pyc-analyze
pyc文件的分析
参考blogs:CataLpa师傅的https://wzt.ac.cn/2019/02/13/pyc-simple/
0x00 pyc简介
某些情况下,反编译 pyc 可能会失败,造成失败的原因有很多,最常见的就是将 pyc 中的结构、byte-code或者一些逻辑进行修改和混淆,甚至会修改 python 的源代码来自定义 opcode。
实际上, pyc 文件所存储的主体就是 python byte-code 另外还有一些必要的结构。为什么会存在 pyc 文件呢?这就回到了之前的问题上,即 python 运行速度慢,由于计算机无法理解高级语言,我们写的代码必须先被编译成计算机能识别的机器码才能被执行,python 也是一样,不过开发者在机器底层和源代码之间加了一层虚拟机,将许多底层硬件细节进行了封装和屏蔽,使得程序员可以专注于自己的代码逻辑上面,这样也造成了一些弊端,python 程序通常以 .py 为后缀名,其内容就是开发者所编写的源代码,所以,每次运行程序的时候,都需要先编译再执行,当项目代码成千上万行时,如果每次运行都需要编译,那么效率可想而知。
为了解决这个问题。python 的开发者提出了一个很好的解决方案,将一个 python 程序会使用到的模块先编译成 pyc 文件,之后再调用的时候,即可省去编译的时间,提高程序效率。这里的 pyc 文件实际上就是 python 模块的预编译文件。
0x01 pyc格式解析
生成pyc文件python -m xxx.py。
例子:自己写了一个test.py
1 | def hello(): |
转成pyc并使用010editor打开,得到:
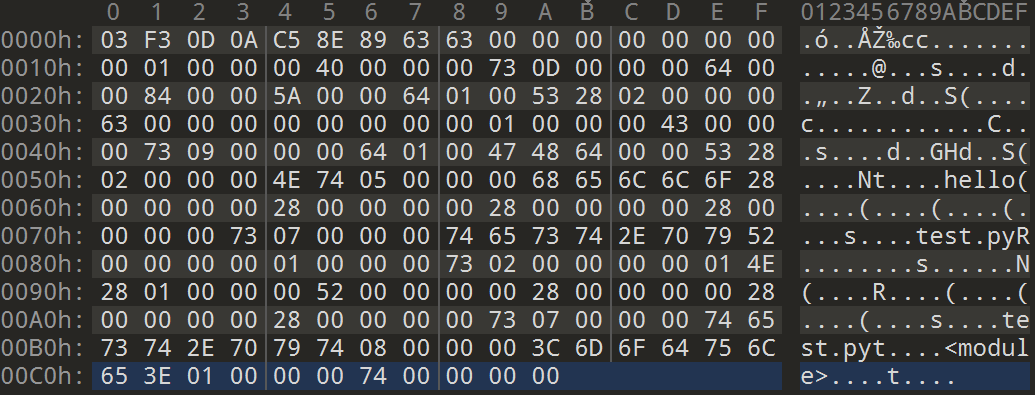
010editor解析如下:
前四个字节是pyc的magic value,前两个字节是可变的,它和编译 python 文件的 python 版本有关,接下来两个字节是固定的 0D0A,转换成 ASC 码就是 \r\n,所以如果一个 pyc 文件被以文本形式打开复制到另一个文件中,新文件一般是不会正常工作的,这也是 pyc 的一种简单保护手段。
