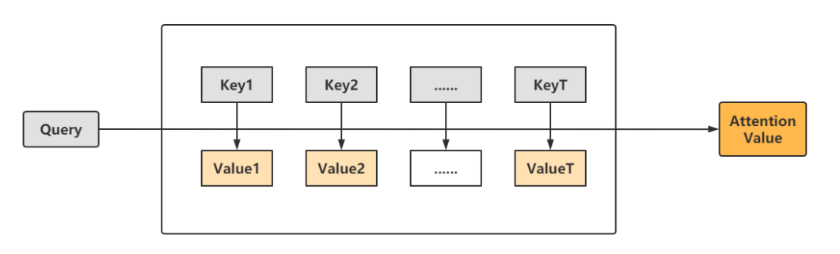
上图中,key就是输入的每一个单词,value是这些单词对应的取值,
给定一个query,计算其与各个key的相似度,得到权重系数,最后得到attention value值。对上述过程进行细分,可以分为:计算相似度、归一化处理、计算注意力3个部分。
0x01.1 计算相似度
三种度量相似度的方式:闵可夫斯基距离、余弦相似度和核函数,当然也可以自己构造相似度。
0x01.2 归一化处理
得到了相似度s_i,之后进行归一化处理(一般使用softmax函数):
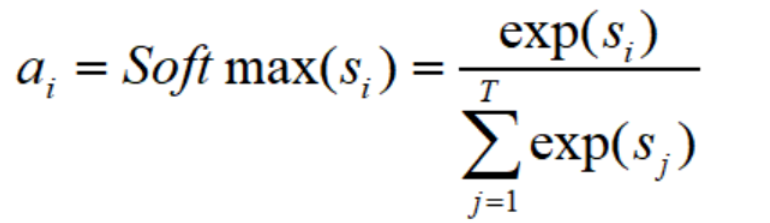
0x01.3 计算注意力
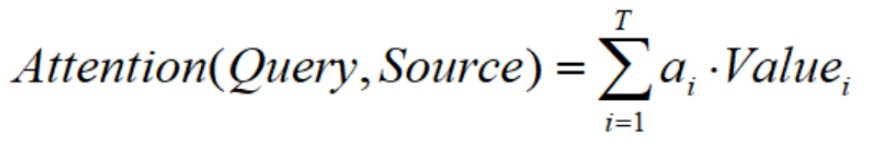
对比一下,不带注意力机制的Encoder-Decoder是这样的:
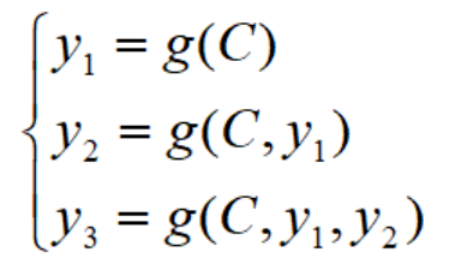
其中,C代表输入X放入Encoder之后编码成的中间向量,y代表输出的值,g代表Decoder。
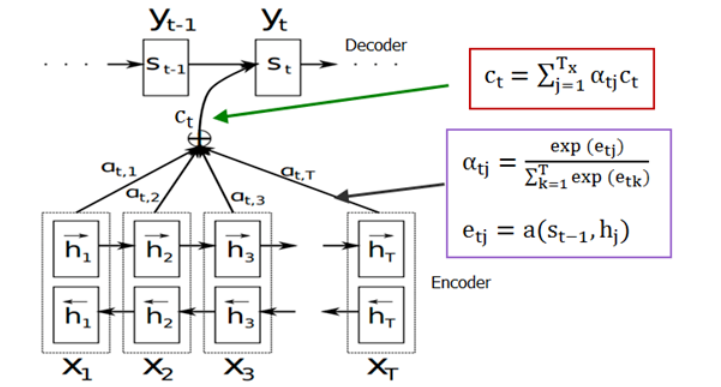
带注意力机制的Encoder-Decoder是这样的:
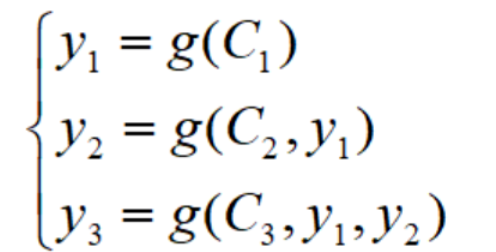

但是每句话输入长度不一样啊,这个矩阵的T不是固定的,那么模型是如何确定权重系数矩阵的呢?它是通过对齐函数F来获得目标单词和每个输入单词对应得对齐可能性,然后经过softmax函数进行归一化得到注意力分配概率分布数值。
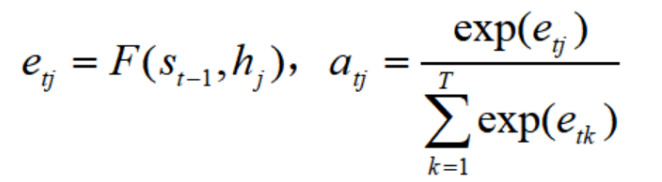

再加入双向循环网络结构,最终结构如下:
0x02 最终项目
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!