接下来四个字节是char mtime,它也占据 4 个字节。这个字段表示该 pyc 文件的编译日期,用 unix 时间戳来表示,由于字节的小端序,要反过来看,例如我这里的文件时间戳是 63898EC5,那么转换成真正的时间就是 2022/12/2 13:36:5。
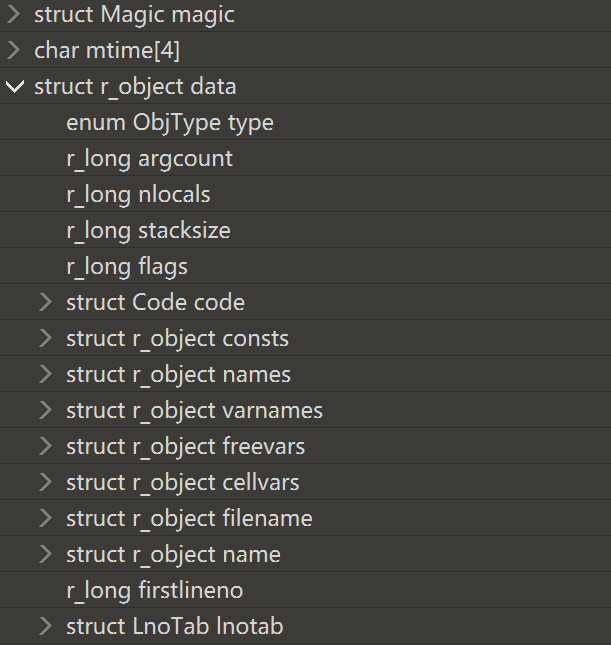
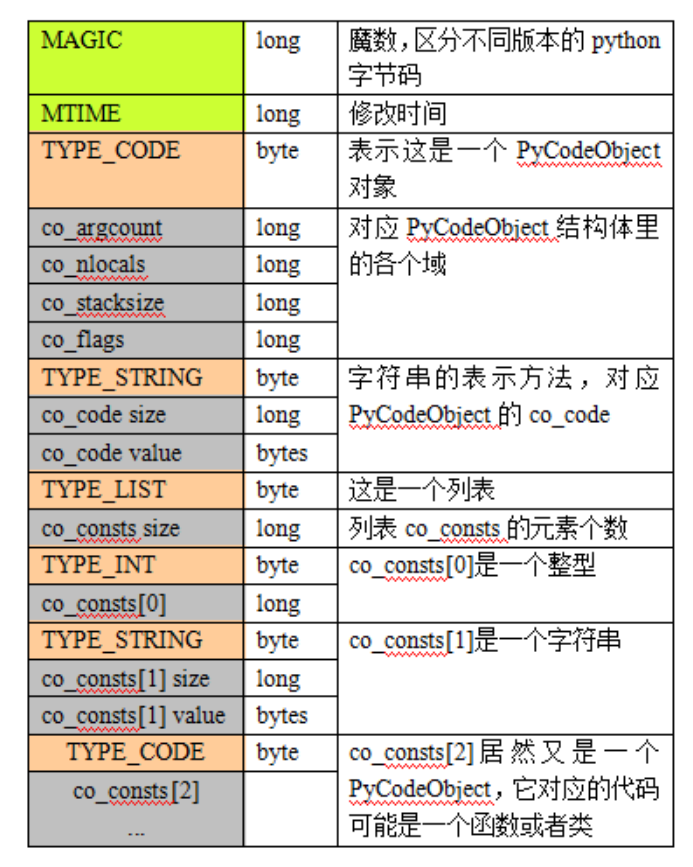
然后就是 pyc 文件的主体部分了,通常叫做struct r_object data,打开之后里面有很多内容。首先是 enum ObjType type(CODE_CODE),占 1 个字节,用它来表示一个 PyCodeObject 开始了。
0x02 PyCodeObject解析
PyCodeObject 包含许多小的组成成部分,这些小部分称为 PyObject。
PyObject 第一个字节指明了接下来的内容是什么类型,例如 0x63 就表示后面跟着的是 CODE_CODE,或者 0x28 就表示后面跟着的是常量列表等等,这里有一份定义类型的源代码。
1 | //Python/marshal.c:22 |
除了 CODE_CODE,还有其他的字段:
1 | argcount 参数个数 |
我们主要关注字节码,字节码类似于机器码,可以通过一定的手段将它们转换成类似于汇编语言的可读代码,这里我们需要用到 python 自带的模块 dis。
编写如下脚本:
1 | import dis |
上述脚本主要是分析struct Code code中的字节码:
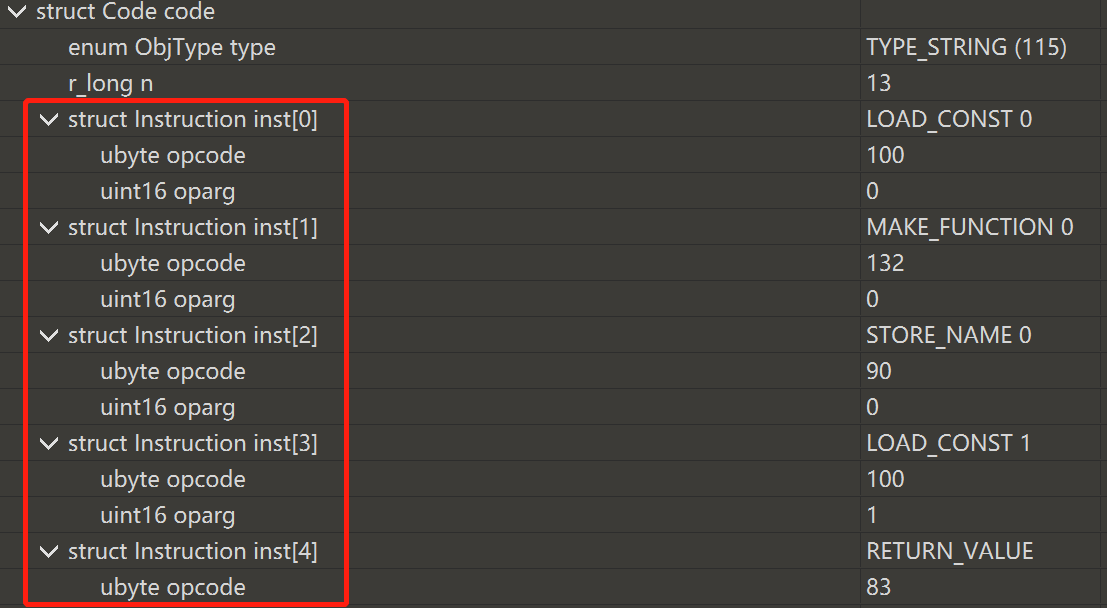
输出为:(从左到右分为四列,第一列代表字节偏移量,第二列是指令操作码的含义,第三列是操作数,第四列是操作数的说明。)
1 | 0 LOAD_CONST 0 (0) |
简单程序的字节码容易分析,但是如果一个大型程序被编译成了 pyc 文件,就难以分析了。
除了CODE_CODE的PyObject,还有其他的PyObject,本例还有:
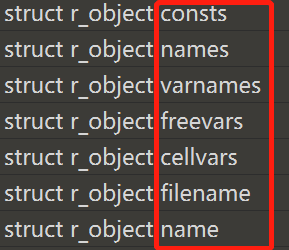
这些部分的结构大同小异,就不一一分析了。
这里有一份 PyCodeObject 的具体定义,感兴趣的同学可以仔细看看。
1 | //Include/code.h |
一个 pyc 文件里面可能包含很多的 PyCodeObject,实际上,一个 PyCodeObject 的定义范围是有限的,例如一个函数就定义在一个 PyCodeObject 里面,一个类、闭包等等都分别定义在不同的 PyCodeObject 里。如下图:
0x03 pyc字节码的处理
保护 python 程序难度很高,因为 python 程序的载体 .py 就是源代码文件,虽然有 pyc 这种不能直接看懂的文件,但是由于 uncompyle6 这样的神器存在,解析它也不在话下,目前保护 python 程序的思路一般是对变量名进行混淆,或者操作 pyc 文件混淆字节码,显然后者的效果要更好一些。
python 也好 C 语言也罢,万变不离其宗,python 的字节码处理其实和混淆一个 exe 程序类似,简单的包括跳转混淆、控制流混淆,复杂一些的可能涉及 byte-code 加密等等。
我们拿出最简单的一种方法分析,通过强制跳转干扰反编译器的工作。
首先要了解一些字节码的知识,可以用下面的代码获取你当前版本的 python 字节码表:
1 | import opcode |
在 pyc 文件中,字节码的格式一般是 opcode + 操作数,如果想要利用强制跳转实现字节码混淆的话,首先要找到强制跳转的字节码,我的机器上这条指令字节码是 0x71,我们会尝试构造这种结构。
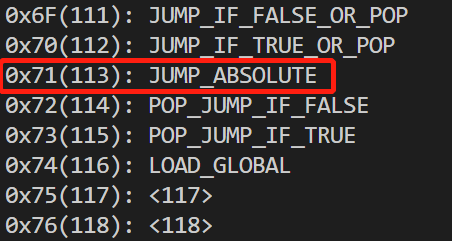
这种结构如下:
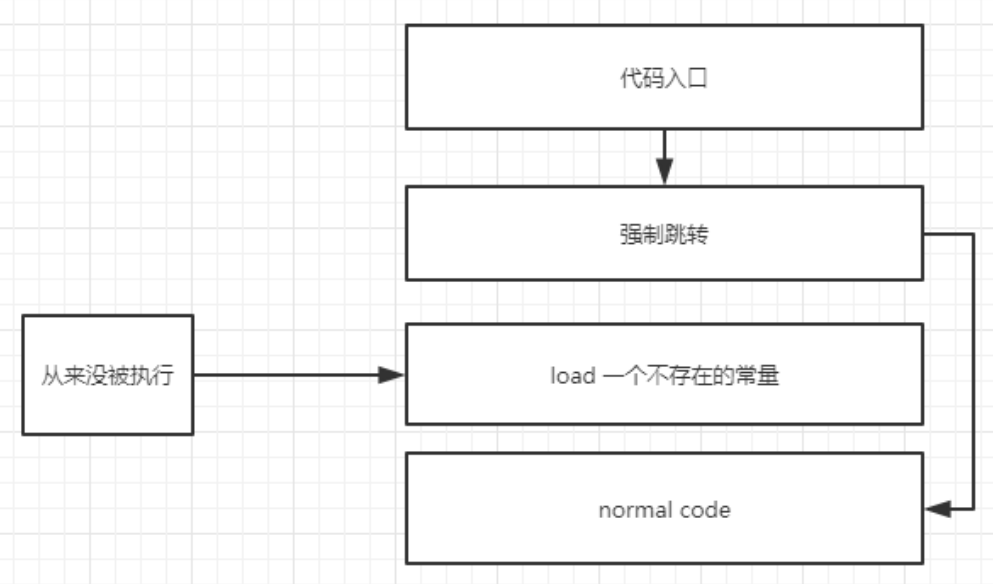
uncompyle 的工作原理和一般的反编译器类似,它会尽力去匹配每一条指令,尝试将所有指令都覆盖到,但是在解析上面的代码时,碰到 load 不存在的常量时就会出错,无法继续反编译。
byte-code加密混淆:把 python 源代码取下来,将内部的 opcode 部分进行重新排序再编译回 python 解释器。
留言
- 文章链接: https://wd-2711.tech/
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-ND 4.0 许可协议。转载请注明出处!